 https://www.bilibili.com/video/BV1Q64y1s74K?p=2
https://www.bilibili.com/video/BV1Q64y1s74K?p=2
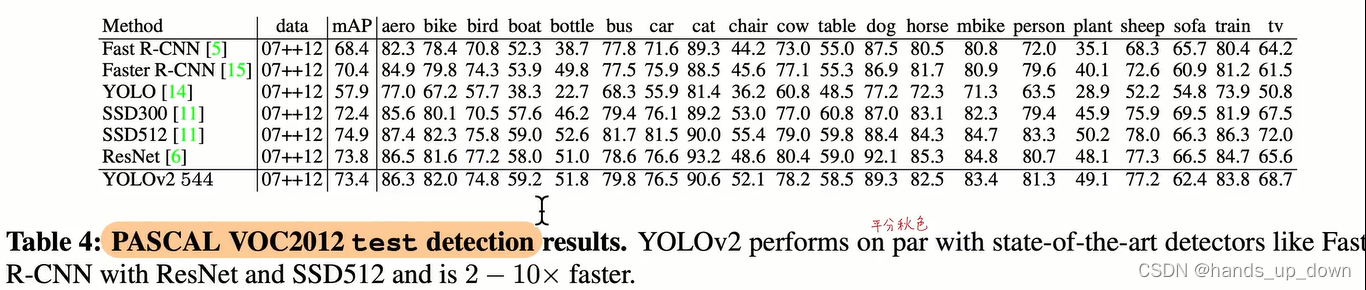
论文题目的意味就是相当明确的

目前我只知道在不同类型数据集上训练的网络结构是不同的

这里讲到imagenet检测数据集是一个弱监督数据集,包含的200个类别中只有44个是在训练阶段模型见过的。那么yolo2再这样一个超过75%的样本都是没有见过的数据集上还能取得19.7%的map
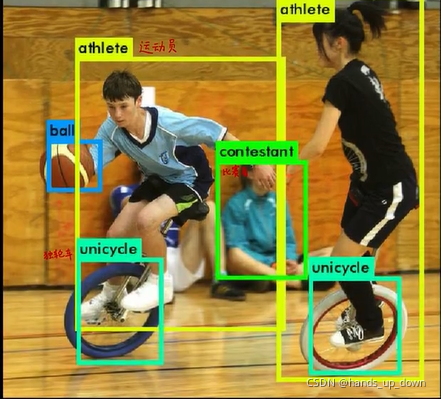
从实际效果来看,yolo2确实可以检测很多细粒度的类别


这里讲到当目标检测领域的困难,数据集是万万不够的。要想做某个领域的检测任务,就得自己去做检测框的标注。像目前,也就VOC数据集用的是最多的,20个类,2012好像是有80个类

yolo2为了扩大数据集,用了一种在分类数据集上的分层视角,用以融合不同的分类数据集。听起来还是很牛逼的。也就是上一篇文章提到的叫wordtree,将数据集结构化了

