引言
IO(Input/Output) 方面的基本知识,相信大家都不陌生,毕竟这也是在学习编程基础时就已经接触过的内容,但最初的 IO 教学大多数是停留在最基本的 BIO ,而并未对于 NIO、AIO 、多路复用等的高级内容进行详细讲述,但这些却是大部分高性能技术的底层核心,因此本文则准备围绕着 IO 知识进行展开。
BIO、NIO、AIO 、多路复用等内容其实在很多文章中都有谈及到,但很多仅是停留在理论层次的定义,以及表面内容的讲解,很少有文章去深入剖析底层的实现,这样会让读者很难去理解 IO 的基本原理。而本文则打算结合多线程知识以及系统内核函数,对 IO 方面的内容进行全方面的剖析。
一、IO基本概念综述
对于 IO 知识,想要真正的去理解它,需要结合多线程、网络、操作系统等多方面的知识, IO 最开始的定义就是指计算机的输入流和输出流,在这里主体为计算机本身,当然主体也可以是一个程序。
PS:从外部设备(如 U 盘、光盘等)中读取数据,这可以被称为输入,而在网络中读取一段数据,这也可以被称为输入。
最初的 IO 流也只有阻塞式的输入输出,但由于时代的不断进步,技术的不停迭代,慢慢的 IO 也会被分为很多种,接下来咱们聊聊 IO 的分类。
1.1、IO的分类
IO 以不同的维度划分,可以被分为多种类型,比如可以从工作层面划分成磁盘 IO (本地 IO )和网络 IO :
- 磁盘
IO:指计算机本地的输入输出,从本地读取一张图片、一段音频、一个视频载入内存,这都可以被称为是磁盘IO。 - 网络
IO:指计算机网络层的输入输出,比如请求/响应、下载/上传等,都能够被称为网络IO。
也可以从工作模式上划分,例如常听的 BIO、NIO、AIO ,还可以从工作性质上分为阻塞式 IO 与非阻塞式 IO ,亦或从多线程角度也可被分为同步 IO 与异步 IO ,这么看下来是不是感觉有些晕乎乎的?没关系,接下来我们对 IO 体系依次全方位进行解析。
1.2、IO工作原理
无论是Java还是其他的语言,本质上 IO 读写操作的原理是类似的,编程语言开发的程序,一般都是工作在用户态空间,但由于 IO 读写对于计算机而言,属于高危操作,所以 OS 不可能 100% 将这些功能开放给用户态的程序使用,所以正常情况下的程序读写操作,本质上都是在调用 OS 内核提供的函数: read()、 write() 。
也就是说,在程序中试图利用 IO 机制读写数据时,仅仅只是调用了内核提供的接口函数而已,本质上真正的 IO 操作还是由内核自己去完成的。
IO 工作的过程如下:
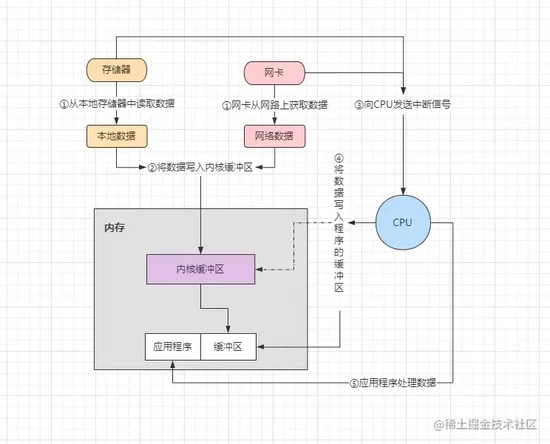
- ①首先在网络的网卡上或本地存储设备中准备数据,然后调用
read()函数。 - ②调用
read()函数厚,由内核将网络/本地数据读取到内核缓冲区中。 - ③读取完成后向
CPU发送一个中断信号,通知CPU对数据进行后续处理。 - ④
CPU将内核中的数据写入到对应的程序缓冲区或网络Socket接收缓冲区中。 - ⑤数据全部写入到缓冲区后,应用程序开始对数据开始实际的处理。
在上述中提到了一个 CPU 中断信号的概念,这其实属于一种 I/O 的控制方式, IO 控制方式目前主要有三种: 忙等待方式、中断驱动方式以及 DMA 直接存储器方式 ,不过无论是何种方式,本质上的最终作用是相同的,都是读取数据的目的。
在上述 IO 工作过程中,其实大体可分为两部分: 准备阶段和复制阶段 ,准备阶段是指数据从网络网卡或本地存储器读取到内核的过程,而复制阶段则是将内核缓冲区中的数据拷贝至用户态的进程缓冲区。常听的 BIO、NIO、AIO 之间的区别,就在于这两个过程中的操作是同步还是异步的,是阻塞还是非阻塞的。
1.3、内核态与用户态
用户态与内核态这两个词汇在前面多次提及到,也包括之前在分析 《Synchronized关键字实现原理》 时也曾讲到过用户态和内核态的切换,那它两究竟是什么意思呢?先上图:
