一、激活函数
隐藏层:relu 、tanh
输出层:sigmoid、softmax
1、sigmoid
函数:torch.sigmoid
公式:
导数: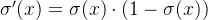
优点: 一般用于二分类的输出层;将任意实数输入映射到 (0, 1)之间,因此非常适合处理概率场景。
缺点:输入非常大或非常小时,Sigmoid函数的梯度会变得非常小,接近于0;涉及指数运算,更为复杂。
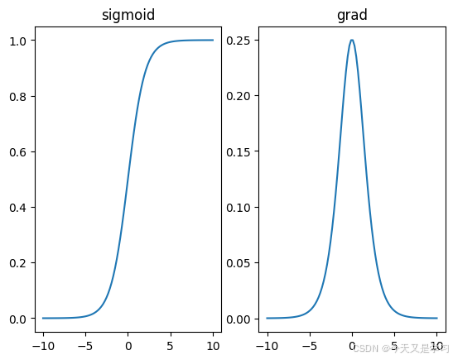
# sigmoid 常用于输出层,使用线性回归方法处理分类问题
import torch
import matplotlib.pyplot as plot
x = torch.linspace(-10,10,100, requires_grad=True)
y = torch.sigmoid(x)
_,ax = plot.subplots(1,2)
ax[0].plot(x.detach().numpy(),y.detach().numpy())
ax[0].set_title("sigmoid")
# 求导
y.sum().backward()
ax[1].plot(x.detach().numpy(),x.grad.detach().numpy())
ax[1].set_title("grad")
2、tanh
函数:torch.tanh
公式:
导数: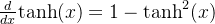
优点:输入映射到(-1, 1)之间,比sigmoid更快收敛;原点对称有助于数据平衡;非常适合于使用梯度下降法进行优化。常用于隐藏层
缺点:梯度问题只是简单优化了,并未处理;指数运算成本大
# tanh 用于隐藏层的激活函数,比sigmoid 更加平滑
import torch
import matplotlib.pyplot as plot
x = torch.linspace(-10,10,100, requires_grad=True)
y = torch.tanh(x)
_,ax = plot.subplots(1,2)
ax[0].plot(x.detach().numpy(),y.detach().numpy())
ax[0].set_title("tanh ")
# 求导
y.sum().backward()
ax[1].plot(x.detach().numpy(),x.grad.detach().numpy())
ax[1].set_title("grad")
3、relu 修正线性单元
函数:torch.relu
公式: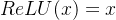
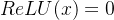
导数:大于0时为1,其余为0
优点:只需要对输入进行一次比较运算;正半区的导数恒为 1,在训练过程中可以更好地传播梯度,不存在饱和问题;输入小于等于 0 时输出为 0,这使得 ReLU 可以在神经网络中引入稀疏性,提升泛化能力。
缺点:输入小于等于0时,处理值为0,等于将这个神经元处死,累计过多后会降低模型表达能力。
# relu 过滤负数内容
import torch
import matplotlib.pyplot as plot
x = torch.linspace(-10,10,100, requires_grad=True)
y = torch.relu(x)
_,ax = plot.subplots(1,2)
ax[0].plot(x.detach().numpy(),y.detach().numpy())
ax[0].set_title("relu")
# 求导
y.sum().backward()
ax[1].plot(x.detach().numpy(),x.grad.detach().numpy())
ax[1].set_title("ygrad")

4、leaky_relu
ReLU 函数的改进,通过得负半区进行缩放解决死亡神经元的问题。
函数:torch.nn.functional.leaky_relu
公式: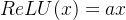
优点:在relu基础上避免死亡神经元过多
缺点:需要合适的系数,设置不当可能导致激活值过低
# leaky_relu 缩放负数内容
import torch
import matplotlib.pyplot as plot
x = torch.linspace(-10,10,100, requires_grad=True)
y = torch.nn.functional.leaky_relu(x,0.1)
_,ax = plot.subplots(1,2)
ax[0].plot(x.detach().numpy(),y.detach().numpy())
ax[0].set_title("leaky_relu ")
# 求导
y.sum().backward()
ax[1].plot(x.detach().numpy(),x.grad.detach().numpy())
ax[1].set_title("grad")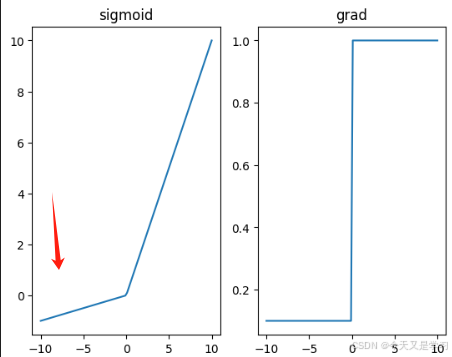
5、softmax
函数:torch.nn.Softmax
公式: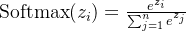
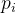
n表示总共类别数量;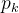
优点:输出转化为概率,进行分类决策,将概率最大的类别输出接近1,其余降低(和为1)用于多分类的输出层;与交叉熵损失函数组合使用。
