01、商品搜索:商品搜索思路分析
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bvaGMkTU-1657680854733)(assets/商品搜索过程.jpg)]
进行商品搜索的过程应该分为两大步骤:
1)把MySQL的商品数据,导入到Elasticsearch中,构建商品索引库。
2)用户搜索商品,从Elasticsearch检索数据,展示到搜索结果页面。
今天我们主要完成第一个步骤,在Elasticsearch中构成商品索引库!
02、商品搜索:设计商品的索引文档对象(*)
构建商品索引库的关键是设计能够满足搜索页展示所需的商品文档对象。接下来逐步分析商品文档对象的数据结构。
1)在ly-pojo模块下创建ly-pojo-search
2)导入ES的jar包
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
</dependency>
</dependencies>
3)商品文档对象(1):商品列表

由上图分析得知,我们要设计文档对象的话,应该是一个Spu对应一个文档。
创建Goods对象,如下:
/**
* 一个SPU对应一个Goods
*/
@Data
@Document(indexName = "goods", type = "docs", shards = 1, replicas = 1)
public class Goods {
@Id
@Field(type = FieldType.Keyword)
private Long id; // spuId 索引,不分词
@Field(type = FieldType.Keyword, index = false)
private String subTitle;// 副标题 不索引,不分词
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String spuName; //spu的名称(因为用于高亮显示,所以 索引,分词)
@Field(type = FieldType.Keyword, index = false)
private String skus;// 所有Sku对象信息, 存储json格式, 不索引,不分词
}
注意: 其中skus字段是一个集合,默认情况下,ElasticSearch会将集合中每个属性进行索引,而这里sku的信息只是做展示使用,无需索引,所以我们可以将整个skus字段转成json字符串来存储,整个字符串就是一个keyword,不分词不索引,从而提高ES的性能啦。
4)商品文档对象(2):搜索字段

搜索条件的内容有一个特征,用户输入的时候,随意性很强,什么都可能输入。
所以我们必须对其分词,而且要索引。
这里,我们专门设计一个all字段用来给索引条件匹配。
all字段的内容,可以设计为:三个分类名称+品牌名称+spuName+subTitle+所有Sku的title
Goods对象如下:
/**
* 一个SPU对应一个Goods
*/
@Data
@Document(indexName = "goods", type = "docs", shards = 1, replicas = 1)
public class Goods {
@Id
@Field(type = FieldType.Keyword)
private Long id; // spuId 索引,不分词
@Field(type = FieldType.Keyword, index = false)
private String subTitle;// 副标题 不索引,不分词
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String spuName; //spu的名称(因为用于高亮显示,所以 索引,分词)
@Field(type = FieldType.Keyword, index = false)
private String skus;// 所有Sku对象信息, 存储json格式, 不索引,不分词
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String all; // 所有需要被搜索的信息,包含三个分类名称+品牌名称+spuName+subTitle+所有Sku的title
}
5)商品文档对象(3):固定过滤条件

固定过滤条件,指的是,搜索任何商品,都必须具备的过滤条件,只有分类和品牌两个,其中分类指第三级分类。
分类和品牌的数据,是通过Spu列表数据中每个Spu的分类和品牌聚合而来的。
经过分析后,Goods对象如下:
/**
* 一个SPU对应一个Goods
*/
@Data
@Document(indexName = "goods", type = "docs", shards = 1, replicas = 1)
public class Goods {
@Id
@Field(type = FieldType.Keyword)
private Long id; // spuId 索引,不分词
@Field(type = FieldType.Keyword, index = false)
private String subTitle;// 副标题 不索引,不分词
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String spuName; //spu的名称(因为用于高亮显示,所以 索引,分词)
@Field(type = FieldType.Keyword, index = false)
private String skus;// 所有Sku对象信息, 存储json格式, 不索引,不分词
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String all; // 所有需要被搜索的信息,包含三个分类名称+品牌名称+spuName+subTitle+所有Sku的titleb 索引,分词
@Field(type = FieldType.Long)
private Long brandId;// 品牌id 索引,不分词
@Field(type = FieldType.Long)
private Long categoryId;// 商品3级分类id 索引,不分词
}
6)商品文档对象(4):动态过滤条件
只要某个搜索条件,确定了分类范围。那么我们就可以通过每一个分类,获取到当前分类下,所有用来搜索的规格参数,最终汇总到一起,形成了如下的动态过滤条件。

动态过滤条件,有一个特征,内容不确定,数量不确定,所以这里我们选择使用Map来存储。
Goods对象如下:
/**
* 一个SPU对应一个Goods
*/
@Data
@Document(indexName = "goods", type = "docs", shards = 1, replicas = 1)
public class Goods {
@Id
@Field(type = FieldType.Keyword)
private Long id; // spuId 索引,不分词
@Field(type = FieldType.Keyword, index = false)
private String subTitle;// 副标题 不索引,不分词
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String spuName; //spu的名称(因为用于高亮显示,所以 索引,分词)
@Field(type = FieldType.Keyword, index = false)
private String skus;// 所有Sku对象信息, 存储json格式, 不索引,不分词
