前面已经简要地介绍过fork与clone二者的作用于区别。这里先来看一下二者在程序设计接口上的不同:
pid_t fork(void);
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...
/* pid_t *parent_tid, void *tls, pid_t *child_tid */ );系统调用clone的主要作用是创建一个线程,这个线程可以是内核线程,也可以是用户线程。创建用户空间线程时,可以给定子线程用户空间堆栈的位置,还可以指定子进程运行的起点。同时,可以用clone创建进程,有选择地复制父进程的资源。而fork,则是全面的复制。还有一个系统调用vfork,其作用也是创建一个线程,但主要只是作为创建进程的中间步骤,目的在于提高创建时的效率,减少系统开销,其程序设计接口则与fork相同。
asmlinkage int sys_fork(struct pt_regs regs)
{
return do_fork(SIGCHLD, regs.esp, ®s, 0);
}
asmlinkage int sys_clone(struct pt_regs regs)
{
unsigned long clone_flags;
unsigned long newsp;
clone_flags = regs.ebx;
newsp = regs.ecx;
if (!newsp)
newsp = regs.esp;
return do_fork(clone_flags, newsp, ®s, 0);
}
/*
* This is trivial, and on the face of it looks like it
* could equally well be done in user mode.
*
* Not so, for quite unobvious reasons - register pressure.
* In user mode vfork() cannot have a stack frame, and if
* done by calling the "clone()" system call directly, you
* do not have enough call-clobbered registers to hold all
* the information you need.
*/
asmlinkage int sys_vfork(struct pt_regs regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs.esp, ®s, 0);
}
可见,三个系统调用的实现都是通过do_fork来完成的,不同的只是对do_fork的调用参数。关于这些参数所起的作用,读了do_fork的代码以后就会清楚,注意sys_clone中的regs.ebx,就是调用clone时的参数stack,读者如果还不清楚,可以回到系统调用的博客中顺着代码再走一遍。调用clone时可以为子进程设置一个独立的用户空间堆栈(在同一个用户空间中),如果stack为0,就表示使用父进程的用户空间堆栈。这三个系统调用的主体部分do_fork是在kernel/fork.c中定义的。这个函数比较大,让我们逐段往下看:
sys_fork=>do_fork
/*
* Ok, this is the main fork-routine. It copies the system process
* information (task[nr]) and sets up the necessary registers. It also
* copies the data segment in its entirety. The "stack_start" and
* "stack_top" arguments are simply passed along to the platform
* specific copy_thread() routine. Most platforms ignore stack_top.
* For an example that's using stack_top, see
* arch/ia64/kernel/process.c.
*/
int do_fork(unsigned long clone_flags, unsigned long stack_start,
struct pt_regs *regs, unsigned long stack_size)
{
int retval = -ENOMEM;
struct task_struct *p;
DECLARE_MUTEX_LOCKED(sem);
if (clone_flags & CLONE_PID) {
/* This is only allowed from the boot up thread */
if (current->pid)
return -EPERM;
}
current->vfork_sem = &sem;
p = alloc_task_struct();
if (!p)
goto fork_out;
*p = *current;
第560行的宏操作DECLARE_MUTEX_LOCKED定义和创建了一个用于进程间互斥和同步的信号量,其定义和实现见后面的“进程间通信”。
参数clone_flags由两部分组成,其最低的字节为信号类型,用以规定子进程去世时应该向父进程发出的信号。我们已经看到,对于fork和vfork这个信号就是SIGCHLD,而对clone则该位段可由调用者决定。第二部分是一些表示资源和特性的标志位,这些标志位定义如下:
/*
* cloning flags:
*/
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */
#define CLONE_VM 0x00000100 /* set if VM shared between processes */
#define CLONE_FS 0x00000200 /* set if fs info shared between processes */
#define CLONE_FILES 0x00000400 /* set if open files shared between processes */
#define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */
#define CLONE_PID 0x00001000 /* set if pid shared */
#define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */
#define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */
#define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */
#define CLONE_THREAD 0x00010000 /* Same thread group? */
#define CLONE_SIGNAL (CLONE_SIGHAND | CLONE_THREAD)对于fork,这一部分全为0,表现对有关资源都要复制而不是通过指针共享。而对vfork,则为CLONE_VFORK|CLONE_VM,表示父子进程共用(用户)虚存区间,并且当子进程释放其虚存区间时要唤醒父进程。至于clone,则这一部分完全由调用者设定而作为参数传递下来。其中标志位CLONE_PID有特殊的作用,当这个标志位为1时,父子进程(线程)共用同一个进程号,也就是说,子进程虽然有其自己的task_struct数据结构,却使用父进程的pid。但是,只有0号进程,也就是系统中的原始进程(实际上是线程),才允许这样来调用clone,所以564行对此加以检查。
接着,通过alloc_task_struct为子进程分配两个连续的物理页面,低端用作子进程的task_struct结构,高端则用作其系统空间堆栈。
注意574行的赋值为整个数据结构的赋值。这样,父进程的整个task_struct就被复制到了子进程的数据结构中。经编译以后,这样的赋值是用memcpy实现的,所以效率很高。
接着看下一段:
sys_fork=>do_fork
retval = -EAGAIN;
if (atomic_read(&p->user->processes) >= p->rlim[RLIMIT_NPROC].rlim_cur)
goto bad_fork_free;
atomic_inc(&p->user->__count);
atomic_inc(&p->user->processes);
/*
* Counter increases are protected by
* the kernel lock so nr_threads can't
* increase under us (but it may decrease).
*/
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
get_exec_domain(p->exec_domain);
if (p->binfmt && p->binfmt->module)
__MOD_INC_USE_COUNT(p->binfmt->module);
p->did_exec = 0;
p->swappable = 0;
p->state = TASK_UNINTERRUPTIBLE;
copy_flags(clone_flags, p);
p->pid = get_pid(clone_flags);
在task_struct结构中有个指针user,用来指向一个user_struct结构。一个用户常常有许多个进程,所以有关用户的一些信息并不专属于某一个进程,属于同一用户的进程就可以通过指针user共享这些信息。显然,每个用户有且只有一个user_struct结构。结构中有个计数器count,对属于该用户的进程数量计数。可想而知,内核线程并不属于某个用户,所以其task_struct中的user指针为0。这个数据结构的定义如下:
/*
* Some day this will be a full-fledged user tracking system..
*/
struct user_struct {
atomic_t __count; /* reference count */
atomic_t processes; /* How many processes does this user have? */
atomic_t files; /* How many open files does this user have? */
/* Hash table maintenance information */
struct user_struct *next, **pprev;
uid_t uid;
};
熟悉Unix内核的读者要注意,不要把Unix的进程控制结构中的user区与这里的user_struct结构相混淆,二者是截然不同的概念。在kernel/user.c中还定义了一个user_struct结构指针的数组uidhash_table:
/*
* UID task count cache, to get fast user lookup in "alloc_uid"
* when changing user ID's (ie setuid() and friends).