缺点: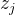
import torch
import torch.nn as nn
import matplotlib.pyplot as plot
# 表示4分类,每个样本全连接后得到4个得分,下面示例模拟的是两个样本的得分
x = torch.tensor([[-1.0, 2.0, -3.0, 4.0],
[-2, 3, -3, 9]]
, requires_grad=True)
y = nn.Softmax()(x) # 求每个输入值的指数值在每个样本指数值和的占比
_,ax = plot.subplots(1,2)
ax[0].plot(x.detach().numpy(),y.detach().numpy())
ax[0].set_title("Softmax")
# 求导
y.sum().backward()
print(x.grad)
ax[1].plot(x.detach().numpy(),x.grad.detach().numpy())
ax[1].set_title("grad")import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 表示4分类,每个样本全连接后得到4个得分,下面示例模拟的是两个样本的得分
x = torch.tensor([[-1.0, 2.0, -3.0, 4.0],
[-2, 3, -3, 9]],
requires_grad=True)
# 计算 Softmax
y = nn.Softmax()(x)
# 绘制输入 x 和输出 y 的关系
fig, ax = plt.subplots(1, 2)
print(range(y.shape[1]))
# 绘制 Softmax 输出
for i in range(y.shape[0]):
ax[0].plot(range(y.shape[1]), y[i].detach().numpy())
ax[0].set_title("Softmax 输出")
ax[0].legend()
# 求导
y.sum().backward()
# 绘制梯度
for i in range(x.shape[0]):
ax[1].plot(range(x.shape[1]), x.grad[i].detach().numpy())
ax[1].set_title("梯度")
ax[1].legend()
plt.show()
# 打印梯度
print("x.grad:\n", x.grad)二、损失函数
激活函数 softmax 对应 损失函数 CorssEntropyLoss ;
激活函数 sigmoid 对应 损失函数 BCELoss;
功能为线性回归时对应 MAE、MSE、smoothL1Loss
1、MAE损失 平均绝对误差
被称为 L1-Loss,通过对预测值和真实值之间的绝对差取平均值来衡量他们之间的差异。
函数:torch.nn.L1Loss
公式: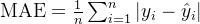
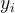
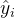
优点:对异常值更具鲁棒性(耐造),与输入数据相等单位度量,易于解释。
import torch
import torch.nn as nn
# 假设 y_true 是真实值, y_pred 是预测值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([4.5, 5.0, 2.0])
# 对应元素差值绝对值的平均值
loss = nn.L1Loss()(y_pred, y_true)
print(f'MAE Loss: {loss.item()}')
# MAE Loss: 0.66666668653488162、MSE损失 均方差
也叫L2Loss,通过对预测值和真实值之间的误差平方取平均值,来衡量预测值与真实值之间的差异。
函数:torch.nn.MSELoss 、 torch.nn.functional.smooth_l1_loss
公式: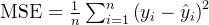
优点:对较大误差惩罚也大,对异常值敏感;是凸函数,存在全局最小值,有助于优化问题的求解。
import torch
import torch.nn as nn
# 假设 y_true 是真实值, y_pred 是预测值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([4.5, 5.0, 2.0])
# 对应元素差的平方的平均y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([4.5, 5.0, 2.0])
# MSELoss : 0.83333331346511843、SmoothL1Loss
将MAE和MSE综合,做到在损失较小时表现为 L2 损失,而在损失较大时表现为 L1 损失。
函数:torch.nn.SmoothL1Loss
公式: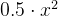
优点:平滑过渡,较大误差得到控制,不会过度敏感异常值,较小误差也存在优化效果区分;适用于目标检测任务中的边界框回归,如 Faster R-CNN 等算法中
# 平滑平均绝对误差损失函数
import torch
import torch.nn as nn
# 假设 y_true 是真实值, y_pred 是预测值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([4.5, 5.0, 2.0])
# 将对应元素差小于1的进行0.5*平方值
# 大于1的差的绝对值 -0.5
loss = nn.SmoothL1Loss()(y_pred, y_true)