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String all; // 所有需要被搜索的信息,包含三个分类名称+品牌名称+spuName+subTitle+所有Sku的titleb 索引,分词
@Field(type = FieldType.Long)
private Long brandId;// 品牌id 索引,不分词
@Field(type = FieldType.Long)
private Long categoryId;// 商品3级分类id 索引,不分词
@Field(type = FieldType.Object)
private Map<String, Object> specs;// 动态过滤条件,商品规格参数,key是参数名,值是参数值 索引
}
注意:在ElasticSearch中Map也会对每一个属性进行索引,且分词的。
7)商品文档对象(5):排序字段
这里我们有两个排序字段,时间和价格。
package com.leyou.search.pojo;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.List;
import java.util.Map;
import java.util.Set;
/**
* 商品实体,与ES的文档映射
* 一个Spu对象对应一个Goods对象
*/
@Data
@Document(indexName = "goods",type = "docs",shards = 1,replicas = 1)
public class Goods {
@Id
private Long id;//存储spuId
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String spuName;//spu表的name属性,因为该字段参与高亮显示,所以必须索引,必须分词
@Field(type = FieldType.Keyword,index = false)
private String subTitle;//副标题,不索引
@Field(type = FieldType.Keyword,index = false)
private String skus;//Spu下的所有Sku数据,由List集合转换成json字符串
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String all;//用于匹配搜索关键词的字段:三个分类名称+品牌名称+spuName+subTitle+所有Sku的title
private Long categoryId;//分类ID,固定过滤条件,通过categoryId聚合而来
private Long brandId;//品牌ID,固定过滤条件,通过brandId聚合而来
/**
* 动态过滤条件格式:
* 1)通用参数格式: {"品牌":"华为"}
* 2)特有参数格式: {"机身颜色":["白色","黑色",...]}
*/
@Field(type = FieldType.Object)
private Map<String,Object> specs;//动态过滤条件
@Field(type = FieldType.Long)
private Long createTime;//创建时间
private Set<Long> price;//价格
}
注意:在ElasticSearch中,如果拿Set类型的字段域排序,降序排列时,会使用Set集合中最大的值排序,升序排序时,会使用Set集合中最小的值排序,总之,会尽量让当前Spu排在靠上的位置。
package com.leyou.search.pojo;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.Map;
import java.util.Set;
/**
* 商品索引库实体类
* 一个Goods对象对应一个Spu对象
*/
@Data
@Document(indexName = "goods",type = "docs")
public class Goods {
@Id
private Long id; //spuId
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String spuName;//商品名称,为了能够高亮显示,spuName也进行索引,分词。
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String all;//把商品用于搜索数据拼接成一个整体(使用空格拼接) 索引,分词
@Field(type = FieldType.Keyword,index = false)
private String subTitle;//副标题 不索引,不分词
@Field(type = FieldType.Keyword,index = false)
private String skus;//商品的所有Sku数据 注意:对象(集合)类型里面对象属性所有都是默认索引和分词的 suks的内容:List集合的json字符串(好处:改变属性为不索引,不分词)
@Field(type = FieldType.Long )
private Set<Long> price; // 存储所有Sku的价格, 索引,不分词
@Field(type = FieldType.Long )
private Long categoryId;//商品分类ID 索引,不分词
@Field(type = FieldType.Long )
private Long brandId;//商品品牌ID 索引,不分词
@Field(type = FieldType.Object )
private Map<String,Object> specs;//商品的所有用于搜索过滤的规格参数 索引,分词
@Field(type = FieldType.Long )
private Long createTime;//创建时间 索引,不分词
}
03、商品搜索:搭建搜索微服务
之前我们学习了Elasticsearch的基本应用。今天就学以致用,搭建搜索微服务,利用elasticsearch实现搜索功能。
1)创建module
2)导入jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>leyou</artifactId>
<groupId>com.leyou</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>ly-search</artifactId>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>2.1.0.RELEASE</version>
</dependency>
<!--springmvc环境-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--调用其他微服务-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>com.leyou</groupId>
<artifactId>ly-client-item</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<!--使用springData系列中的springDataElasticsearch操作elasticsearch-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>com.leyou</groupId>