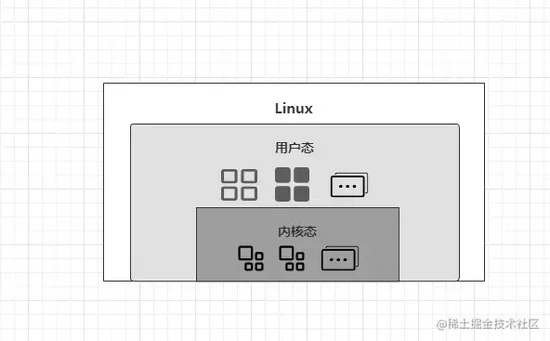
Linux 为了确保系统足够稳定与安全,因此在运行过程中会将内存划分为内核空间与用户空间,其中运行在用户空间的程序被称为“用户态”程序,同理,运行在“内核态”的程序则被称为“内核态”程序,而普通的程序一般都会运行在用户空间。
那么系统为什么要这样设计呢?因为如果内核与用户空间都为同一块儿,此时假设某个程序执行异常导致崩溃了,最终会导致整个系统也出现崩溃,而划分出两块区域的目的就在于:用户空间中的某个程序崩溃,那自会影响自身,而不会影响系统整体的运行。
同时为了防止普通程序去进行 IO 、内存动态调整、线程挂起等一些高危操作引发系统崩溃,因此这些高危操作的具体执行,也只能由内核自己来完成,但程序中有时难免需要用到这些功能,因此内核也会提供很多的函数/接口提供给外部调用。
当处于用户态的程序调用某个内核提供的函数时,此时由于用户态自身不具备这些函数的执行权限,因此会发生用户态到内核态的切换,也就是说:当程序调用某个内核提供的函数后,具体的操作会切换成内核自己去执行。
但用户态与内核态切换时,由于需要处理操作句柄、保存现场、执行系统调用、恢复现场等等过程,因此状态切换其实也是一个开销较大的动作,因此在设计程序时,要尽量减少会发生状态切换的事项,比如Java中,解决线程安全能用 ReetrantLock 的情况下则尽量不使用 Synchronized 。
最后对于用户态和内核态的区别,用大白话来说就是:类似于做程序开发时, 普通用户和管理员的区别 ,为了防止普通用户到处乱点,从而导致系统无法正常运转,因此有些权限只能开放给管理员身份执行,例如删库~
1.4、同步与异步
在上面我们提及到了同步与异步的概念,相信掌握多线程技术的小伙伴对这两个概念并不陌生,这两个概念本身并不难理解,上个<熊猫煮泡面>的栗子:
①先烧水,再开封泡面倒调料,倒开水,等泡面泡好,开吃。
②“熊猫”要煮泡面,然后“竹子”听到了,接下来由竹子去做一系列的工作,泡面好了之后,竹子会端过来或告诉熊猫可以了,然后开吃。
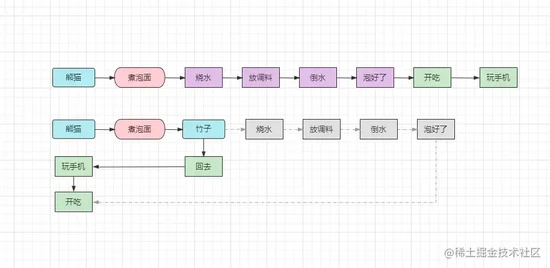
在这个栗子中,第一种情况就属于同步执行的,每一个步骤都需要建立在上一个步骤的基础上依次进行,一步一步全部做完了才能吃上泡面,最后玩手机。而第二种情况则属于异步执行的,熊猫主要煮泡面时,只需要告诉竹子后就能立马回去玩手机了,其他的一系列工作都会由竹子完成,最后熊猫也能吃上泡面。
在这个例子中,熊猫可以理解成主线程,竹子又可以理解成另外一个线程,同步是指线程串行的依次执行,异步则是可以将自己要做的事情交给其他线程执行,然后主线程就能立马返回干其他事情。
1.5、阻塞与非阻塞
同步与阻塞,异步与非阻塞,很多人都会对这两组概念产生疑惑,都会有些区分不清,这是由于它们之间的确是存在关系的,而且是相辅相成的关系,从某种意义上来说: “同步天生就是阻塞的,异步天生就是非阻塞的” 。这句话听起来似乎有些难以理解,那先来看看阻塞与非阻塞的概念:
- 阻塞:对于需要的条件不具备时会一直等待,直至具备条件时才继续往下执行。
- 非阻塞:对于需要的条件不具备时不会等待,而是直接返回等后期具备条件时再回来。
还是之前<熊猫煮泡面>的例子,在第一种同步执行的事件中,由于烧水、泡面等过程都需要时间,因此在这些过程中,由于条件还不具备(水还没开,泡面还没熟),所以熊猫会在原地傻傻等待条件满足(等水开,等泡面熟),那这个过程就是阻塞式过程。
反之,在第二种异步执行的事件中,由于煮泡面的活交给竹子去做了,因此烧水、泡面这些需要等待条件满足的过程,自己都无需等待条件满足,所以在<煮泡面>这个过程中,对于熊猫而言就是非阻塞式的过程。
噼里啪啦一大堆下来,这跟我们本次的主题有何关系呢?
