卷积神经网络
卷积神经网络(convolutional neural network,CNN)是一类强大的、为处理图像数据而设计的神经网络。基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位,当今几乎所有的图像识别、 目标检测或语义分割相关的学术竞赛和商业应用都以这种方法为基础。
卷积出现的原因
基础神经网络的全连接层的缺点:
-
参数太多,手写识别数字的数据集中,使用28*28,就会有7840个权重,那要是有彩色的、更大的图片,就需要更多的权重,完全是浪费。
-
层数限制:一味的增加层数反倒可能不如一层效果好,因为没有提炼到图像的重点。
所以为了改善这些问题,为了提高准确率,加快训练速度,卷积出现了。
特点以及基本构成
特点
- Sparse Interaction(稀疏交互/局部视野):稀疏交互是指在卷积神经网络中,每个神经元仅与输入数据的局部区域进行交互。这意味着神经元只对输入数据的一小部分感知,并且仅与该部分进行连接。相比于全连接神经网络,这种稀疏交互的方式可以大大减少网络的参数数量,提高计算效率。同时,通过仅与局部区域进行交互,网络能够更加关注输入数据的局部特征,从而更好地捕捉到数据中的局部模式和结构。
- Parameter Sharing(参数共享):参数共享是指在卷积神经网络中,多个位置上的权重参数是共享的。具体来说,卷积核(滤波器)在应用于输入数据的不同位置时使用相同的权重。这种参数共享的方式使得网络可以提取出相同类型的特征,无论这些特征出现在输入数据的哪个位置。参数共享不仅可以减少模型的参数数量,还使得网络对平移不变性具有更好的处理能力。这意味着即使目标出现在输入数据中的不同位置,网络也能够学习到相同的特征表示。
- Equivariant Representations(等变表示):等变表示是指卷积神经网络能够保持输入数据的变换性质。具体来说,当 输入数据发生平移、旋转或其他几何变换时,网络的输出也会相应地发生相似的变换。这种等变性质使得网络能够更好地处理具有平移或旋转不变性的任务,如图像分类或物体检测通过使用卷积操作和参数共享,CNNs能够提取出与输入数据的几何变换相关的特征,并保持这些特征在不同位置的等变性质。
基本构成
基本组成包括输入层、隐藏层、输出层。而神经网络的特点在于隐藏层分为卷积层和池化层。
卷积层:通过在原始图像上平移来提取特征。
池化层:通过特征后稀疏参数来减少学习的参数,降低网络的复杂度
卷积层
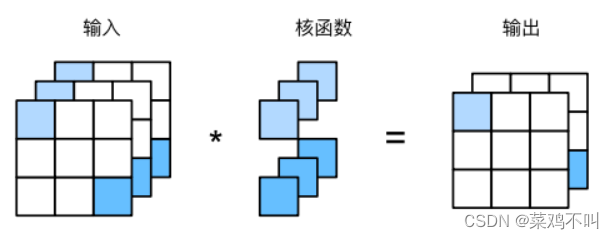
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。所以,卷积层中的两个被训 练的参数是卷积核权重和标量偏置。如下图,做了一个完整的卷积操作,可知卷积核大小为3*3,padding为1,stride为2.