<artifactId>ly-pojo-search</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.leyou</groupId>
<artifactId>ly-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3)配置application.yml
server:
port: 8083
spring:
application:
name: search-service
data:
elasticsearch:
cluster-name: elasticsearch
cluster-nodes: 127.0.0.1:9300
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
4)启动类
package com.leyou;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
/**
* @author yy
*/
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients // 开启远程Feign调用功能
public class LySearchApplication {
public static void main(String[] args) {
SpringApplication.run(LySearchApplication.class, args);
}
}
5)添加网关路由
在网关ly-gateway的spring.cloud.gateway.routes 配置下添加路由:
- id: search-service
uri: lb://search-service
predicates:
- Path=/api/search/**
filters:
- StripPrefix=2
04、商品搜索:搜索微服务代码准备工作
1)提供repository
package com.leyou.search.repository;
import com.leyou.search.pojo.Goods;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
/**
* 搜索Repository
*/
public interface SearchRepository extends ElasticsearchRepository<Goods,Long>{
}
2)提供service
package com.leyou.search.service;
import com.leyou.search.repository.SearchRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.stereotype.Service;
/**
* 搜索业务
*/
@Service
public class SearchServiceImpl{
@Autowired
private SearchRepository searchRepository; //完成基本CRUD操作
@Autowired
private ElasticsearchTemplate esTemplate;//用于高级搜索
}
3)提供处理器
package com.leyou.search.controller;
import com.leyou.search.service.SearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RestController;
/**
* 搜索Controller
*
*/
@RestController
public class SearchController {
@Autowired
private SearchServiceImpl searchService;
}
05、构建索引库:提供商品微服务对外的feign接口
索引库中的数据来自于数据库,我们不能直接去查询商品的数据库,因为真实开发中,每个微服务都是相互独立的,包括数据库也是一样。所以我们只能调用商品微服务提供的接口服务。
再思考我们需要哪些服务:
- 第一:分页查询spu的服务,写过。
- 第二:根据spuId查询sku集合的服务,没写过
- 第三:查询分类下可以用来搜索的规格参数:写过
- 第四:根据spuId查询SpuDetail对象的服务,没写过
1)在ly-client父工程的pom文件中导入ly-common依赖
<dependency>
<groupId>com.leyou</groupId>
<artifactId>ly-pojo-item</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.leyou</groupId>
<artifactId>ly-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
2)根据SpuId查询Sku对象集合
提供controller:
/**
* 根据spuId查询Sku集合
*/
@GetMapping("/of/spu")
public ResponseEntity<List<TbSku>> findSkusBySpuId(@RequestParam("id") Long id){
List<TbSku> skus = tbSkuService.findSkusBySpuId(id);
return ResponseEntity.ok(skus);
}
提供service:
@Override
public List<TbSku> findSkusBySpuId(Long id) {
LambdaQueryWrapper<TbSku> queryWrapper = Wrappers.lambdaQuery();
queryWrapper.eq(TbSku::getSpuId,id);
List<TbSku> skus = this.list(queryWrapper);
if(CollectionUtils.isEmpty(skus)){
throw new LyException(ResultCode.GOODS_NOT_FOUND);
}
return skus;
}
3)根据SpuId查询SpuDetail对象
提供controller:
/**
* 根据spuId查询SpuDetail
*/
@GetMapping("detail")
public ResponseEntity<TbSpuDetail> findSpuDetailBySpuId(@RequestParam("id") Long id){
TbSpuDetail spuDetail = supDetailService.getById(id);
if(spuDetail==null){
throw new LyException(ResultCode.GOODS_NOT_FOUND);
}
return ResponseEntity.ok(spuDetail);
}
4)最终的item对外feign接口
package com.leyou.item;
import com.leyou.commom.exception.pojo.PageResult;
import com.leyou.item.dto.SpuDto;
import com.leyou.item.pojo.TbSku;
import com.leyou.item.pojo.TbSpecParam;
import com.leyou.item.pojo.TbSpuDetail;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import java.util.List;