其实这些跟本次的内容关系很大,因为基于上述的概念来说, IO 总共可被分为四大类:同步阻塞式 IO 、同步非阻塞式 IO 、异步阻塞式 IO 、异步非阻塞式 IO ,当然,由于异步执行在一定程度上而言,天生就是非阻塞式的,因此不存在异步阻塞式 IO 的说法。
二、Linux的五种IO模型浅析
在上述中,对于一些 IO 、同步与异步、阻塞与非阻塞等基础概念已经有了基本认知,那此时再将这些概念结合起来后,同步阻塞 IO 、同步非阻塞 IO .....,这又如何理解呢?接下来则依次按顺展开。
Linux 系统中共计提供了五种 IO 模型,它们分别为 BIO、NIO 、多路复用、信号驱动、 AIO ,从性能上来说,它们属于依次递进的关系,但越靠后的 IO 模型实现也越为复杂。
2.1、同步阻塞式IO-BIO
BIO(Blocking-IO) 即同步阻塞模型,这也是最初的 IO 模型,也就是当调用内核的 read() 函数后,内核在执行数据准备、复制阶段的 IO 操作时,应用线程都是阻塞的,所以本次 IO 操作则被称为同步阻塞式 IO ,如下:
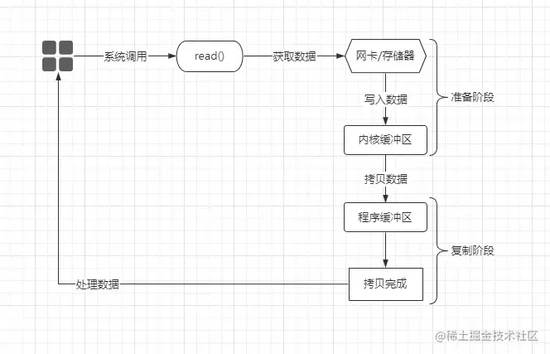
当程序中需要进行 IO 操作时,会先调用内核提供的 read() 函数,但在之前分析过 IO 的工作原理, IO 会经过“设备→内核缓冲区→程序缓冲区”这个过程,该过程必然是耗时的,在同步阻塞模型中,程序中的线程发起 IO 调用后,会一直挂起等待,直至数据成功拷贝至程序缓冲区才会继续往下执行。
简单了解了 BIO 的含义后,那此刻思考一个问题: 当本次 IO 操作还在执行时,又出现多个 IO 调用,比如多个网络数据到来,此刻该如何处理呢?
