这篇论文提出了一种新的深度学习哈希方法,称为“HashNet”。相比于传统的哈希方法,HashNet 使用了深度神经网络来学习数据的哈希表达,从而避免了传统哈希方法中需要手动设计特征的缺点。
HashNet 可以通过两个连续过程来训练。首先,使用一个双重损失函数来训练模型的特征提取和哈希表达能力。其中第一个损失函数是分类损失函数,用于有监督地训练模型的分类能力。第二个损失函数是哈希损失函数,用于有监督地训练模型的哈希表达能力。通过这两个损失函数的联合训练,可以在保证高分类准确率和哈希表达能力的同时,学习到一种高效的哈希函数。
接下来,在这个训练好的模型的基础上,使用自对接技术来进一步优化哈希表达。具体来说,通过将数据集分成单独的两部分,然后使用其中一部分的样本来训练模型,而使用另一部分的样本来验证哈希表达的效果。这个过程可以迭代多次,不断地优化模型,从而生成更加准确的哈希表示。
实验结果表明,HashNet 在多个数据集上具有优异的性能,不仅在哈希率较低时可以获得高精度,同时也可以在哈希率非常高时获得良好的性能。此外,HashNet 的训练和预测速度都非常快,具有很好的可扩展性。
总之,这篇论文提出了一种有效的深度学习哈希方法,并在多个数据集上进行了验证,证明了其在不同情况下的有效性和效率。这种方法对于提高大规模图像/视频检索和推荐等任务的效率和准确度具有重要意义。
摘要
学习哈希已经被广泛应用于大规模多媒体检索的近似最近邻搜索中,由于其计算效率和检索质量。深度学习哈希通过端到端表示学习和哈希编码来提高检索质量,最近受到越来越多的关注。由于优化具有符号激活功能的深度学习哈希方法存在病态梯度困难,现有方法需要首先学习连续表示,并在分离的二值化步骤中生成二进制哈希代码,这会导致严重降低检索质量。
现有哈希方法首先学习连续表示,并在分离的二值化步骤中生成二进制哈希代码,会导致严重降低检索质量的原因主要有两点:
损失函数的设计不合理。在传统的哈希方法中,二进制哈希码通常是通过阈值函数对连续向量进行二值化得到的。然而,在优化损失函数时,将连续向量和二值化哈希码的距离定义为损失函数值,往往不利于学习到有效的哈希码,因为它忽略了二值化的非凸性。
信息丢失。将连续向量经过二值化处理得到哈希码后,一些原本具有区分能力的信息将被丢失。这些信息包括向量之间的相对位置和方向等,而这些信息对于识别、分类和检索任务都是至关重要的。
由于上述原因,现有方法在生成二进制哈希码时往往不能充分利用原始数据的信息,导致对数据的表示和检索质量都有很大的影响。因此,HashNet提出了基于连续的哈希方法,并将二值化阶段嵌入到整个网络中,通过端到端的学习来实现高质量的哈希码生成。这一方法有效地解决了现有方法的问题,提高了哈希检索的准确率和效率。
本文介绍了HashNet,一种新颖的、具有收敛保证的基于连续法进行深度学习哈希架构,在失衡相似性数据中学习精确二进制哈希代码。关键思想是通过连续法攻击优化具有非平滑二元激活函数深层网络时存在的病态梯度问题,在训练期间从一个较容易处理的平滑激活函数网络开始,并使其逐渐演变直至最后回归为原始、难以优化、具有符号激活函数的深层网络。全面实验结果表明,HashNet能够生成精确的二进制哈希代码,并在标准基准测试中产生最先进的多媒体检索性能。
介绍