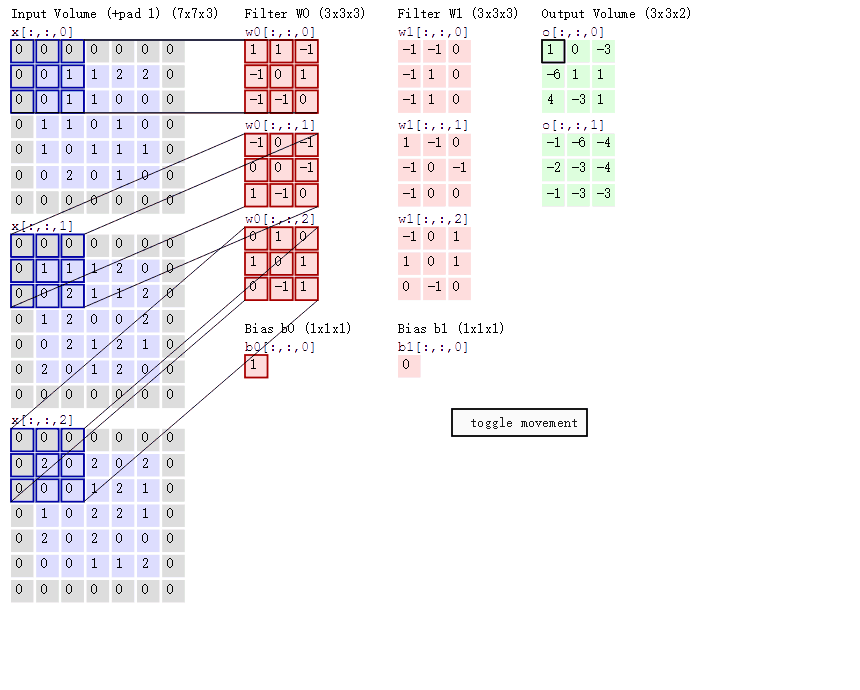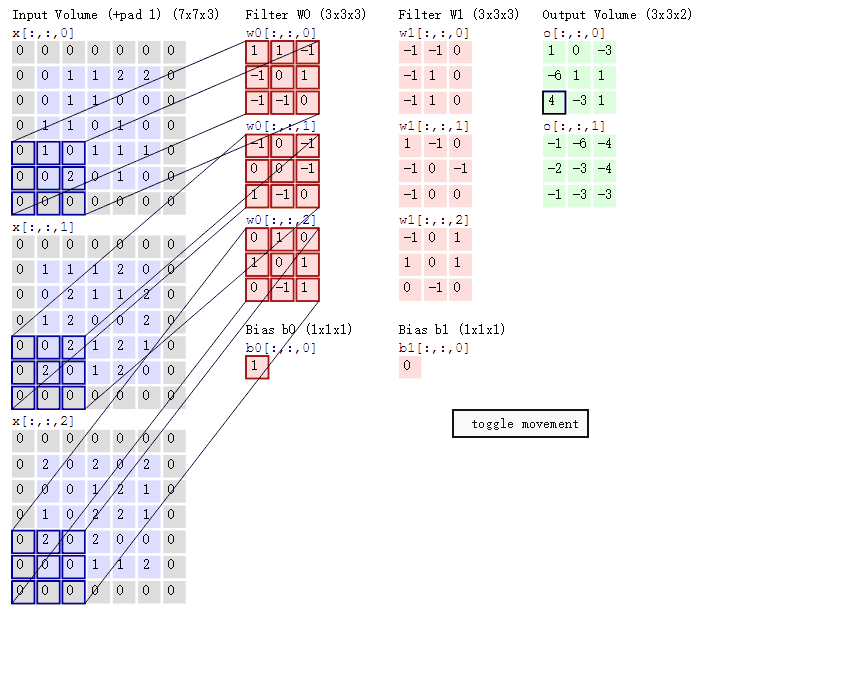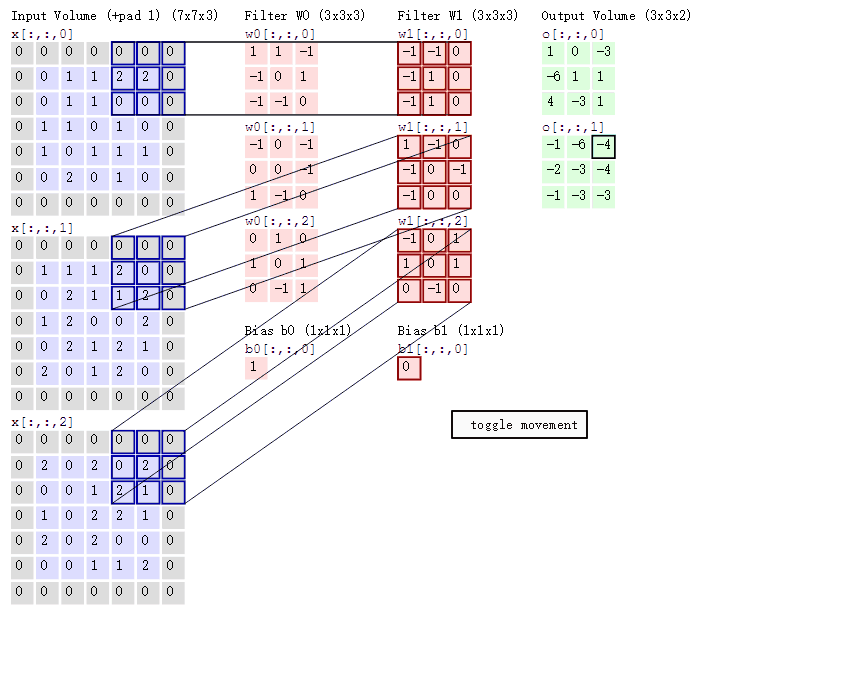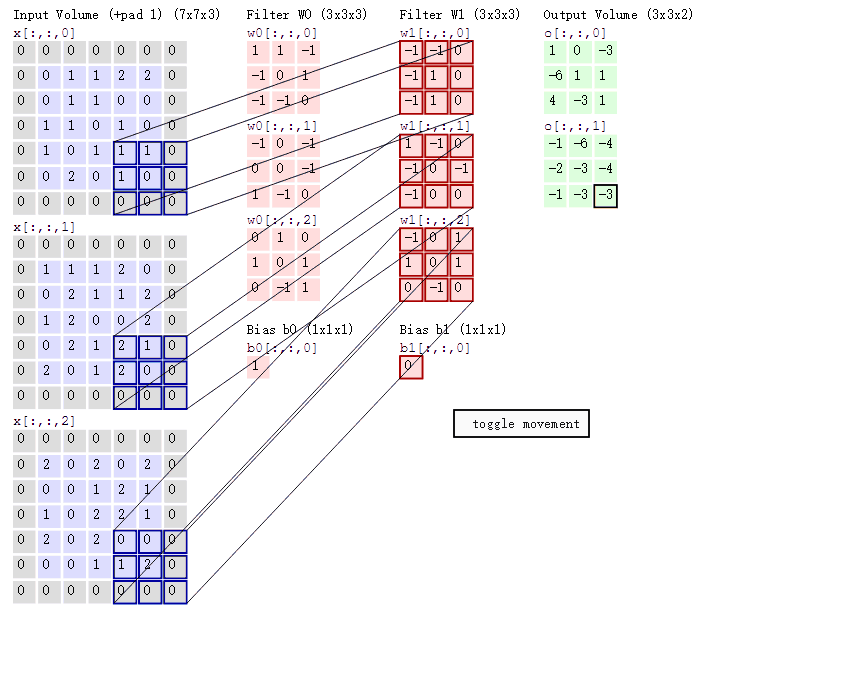
填充和步长的作用:
• 填充可以增加输出的高度和宽度。这常用来使输出与输入具有相同的高和宽。
• 步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的1/n(n是一个大于1的整数)。
• 填充和步幅可用于有效地调整数据的维度。
在卷积神经网络中的常用计算。

1X1卷积
- 1 × 1卷积层通常用于调整网络层的通道数量和控制模型复杂性。
1X1卷积使用了最小窗口,失去了卷积层的特有能力——在高度和宽度维度上,识别相邻元素间相互作用的能力。其实1 × 1卷积的唯一计算发生在通道上。
如上图可见,1X1卷积,采用了两个1X1X3的卷积核,输入为3X3X3,输出为3X3X2。仅修改了输入图像的通道数。
卷积神经网络的激活函数为RELU
为什么不用sigmoid函数呢?