很简单,采用多线程实现,包括最初的 IO 模型也的确是这样实现的,也就是当出现一个新的 IO 调用时,服务器就会多一条线程去处理,因此会出现如下情况:
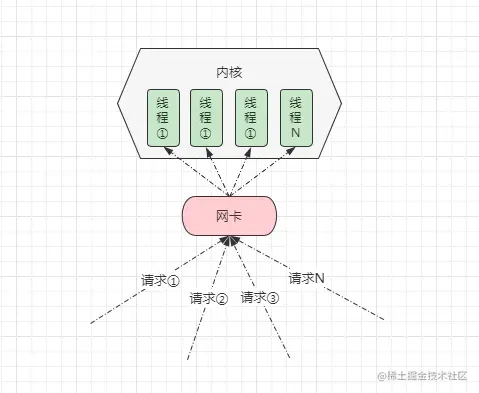
在 BIO 这种模型中,为了支持并发请求,通常情况下会采用“请求:线程” 1:1 的模型,那此时会带来很大的弊端:
- ①并发过高时会导致创建大量线程,而线程资源是有限的,超出后会导致系统崩溃。
- ②并发过高时,就算创建的线程数未达系统瓶颈,但由于线程数过多也会造成频繁的上下文切换。
但在 Java 常用的 Tomcat 服务器中, Tomcat7.x 版本以下默认的 IO 类型也是 BIO ,但似乎并未碰到过:并发请求创建大量线程导致系统崩溃的情况出现呢?这是由于 Tomcat 中对 BIO 模型稍微进行了优化,通过线程池做了限制:
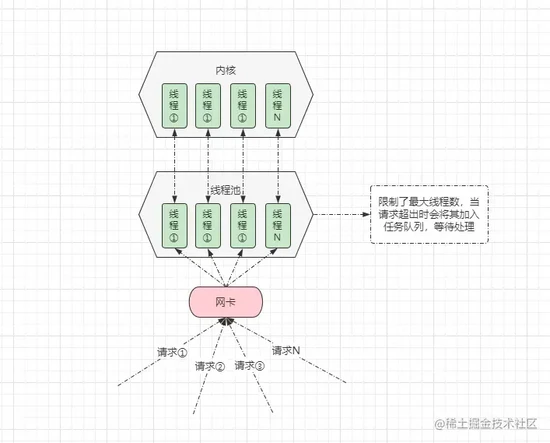
在 Tomcat 中,存在一个处理请求的线程池,该线程池声明了核心线程数以及最大线程数,当并发请求数超出配置的最大线程数时,会将客户端的请求加入请求队列中等待,防止并发过高造成创建大量线程,从而引发系统崩溃。
2.2、同步非阻塞式IO-NIO
NIO(Non-Blocking-IO) 同步非阻塞模型,从字面意思上来说就是:调用 read() 函数的线程并不会阻塞,而是可以正常运行,如下:
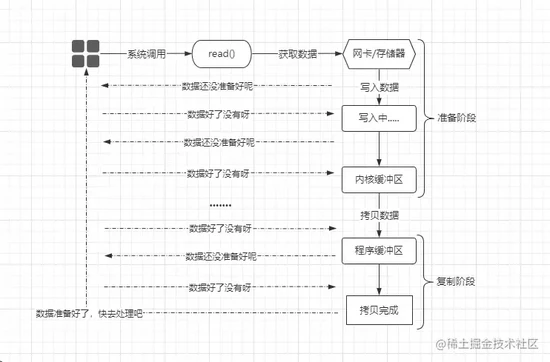
当应用程序中发起 IO 调用后,内核并不阻塞当前线程,而是立马返回一个“数据未就绪”的信息给应用程序,而应用程序这边则一直反复轮询去问内核:数据有没有准备好?直到最终数据准备好了之后,内核返回“数据已就绪”状态,紧接着再由进程去处理数据.....
其实相对来说,这个过程虽然没有阻塞发起 IO 调用的线程,但实际上也会让调用方不断去轮询发起“数据是否准备好”的信号,这也并非真正意义上的非阻塞,就好比:
原本竹子在给熊猫煮泡面,然后熊猫就一直在旁边等着泡面煮好(同步阻塞式),在这个过程中熊猫是“阻塞”的。
现在竹子给熊猫煮泡面。熊猫告诉竹子要吃泡面后就立马回去了,但是过了一会儿又跑回来:泡面有没有好?然后竹子回答没好,然后片刻后又回来问泡面有没有好?竹子又回答还没好......,一直反复循环这个过程直到泡面好了为止。
通过如上的例子,应该能明显感受到这种所谓的 NIO 相对来说较为鸡肋,因此目前大多数的 NIO 技术并非采用这种多线程的模型,而是基于单线程的 多路复用模型 实现的, Java 中支持的 NIO 模型亦是如此。
2.3、多路复用模型
在理解多路复用模型之前,我们先分析一下上述的 NIO 模型到底存在什么问题呢?很简单,由于线程在不断的轮询查看数据是否准备就绪,造成 CPU 开销较大。既然说是由于大量无效的轮询造成 CPU 占用过高,那么等内核中的数据准备好了之后,再去询问数据是否就绪是不是就可以了?答案是 Yes