
正文共:1024 字 18 图,预估阅读时间:1 分钟
上次实验(MX250笔记本安装Pytorch、CUDA和cuDNN),终于在个人PC上尝到了一点点甜头,可以识别到GPU型号了。

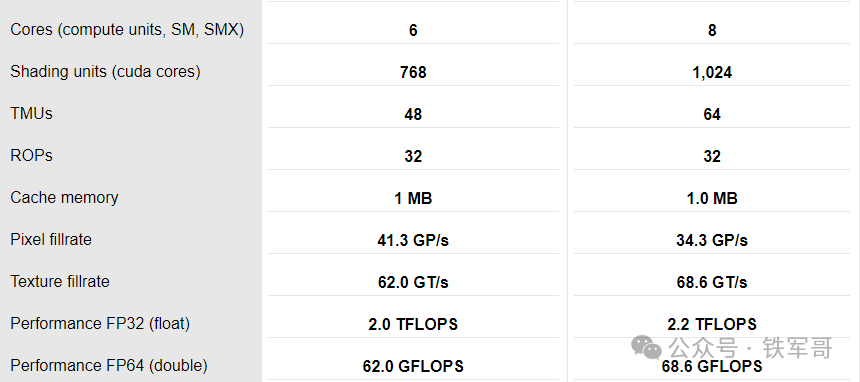
但是如同大家所说,显卡的性能太低了,另外一张能拿得出手的显卡也就是颜总的GTX 1050 Ti了,和Tesla M4相比,性能差距不到10%。经过软磨硬泡,终于可以拿出来跑一下了。
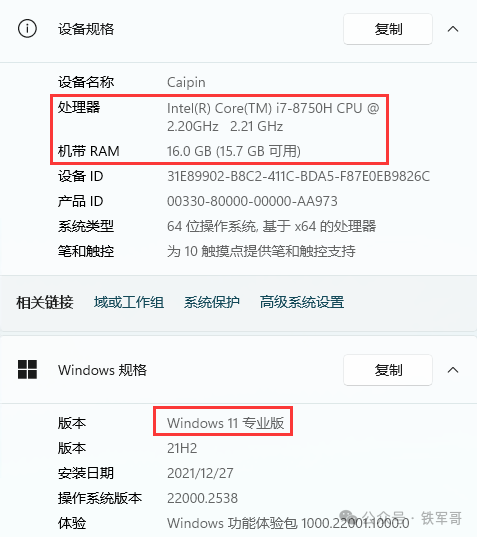
颜总的电脑型号为HP Spectre X360,操作系统为Windows 11专业版,CPU型号为Core i7-8750H,运行内存16 GB,集显型号为UHD630,独显型号为GeForce GTX 1050 Ti(Max-Q)。相比于我自己的电脑,除了内存之外,其他配置全面升级。
在NVIDIA控制面板可以看到,该显卡有768个CUDA核心,只用Tesla M4四分之三的规格,实现了90%的性能,可能这就是架构的优势吧。
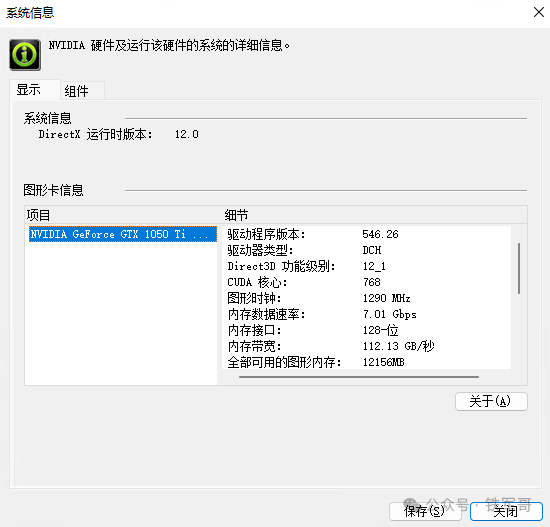
现在的驱动版本时546.26,对应的CUDA版本为12.3.106,已经很新了。
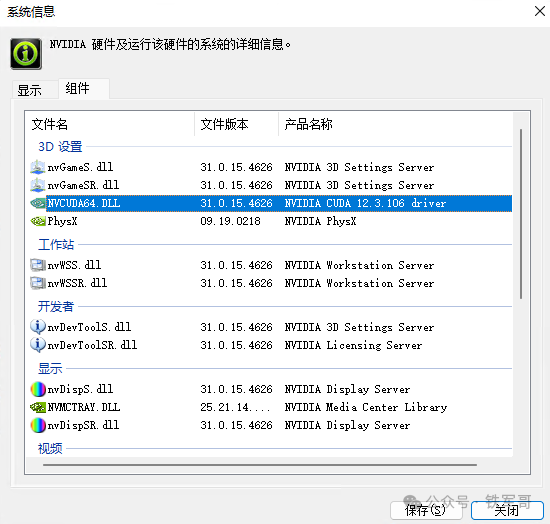
但为了保险起见,我们还是去官网下载一下最新版本。

与MX250不同,GTX 1050 Ti有SD版本驱动,版本号是一样的,用这个试试。
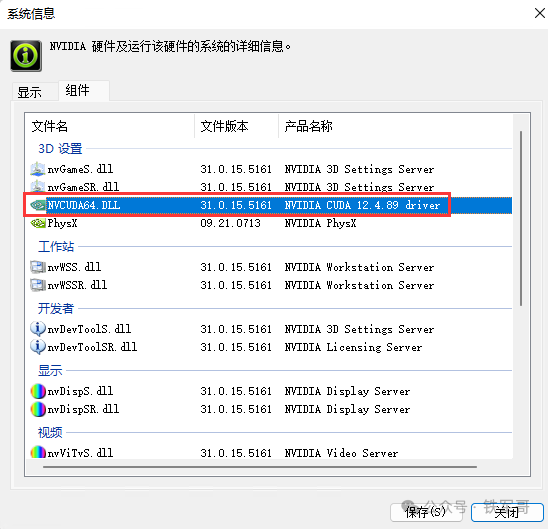
升级之后,CUDA版本升级到了12.4.89。
在PyTorch页面,在Windows系统使用Conda(Anaconda)、Python 3.8以上环境时,匹配稳定版的CUDA版本为11.8和12.1,都比12.4要低,我们这次选12.1试一下。