print(f'SmoothL1Loss : {loss.item()}')
# SmoothL1Loss : 0.375
loss = nn.functional.smooth_l1_loss(y_pred, y_true)
print(f'smooth_l1_loss : {loss.item()}')
# smooth_l1_loss : 0.3754、CrossEntropyLoss 交叉熵损失函数
在输出层使用 softmax 激活函数进行多分类时,一般都采用交叉熵损失函数。
函数:torch.nn.CrossEntropyLoss
公式: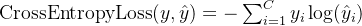
优点:与softmax结合,选取概率最大(也就是值对应最大的)节点,作为预测目标类别。
# 交叉熵损失函数
import torch
import torch.nn as nn
import math
# 假设 y_true 是真实值, y_pred 是预测值
y_pred = torch.tensor([[0.5, 0.3, 0.2],[0.3, 0.6, 0.1]])
y_true = torch.tensor([0,1])
# 计算MAE
loss = nn.CrossEntropyLoss()(y_pred, y_true)
# 等同于 Softmax 激活函数处理输入值 y_softmax = nn.Softmax()(y_pred)
# 目标元素值对应到预测值下标对应位置处理后数据取对数的负数 -math.log(0.3199),-math.log(0.2584))
print(f'CrossEntropyLoss : {loss.item()}')
# CrossEntropyLoss : 1.2465587854385376
5、BCELoss 二分类交叉熵损失函数
在输出层使用sigmoid激活函数进行二分类时使用。
函数:torch.nn.BCELoss
公式:
优点:与 sigmoid 结合,选取概率最大(也就是值对应最大的)节点,作为预测目标类别。
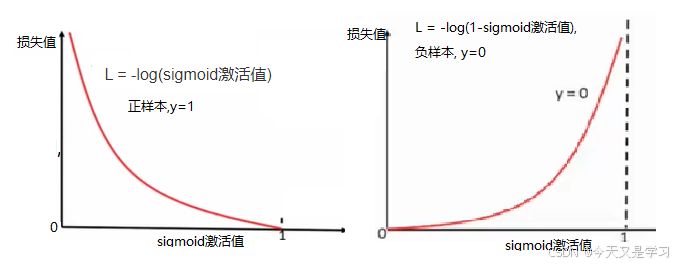
# 二分类交叉熵损失函数
import torch
import torch.nn as nn
# 假设 y_true 是真实值, y_pred 是预测值
y_pred = torch.tensor([[0.1], [0.2], [0.7]])
y_true = torch.tensor([[1.], [0.], [1.]])
# 计算MAE
loss = nn.BCELoss()(y_pred, y_true)
# 等同于 x= [(y_true[i] * math.log(y_pred[i])+(1-y_true[i])* math.log(1-y_pred[i])) for i in
range(len(y_pred))]
# print(sum(x)/3) 对每个值求平均
# 真实数据 乘以 对应位置的预测值的指数 加上 1-真实 * (1-预测值)的对数
print(f'BCELoss : {loss.item()}')
# BCELoss : 0.9608011841773987三、BP算法
误差反向传播算法(BP)的基本步骤:
-
前向传播:正向计算得到预测值。
-
计算损失:通过 损失函数 计算预测值和真实值的差距。
-
梯度计算:反向传播的核心;计算损失函数 对每个权重和偏置的梯度。
-
更新参数:使用梯度下降算法来更新每层的权重和偏置,使得损失逐渐减小。
-
迭代训练:将前向传播、梯度计算、参数更新的步骤重复多次,直到损失函数收敛或达到预定的停止条件。
1、前向传播
使用激活函数或损失函数求值的过程,用于预测或计算损失。
# 前向传播
import torch
# 输入值
i1 = 0.05
i2 = 0.10
# 输入层常数
b1 = 0.35
# 隐藏层常数
b2 = 0.60
def h1():
w1 = 0.15
w2 = 0.20
l1 = i1 * w1 +i2 * w2+ b1
return (1+torch.e**(-l1))**-1
print("h1的神经元输入结果:",h1())
def h2():
w3 = 0.25
w4 = 0.30
l2 = i1 * w3 +i2 * w4+ b1
return (1+torch.e**(-l2))**-1
print("h2的神经元输入结果:",h2())
# l 表示 函数关系
# h 表示 第一层激活函数处理数据
def o1():
w5 = 0.40
w6 = 0.45
l3 = h1()*w5 + h2()*w6 +b2
print("输出层神经元l3的结果:",l3)
return (1+torch.e**(-l3))**-1
print("输出层神经元o1的结果:",o1())
def o2():
w7 = 0.50
w8 = 0.55
l4 = h1()*w7 + h2()*w8 +b2
print("输出层神经元l4的结果:",l4)
return (1+torch.e**(-l4))**-1
print("输出层神经元o2的结果:",o2())
# l 表示 函数关系
# o 表示 第二层激活函数处理数据并输出
def mse():
return 0.5*(o1()-0.01)**2+(o2()-0.99)**2
loss = mse()
print("loss的结果:",loss)
2、反向传播
计算损失函数相对于每个参数的梯度来调整权重,使模型在训练数据上的表现逐渐优化。
利用链式求导法则对每一层进行求导,直到求出输入层 x 的导数,然后利用导数值进行梯度更新。
2.1、链式法则
# 链式求导
import torch
x = torch.tensor(1.)