1、采用sigmoid函数,反向传播求误差梯度时,计算量相对大,而采用Relu激活函数时,整个过程的计算量节省很多。
2、对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度爆炸的情况。
所以,综上,卷积神经网络用的是ReLu。
池化层
主要的作用是特征提取,通过去掉Feature Map中不重要的样本,进一步减少参数数量,使得计算资源耗费变少,也能有效控制过拟合。
包括 maximum pooling 和 average pooling。
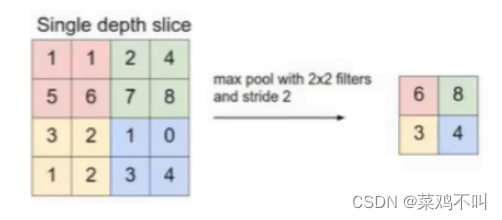
实例
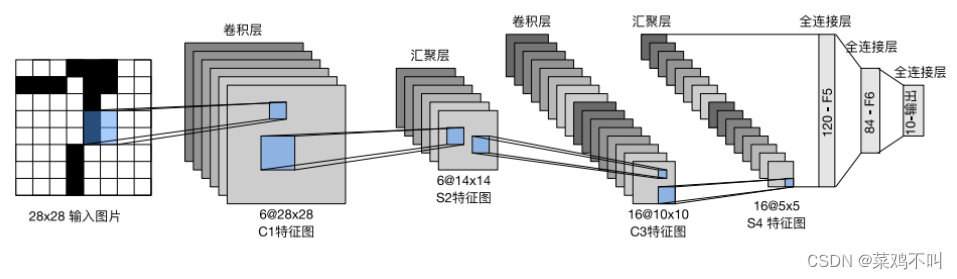
实现LeNet,LeNet‐5由两个卷积层组成和三个全连接层组成。
**每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层(average pooling)。**请注意,虽然ReLU和最大汇 聚层更有效,但它们在20世纪90年代还没有出现。每个卷积层使用5 × 5卷积核和一个sigmoid激活函数。这 些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷 积层有16个输出通道。每个2 × 2池操作(步幅2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
使用GPU加快训练.由于完整的数据集位于内存中,因此在模型使用GPU计算数据集之前,我们需要将其复制到显存中。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
函数学习
#卷积核K与原图像X做一次卷积---互相关操作
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
神经网络中view(),torch.flatten(),torch.nn.Flatten()
view()
其实就是把原先tensor中的数据进行排列,排成一行,然后根据所给的view()中的参数从一行中按顺序选择组成最终的tensor。
| view()的参数 | 作用 |
|---|---|
| h | 取值代表行数,当不知道要变为几行,但知道要变为几列时可取-1 |
| w | 取值代表列数,当不知道要变为几列,但知道要变为几行时可取-1 |
import torch
a=torch.Tensor([[[1,2,3],[4,5,6]]])
b=a.view(3,-1)
#a的结果:2行3列
tensor([[[1., 2., 3.],
[4., 5., 6.]]])
#b的结果:变为了3行2列
tensor([[1., 2.],
[3., 4.],
[5., 6.]])
torch.nn.Flatten()
torch.nn.Flatten(start_dim=1,end_dim=-1)
start_dim与end_dim代表合并的维度,开始的默认值为1,结束的默认值为-1,因此常被使用在神经网络当中,将每个batch的数据拉伸成一维。
import torch
a = torch.randn(8,3,64,64)
F = torch.nn.Flatten(1,2)
a1 = F(a)
a的大小:
torch.Size([8, 3, 64, 64])
a1的大小:
torch.Size([8, 192, 64])
将第一维到第二维拍成一维,其余不变
torch.flatten()
与 torch.nn.flatten 类似,都是用于展平 tensor 的,但是torch.flatten默认是从0开始的。
torch.flatten(t, start_dim=0, end_dim=-1)
t表示的时要展平的tensor,start_dim是开始展平的维度,end_dim是结束展平的维度
这里只举一个例子,其余与torch.nn.Flatten()是一样的。
import torch
a = torch.randn(8,3,64,64)
F = torch.flatten(a)
a的大小:
torch.Size([8, 3, 64, 64])
F的大小(默认从第0维展平):
torch.Size([98304])