下载CUDA的12.1版本,链接如下:
https://developer.download.nvidia.cn/compute/cuda/12.1.0/local_installers/cuda_12.1.0_531.14_windows.exe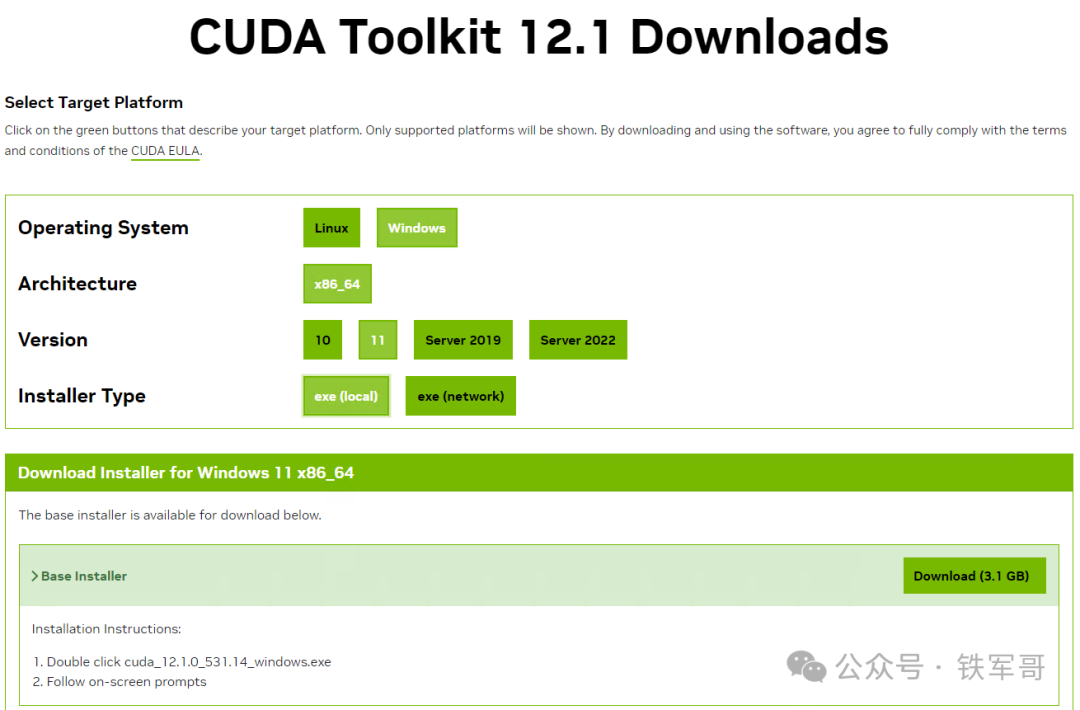
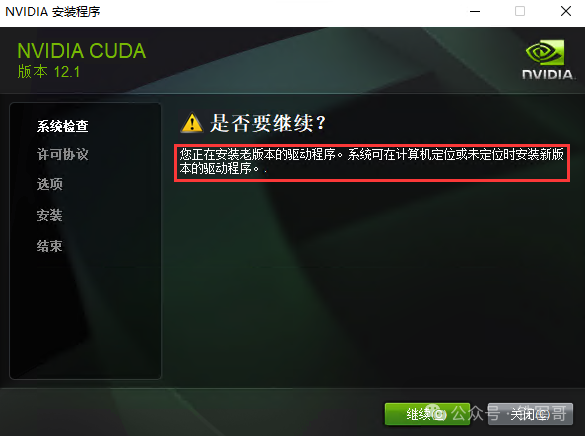
此时我们再手动安装CUDA版本时,出现了驱动程序版本低的提示,无视报错,继续安装。
同样的,在安装cuDNN时,匹配的CUDA版本只有11.8和12.3,没有12.1,先安装试试吧。
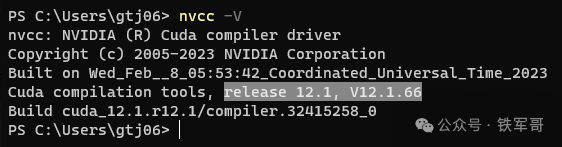
安装完成之后,使用nvcc -V命令查看CUDA是否安装成功。
接下来,先安装Anaconda,下载链接如下:
https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Windows-x86_64.exe再安装PyTorch。
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
安装完成之后,在Python命令行使用以下命令检查CUDA和cuDNN是否安装成功,返回值为True则说明安装成功。捎带检查一下CUDA设备(GPU)的数量,>1说明设备识别成功。
import torch
print(torch.cuda.is_available())
from torch.backends import cudnn
print(cudnn. is_available( ))
print(torch.cuda.device_count())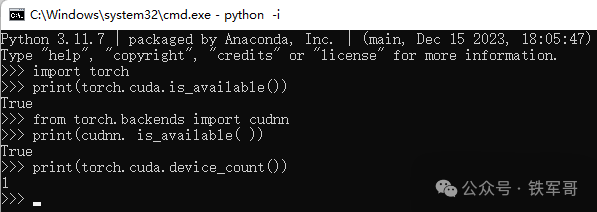
除此之外,还可以获取GPU设备的名称、显存大小等等,还可以运行简单的GPU运算。