在大数据时代,大规模和高维媒体数据已经普及到搜索引擎和社交网络中。为了保证检索质量和计算效率,近似最近邻(ANN)搜索受到越来越多的关注。与传统的索引方法[21]并行的另一种有利解决方案是哈希方法[38],它将高维媒体数据转换为紧凑的二进制编码,并为相似的数据项生成类似的二进制编码。在本文中,我们将重点关注学习哈希方法[38],该方法构建依赖于数据的哈希编码方案以实现有效图像检索,在性能上比独立于数据的哈希方法如局部敏感哈希(LSH)[10]表现更好。
许多学习哈希方法已被提出来通过汉明排序紧凑二进制哈希代码来使 ANN 搜索变得高效。最近深度学习到 hash 方法 表明使用端对端学习特征表示和 Hash 编码可以更加有效地使用深度神经网络 进行非线性 Hash 函数自然编码 。这些深度学习哈希方法在许多基准测试中表现出最先进的性能。特别地,联合学习保持相似表示和控制将连续表示量化为二进制代码的量化误差 是关键。然而,这些深度学习到 Hash 方法的一个主要缺点是他们需要首先学习连续的深层表示,在分隔后进行符号阈值计算以生成哈希码。通过连续松弛来解决离散优化问题,即使用连续优化解决哈希码离散优化问题,所有这些方法本质上都是解决与哈希目标显著偏离的优化问题 ,因为它们不能在其优化过程中确切地学习二进制哈希码 。因此,现有的深度哈希方法可能无法生成紧凑二进制哈希码以实现高效相似性检索。
使端到端真正支持深度学习到 hash 有两个关键挑战。首先,在使用相似性保持学习时生成二进制 hash 码时,我们需要采用符号函数 h = sgn (z) 作为激活函数将深层表示转换为确切的二进制 hash 码;但是符号函数的梯度在所有非零输入时为零,这将使标准反向传播方法不可行。这被称为病态梯度问题,是通过反向传播[14]训练深度神经网络的主要困难。其次,在实际检索系统中相似性信息通常非常稀疏,即类似对数量远小于不同对数量。这将导致数据失衡问题,并使保持相似性的学习无效。
优化具有符号激活的深层网络仍然是一个未解决的问题,并且也是进行深度学习哈希所面临的关键挑战。本文提出了HashNet——一种新型架构来进行基于连续收敛保证方法、在特征学习和二进制哈希编码端到端框架下解决了病态梯度和数据失衡问题。具体来说,我们通过连续方法[1]来解决非光滑符号激活的深度网络的非凸优化中的病态梯度问题。该方法将原始函数平滑化,转换成一个更容易进行优化的不同问题,逐渐在训练过程中减少平滑量,从而得到一系列收敛于原始优化问题的最优解序列。我们还设计了一种新型加权配对交叉熵损失函数,用于学习不均衡相似性关系。
全面实验证明HashNet可以生成完全二进制哈希码,并且在标准数据集上获得了最先进的检索性能。
相关网络
现有的哈希学习方法可以分为两类:无监督哈希和监督哈希。我们建议读者参考[38]进行全面调查。 无监督哈希方法通过从未标记数据中训练学习哈希函数来将数据点编码为二进制代码。典型的学习准则包括重构误差最小化[33、12、16]和图形学习[39、26]等。虽然无监督方法更加通用,可以在没有语义标签或相关信息的情况下进行训练,但它们受到语义鸿沟困境 [35] 的影响,即高级语义描述对象与低级特征描述符不同。 监督方法可以合并语义标签或相关信息以减轻语义鸿沟并显著提高哈希质量。 典型的有监督方法包括二进制重构嵌入(BRE)[19]、最小损失哈希(MLH)[30]和海明距离度量学习 [31]. 带核函数的有监督散列(KSH)[25]通过最小化相似对之间的汉明距离并最大化不相似对之间的汉明距离生成散列代码。