/**
* @author yy
* 商品微服务远程接口
*/
@FeignClient("item-service")
public interface ItemClient {
/**
* 根据spuId查询Sku集合
*/
@GetMapping("sku/of/spu")
List<TbSku> findSkusBySpuId(@RequestParam("id") Long id);
/**
* 根据spuId查询SpuDetail
*/
@GetMapping("spuDetail/detail")
TbSpuDetail findSpuDetailBySpuId(@RequestParam("id") Long id);
/**
* 分页查询商品
*/
@GetMapping("spu/page")
PageResult<SpuDto> spuPageQuery(
@RequestParam(value = "page",defaultValue = "1") Integer page,
@RequestParam(value = "rows",defaultValue = "5") Integer rows,
@RequestParam(value = "key",required = false) String key,
@RequestParam(value = "saleable",required = false) Boolean saleable
);
@GetMapping("/spec/params")
List<TbSpecParam> findSpecParams( @RequestParam(value = "gid",required = false) Long gid,
@RequestParam(value = "cid",required = false)Long cid,
@RequestParam(value = "searching",required = false)Boolean searching);
}
**
更正一下:此处由于findSpecParams接口后续调用出现问题,在此先更正传参方式,
**
controller变动 其余不变动
@GetMapping("/spec/params")
public ResponseEntity<List<TbSpecParam>> findSpecParams( @RequestParam(value = "gid",required = false) Long gid,
@RequestParam(value = "cid",required = false)Long cid,
@RequestParam(value = "searching",required = false)Boolean searching){
List<TbSpecParam> list = specParamService.findSpecParams(cid,gid,searching);
if (CollectionUtils.isEmpty(list)){
throw new LyException(ResultCode.GOODS_NOT_FOUND);
}
return ResponseEntity.ok(list);
}
06、构建索引库:FeignClient接口测试(*)
01)服务的提供方
服务的提供方只需要提供对外的feign接口,上面已经完成了此步骤。
02)服务的消费方
导入feign的jar包【已完成】
在启动类上开启feign调用的支持【已完成】
将服务的提供方提供的feign接口引入到项目中【已完成】
测试使用feign接口获取服务提供者提供的数据
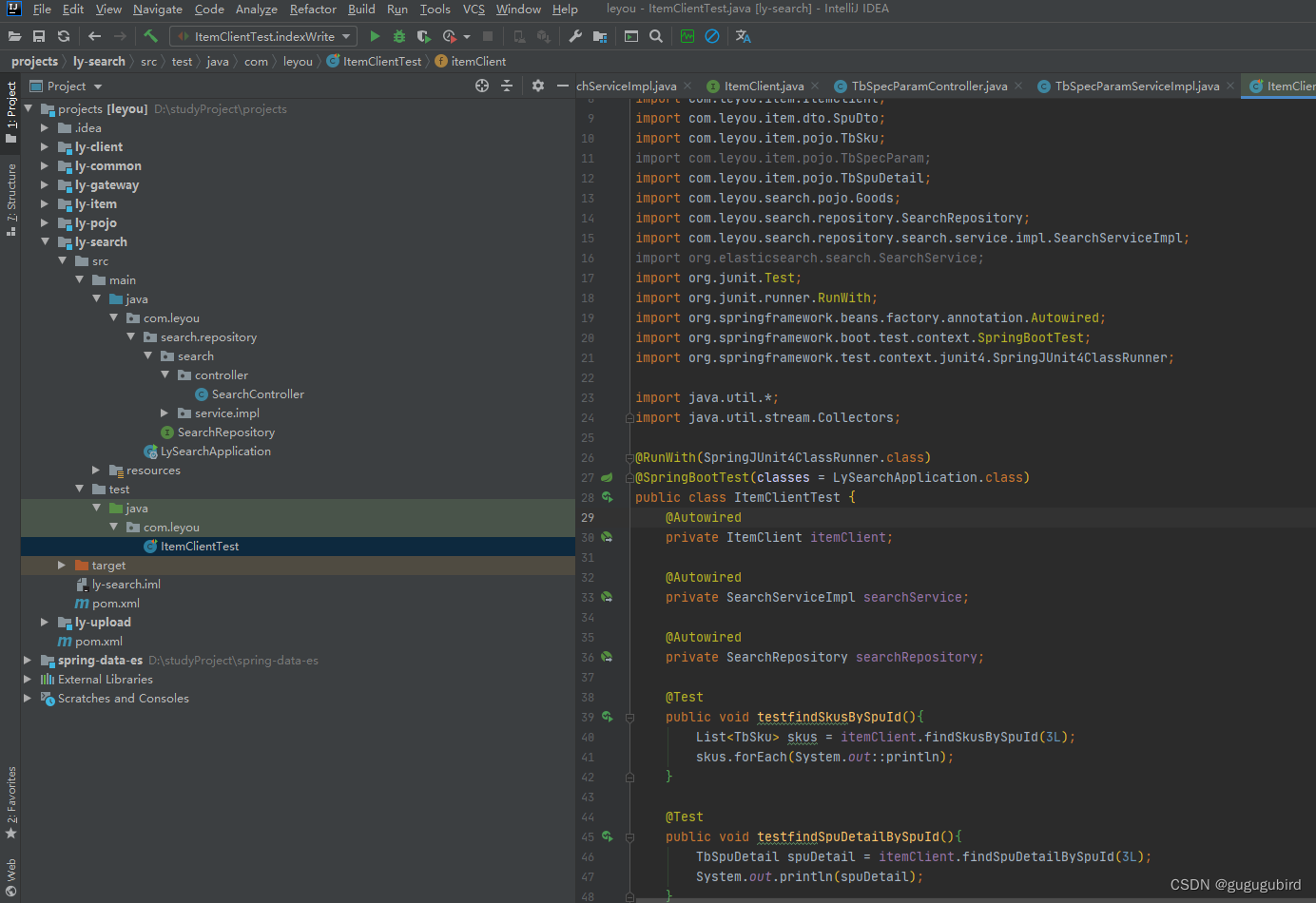
package com.leyou;
import com.leyou.commom.exception.pojo.PageResult;
import com.leyou.item.ItemClient;
import com.leyou.item.dto.SpuDto;
import com.leyou.item.pojo.TbSku;
import com.leyou.item.pojo.TbSpuDetail;
import com.leyou.search.pojo.Goods;
import com.leyou.search.repository.SearchRepository;
import com.leyou.search.repository.search.service.impl.SearchServiceImpl;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.*;
import java.util.stream.Collectors;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = LySearchApplication.class)
public class ItemClientTest {
@Autowired
private ItemClient itemClient;
@Autowired
private SearchServiceImpl searchService;
@Autowired
private SearchRepository searchRepository;
@Test
public void testfindSkusBySpuId(){
List<TbSku> skus = itemClient.findSkusBySpuId(3L);
skus.forEach(System.out::println);
}
@Test
public void testfindSpuDetailBySpuId(){
TbSpuDetail spuDetail = itemClient.findSpuDetailBySpuId(3L);
System.out.println(spuDetail);
}
}
07、构建索引库:构建Goods对象-基本实现
现在所有的资源都准备好了。
那么,我们开始编写从MySQL数据库把商品数据批量导入到Elasticsearch的方法了
SearchService类:
package com.leyou.search.service;
import com.baomidou.mybatisplus.core.toolkit.CollectionUtils;
import com.leyou.common.pojo.PageResult;
import com.leyou.item.client.ItemClient;
import com.leyou.item.dto.SpuDTO;
import com.leyou.search.pojo.Goods;
import com.leyou.search.repository.SearchRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.Date;
import java.util.List;
import java.util.stream.Collectors;
@Service
public class SearchService {
@Autowired
private SearchRepository searchRepository;
@Autowired
private ItemClient itemClient;
/**
* 数据导入
*/
public void importData(){
int page = 1;//当前页码
int rows = 100;//每页条数