*/
#define UIDHASH_BITS 8
#define UIDHASH_SZ (1 << UIDHASH_BITS)
#define UIDHASH_MASK (UIDHASH_SZ - 1)
#define __uidhashfn(uid) (((uid >> UIDHASH_BITS) ^ uid) & UIDHASH_MASK)
#define uidhashentry(uid) (uidhash_table + __uidhashfn(uid))
static kmem_cache_t *uid_cachep;
static struct user_struct *uidhash_table[UIDHASH_SZ];
static spinlock_t uidhash_lock = SPIN_LOCK_UNLOCKED;
这是一个杂凑表。对用户名施以杂凑运算,就可以计算出一个下标而找到该用户的user_struct结构。
各进程的task_struct结构中还有个数组rlim,对该进程占用各种资源的数量作出限制,而rlim[RLIMIT_NPROC]就规定了该进程所属的用户可以拥有的进程数量。所以,如果当前进程是一个用户进程,并且该用户拥有的进程数量已经达到了规定的限制值,就再不允许它fork了。对于不属于任何用户的内核线程怎么办呢?587行中的两个计数器就是为进程的总量而设的。
一个进程除了属于某一个用户之外,还属于某个执行域。总的来说,linux是Unix的一个变种,并且符合POSIX的规定。但是,有很多版本的操作系统同样是Unix变种,同样符合POSIX规定,互相之间的实现细节上却仍然有明显的不同。例如,at&t的sys V和BSD 4.2就有相当的不同,而Sun的Solaris又有区别,这就形成了不同的执行域。如果一个进程所执行的程序是为Solaris开发的,那么这个进程就属于Solaris执行域PER_SOLARIS。当然,在linux上运行的绝大多数程序都属于linux执行域。在task_struct结构中有一个指针exec_domain,可以指向一个exec_domain数据结构。定义如下:
/* Description of an execution domain - personality range supported,
* lcall7 syscall handler, start up / shut down functions etc.
* N.B. The name and lcall7 handler must be where they are since the
* offset of the handler is hard coded in kernel/sys_call.S.
*/
struct exec_domain {
const char *name;
lcall7_func handler;
unsigned char pers_low, pers_high;
unsigned long * signal_map;
unsigned long * signal_invmap;
struct module * module;
struct exec_domain *next;
};
函数指针handler,用于通过调用门实现系统调用,我们并不关心。字节pers_low为某种域的代码,有PER_LINUX、PER_SVR4、PER_BSD和PER_SOLARIS等等。
我们在这里主要关心的结构成分是module数据结构的指针。读者在有关文件系统和设备驱动的博客中将会看到,在linux系统中设备驱动程序可以设计并实现成动态安装模块module,使其在运行时动态地安装和拆除。这些动态安装模块与运行中的进程的执行域有密切的关系。例如,一个属于Solaris执行域的进程就很可能要用到专门为Solaris设置的一些模块,只要还有一个这样的进程在运行,这些为Solaris所需的模块就不能拆除。所以,在描述每个已安装模块的数据结构中都有一个计数器,表明有几个进程需要使用这个模块。因此,do_fork中通过590行的get_exec_domain递增具体模块的数据结构中的计数器。
#define get_exec_domain(it) \
if (it && it->module) __MOD_INC_USE_COUNT(it->module);同样的道理,每个进程所执行的程序属于某个可执行映像格式,如a.out格式、ELF格式、甚至Java虚拟机格式。对着不同格式的支持通常是通过动态安装的驱动模块来实现的。所以task_struct结构中还有一个指向linux_binfmt数据结构的指针binfmt,而do_fork中593行的__MOD_INC_USE_COUNT就是对有关模块的使用计数器进行操作。
为什么要在597行把状态设成TASK_UNINTERRUPTIBLE呢?这是因为在get_pid中产生一个新pid的操作必须是独占的,当前进程可能会因为一时进不了临界区而只好暂时进入睡眠状态等待,所以才事先把状态设成UNINTERRUPTIBLE。函数copy_flags中的标志位略加补充和变换,然后写入p->flags。这个函数的代码也在fork.c中。读者可以自己阅读。
至于600行的get_pid,则根据clone_flags中标志位CLONE_PID的值,或者返回父进程(当前进程)的pid。或返回一个新的pid放在子进程的task_struct中。函数get_pid的代码也在fork.c中:
sys_fork=>do_fork=>get_pid
static int get_pid(unsigned long flags)
{
static int next_safe = PID_MAX;
struct task_struct *p;
if (flags & CLONE_PID)
return current->pid;
spin_lock(&lastpid_lock);
if((++last_pid) & 0xffff8000) {
last_pid = 300; /* Skip daemons etc. */
goto inside;
}
if(last_pid >= next_safe) {
inside:
next_safe = PID_MAX;
read_lock(&tasklist_lock);
repeat:
for_each_task(p) {
if(p->pid == last_pid ||
p->pgrp == last_pid ||
p->session == last_pid) {
if(++last_pid >= next_safe) {
if(last_pid & 0xffff8000)
last_pid = 300;
next_safe = PID_MAX;
}
goto repeat;
}
if(p->pid > last_pid && next_safe > p->pid)
next_safe = p->pid;
if(p->pgrp > last_pid && next_safe > p->pgrp)
next_safe = p->pgrp;
if(p->session > last_pid && next_safe > p->session)
next_safe = p->session;
}
read_unlock(&tasklist_lock);
}
spin_unlock(&lastpid_lock);
return last_pid;
}
这里的常数PID_MAX定义为0x8000。可见,进程号的最大值时0x7fff,即32767。进程号0-299时为系统进程(包括内核线程)保留的,主要用于各种保护神进程。以上这段代码的逻辑并不复杂,我们就不多加解释了。
sys_fork=>do_fork
p->run_list.next = NULL;
p->run_list.prev = NULL;
if ((clone_flags & CLONE_VFORK) || !(clone_flags & CLONE_PARENT)) {
p->p_opptr = current;
if (!(p->ptrace & PT_PTRACED))
p->p_pptr = current;
}
p->p_cptr = NULL;
init_waitqueue_head(&p->wait_chldexit);
p->vfork_sem = NULL;
spin_lock_init(&p->alloc_lock);
p->sigpending = 0;
init_sigpending(&p->pending);
p->it_real_value = p->it_virt_value = p->it_prof_value = 0;
p->it_real_incr = p->it_virt_incr = p->it_prof_incr = 0;
init_timer(&p->real_timer);
p->real_timer.data = (unsigned long) p;
p->leader = 0; /* session leadership doesn't inherit */
p->tty_old_pgrp = 0;
p->times.tms_utime = p->times.tms_stime = 0;
p->times.tms_cutime = p->times.tms_cstime = 0;
#ifdef CONFIG_SMP
{
int i;
p->has_cpu = 0;
p->processor = current->processor;