对啊,yolo2的网络结构是什么,似乎一直还没讲,相比yolo1的darknet8,darknet19的结构就没有那么好画了。我似乎是没有看到FC层了

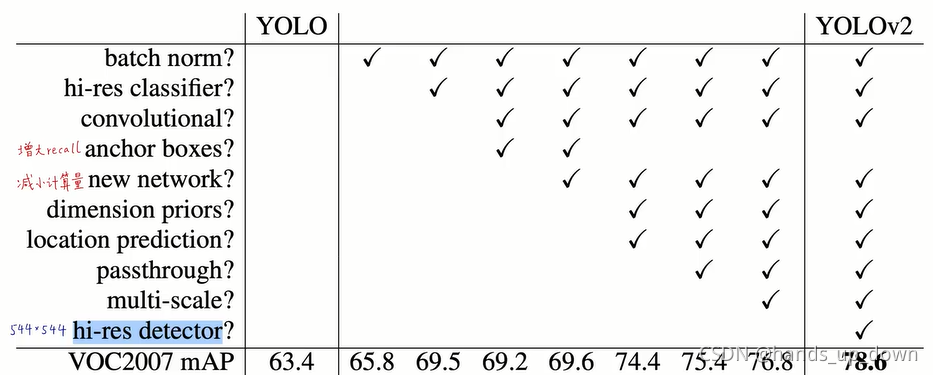
BETTER:更准确
回顾yolo1,我们可以很容易的想到几个缺点:
1.小目标和密集目标的识别能力比较差,包括分类和定位。子豪兄给的原因是,grid cell太少,这种划分方法最多只能检测49个类别。我认为原因还包括预测框的数量太少,在清理冗余的时候很多框会被清理掉
2.定位误差较大。预测框的尺寸不够精准
3.recall比较低。即将所有真实目标检出的能力比较差。可以说bounding box的数量比较少就导致对图像中目标的抓取能力不够。yolo2中的anchor机制极大的提升了recall,本质上是因为增加了检测框的数量
在确定yolo1的这些缺陷之后,yolo2的目标就旨在改善这些缺点
anchor机制,BN,细粒度特征passthrough,多尺度融合训练等
视觉领域的目标近些年在朝着更大、更深的网络发展,2016年的resnet有152层,当然随着网络变大变深,网络衰退又成了一个问题
yolo2的技术思路不是以扩大网络规模为导向,而是:

分类器和检测器都增加了分辨率
(1)BN层
在上一篇文章中,我们总结了BN的作用,一是提升训练速度,二是提升了准确度。

比如说为了防止模型过拟合,我们可以在loss function中加入一个项来做限制,这个项就可以叫正则项,加正则项的操作就叫正则化

上一篇提到,BN层和dropout层是不能协同工作的

BN层的γ和β是怎么训练的,他也要加入反向传播的链条吗??计算的时候能把他俩的计算融入到权重的迭代中吗??

在上一篇文章中,我基于卷积网络只是为了提取卷积特征这一点判断卷积网络不需要进行BN操作,但在网络结构上又存在BN
卷积网络中的BN操作如下:
如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数。 计算:对单通道,batchsize=m,卷积计算输出=pxq 对该通道中m×p×q个元素同时做批量归一化,使用相同的均值和方差
(2)high resolution classfier:高分辨率分类器

在yolo2之前的最先进的目标检测模型的分类器都是在imagenet数据集上预训练得到的,分辨率偏小
比如说常用的backbone alexnet,就是227*227的分类器
yolo1呢,是224*224的分类器,然后在定位的时候分辨率改成448*448的detector,检测器

yolo2就取消了这种切换,直接在大分辨率下训练10个epoch来得到大分辨率的分类器。这无疑会增加计算量

然后再做检测的训练
那由此是否可以判断,10个epoch之后我就能得到相当有用的分类器了,那我在训练自己的数据集的时候,可以将其作为一个重要的判断依据。比如总共训练50个epoch, 等训练10轮次之后,我就可以检测在分类器的效果


faster RCNN具体的预测是使用滑窗,对feature map的每一个位置生成9个anchor。这句话我看着是很懵逼的???滑窗我不熟悉
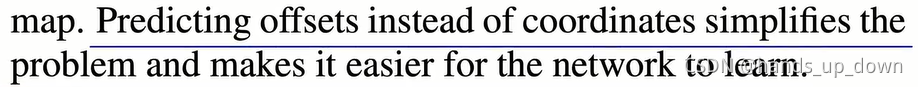
这里解释训练输出偏移量的原因是可以简化问题以及使网络更容易地进行学习
为什么呢???
我记得在yolo1中好像是直接输出中心坐标和宽高,在loss function中专门设计了项去收敛中心位置误差和宽高误差。按照我的理解,直接输出中心坐标,求中心坐标的误差也是很容易的吧,因为标注当中真实值都是直接给出的。这里不明白为什么???