w = torch.tensor(0.,requires_grad=True)
b = torch.tensor(0.,requires_grad=True)
fc1 = 1/(torch.exp(-1*x*w+b)+1) # 第一层函数
fc1.retain_grad() # 保留梯度
fc2 = 2*fc1+1 # 第二层函数 就等于 2* 1/(torch.exp(-1*x*w+b)+1) +1
fc2.backward() # 反向传播 ,在第二层求导
print(fc1.grad) # 第二层对第一层求导 将第一层看作一个变量求导(不管其内部结构)认为 2*x +1 求导
print(w.grad)
print(b.grad)
2.2、使用链式法则手动推导
# 反向传播 手动计算梯度
import torch
import torch.nn as nn
# 将前向传播数据导入
i1 = 0.05
i2 = 0.10
loss = torch.tensor(0.32193113434385046)
l3 = torch.tensor(1.10590596705977)
l4 = torch.tensor(1.2249214040964653)
o1 = torch.tensor(0.7513650695523157)
o2 = torch.tensor(0.7729284653214625)
h1 = torch.tensor(0.5932699921071872)
h2 = torch.tensor(0.596884378259767)
w1 = 0.15
w2 = 0.20
w3 = 0.25
w4 = 0.30
w5 = 0.40
w6 = 0.45
w7 = 0.50
w8 = 0.55
# 求 loss 对 w5 的求导
w5_grad = (o1 - 0.01) * (nn.functional.sigmoid(l3) *(1- nn.functional.sigmoid(l3))) * h1
print(w5_grad)
# 求 loss 对 w6 的求导
w6_grad = (o1 - 0.01) * (nn.functional.sigmoid(l3) *(1- nn.functional.sigmoid(l3))) * h2
print(w6_grad)
# 求 loss 对 w7 的求导
w7_grad = (o2 - 0.99) * (nn.functional.sigmoid(l4) *(1- nn.functional.sigmoid(l4))) * h1
print(w7_grad)
# 求 loss 对 w8 的求导
w8_grad = (o2 - 0.99) * (nn.functional.sigmoid(l4) *(1- nn.functional.sigmoid(l4))) * h2
print(w8_grad)
# 求 loss 对 w1 的求导
w1_grad = (o1 - 0.01) * (nn.functional.sigmoid(l3) *(1- nn.functional.sigmoid(l3))) * w5 * (nn.functional.sigmoid(h1) *(1- nn.functional.sigmoid(h1))) * i1 + (o2 - 0.99) * (nn.functional.sigmoid(l4) *(1- nn.functional.sigmoid(l4))) * w7 * (nn.functional.sigmoid(h1) *(1- nn.functional.sigmoid(h1)))* i1
print(w1_grad)
# 求 loss 对 w2 的求导
w2_grad = (o1 - 0.01) * (nn.functional.sigmoid(l3) *(1- nn.functional.sigmoid(l3))) * w5 * (nn.functional.sigmoid(h1) *(1- nn.functional.sigmoid(h1))) * i2 + (o2 - 0.99) * (nn.functional.sigmoid(l4) *(1- nn.functional.sigmoid(l4))) * w7 * (nn.functional.sigmoid(h1) *(1- nn.functional.sigmoid(h1)))* i2
print(w2_grad)
# 求 loss 对 w3 的求导
w3_grad = (o1 - 0.01) * (nn.functional.sigmoid(l3) *(1- nn.functional.sigmoid(l3))) * w6 * (nn.functional.sigmoid(h2) *(1- nn.functional.sigmoid(h2))) * i1 + (o2 - 0.99) * (nn.functional.sigmoid(l4) *(1- nn.functional.sigmoid(l4))) * w8 * (nn.functional.sigmoid(h2) *(1- nn.functional.sigmoid(h2))) * i1
print(w3_grad)
# 求 loss 对 w4 的求导
w4_grad = (o1 - 0.01) * (nn.functional.sigmoid(l3) *(1- nn.functional.sigmoid(l3))) * w6 * (nn.functional.sigmoid(h2) *(1- nn.functional.sigmoid(h2))) * i2 + (o2 - 0.99) * (nn.functional.sigmoid(l4) *(1- nn.functional.sigmoid(l4))) * w8 * (nn.functional.sigmoid(h2) *(1- nn.functional.sigmoid(h2))) * i2
print(w4_grad)