/* ?? should we just memset this ?? */
for(i = 0; i < smp_num_cpus; i++)
p->per_cpu_utime[i] = p->per_cpu_stime[i] = 0;
spin_lock_init(&p->sigmask_lock);
}
#endif
p->lock_depth = -1; /* -1 = no lock */
p->start_time = jiffies;我们在前一节中提到过wait4和wait3,一个进程可以停下来等待其子进程完成使命。为此,在task_struct中设置了一个队列头部wait_chldexit,前面在复制task_struct结构时把这个也照抄了过来,而子进程此时尚未出生,当然谈不上子进程的等待队列,所以要611行中加以初始化。
类似地,对各种信息也要加以初始化。这里615和616行是对子进程的待处理信号队列以及有关结构成分的初始化。对这些与信号有关的结构成分我们将在“进程间通信”的信号的博客中详细介绍。接下来是对task_struct结构中各种计时变量的初始化,我们将在进程调度博客中介绍这些变量。在这里我们并不关对多处理器SMP结构的特殊考虑,所以也跳过627-637行。
最后,task_struct结构中的start_time表示进程创建的时间,而全局变量jiffies的数值就是以时钟中断周期为单位的从系统初始化开始至此时的时间,
至此,对task_struct树结构的复制与初始化就基本完成了。下面就轮到其他的资源了:
sys_fork=>do_fork
retval = -ENOMEM;
/* copy all the process information */
if (copy_files(clone_flags, p))
goto bad_fork_cleanup;
if (copy_fs(clone_flags, p))
goto bad_fork_cleanup_files;
if (copy_sighand(clone_flags, p))
goto bad_fork_cleanup_fs;
if (copy_mm(clone_flags, p))
goto bad_fork_cleanup_sighand;
retval = copy_thread(0, clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_sighand;
p->semundo = NULL;函数copy_files有条件地复制已打开文件的控制结构,这种复制只有在clone_flags中CLONE_FILES标志位为0时才真正进行,否则就只是共享父进程的已打开文件。当一个进程有已打开文件时,task_struct结构中的指针files指向一个files_struct数据结构,否则为0。所有与终端设备tty相联系的用户进程的头三个文件,即stdin、stdout以及stderr,都是预先打开的,所以指针一般不会是0。数据结构files_struct在文件系统的博客中讲解了,copy_files的代码如下:
sys_fork=>do_fork=>copy_files
static int copy_files(unsigned long clone_flags, struct task_struct * tsk)
{
struct files_struct *oldf, *newf;
struct file **old_fds, **new_fds;
int open_files, nfds, size, i, error = 0;
/*
* A background process may not have any files ...
*/
oldf = current->files;
if (!oldf)
goto out;
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
goto out;
}
tsk->files = NULL;
error = -ENOMEM;
newf = kmem_cache_alloc(files_cachep, SLAB_KERNEL);
if (!newf)
goto out;
atomic_set(&newf->count, 1);
newf->file_lock = RW_LOCK_UNLOCKED;
newf->next_fd = 0;
newf->max_fds = NR_OPEN_DEFAULT;
newf->max_fdset = __FD_SETSIZE;
newf->close_on_exec = &newf->close_on_exec_init;
newf->open_fds = &newf->open_fds_init;
newf->fd = &newf->fd_array[0];
/* We don't yet have the oldf readlock, but even if the old
fdset gets grown now, we'll only copy up to "size" fds */
size = oldf->max_fdset;
if (size > __FD_SETSIZE) {
newf->max_fdset = 0;
write_lock(&newf->file_lock);
error = expand_fdset(newf, size);
write_unlock(&newf->file_lock);
if (error)
goto out_release;
}
read_lock(&oldf->file_lock);
open_files = count_open_files(oldf, size);
/*
* Check whether we need to allocate a larger fd array.
* Note: we're not a clone task, so the open count won't
* change.
*/
nfds = NR_OPEN_DEFAULT;
if (open_files > nfds) {
read_unlock(&oldf->file_lock);
newf->max_fds = 0;
write_lock(&newf->file_lock);
error = expand_fd_array(newf, open_files);
write_unlock(&newf->file_lock);
if (error)
goto out_release;
nfds = newf->max_fds;
read_lock(&oldf->file_lock);
}
old_fds = oldf->fd;
new_fds = newf->fd;
memcpy(newf->open_fds->fds_bits, oldf->open_fds->fds_bits, open_files/8);
memcpy(newf->close_on_exec->fds_bits, oldf->close_on_exec->fds_bits, open_files/8);
for (i = open_files; i != 0; i--) {
struct file *f = *old_fds++;
if (f)
get_file(f);
*new_fds++ = f;
}
read_unlock(&oldf->file_lock);
/* compute the remainder to be cleared */
size = (newf->max_fds - open_files) * sizeof(struct file *);
/* This is long word aligned thus could use a optimized version */
memset(new_fds, 0, size);
if (newf->max_fdset > open_files) {
int left = (newf->max_fdset-open_files)/8;
int start = open_files / (8 * sizeof(unsigned long));
memset(&newf->open_fds->fds_bits[start], 0, left);
memset(&newf->close_on_exec->fds_bits[start], 0, left);
}
tsk->files = newf;
error = 0;
out:
return error;
out_release:
free_fdset (newf->close_on_exec, newf->max_fdset);
free_fdset (newf->open_fds, newf->max_fdset);
kmem_cache_free(files_cachep, newf);
goto out;
}
读者可以回过去学习系文件系统的系列博客再回过头来仔细阅读这段代码,我们在这里做一些解释。
先看复制的方向。因为是当前进程在创建子进程,是从当前进程复制到子进程,所以把当前进程的task_struct结构中的files_struct结构指针作为oldf。