这里还说使用anchor模块来做预测框,这要怎么做???
文章只是说去掉了一个池化层来使最终输出的feature map能有更高的分辨率
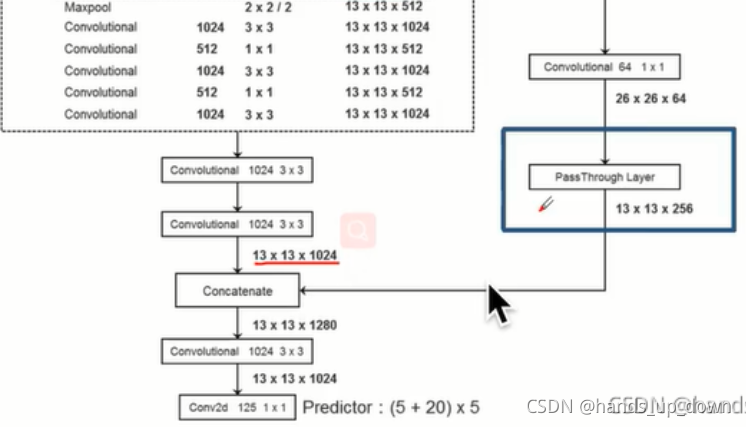
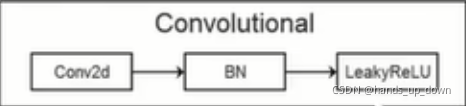
仔细看下来,convolutional和conv2d有什么区别吗??
图例上有解释:conv2d = convolutional + BN + leaky relu

使feature map的像素总数变成奇数????这是为什么啊???
取消了FC层之后,网络全部都是卷积网络,是否可以这样分区,用于提取特征的卷积网络以及用于分类和定位的卷积网络???
如果存在FC层,模仿yolo1的思路,输出应该是13*13*125

前文我提出了去掉FC层之后,如何进行分类和定位?
论文给出了解释,卷积网络最后输出一个13*13的feature map,这个feature map就相当于yolo1FC层那个7*7*30 = 1470维的最终输出。根据前面掌握的情况,可以估计这个feature map的通道数应该是125 = (20 + 5) * 5
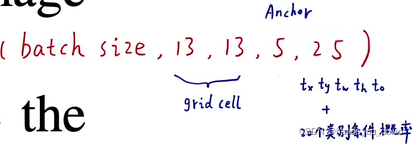
那yolo2的输入尺寸究竟是多少???
448*448还是416*416。再加上还有多尺度训练的问题。
说到多尺度训练,我之前的判断是包含FC层的,现在取消了FC层,是否可以直接进行多尺度训练???
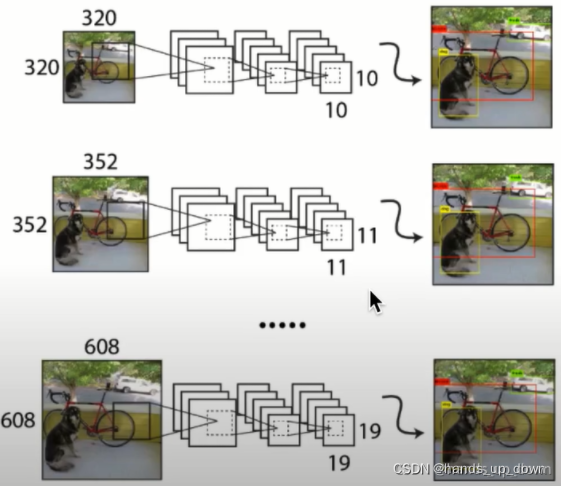
这张图给出的尺寸示例应该只是为了解释说明
仍然是不行。前文已经说明,卷积网络的输出尺寸已经固定了13*13*125,这就意味着不论输入的尺寸是多少,最终要保证与要求的输出尺寸匹配。因此我现在的判断是全局平均池化就不再是为了匹配FC层输入神经元的个数,而是为了满足设定好的卷积网络的输出尺寸
anchor box机制

objectness???应该是the objectness prediction,置信度不应该是confidence吗???
anchor box,可能是grid cell,每个grid cell都包含有5个anchor。这个判断是错误的的
anchor box对应的应该是bounding box,每个anchor反映到样本上就是一个框,估计就是这个原因交anchor box