int totalPage = 1;//总页数
do {
//1.分页查询Spu商品数据,直到全部数据查询完毕
PageResult<SpuDTO> pageResult = itemClient.spuPageQuery(page, rows, null, true);//注意:导入到ES的数据必须是上架的数据
//2.取出所有商品数据
List<SpuDTO> spuDTOList = pageResult.getItems();
//3.判空处理
if(CollectionUtils.isNotEmpty(spuDTOList)){
//获取List<Goods>集合
List<Goods> goodsList = spuDTOList.stream().map( spuDTO -> buildGoods(spuDTO) ).collect(Collectors.toList());
//保存List<Goods>数据到ES中
searchRepository.saveAll(goodsList);
}
//获取总页数
totalPage = pageResult.getTotalPage().intValue();
page++;
}while (page<=totalPage);
}
/**
* 将一个SpuDTO对象转换为一个Goods对象
*/
public Goods buildGoods(SpuDto spuDto){
Goods goods = new Goods();
goods.setId(spuDto.getId());
goods.setSpuName(spuDto.getName());
goods.setSubTitle(spuDto.getSubTitle());
goods.setCreateTime(System.currentTimeMillis());
goods.setCategoryId(spuDto.getCid3());
goods.setBrandId(spuDto.getBrandId());
goods.setAll(null);
goods.setSkus(null);
goods.setPrice(null);
goods.setSpecs(null);
return goods;
}
}
08、构建索引库:构建Goods对象-封装skus,price,all字段
在上一步中,我们标出了Goods的四个属性还没有值,接下来我们一个一个来完成,这里我们先通过Sku对象集合来封装skus,price,all字段:
/**
* 将一个SpuDTO对象转换为一个Goods对象
*/
public Goods buildGoods(SpuDto spuDto){
Goods goods = new Goods();
//塞入商品基本信息
goods.setId(spuDto.getId());
goods.setSpuName(spuDto.getName());
goods.setSubTitle(spuDto.getSubTitle());
goods.setCreateTime(System.currentTimeMillis());
goods.setCategoryId(spuDto.getCid3());
goods.setBrandId(spuDto.getBrandId());
//根据spuId查询所有Sku
List<TbSku> skuList = itemClient.findSkusBySpuId(spuDto.getId());
//只取出Sku部分属性
List<Map<String,Object>> skuMapList = new ArrayList<>();
//遍历Sku对象
if(CollectionUtils.isNotEmpty(skuList)){
skuList.forEach(sku -> {
Map<String,Object> skuMap = new HashMap<>();//封装一个Sku数据
skuMap.put("id",sku.getId());
skuMap.put("images",sku.getImages());
skuMap.put("price",sku.getPrice());
skuMapList.add(skuMap);
});
}
//将List转换json字符串
String skusJosn = JsonUtils.toString(skuMapList);
//获取all属性 (spu的name + spu的subTitle + 所有Sku的title)
//将所有sku里边的title进行拼接 用空格进行拼接
String skusTitle = skuList.stream().map(m -> m.getTitle()).collect(Collectors.joining(""));
String all = spuDto.getName()+""+spuDto.getSubTitle()+""+skusTitle;
//获取price
Set<Long> prices = skuList.stream().map(a -> a.getPrice()).collect(Collectors.toSet());
goods.setAll(all);
goods.setSkus(skusJosn);
goods.setPrice(prices);
goods.setSpecs(null);
return goods;
}
09、构建索引库:构建Goods对象-封装specs属性(*)
/**
* 将一个SpuDTO对象转换为一个Goods对象
*/
public Goods buildGoods(SpuDTO spuDTO){
Goods goods = new Goods();
//塞入商品基本信息
goods.setId(spuDto.getId());
goods.setSpuName(spuDto.getName());
goods.setSubTitle(spuDto.getSubTitle());
goods.setCreateTime(System.currentTimeMillis());
goods.setCategoryId(spuDto.getCid3());
goods.setBrandId(spuDto.getBrandId());
//根据spuId查询所有Sku
List<TbSku> skuList = itemClient.findSkusBySpuId(spuDto.getId());
//只取出Sku部分属性
List<Map<String,Object>> skuMapList = new ArrayList<>();
//遍历Sku对象
if(CollectionUtils.isNotEmpty(skuList)){
skuList.forEach(sku -> {
Map<String,Object> skuMap = new HashMap<>();//封装一个Sku数据
skuMap.put("id",sku.getId());
skuMap.put("images",sku.getImages());
skuMap.put("price",sku.getPrice());
skuMapList.add(skuMap);
});
}
//将List转换json字符串
String skusJosn = JsonUtils.toString(skuMapList);
//获取all属性 (spu的name + spu的subTitle + 所有Sku的title)
//将所有sku里边的title进行拼接 用空格进行拼接
String skusTitle = skuList.stream().map(m -> m.getTitle()).collect(Collectors.joining(""));