再看复制的条件。如果参数clone_flags中的CLONE_FILES标志位为1,就只能通过atomic_inc递增当前进程的files_struct结构中的共享计数,表示这个数据结构现在多了一个用户,就返回了。由于在此之前已经通过数据结构赋值将当前进程的整个task_struct结构都复制给了子进程,结构中的指针files自然也复制到了子进程的task_struct结构中,使子进程通过这个指针共享当前进程的files_struct数据结构。否则,如果CLONE_FILES标志位为0,那就要复制了。首先通过kmem_cache_alloc为子进程分配一个files_struct数据结构作为newf,然后从oldf把内容复制到newf。在files_struct数据结构中有三个主要的部件:其一是个位图,为名close_on_exec_init;其二也是位图,名为open_fds_init;其三则是file结构数组fd_array。这三个部件都是固定大小的,如果打开的文件数量超过其容量,就得通过expand_fdset和expand_fd_array在files_struct数据结构以外另行分配空间作为替换。不管是采用files_struct数据结构内部的这三个部件或是采用外部的替换空间,指针close_on_exec、open_fds和fd总是分别指向这三组信息。所以,如何复制取决于打开文件的数量。
显而易见,共享比复制要简单的多。那么这二者在效果上到底有什么区别呢?如果共享就可以达到目的,为什么还要不辞辛劳地复制呢?区别在于子进程(以及父进程本身)是否能独立自主。当复制完成之初。子进程有了一份副本,它的内容与父进程的正本在内容上基本是相同的,在这一点上似乎与共享没有什么区别。可是,随后区别就来了。在共享的情况下,两个进程是互相牵制的。如果子进程对某个已打开文件调用了一个lseek,则父进程对这个文件的读写位置也随着改变了,因为两个进程共享着对文件的同一个读写上下文。而在复制的情况下就不一样了,由于子进程有自己的副本,就有了对同一文件的另一个读写上下文,以后就可以各走各的路,互不干扰了。
除files_struct数据结构外,还有个fs_struct数据结构也是与文件系统有关的,也要通过共享或复制遗传给子进程。类似地,copy_fs也是只有在clone_flags中CLONE_FS标志位为0时才加以复制。task_struct结构中的指针指向一个fs_struct数据结构,结构中记录的是进程的根目录root、当前工作目录pwd、一个用于文件系统权限管理的umask,还有一个计数器。函数copy_fs连同几个有关低层函数的代码也在fork.c中。我们把这些代码留给读者:
sys_fork=>do_fork=>copy_fs
static inline int copy_fs(unsigned long clone_flags, struct task_struct * tsk)
{
if (clone_flags & CLONE_FS) {
atomic_inc(¤t->fs->count);
return 0;
}
tsk->fs = __copy_fs_struct(current->fs);
if (!tsk->fs)
return -1;
return 0;
}
sys_fork=>do_fork=>copy_fs=>__copy_fs_struct
static inline struct fs_struct *__copy_fs_struct(struct fs_struct *old)
{
struct fs_struct *fs = kmem_cache_alloc(fs_cachep, GFP_KERNEL);
/* We don't need to lock fs - think why ;-) */
if (fs) {
atomic_set(&fs->count, 1);
fs->lock = RW_LOCK_UNLOCKED;
fs->umask = old->umask;
read_lock(&old->lock);
fs->rootmnt = mntget(old->rootmnt);
fs->root = dget(old->root);
fs->pwdmnt = mntget(old->pwdmnt);
fs->pwd = dget(old->pwd);
if (old->altroot) {
fs->altrootmnt = mntget(old->altrootmnt);
fs->altroot = dget(old->altroot);
} else {
fs->altrootmnt = NULL;
fs->altroot = NULL;
}
read_unlock(&old->lock);
}
return fs;
}
代码中的mntget和dget都是用来递增相应数据结构中的共享计数的,因为这些数据结构现在多了一个用户。注意,在这里要复制的是fs_struct数据结构,而并不复制更深层的数据结构。复制了fs_struct数据结构,就在这一层有了自主性,至于对更深层的数据结构则还是共享,所以要递增它们的共享计数。
接着是关于对信号的处理方式。是否复制父进程对信号的处理是由标志位CLONE_SIGHAND控制的,信号基本上是一种进程间通信手段。信号之于一个进程就好像中断之于一个处理器。进程可以为各种信号设置用于该信号的处理程序,就好像系统可以为各种中断而设置相应的中断服务程序一样。如果一个进程设置了信号处理程序,其task_struct结构中的指针sig就指向一个signal_struct数据结构。这种结构的定义如下:
struct signal_struct {
atomic_t count;
struct k_sigaction action[_NSIG];
spinlock_t siglock;
};
其中的数组action确定了一个进程对各种信号(以信号的数值为下标)的反应和处理。子进程可以通过复制或共享把它从父进程继承下来。函数copy_sighand的代码如下:
sys_fork=>do_fork=>copy_sighand
static inline int copy_sighand(unsigned long clone_flags, struct task_struct * tsk)
{
struct signal_struct *sig;
if (clone_flags & CLONE_SIGHAND) {
atomic_inc(¤t->sig->count);
return 0;
}
sig = kmem_cache_alloc(sigact_cachep, GFP_KERNEL);
tsk->sig = sig;
if (!sig)
return -1;
spin_lock_init(&sig->siglock);
atomic_set(&sig->count, 1);
memcpy(tsk->sig->action, current->sig->action, sizeof(tsk->sig->action));
return 0;
}
像copy_files和copy_fs一样,copy_sighand也是只有在CLONE_SIGHAND为0时才真正进行,否则就共享父进程的sig指针,并将父进程的signal_struct的共享计数加1。
然后是用户空间的继承。进程的task_struct结构中有个指针mm,读者已经相当熟悉了,它指向一个代表着进程的用户空间的mm_struct数据结构。由于内核线程并不拥有用户空间,所以在内核线程的task_struct结构中该指针为0。有关mm_struct及其下属的vm_area_struct等数据结构已经在内存管理中分析过,这里不再重复。函数copy_mm的代码如下:
sys_fork=>do_fork=>copy_mm
static int copy_mm(unsigned long clone_flags, struct task_struct * tsk)
{
struct mm_struct * mm, *oldmm;
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->cmin_flt = tsk->cmaj_flt = 0;
tsk->nswap = tsk->cnswap = 0;
tsk->mm = NULL;
tsk->active_mm = NULL;
/*
* Are we cloning a kernel thread?
*
* We need to steal a active VM for that..
*/
oldmm = current->mm;
if (!oldmm)
return 0;
if (clone_flags & CLONE_VM) {
atomic_inc(&oldmm->mm_users);
mm = oldmm;
goto good_mm;
}
retval = -ENOMEM;
mm = allocate_mm();
if (!mm)
goto fail_nomem;
/* Copy the current MM stuff.. */
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm))
goto fail_nomem;
down(&oldmm->mmap_sem);
retval = dup_mmap(mm);
up(&oldmm->mmap_sem);
/*
* Add it to the mmlist after the parent.
*
* Doing it this way means that we can order
* the list, and fork() won't mess up the
* ordering significantly.
