单纯仅靠LLM会产生误导性的 “幻觉”,训练数据会过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。
正是在这样的背景下,检索增强生成技术(Retrieval-Augmented Generation,RAG)应时而生,成为大模型时代的一大趋势。
RAG通过在语言模型生成答案之前,先从广泛的专业文档数据库中检索相关信息,然后利用这些专业信息来引导大模型生成的结果,极大地提升了内容的准确性和相关性。
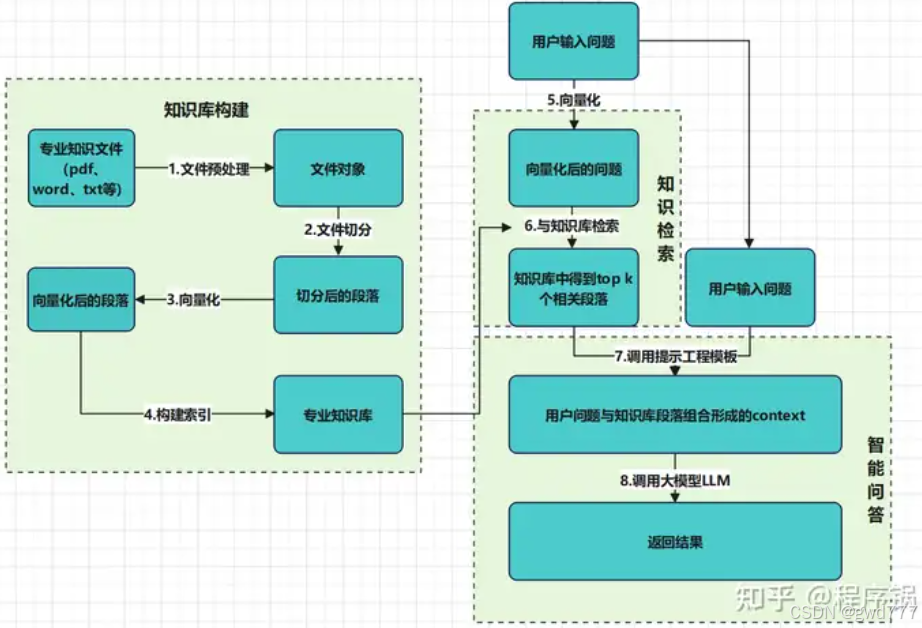
RAG整体技术路线可分为3大块8个小点见图1,其中包含知识库构建、知识检索和知识问答。
参考连接:
langchain框架轻松实现本地RAG_langchain实现rag-CSDN博客
https://www.zhihu.com/question/652674711/answer/3617998488
https://zhuanlan.zhihu.com/p/695287607
https://zhuanlan.zhihu.com/p/692327769
1,Linux 安装llamaFactory
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e '.[torch,metrics]'2, 安装Qwen2-7b-VL模型
pip install modelscope
modelscope download --model Qwen/Qwen2-VL-7B-Instruct --local_dir ./Qwen2-VL-7B-Instruct3,用llamaFactory启动Qwen2-7b-VL 【启动server端,端口8000】
# 启动黑框api
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \
--model_name_or_path /home/xxx/Qwen2-VL-7B-Instruct \
--template qwen2_vl \
--infer_backend huggingface \
--trust_remote_code true
# 后端运行,启动对话页面
nohup llamafactory-cli webchat \
--model_name_or_path /home/xxx/Qwen2-VL-2B-Instruct \
--template qwen2_vl \
--infer_backend huggingface \
--trust_remote_code true &4, 安装Embedding库
modelscope download --model BAAI/bge-large-zh --local_dir ./bge-large-zh5,自定义langchain Client代码【Client端,端口8000】;将搜集的文档放在目录langchain_dataset下
import os
from langchain_community.document_loaders import TextLoader
from langchain.prompts import ChatPromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.llms.base import LLM
from openai import OpenAI
import base64
from langchain.llms.utils import enforce_stop_tokens
from langchain_huggingface import HuggingFaceEmbeddings
# 定义LLM模型
class MyGame(LLM):
def __init__(self):
super().__init__()
print("construct MyGame")
def _llm_type(self) -> str:
return "MyGame"
def encode_image(self, image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def mygame_completion(self, message):
client = OpenAI(
api_key="0",
base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 8000)),
)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=message,
stream=False,
temperature=0.1
)
return response.choices[0].message.content
def _call(self, prompt, stop=None, image_path=None):
if image_path is None:
messages = [
{"role": "user", "content": prompt}
]
else:
base64_image = self.encode_image(image_path)
messages = [
{"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {"url":f"data:image/jpeg;base64,{base64_image}"},
}
]
}
]
response = self.mygame_completion(messages)
if stop is not None:
response = enforce_stop_tokens(response, stop)
return response
BGE_MODEL_PATH = "/home/xxx/bge-large-zh"
root_dir = "./langchain_dataset"
def extract_docs_from_directory(directory):
docs = [] # 初始化文档列表
for root, dirs, files in os.walk(directory): # 遍历目录
for file in files:
file_path = os.path.join(root, file) # 获取文件的完整路径
try:
loader = TextLoader(file_path) # 创建TextLoader实例
docs.extend(loader.load()) # 加载文件内容并追加到文档列表
except Exception as e:
print(f"Error loading file {file_path}: {e}") # 捕获并打印加载错误
return docs
docs = extract_docs_from_directory(root_dir)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=150, chunk_overlap=20)
documents = text_splitter.split_documents(docs)
huggingface_bge_embedding = HuggingFaceEmbeddings(model_name=BGE_MODEL_PATH)
vectorstore = Chroma.from_documents(documents, huggingface_bge_embedding, persist_directory="./vectorstore")
query="80cm是多少米."
result = vectorstore.similarity_search(query, k=3)
for doc in result:
print(doc.page_content)
print("********")
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question},请用中文输出答案。
"""
prompt = ChatPromptTemplate.from_template(template)
llm = MyGame()
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = chain.invoke(query)
print("RAG 输出结果:",response)
print("LLM 输出结果:",llm(query))6,图文测试代码
if __name__ == "__main__":
llm = MyGame() # 上面代码有定义
print(llm("这张图里的是什么。", image_path="E:\code_llm_workspace\static\images\\xxx.jpeg"))