
Arxiv原文:S4RL: Surprisingly Simple Self-Supervision for Offline Reinforcement Learning in Robotics
本文是由多伦多大学、斯坦福大学和Nvidia三家合作完成的工作,发表在5th Conference on Robot Learning (CoRL2021)会议上。
现有的OfflineRL存在(1)对训练数据集过度拟合;(2)在部署时表现出对环境的分布外(OOD)泛化能力差的问题,本篇论文作者研究了在 状态空间上执行数据增强 的有效性,并通过7种不同的增强方案在OfflineRL环境环境中进行了实验。结果不表明使用 S4RL(简单自我监督技术, Surprisingly Simple Self-Supervision in RL) 可以显着改进离线机器人学习环境中的效果。
当前的offline model-free强化学习算法包括学习 Q Q Q 函数,其中训练参数化神经网络以从数据中学习状态动作值。 这一系列算法高估了与所使用的离线数据集不同分布的数据的真实状态-动作值。 除了高估误差外,另一个误差来源是神经网络的函数逼近,通常用于参数化 Q Q Q 函数。 由于在训练期间状态-动作分布是静态的,因此神经网络可能会过度拟合数据,从而在部署到实际环境时进一步导致泛化能力差。 为了阻止神经网络中的过度拟合,可以利用数据增来解决。
流行的actor-critic算法中,例如Soft Actor Critic (SAC),在从离线数据集学习时往往表现不佳,因为它们由于高估偏差(overestimate)而无法推广到分布外 (OOD) 数据: Critic高估了以前从收集的数据中没有遇到的状态-动作对的值,会导致了一个脆弱策略(brittle policy)。
1. Representation Learning in RL
一系列的研究表明,使用表示学习对强化学习的特征提取帮助非常大。
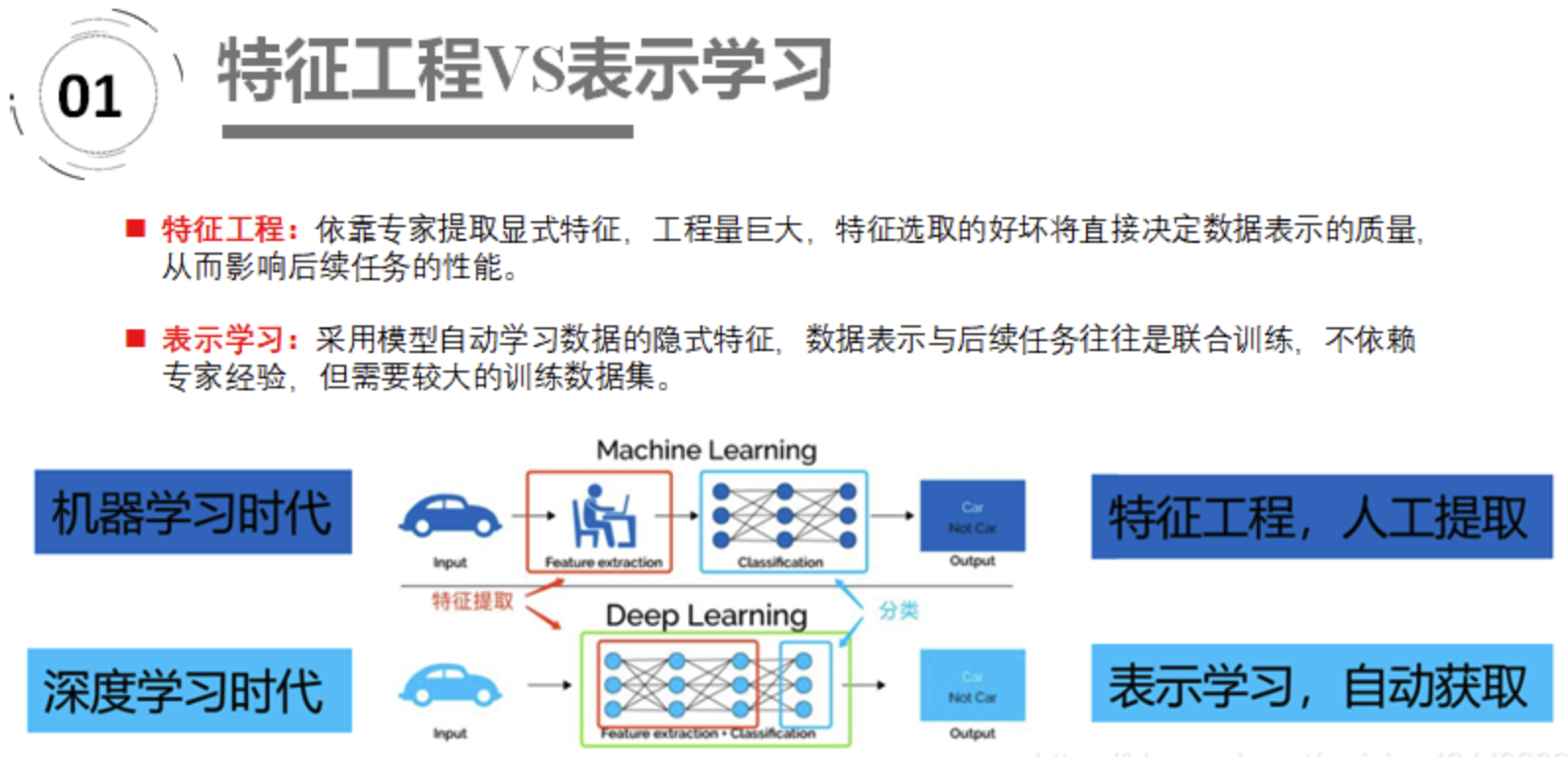
表示学习(Representation Learning) 的目的是对复杂的原始数据化繁为简,把原始数据的无效的或者冗余的信息剔除,把有效信息进行提炼,形成特征(feature),这个2013年的时候Yoshua Bengio就写了一篇综述Representation Learning: A Review and New