*/
spin_lock(&mmlist_lock);
list_add(&mm->mmlist, &oldmm->mmlist);
spin_unlock(&mmlist_lock);
if (retval)
goto free_pt;
/*
* child gets a private LDT (if there was an LDT in the parent)
*/
copy_segments(tsk, mm);
if (init_new_context(tsk,mm))
goto free_pt;
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
free_pt:
mmput(mm);
fail_nomem:
return retval;
}
显然,对mm_struct的复制也是只在clone_flags中CLONE_VM标志位为0时才真正进行,否则就只是通过已经复制的指针共享父进程的用户空间。对mm_struct的复制就不只是局限于这个数据结构本身了,也包括了对更深层数据结构的复制,其中最重要的是vm_area_struct数据结构和页面映射表,这是由dup_mmap复制的。函数dup_mmap的代码在kernel/fork.c中,读者在认真读过本系列的博客以后,阅读这段程序应该不会感到困难,同时也是一次很好地练习。sys_fork=>do_fork=>copy_mm=>dup_mmap
static inline int dup_mmap(struct mm_struct * mm)
{
struct vm_area_struct * mpnt, *tmp, **pprev;
int retval;
flush_cache_mm(current->mm);
mm->locked_vm = 0;
mm->mmap = NULL;
mm->mmap_avl = NULL;
mm->mmap_cache = NULL;
mm->map_count = 0;
mm->cpu_vm_mask = 0;
mm->swap_cnt = 0;
mm->swap_address = 0;
pprev = &mm->mmap;
for (mpnt = current->mm->mmap ; mpnt ; mpnt = mpnt->vm_next) {
struct file *file;
retval = -ENOMEM;
if(mpnt->vm_flags & VM_DONTCOPY)
continue;
tmp = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
if (!tmp)
goto fail_nomem;
*tmp = *mpnt;
tmp->vm_flags &= ~VM_LOCKED;
tmp->vm_mm = mm;
mm->map_count++;
tmp->vm_next = NULL;
file = tmp->vm_file;
if (file) {
struct inode *inode = file->f_dentry->d_inode;
get_file(file);
if (tmp->vm_flags & VM_DENYWRITE)
atomic_dec(&inode->i_writecount);
/* insert tmp into the share list, just after mpnt */
spin_lock(&inode->i_mapping->i_shared_lock);
if((tmp->vm_next_share = mpnt->vm_next_share) != NULL)
mpnt->vm_next_share->vm_pprev_share =
&tmp->vm_next_share;
mpnt->vm_next_share = tmp;
tmp->vm_pprev_share = &mpnt->vm_next_share;
spin_unlock(&inode->i_mapping->i_shared_lock);
}
/* Copy the pages, but defer checking for errors */
retval = copy_page_range(mm, current->mm, tmp);
if (!retval && tmp->vm_ops && tmp->vm_ops->open)
tmp->vm_ops->open(tmp);
/*
* Link in the new vma even if an error occurred,
* so that exit_mmap() can clean up the mess.
*/
*pprev = tmp;
pprev = &tmp->vm_next;
if (retval)
goto fail_nomem;
}
retval = 0;
if (mm->map_count >= AVL_MIN_MAP_COUNT)
build_mmap_avl(mm);
fail_nomem:
flush_tlb_mm(current->mm);
return retval;
}
这里通过140-185行的for循环对同一用户空间中的各个区间进行复制。对于通过mmap映射到某个文件区间,155-169行是一些特殊的附加处理。172行的copy_page_range是关键所在,这个函数逐层处理页面目录项和页面表项。其代码如下:
sys_fork=>do_fork=>copy_mm=>dup_mmap=>copy_page_range
/*
* copy one vm_area from one task to the other. Assumes the page tables
* already present in the new task to be cleared in the whole range
* covered by this vma.
*
* 08Jan98 Merged into one routine from several inline routines to reduce
* variable count and make things faster. -jj
*/
int copy_page_range(struct mm_struct *dst, struct mm_struct *src,
struct vm_area_struct *vma)
{
pgd_t * src_pgd, * dst_pgd;
unsigned long address = vma->vm_start;
unsigned long end = vma->vm_end;
unsigned long cow = (vma->vm_flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
src_pgd = pgd_offset(src, address)-1;
dst_pgd = pgd_offset(dst, address)-1;
for (;;) {
pmd_t * src_pmd, * dst_pmd;
src_pgd++; dst_pgd++;
/* copy_pmd_range */
if (pgd_none(*src_pgd))
goto skip_copy_pmd_range;
if (pgd_bad(*src_pgd)) {
pgd_ERROR(*src_pgd);
pgd_clear(src_pgd);
skip_copy_pmd_range: address = (address + PGDIR_SIZE) & PGDIR_MASK;
if (!address || (address >= end))
goto out;
continue;
}
if (pgd_none(*dst_pgd)) {
if (!pmd_alloc(dst_pgd, 0))
goto nomem;
}
src_pmd = pmd_offset(src_pgd, address);
dst_pmd = pmd_offset(dst_pgd, address);
do {
pte_t * src_pte, * dst_pte;
/* copy_pte_range */
if (pmd_none(*src_pmd))
goto skip_copy_pte_range;
if (pmd_bad(*src_pmd)) {
pmd_ERROR(*src_pmd);
pmd_clear(src_pmd);
skip_copy_pte_range: address = (address + PMD_SIZE) & PMD_MASK;
if (address >= end)
goto out;
goto cont_copy_pmd_range;
}
if (pmd_none(*dst_pmd)) {
if (!pte_alloc(dst_pmd, 0))
goto nomem;
}
src_pte = pte_offset(src_pmd, address);