2.3、线性层组件优化
# 使用线性层组件创建模型
import torch
i = torch.tensor([[0.05,0.1]])
model1 = torch.nn.Linear(2,2)
model1.weight.data = torch.tensor([[0.15,0.20],
[0.25,0.30]])
model1.bias.data = torch.tensor([0.35,0.35])
l1_l2 = model1(i)
h1_h2 = torch.sigmoid(l1_l2)
model2 = torch.nn.Linear(2,2)
model2.weight.data = torch.tensor([[0.40,0.45],
[0.50,0.55]])
model2.bias.data = torch.tensor([0.60,0.60])
l3_l4 = model2(h1_h2)
o1_o2 = torch.sigmoid(l3_l4)
# 反向传播
o1_o2_true = torch.tensor([[0.01,0.99]])
loss = torch.nn.MSELoss()(o1_o2,o1_o2_true)
loss.backward()
print(model1.weight.grad)
print(model2.weight.grad)
2.4、标准写法
调用 torch.nn.Module ;标准写法就是通过 forward() 函数计算出所有中间变量,通过输入值调用model时自动前向传播;然后通过 backward() 函数计算出所有梯度。
第一种标准写法使用单独的线性层和激活函数处理。
第二种标准写法将线性层和激活函数放在一起 torch.nn.Sequential(线性层,激活函数) ,调用对象时,自动使用线性层和激活函数处理数据。
import torch
class mynet(torch.nn.Module):
def __init__(self):
super(mynet,self).__init__()
self.linear1=torch.nn.Linear(2,2)
self.linear2=torch.nn.Linear(2,2)
self.activation=torch.sigmoid
# 初始化参数
self.linear1.weight.data =torch.tensor([[0.15,0.20],[0.25,0.30]])
self.linear2.weight.data =torch.tensor([[0.40,0.45],[0.50,0.55]])
self.linear1.bias.data =torch.tensor([[0.35,0.35]])
self.linear2.bias.data =torch.tensor([[0.60,0.60]])
def forward(self,x):
x= self.linear1(x)
x= self.activation(x)
x= self.linear2(x)
x= self.activation(x)
return x
def train():
model=mynet()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
input = torch.tensor([[0.05,0.10]])
target = torch.tensor([[0.01,0.99]])
output = model(input)
loss = torch.nn.MSELoss()(output, target)
optimizer.zero_grad()
loss.backward()
print(model.linear1.weight.grad)
print(model.linear2.weight.grad)
optimizer.step()
train()import torch
class mynet(torch.nn.Module):
def __init__(self):
super(mynet,self).__init__()
self.hidde1 = torch.nn.Sequential(torch.nn.Linear(2,2),torch.nn.Sigmoid())
self.out = torch.nn.Sequential(torch.nn.Linear(2,2),torch.nn.Sigmoid())
# 初始化参数
self.hidde1[0].weight.data =torch.tensor([[0.15,0.20],[0.25,0.30]])
self.out[0].weight.data =torch.tensor([[0.40,0.45],[0.50,0.55]])
self.hidde1[0].bias.data =torch.tensor([[0.35,0.35]])
self.out[0].bias.data =torch.tensor([[0.60,0.60]])
def forward(self,x):
x= self.hidde1(x)
x= self.out(x)
return x
def train():
model=mynet()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
input = torch.tensor([[0.05,0.10]])
target = torch.tensor([[0.01,0.99]])
output = model(input)
loss = torch.nn.MSELoss()(output, target)
optimizer.zero_grad()
loss.backward()
print(model.hidde1[0].weight.grad)
print(model.out[0].weight.grad)
optimizer.step()
train()