Perspectives, 它和特征工程的区别如下:
而将表示学习与RL结合起来,它的结构如下
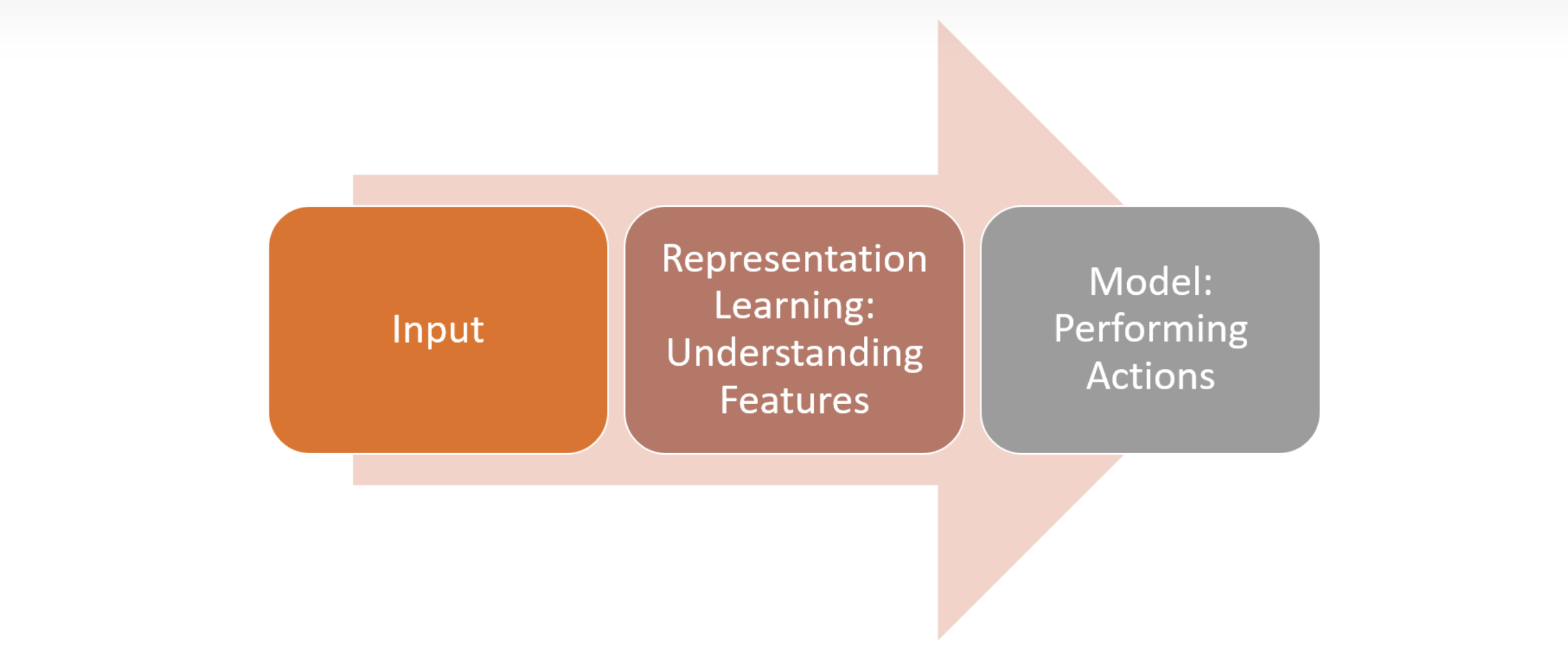
其中最重要的为中间这一部分,即理解特征(PS:强化学习中状态空间过大,特别是无用的特征对算法的收敛也会造成影响,导致算法的收敛、稳定性差)这一层。
本文中作者介绍的数据增强(Data Augementation)主要在状态的提取和策略生成这一层,从图中可以看到直接从Offline Dataset中进行提取数据,通过了 T 1 ( s t ) T_{1}(s_{t}) T1(st) 和 T 2 ( s t ) T_{2}(s_{t}) T2(st)两种方式。然后通过状态空间中的局部扰动具有相似的 Q Q Q 值进行估计,使用增强状态来计算 Q Q Q 值和目标值,以更好地逼近 Q Q Q 网络的函数。
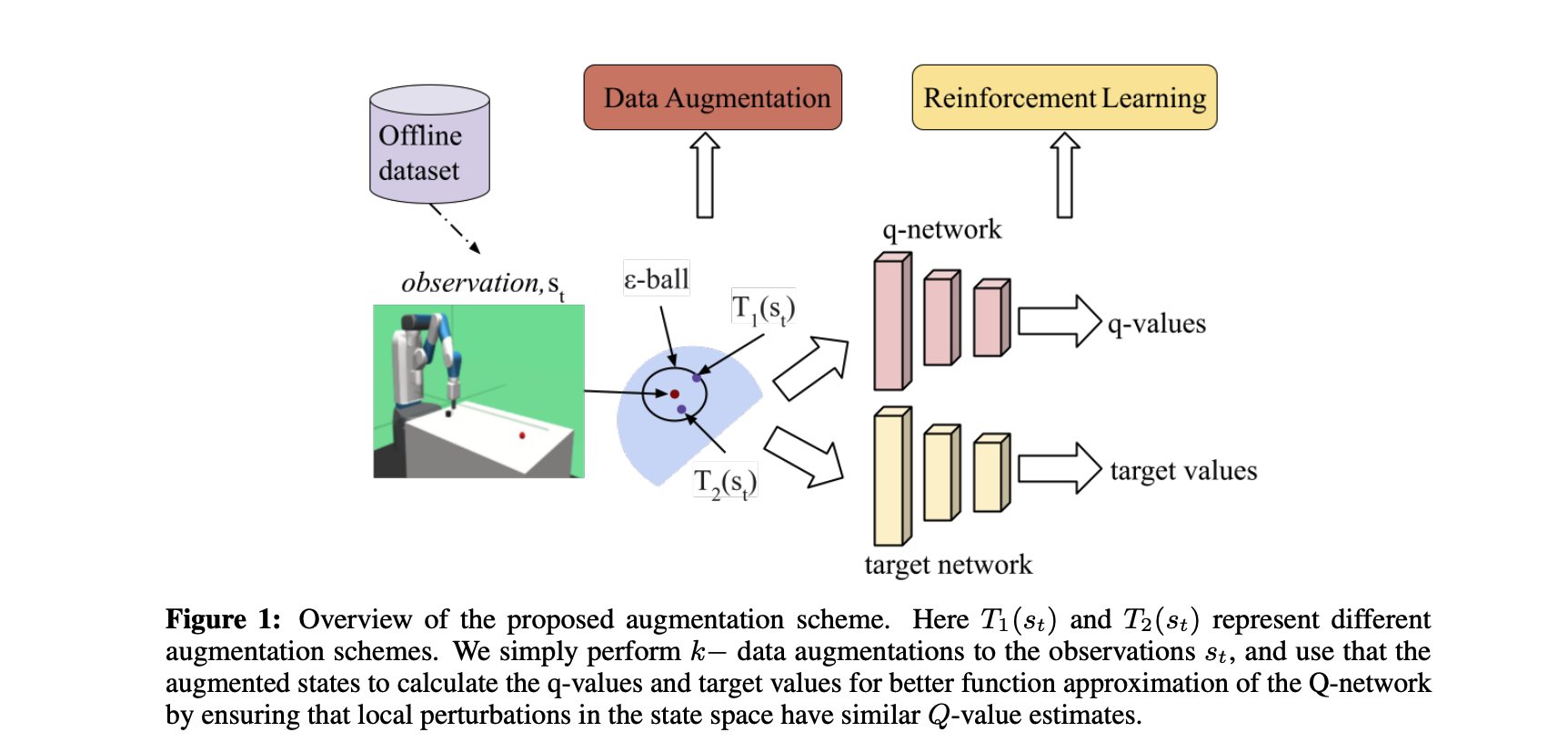
它和传统的RL的区别可以用下图表示,作者特意说: 使用数据增强,能够平滑数据集 s t s_{t} s