dst_pte = pte_offset(dst_pmd, address);
do {
pte_t pte = *src_pte;
struct page *ptepage;
/* copy_one_pte */
if (pte_none(pte))
goto cont_copy_pte_range_noset;
if (!pte_present(pte)) {
swap_duplicate(pte_to_swp_entry(pte));
goto cont_copy_pte_range;
}
ptepage = pte_page(pte);
if ((!VALID_PAGE(ptepage)) ||
PageReserved(ptepage))
goto cont_copy_pte_range;
/* If it's a COW mapping, write protect it both in the parent and the child */
if (cow) {
ptep_set_wrprotect(src_pte);
pte = *src_pte;
}
/* If it's a shared mapping, mark it clean in the child */
if (vma->vm_flags & VM_SHARED)
pte = pte_mkclean(pte);
pte = pte_mkold(pte);
get_page(ptepage);
cont_copy_pte_range: set_pte(dst_pte, pte);
cont_copy_pte_range_noset: address += PAGE_SIZE;
if (address >= end)
goto out;
src_pte++;
dst_pte++;
} while ((unsigned long)src_pte & PTE_TABLE_MASK);
cont_copy_pmd_range: src_pmd++;
dst_pmd++;
} while ((unsigned long)src_pmd & PMD_TABLE_MASK);
}
out:
return 0;
nomem:
return -ENOMEM;
}
代码中163行的for循环是对页面目录项的循环,188行的do循环是对中间目录项的循环,211行的do循环则是对页面表项的循环。我们把注意力集中在211-246行对页面表项的do-while循环。
循环中检查父进程一个页面表中的每个表项,根据表项的内容决定具体的操作。而表项的内容,则无非是下面对这么一些可能:
- 表项的内容为全0,所以pgd_none返回0。说明该页面的映射尚未建立,或者说是个空洞,因此不需要做任何事情。
- 表项的最低位,即_PAGE_PRESENT标志位为0,所以pte_present返回1。说明该页面映射已经建立,但是该页面尚不在内存中,被调离到交换设备上。此时此表项的内容表明盘上页面的地点,而现在该盘上页面多了一个用户,所以要通过swap_duplicate递增它的共享计数。然后,就转到cont_copy_pte_range将此表项复制到子进程的页面表中。
- 映射已经建立,但是物理页面不是一个有效的页面,所以VALID_PAGE返回0。读者可以回顾一下,我们以前讲过有些物理页面在外设接口卡上,相应的地址称为总线地址,而并不是内存页面。这样的页面、以及虽然是内存页面但由内核保留的页面,是不属于页面换入换出机制管辖的,实际上也不消耗动态分配的内存页面,所以也转到cont_copy_pte_range将此表项复制到子进程的页面表中。
- 需要从父进程复制的可写页面。本来,此时应该分配一个空闲的内存页面,再从父进程的页面把内容复制过来,并为之建立映射。显然,这个操作的代价是不小的。然而,对这么辛辛苦苦复制下来的页面,子进程是否一定会用呢?特别是会有写访问呢?如果只是读访问,则只要父进程从此不再写这个页面,就完全可以通过复制指针来共享这个页面。那不知要省事多少了。所以,linux内核采用了一种称为copy on write的技术,先通过复制页面表项暂时共享这个页面,到子进程(或父进程)真的要写这个页面时再次分配页面和复制。代码中的局部变量cow是前面158行定义的。变量名cow是copy on write的缩写。只要一个虚存区间的性质是可写(VM_MAYWRITE为1)而又不是共享(VM_SHARED为0),就属于copy on write区间。实际上,对于绝大多数的可写虚存区间,cow是1。在通过复制页面表项时共享一个页面表项时要做两件重要的事情,首先要在230-231行将父进程的页面表项改成写保护,然后在236行把已经改写保护的表项设置到子进程的页面表中。这样一来,相应的页面在两个进程中都变成只读了,当不管是父进程或子进程企图写入该页面时,都会引起一次页面异常。而页面异常处理程序对此的反应则是另行分配一个物理页面,并把内容真正地复制到新的物理页面中,让父子进程各自都有自己的物理页面,然后将两个页面表中相应的表项改成可写。所以,linux内核之所以可以很迅速地复制一个进程,完全依赖于copy on write(否则,在fork一个进程时就得要复制每一个物理页面了)。可是copy on write只有在父子进程各自拥有自己的页面表时才能实现。当CLONE_VM标志为1,因而父子进程通过指针共享用户空间时,copy on write 就用不上了。此时,父子进程是在真正意义上共享用户空间,父进程写入其用户空间的内容同时也写入子进程的用户空间。
- 父进程的只读页面。这种页面本来就不需要复制,因而可以复制页面表项共享物理页面。
可见,名为copy_page_range,实际上却连一个页面也没有真正地复制,这就是为什么linux内核能够很迅速地fork或clone一个进程的秘密。
回到copy_mm的代码中,函数copy_segments处理的是进程可能具有的局部段描述表LDT。我们在内存管理中讲过,只有在vm86模式中运行的进程才会有LDT,虽然我们并不关心vm86模式,但是有兴趣的读者也不妨自己看看它是怎样复制的。copy_segments的代码如下:
sys_fork=>do_fork=>copy_mm=>copy_segments
/*
* we do not have to muck with descriptors here, that is
* done in switch_mm() as needed.
*/
void copy_segments(struct task_struct *p, struct mm_struct *new_mm)
{
struct mm_struct * old_mm;
void *old_ldt, *ldt;
ldt = NULL;
old_mm = current->mm;
if (old_mm && (old_ldt = old_mm->context.segments) != NULL) {
/*
* Completely new LDT, we initialize it from the parent:
*/
ldt = vmalloc(LDT_ENTRIES*LDT_ENTRY_SIZE);
if (!ldt)
printk(KERN_WARNING "ldt allocation failed\n");
else
memcpy(ldt, old_ldt, LDT_ENTRIES*LDT_ENTRY_SIZE);
}
new_mm->context.segments = ldt;
}
回到copy_mm的代码。对于i386 CPU来说,copy_mm中339行处的init_new_context是个空语句。
当CPU从copy_mm回到do_fork中时,所有需要有条件复制的资源都已经处理完了。读者不妨回顾一下,当系统调用fork通过sys_fork进入do_fork时,其clone_flags为SIGCHLD,也就是说,所有的标志位均为0,所以copy_files、copy_fs、copy_mm、copy_sighand全部都真正执行了,这四项资源全部复制了。当然vfork经过sys_fork进入do_fork时,则其clone_flags为CLONE_VFORK | CLONE_VM | SIGCHLD,所以只执行了copy_files、copy_fs以及copy_sighand,而copy_mm,则因为标志位CLONE_VM为1,只是通过指针共享其父进程的mm_struct,并没有一份自己的副本,这也就是说,经vfork复制的是个线程,只能靠共享其父进程的存储空间度日,包括用户空间堆栈在内。至于clone,则取决于调用时的参数。当然,最终还是取决于父进程具有什么资源,要是父进程没有已打开文件,那么即使执行了copy_files,也还是空的。
回到do_fork的代码中,前面已通过alloc_task_struct分配了两个连续的页面,其低端用作task_struct结构,已经基本上复制好了;而用作系统空间堆栈的高端,却还没有复制,现在就由copy_thread来做这件事了,这个函数的代码如下:
sys_fork=>do_fork=>copy_thread
/*
* Save a segment.