String all = spuDto.getName()+""+spuDto.getSubTitle()+""+skusTitle;
//获取price
Set<Long> prices = skuList.stream().map(a -> a.getPrice()).collect(Collectors.toSet());
goods.setAll(all);
goods.setSkus(skusJosn);
goods.setPrice(prices);
/**
* 格式: Map<String,Object>
* key: 规格参数的名称
* value: 规格参数的值(包含通用规格参数+特有规格参数)
*
* 思路:
* 1)根据分类(第三级)ID查询用于搜索过滤的规格参数(searching=true)
* 2) Map的key,就是规格参数名称
* 3)根据spuId查询SpuDetail数据,取出 generic_spec和special_spec属性值
* 4)将generic_spec,special_spec转换为Map集合,使用规格参数的ID到Map集合取值
* 5)根据generic属性判断该参数是否为通用,如果为通用(true),往Map存入第4步取的值,否则,存入第4步取的值
*
*/
//用于存储所有搜素过滤的规格参数
Map<String,Object> specsMap = new HashMap<>();
//1)根据分类(第三级)ID查询用于搜索过滤的规格参数(searching=true)
List<TbSpecParam> specParamList = itemClient.findSpecParams(null,spuDto.getCid3(),true);
specParamList.stream().forEach(specParam -> {
//2)Map的key,就是规格参数名称
String key = specParam.getName();
Object value = null;
//3)根据spuId查询SpuDetail数据,取出 generic_spec和special_spec属性值
TbSpuDetail spuDetail = itemClient.findSpuDetailBySpuId(spuDto.getId());
String genericSpec = spuDetail.getGenericSpec();
String specialSpec = spuDetail.getSpecialSpec();
//4)将generic_spec,special_spec转换为Map集合,使用规格参数的ID到Map集合取值
//转换generic_spec为Map集合
//toMap():只能转换一层集合架构
Map<Long, Object> genericSpecMap = JsonUtils.toMap(genericSpec, Long.class, Object.class);
//转换special_spec为Map集合
//nativeRead():可以转换多层集合结构
Map<Long, List<Object>> specialSpecMap = JsonUtils.nativeRead(specialSpec, new TypeReference<Map<Long, List<Object>>>() {
});
if(specParam.getGeneric()){
//通用规格参数
value = genericSpecMap.get(specParam.getId());
}else{
//特有规格参数
value = specialSpecMap.get(specParam.getId());
}
/**
* 把数字类型的参数转换为区间范围
* 思路:
* 1)判断该参数是否为数字参数(numeric=true),为true才进行第2步
* 2)取出当前参数的区间(segments),格式:0-4.0,4.0-5.0,5.0-5.5,5.5-6.0,6.0-
* 3)以逗号切割字符串,获取所有区间,在遍历每个区间,再去使用-去切割每个区间,得到每个区间的起始值和结束值。
* 4)判断当前参数值,在哪个区间中,如果匹配,则取出当前区间:4.0-5.0
* 5) 把第4步区间值和参数的单位(unit)拼接,最后成为区间:4.0-5.0英寸 或 4.0英寸以下 或 5.0英寸以上
*/
if(specParam.getNumeric()){
//只有数字类型参数,才去转换区间
value = chooseSegment(value,specParam);
}
specsMap.put(key,value);
});
goods.setSpecs(specsMap);
return goods;
}
10、构建索引库:构建Goods对象-封装specs属性优化
因为过滤参数中有一类比较特殊,就是数值区间,这些区间的值,是商品列表结果中有的才会显示在这里,如果结果中没有个数值区间的,我们不显示。
我们怎么知道结果中有哪些段?先知道结果中有那些尺寸,我们可以用聚合查询加上当前的查询条件,查询这些段,但是我们还需要拿着这些段,去一个个判断,看看那些包含,那些不包含,包含就放入页面显示,不包含就不显示,这样的做法太麻烦,效率不高。
现在的问题是:
1)不知道显示那些段
2)用段来过滤,性能太差
怎么办?这里的设计非常巧妙,当我们把屏幕尺寸存入到索引库的时候,我们不存入值,我们先把它转成段,然后再存入索引库,这样搜索的时候,我们就可以使用term词条查询了,这样的性能就很高了。例如: 5.2英寸 ,我们就存入一个段: 5.0-5.5英寸, 搜索的时候,把5.0-5.5英寸当成词条即可。
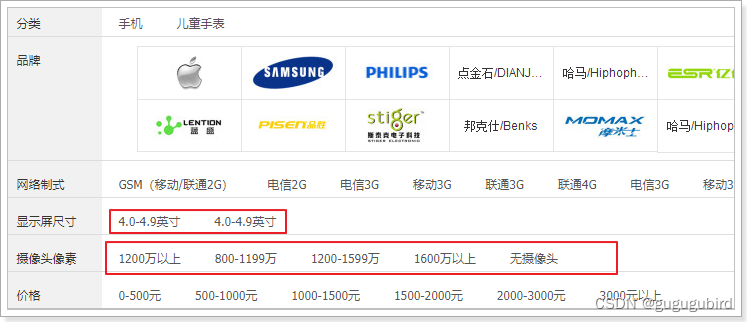
所以我们在存入时要进行分段处理,这段逻辑比较复杂,我已经把它封装成方法,大家直接调用即可:
private String chooseSegment(Object value, SpecParam p) {
if (value == null || StringUtils.isBlank(value.toString())) {
return "其它";
}
double val = parseDouble(value.toString());
String result = "其它";
// 保存数值段
for (String segment : p.getSegments().split(",")) {
String[] segs = segment.split("-");
// 获取数值范围
double begin = parseDouble(segs[0]);
double end = Double.MAX_VALUE;
if (segs.length == 2) {
end = parseDouble(segs[1]);
}
// 判断是否在范围内
if (val >= begin && val < end) {
if (segs.length == 1) {
result = segs[0] + p.getUnit() + "以上";
} else if (begin == 0) {
result = segs[1] + p.getUnit() + "以下";
} else {
result = segment + p.getUnit();
}
break;
}
}
return result;
}
private double parseDouble(String str) {
try {
return Double.parseDouble(str);
} catch (Exception e) {
return 0;
}
}
优化之后的完整的==SearchService==类如下:
/**
* 将一个SpuDTO对象转换为一个Goods对象
* @param spuDto
* @return
*/
public Goods buildGoods(SpuDto spuDto) {
Goods goods = new Goods();
//塞入商品基本信息
goods.setId(spuDto.getId());
goods.setSpuName(spuDto.getName());
goods.setSubTitle(spuDto.getSubTitle());
goods.setCreateTime(System.currentTimeMillis());
goods.setCategoryId(spuDto.getCid3());
goods.setBrandId(spuDto.getBrandId());
//根据spuId查询所有Sku
List<TbSku> skuList = itemClient.findSkusBySpuId(spuDto.getId());
//只取出Sku部分属性
List<Map<String,Object>> skuMapList = new ArrayList<>();
//遍历Sku对象
if(CollectionUtils.isNotEmpty(skuList)){
skuList.forEach(sku -> {
Map<String,Object> skuMap = new HashMap<>();//封装一个Sku数据
skuMap.put("id",sku.getId());
skuMap.put("images",sku.getImages());
skuMap.put("price",sku.getPrice());
skuMapList.add(skuMap);
});
}
//将List转换json字符串
String skusJosn = JsonUtils.toString(skuMapList);
//获取all属性 (spu的name + spu的subTitle + 所有Sku的title)
//将所有sku里边的title进行拼接 用空格进行拼接
String skusTitle = skuList.stream().map(m -> m.getTitle()).collect(Collectors.joining(""));
String all = spuDto.getName()+""+spuDto.getSubTitle()+""+skusTitle;
//获取price
Set<Long> prices = skuList.stream().map(a -> a.getPrice()).collect(Collectors.toSet());
goods.setAll(all);
goods.setSkus(skusJosn);
goods.setPrice(prices);
/**
* 格式: Map<String,Object>
* key: 规格参数的名称
* value: 规格参数的值(包含通用规格参数+特有规格参数)
*
* 思路:
* 1)根据分类(第三级)ID查询用于搜索过滤的规格参数(searching=true)
* 2) Map的key,就是规格参数名称
* 3)根据spuId查询SpuDetail数据,取出 generic_spec和special_spec属性值
* 4)将generic_spec,special_spec转换为Map集合,使用规格参数的ID到Map集合取值
* 5)根据generic属性判断该参数是否为通用,如果为通用(true),往Map存入第4步取的值,否则,存入第4步取的值
*
*/
//用于存储所有搜素过滤的规格参数
Map<String,Object> specsMap = new HashMap<>();
//1)根据分类(第三级)ID查询用于搜索过滤的规格参数(searching=true)
List<TbSpecParam> specParamList = itemClient.findSpecParams(null,spuDto.getCid3(),true);
specParamList.stream().forEach(specParam -> {
//2)Map的key,就是规格参数名称
String key = specParam.getName();
Object value = null;
//3)根据spuId查询SpuDetail数据,取出 generic_spec和special_spec属性值
TbSpuDetail spuDetail = itemClient.findSpuDetailBySpuId(spuDto.getId());
String genericSpec = spuDetail.getGenericSpec();
String specialSpec = spuDetail.getSpecialSpec();
//4)将generic_spec,special_spec转换为Map集合,使用规格参数的ID到Map集合取值
//转换generic_spec为Map集合
//toMap():只能转换一层集合架构
Map<Long, Object> genericSpecMap = JsonUtils.toMap(genericSpec, Long.class, Object.class);
//转换special_spec为Map集合
//nativeRead():可以转换多层集合结构
Map<Long, List<Object>> specialSpecMap = JsonUtils.nativeRead(specialSpec, new TypeReference<Map<Long, List<Object>>>() {
});
if(specParam.getGeneric()){
//通用规格参数
value = genericSpecMap.get(specParam.getId());
}else{
//特有规格参数
value = specialSpecMap.get(specParam.getId());
}
/**
* 把数字类型的参数转换为区间范围
* 思路:
* 1)判断该参数是否为数字参数(numeric=true),为true才进行第2步
* 2)取出当前参数的区间(segments),格式:0-4.0,4.0-5.0,5.0-5.5,5.5-6.0,6.0-
* 3)以逗号切割字符串,获取所有区间,在遍历每个区间,再去使用-去切割每个区间,得到每个区间的起始值和结束值。
* 4)判断当前参数值,在哪个区间中,如果匹配,则取出当前区间:4.0-5.0
* 5) 把第4步区间值和参数的单位(unit)拼接,最后成为区间:4.0-5.0英寸 或 4.0英寸以下 或 5.0英寸以上
*/
if(specParam.getNumeric()){
//只有数字类型参数,才去转换区间
value = chooseSegment(value,specParam);
}
specsMap.put(key,value);
});
goods.setSpecs(specsMap);
return goods;
}
private String chooseSegment(Object value, TbSpecParam p) {
if (value == null || StringUtils.isBlank(value.toString())) {
return "其它";
}
double val = parseDouble(value.toString());
String result = "其它";
// 保存数值段
for (String segment : p.getSegments().split(",")) {