if torch.cuda.is_available():
print("GPU可用")
device_name = torch.cuda.get_device_name(0)
print("设备名称:", device_name)
# 获取GPU属性(显存大小)
device_properties = torch.cuda.get_device_properties(0)
print("总显存大小:", device_properties.total_memory)
# 运行一个简单的GPU计算任务来测试性能
x = torch.randn(1024, 1024).cuda()
y = torch.randn(1024, 1024).cuda()
z = x + y
print("GPU计算完成",z)
else:
print("GPU不可用")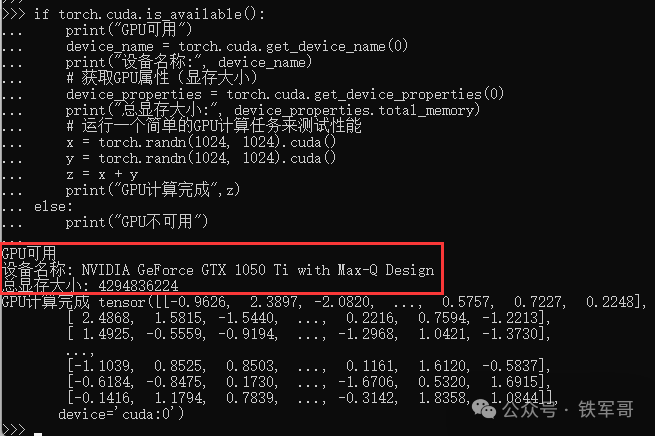
可以看到,成功识别到设备型号为NVIDIA GeForce GTX 1050 Ti with Max-Q Design,显存为4 GB,对应的CUDA设备序号为0。
甚至可以运行一个简单的脚本来对比一下CPU和GPU的运算速度。
import torch
import time
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
print(f"Device: {device}")
# 定义一个较大的张量用于计算
size = (1024, 1024)
input_cpu = torch.randn(size)
input_gpu = input_cpu.to(device)
# 在CPU上执行矩阵乘法(耗时操作)
start_time_cpu = time.time()
output_cpu = torch.mm(input_cpu, input_cpu.t())