*/
#define savesegment(seg,value) \
asm volatile("movl %%" #seg ",%0":"=m" (*(int *)&(value)))
int copy_thread(int nr, unsigned long clone_flags, unsigned long esp,
unsigned long unused,
struct task_struct * p, struct pt_regs * regs)
{
struct pt_regs * childregs;
childregs = ((struct pt_regs *) (THREAD_SIZE + (unsigned long) p)) - 1;
struct_cpy(childregs, regs);
childregs->eax = 0;
childregs->esp = esp;
p->thread.esp = (unsigned long) childregs;
p->thread.esp0 = (unsigned long) (childregs+1);
p->thread.eip = (unsigned long) ret_from_fork;
savesegment(fs,p->thread.fs);
savesegment(gs,p->thread.gs);
unlazy_fpu(current);
struct_cpy(&p->thread.i387, ¤t->thread.i387);
return 0;
}名为copy_thread,实际上却只是复制父进程的系统空间堆栈,堆栈中的内容说明了父进程从通过系统调用进入系统空间开始到进入copy_thread的来历,子进程将要循相同的路线返回,所以要把它复制给子进程。但是,如果子进程的系统空间堆栈与父进程的完全相同,那返回以后就无从区分谁是子进程了,所以复制以后要略作调整。这是一段有趣的程序,我们先来看535行。在中断系列博客中,读者已经看到当一个进程因系统调用或中断而进入内核时,其系统空间堆栈的顶部保存着CPU进入内核前夕各个寄存器的内容,并形成一个pt_regs数据结构。这里535行中的p为子进程的task_struct指针,指向两个连续物理页面的起始地址,而(THREAD_SIZE + (unsigned long) p)值指向这个两个页面的顶端。将其变换成struct pt_regs *,再从中减1,就指向了子进程系统空间堆栈中的pt_regs结构,如下图所示:
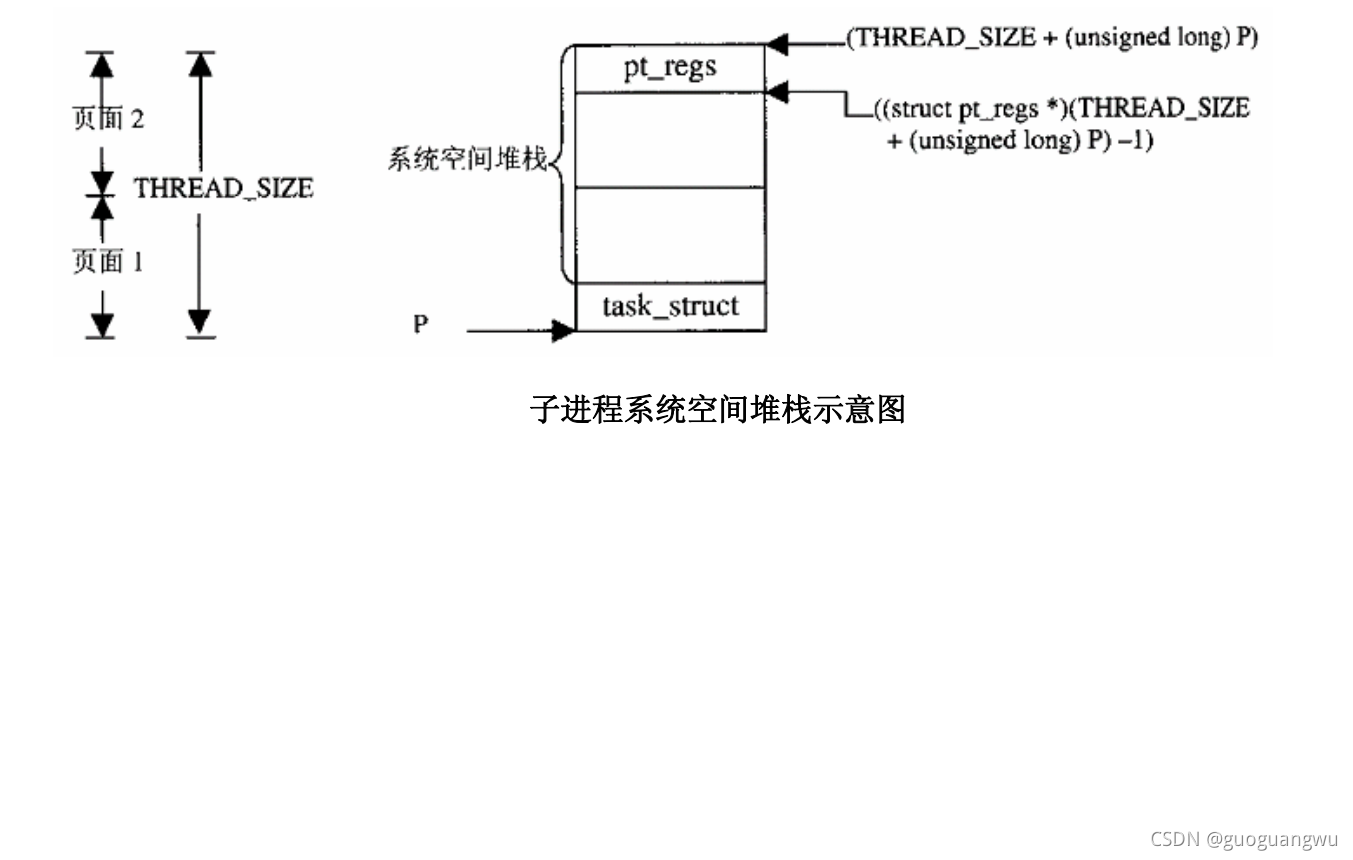
得到了指向子进程系统空间堆栈中pt_regs结构的指针childregs以后,就先将当前进程系统空间堆栈中的pt_regs结构复制过去,再来作少量的调整,什么样的调整呢?首先,将该结构中的eax置成0。当子进程受到调度而恢复运行,从系统调用返回时,这就是返回值。如前所述,子进程的返回值为0。其次,还要将结构中的esp置成这里的参数esp,它决定了进程在用户空间的堆栈位置,在clone调用中,这个参数是由调用者给定的。而在fork和vfork中,则来自调用do_fork前夕的regs.esp,所以实际上并没有改变,还是指向父进程原来的用户空间的堆栈。
在进程的task_struct结构中有个重要的成分thread,它本身是一个数据结构thread_struct,里面记录着进程在切换时的(系统空间)堆栈指针,其指令地址(也就是返回地址)等关键性的信息。在复制task_struct数据结构的时候,这些信息也原封不动地复制了过来。可是,子进程有自己的系统空间堆栈,所以也要相应加以调整。具体地说,540行将p->thread.esp设置成子进程系统空间堆栈中pt_regs结构的起始地址,就好像这个子进程以前曾经运行过,而在进入内核以后正要返回用户空间时被切换了一样。而p->thread.esp则应该指向子进程的系统空间堆栈的顶端。当一个进程被调度运行时,内核会将这个变量的值写入TSS的esp0字段,表示整个进程进入0级运行时其堆栈的位置。此外,p->thread.esp的值表示进程下一次被切换进入运行的切入点,类似于函数调用或中断的返回地址。将此地址设置成ret_from_fork,使创建的子进程在首次被调度运行时就从那儿开始,这一点以后在阅读有关进程切换的代码时还要讲到。545行和546行的savesegment是个宏操作其定义就在526行,所以,545行在gcc预处理以后就会变成
asm volatile("movl %%" #fs ",%0":"=m" (*(int *)&(p->thread.fs)))也就是把当前寄存器fs的值保存在p->thread.fs中。546行与此类似。548行和549行是为i387浮点数处理器而设的,那就不是我们所关心的了。
回到do_fork,再往下看:
sys_fork=>do_fork
/* Our parent execution domain becomes current domain
These must match for thread signalling to apply */
p->parent_exec_id = p->self_exec_id;
/* ok, now we should be set up.. */
p->swappable = 1;
p->exit_signal = clone_flags & CSIGNAL;
p->pdeath_signal = 0;
/*
* "share" dynamic priority between parent and child, thus the
* total amount of dynamic priorities in the system doesnt change,
* more scheduling fairness. This is only important in the first
* timeslice, on the long run the scheduling behaviour is unchanged.