String[] segs = segment.split("-");
// 获取数值范围
double begin = parseDouble(segs[0]);
double end = Double.MAX_VALUE;
if (segs.length == 2) {
end = parseDouble(segs[1]);
}
// 判断是否在范围内
if (val >= begin && val < end) {
if (segs.length == 1) {
result = segs[0] + p.getUnit() + "以上";
} else if (begin == 0) {
result = segs[1] + p.getUnit() + "以下";
} else {
result = segment + p.getUnit();
}
break;
}
}
return result;
}
public double parseDouble(String str) {
try {
return Double.parseDouble(str);
} catch (Exception e) {
return 0;
}
}
/**
* 将数字型参数转换为区间字符串
* @param value
* @param p
* @return
*/
private String chooseSegment(Object value, SpecParam p) {
if (value == null || StringUtils.isBlank(value.toString())) {
return "其它";
}
double val = parseDouble(value.toString());
String result = "其它";
// 保存数值段
for (String segment : p.getSegments().split(",")) {
String[] segs = segment.split("-");
// 获取数值范围
double begin = parseDouble(segs[0]);
double end = Double.MAX_VALUE;
if (segs.length == 2) {
end = parseDouble(segs[1]);
}
// 判断是否在范围内
if (val >= begin && val < end) {
if (segs.length == 1) {
result = segs[0] + p.getUnit() + "以上";
} else if (begin == 0) {
result = segs[1] + p.getUnit() + "以下";
} else {
result = segment + p.getUnit();
}
break;
}
}
return result;
}
private double parseDouble(String str) {
try {
return Double.parseDouble(str);
} catch (Exception e) {
return 0;
}
}
11、构建索引库:用测试类将数据源的数据写入索引库
package com.leyou.search.test;
import com.leyou.common.pojo.PageResult;
import com.leyou.item.client.ItemClient;
import com.leyou.item.dto.SpuDTO;
import com.leyou.item.entity.SpecParam;
import com.leyou.search.entity.Goods;
import com.leyou.search.repository.SearchRepository;
import com.leyou.search.service.SearchService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
import java.util.stream.Collectors;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SearchTest {
@Autowired
private ItemClient itemClient;
@Autowired
private SearchService searchService;
@Autowired
private SearchRepository searchRepository;
/**
* 将数据源的数据写入索引库
*/
@Test
public void indexWrite(){
//定义查询的页数,每页条数,总页数
Integer page = 1, rows = 100;
Long totalPage = 1L;
do{
//查询指定页的Spu数据,不带搜索条件,只查询上架商品数据
PageResult<SpuDTO> pageResult = itemClient.spuPageQuery(page, rows, null, true);
//获取数据列表
List<SpuDTO> spuDTOS = pageResult.getItems();
//把Spu集合转成Goods集合
List<Goods> goodsList = spuDTOS.stream().map(searchService::buildGoods).collect(Collectors.toList());
//批量写入索引库
searchRepository.saveAll(goodsList);
//获取总页数
totalPage = pageResult.getTotalPage();
//页码往后自增
page++;
}while (page<=totalPage);//当当前页数不大于总页的时候执行
}
@Test
public void findSpecParams(){
List<SpecParam> specParams = itemClient.findSpecParams(null, 76l, true);
System.out.println(specParams);
}
}
执行测试代码,然后查看索引库:
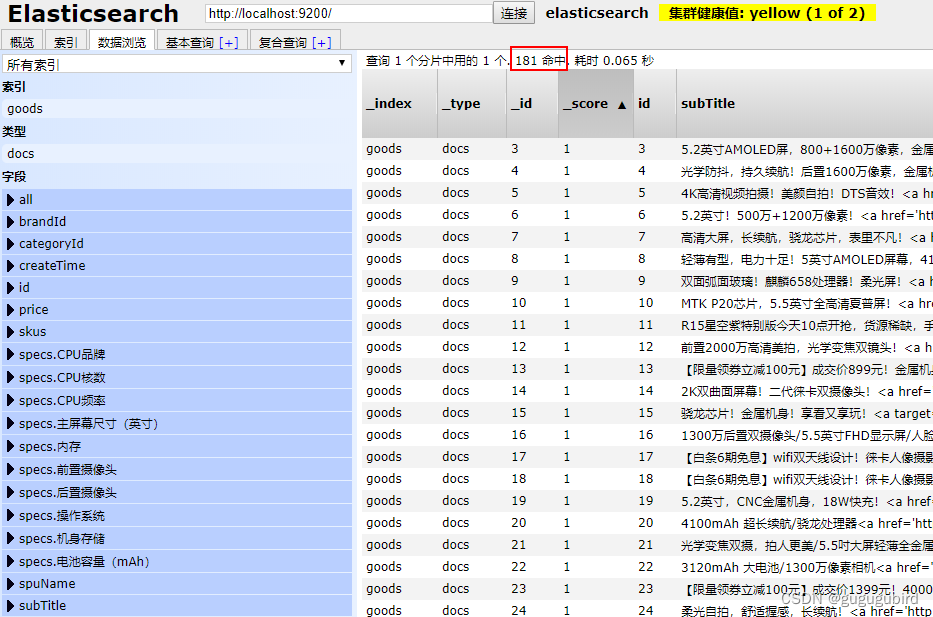
12、搜索页渲染:把商品图片导入
现在商品表中虽然有数据,但是所有的图片信息都是无法访问的,看看数据库中给出的图片信息:
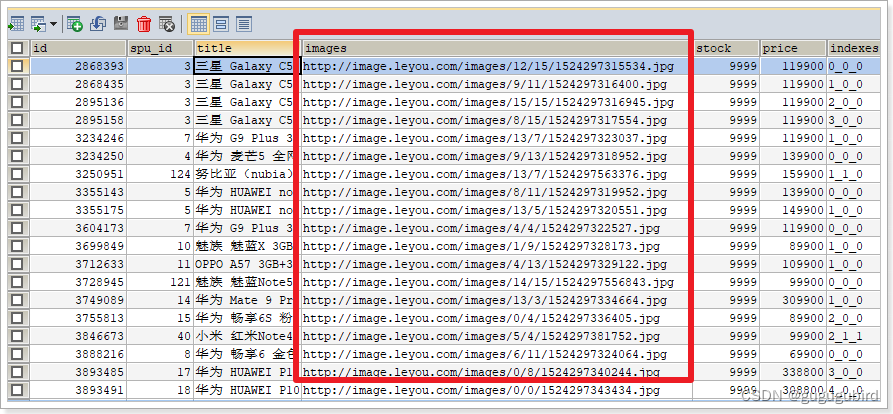
现在这些图片的地址指向的是http://image.leyou.com这个域名。而之前我们在nginx中做了反向代理,把图片地址指向了阿里巴巴的OSS服务。
我们可以再课前资料中找到这些商品的图片:
链接:https://pan.baidu.com/s/1np4EqJ2Vm2mwts0ULWe-Lg
提取码:5mon
并且把这些图片放到nginx目录,然后由nginx对其加载即可。
首先,我们需要把图片放到nginx/html目录,并且解压缩:
修改Nginx中,有关image.leyou.com的监听配置,使nginx来加载图片地址:
server {
listen 80;
server_name image.leyou.com;
location /images { # 监听以/images打头的路径,
root html;
}
location / {
proxy_pass https://ly-images.oss-cn-shanghai.aliyuncs.com;
}
}
再次测试:
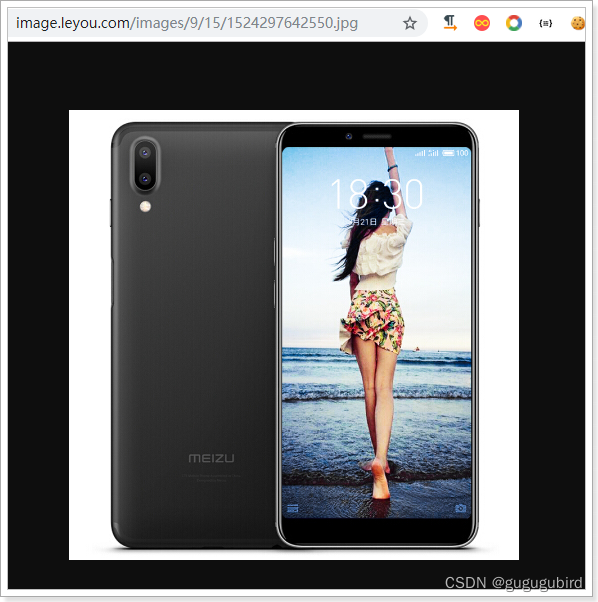
ok,商品图片都搞定了!