duration_cpu = time.time() - start_time_cpu
# 在GPU上执行同样的操作
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t().to(device))
duration_gpu = time.time() - start_time_gpu
# 输出结果和运行时间
print(f"CPU Matrix Multiplication Time: {duration_cpu:.6f} seconds")
print(f"GPU Matrix Multiplication Time: {duration_gpu:.6f} seconds")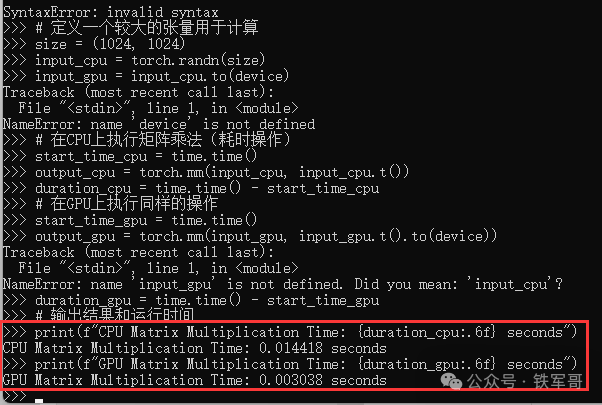
对应CPU计算耗时0.014418秒,GPU计算耗时0.003038秒,GPU耗时约为CPU耗时的21%,也就是说性能大概是CPU的5倍。如果将张量再增大10倍。
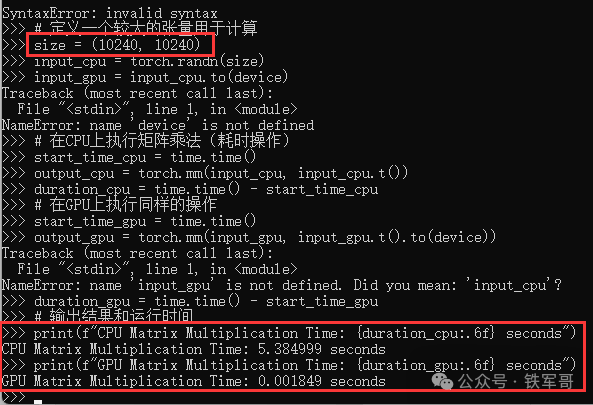
差距更明显了,GPU耗时更少了,而CPU计算耗时370倍。说明GPU运行时间显著小于CPU,GPU在执行该任务上有更好的加速效果。
下一步,回到Tesla M4来重新验证,拭目以待吧!

长按二维码
关注我们吧


CentOS 7.9安装Tesla M4驱动、CUDA和cuDNN
使用8条命令即可完成的VPN配置!CentOS快速配置WireGuard全互联组网
2个报文即完成隧道建立!WireGuard的报文交互竟然比野蛮模式还快!
Windows Server调整策略实现999999个远程用户用时登录
将Juniper虚拟防火墙vSRX部署在ESXi进行简单测试
配置Juniper虚墙vSRX基于策略的IPsec VPN(CLI方式)
Ubuntu 23.10通过APT安装Open vSwitch