*/
p->counter = (current->counter + 1) >> 1;
current->counter >>= 1;
if (!current->counter)
current->need_resched = 1;
/*
* Ok, add it to the run-queues and make it
* visible to the rest of the system.
*
* Let it rip!
*/
retval = p->pid;
p->tgid = retval;
INIT_LIST_HEAD(&p->thread_group);
write_lock_irq(&tasklist_lock);
if (clone_flags & CLONE_THREAD) {
p->tgid = current->tgid;
list_add(&p->thread_group, ¤t->thread_group);
}
SET_LINKS(p);
hash_pid(p);
nr_threads++;
write_unlock_irq(&tasklist_lock);
if (p->ptrace & PT_PTRACED)
send_sig(SIGSTOP, p, 1);
wake_up_process(p); /* do this last */
++total_forks;
fork_out:
if ((clone_flags & CLONE_VFORK) && (retval > 0))
down(&sem);
return retval;
代码中的parent_exec_id表示父进程的执行域,self_exec_id为本进程的执行域,swappable表示本进程的存储页面可以被换出,exit_signal为本进程执行exit时应向父进程发出的信号,pdeath_signal为要求父进程在执行exit时向本进程发送的信号。此外,task_struct结构中counter字段的值就是进程的运行时间配置,这里将父进程的时间配置分成两半,让父子进程各有原值的一半。如果创建的是线程,则还有通过task_struct结构中队列头thread_group与父进程链接起来,形成一个线程组。接着,就要让子进程进入的它的关系网了。先通过SET_LINKS(p)将子进程的task_struct结构链入内核的进程队列,然后又通过hash_pid将其链入按其pid计算得到的杂凑队列。有关这些队列的详情可参看"进程"以及"进程的调度与切换"两篇博客中的有关描述。最后,通过wake_up_process将子进程唤醒,也就是其挂入可执行队列等待调度。有关详情可参看"进程的睡眠与唤醒"博客。
至此,新进程的创建已经完成了,并且已经挂入了可运行进程队列接受调度,子进程与父进程在用户空间中具有相同的返回地址,然后才会因用户空间中程序的安排而分开。同时,由于当父进程(当前进程)从系统调用返回的前夕可能会接受调度,所以,到底谁会先返回到用户空间时不确定的。不过,一般而言,由于父子进程都适用相同的调度策略部,而父进程在可执行进程队列中排在子进程前面,所以父进程先运行的可能较大。
还有一种情况要考虑,当调用do_fork的参数中CLONE_VFORK标志位为1时,一定要保证让子进程先运行,一直到子进程通过系统调用execve执行一个新的可执行程序或通过系统调用exit退出系统时,才可以恢复父进程的运行,为什么呢?这要从用户空间的复制或共享这个问题说起,前面读者已经看到,在创建子进程时,对于父进程的用户空间可以通过复制父进程的mm_struct及其下属的各个vm_area_struct数据结构,再加上父进程的页面目录和页面表来继承,也可以简单地复制父进程的task_struct结构中指向其mm_struct结构的指针来共享。具体取决于CLONE_VM标志位的值。当CLONE_VM标志位为1,因而父子进程通过指针共享用户空间时,父子进程在真正的意义共享用户空间,父进程写入其用户空间的内容同时也写入子进程的用户空间,反之亦然。如果说,在这种情况下父子进程各自对其数据区的写入可能会引起问题的话,那么对堆栈区的写入可能是致命的了。而每次对子进程的调用都是对堆栈区的写入!由此可见,在这种情况下决不能让两个进程都回到用户空间并发地执行;否则,必须是两个进程最终都乱来一气或者因非法越界访问而死亡。解决的办法只能是扣留其中一个进程,而只让另一个进程回到用户空间,直到两个进程不再共享它们的用户空间或其中一个进程(必然是回到用户空间运行的那个进程)消亡为止。
所以,do_fork中的703行和704行在CLONE_VFORK标志位为1并且fork子进程成功的情况下,通过让当前进程(父进程)在一个信号量上执行一次down操作,已达到扣留父进程的目的,我们来看看其具体是怎样实现的。
首先,信号量sem是在函数开头的500行定义的一个局部变量(名曰DECLARE_MUTEX_LOCKED(sem),实际上为之分配了空间)
#define DECLARE_MUTEX(name) __DECLARE_SEMAPHORE_GENERIC(name,1)
#define DECLARE_MUTEX_LOCKED(name) __DECLARE_SEMAPHORE_GENERIC(name,0)
将DECLARE_MUTEX_LOCKED与DECLARE_MUTEX做一比较,可以看出正常情况下信号量中资源的数量为1,而现在这个信号量中资源的数量为0。当资源数量为1时,第一个执行down操作的进程进入临界区,而使资源数量变成了0,以后执行加down操作的进程会因为资源为0而被拒之门外进入睡眠,直到第一个进程归还资源离开临界区时才被唤醒,一直到某个进程往这个信号量中投入资源,也就是执行一次up操作时才会被唤醒。
那么,谁来投入资源呢?在"inux内核-系统调用execve()"博客中读者会看到,子进程在通过execve执行一个新的可执行程序时会做这件事。此外,子进程在通过exit退出消停时也会做这件事。这里还要指出,这个信号量是do_fork的一个局部变量,所以在父进程的系统空间堆栈中,而子进程在其task_struct结构有指向这个信号量的指针(即vfork_sem,见do_fork的第568行),既然父进程一直要睡眠到子进程使用这个信号量以后,信号量所在的空间就不会受到打扰,还应指出,CLONE_VM,要与CLONE_VFORK结合使用。否则就会发生前述的问题。除非在用户程序中采取了特殊的预防措施。
不管怎样,子进程的创建终于完成了,让我们祝福这新的生命!可见,如果子进程只具有与父进程相同的可执行程序和函数,只是父进程的影子,那又有什么意义呢?子进程必须走自己的路,这就是下一篇博客"linux内核-系统调用execve()"所要讲述的内容了。