由于深度卷积神经网络(CNN)[18、13]在许多计算机视觉任务中取得了突破性的表现,因此深度学习哈希近期受到关注。 CNNH [40]采用两阶段策略,第一阶段学习哈希代码,第二阶段学习一个深度网络将输入图像映射到哈希代码。 DNNH [20]通过同时进行特征学习和哈希编码管道改进了两阶段CNNH,从而可以在联合学习过程中优化表示和哈希代码。 DHN [44]通过交叉熵损失和量化损失进一步改进DNNH,这些损失同时保留成对相似性并控制量化误差。 DHN 在几个基准测试上获得最先进的性能。
然而,现有的深度学习哈希方法只能学习连续码g,并需要进行二值化后处理才能生成二进制码h。通过连续松弛,这些方法基本上解决了一个优化问题L(g),它与哈希目标L(h)明显偏离,因为它们无法在收敛后保持代码完全二进制。用Q(g,h)表示将连续码g量化为二进制码h时的量化误差函数。先前的方法通过两种方式控制量化误差:(a) 通过连续优化minL(g)+Q(g,h)[44,22]; (b) 通过对L(h)进行离散优化但对Q(g,h)进行连续优化来最小化min L(h)+ Q(g,h)(由于离散优化不能扩展到测试数据中所以采用连续优 化来实现对样本外数据的拓展)[24] 。然而,由于Q(g,h)不能被最小限度地减少到零,因此在连续和二进制代码之间存在很大差距。要直接优化min L(h),我们必须采用符号作为深层网络中的激活函数,在其中引入不适定梯度问题但可以生成完全二进制代码。本文是首次尝试使用延续方法学习符号激活的深度网络,它可以直接优化L(h)进行深度学习哈希。
3. HashNet
在相似性检索系统中,我们给定一个训练集N个点{xi}Ni=1,每个点都用D维特征向量表示xi∈RD。一些点对(xi, xj)提供了相似度标签sij,其中sij=1表示xi和xj是相似的,而sij=0则表示它们不相似。深度学习哈希的目标是从输入空间RD到汉明空间{-1, 1}K中使用深度神经网络学习非线性哈希函数f:x↦h∈{-1, 1}K,将每个点x编码成紧凑的K位二进制哈希码h=f(x),以便保留给定对S之间的相似信息。
在监督哈希中,可以根据数据点的语义标签或实际检索系统中通过点击反馈构建相似性集合S={sij}。为了解决端到端学习框架中存在的数据不平衡和病态梯度问题,在本文中提出了HashNet——一种通过延续进行深层次学习哈希的新型体系结构(如图所示)。
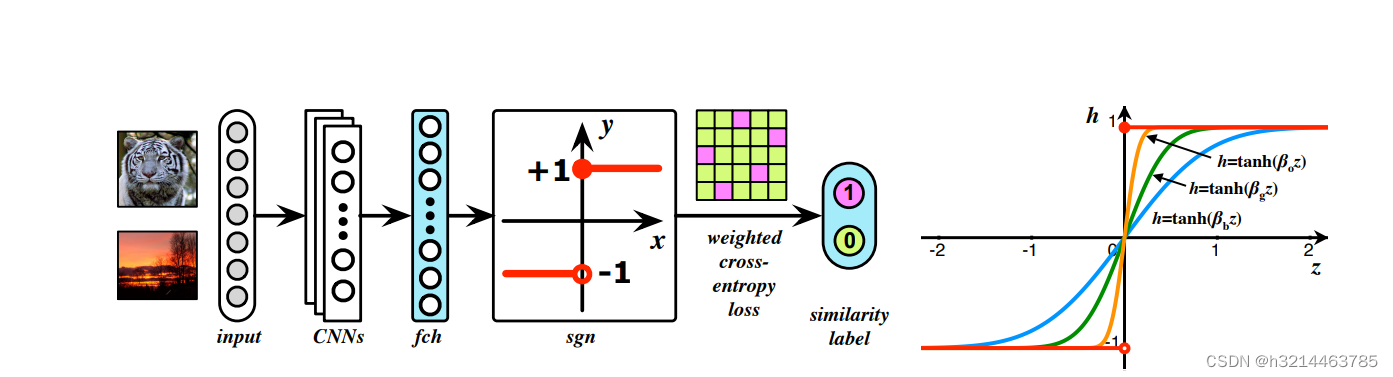
图1. (左)所提出的HashNet用于通过延续进行深度学习哈希,它由四个关键组件组成:(1)标准卷积神经网络(CNN),例如AlexNet和ResNet,用于学习深度图像表示,(2)完全连接的哈希层(fch)将深度表示转换为K维表示,(3)符号激活函数(sgn)将K维表达式二值化为K位二进制哈希码,以及(4)一种新颖的加权交叉熵损失函数,用于从稀疏数据中保持相似性的学习。 (右侧)平滑响应符号函数h = sgn (z) 的曲线图:红色是符号函数,蓝色、绿色和橙色显示了具有不同带宽βb < βg < βo 的功能h = tanh (βz)。其关键特性是limβ→∞tanh (βz)=sgn(z),最好使用彩色查看。 二进制哈希码hi ∈ {−1, 1} K,并且(4)一种新型加权交叉熵损失来自易失衡数据的相似保留学习。我们通过连续性攻击非平滑激活函数 h=sgn(z) 的不适定渐变问题,在训练过程中从平滑的激活函数y = tanh (βx) 开始,通过增加 β来使其更不平滑,直到最终回到原始、难以优化的符号激活函数。