和yolo1一样,输出结果中1*1*125维向量中包含的是条件类别概率,计算最终的类别概率的时候需要和IoU相乘

和之前说的一样,anchor机制在对精确度产生极小影响的同时却可以极大地增加recall,一方面是因为增加了预测框的数量,另一方面对于预测框的尺寸做了更为精准的设置
recall:真实目标被检测出的比例
precision:预测框中包含有目标的比例
(3)dimension cluster:维度或者尺寸聚类

论文给出了一个判断:更好的anchor可以使模型更容易训练
像yolo2参考的faster RCNN以及SSD,他们都是手工设置anchor尺寸。有一些固定的宽高比,我之前就觉得固定宽高比其实是一种退化,至少yolo1还能够适应各种尺寸的预测框,固定宽高比就好像是简单的缩放
但在实际的算法中,并没有采用固定宽高比的方案,而是以anchor box的尺寸为基准,中心位置需要做归一化,预测框的宽高和anchor的宽高服从exp函数,预测框的宽高比和anchor box的宽高比正相关

yolo2针对训练集做聚类来的到anchor box的尺寸
是否意味着当训练本地数据集的时候,最好在本地数据集上也做一次KNN???如果我们采用基于imagenet分类数据集的预训练权重,我们还是需要在本地数据集上做KNN吗???
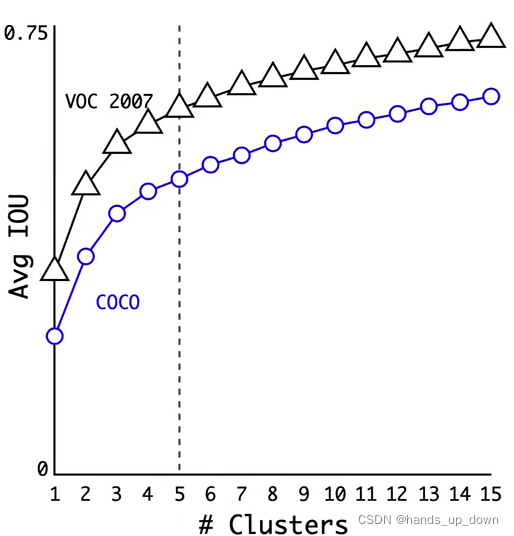
KNN需要人工指定k值,yolo2做了一系列实验来确定k值
在针对预测框的尺寸进行KNN的时候,欧氏距离是不合适的,yolo2采用聚类中心框和预测狂的IoU的方案来计算距离

在voc数据集上聚类的到的anchor有更多的高瘦框,这应该是数据集依赖的
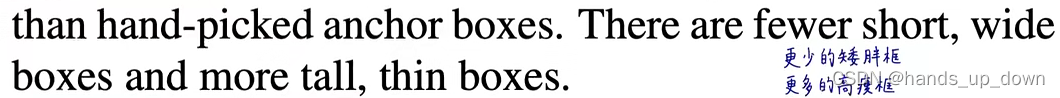
(4)direct location prediction:直接定位预测,要解决如何使用anchor的问题,之前也说了,利用的就是anchor的宽高,我们利用anchor的方法就决定了我们打算从样本中学到什么东西,比如说tx,ty,tw,th
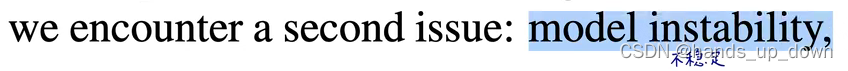
当yolo2加入anchor机制的时候,出现了新问题-模型不稳定,也就是预测框变得比较离谱,这是我们组自己训练的中间结果


yolo2遇到的大部分的不稳定来自于预测框的中心位置误差,我之前认为通过loss function应该可以解决这个问题
我上面的训练结果的问题来自于预测框宽高计算公式错误,有一个溢出问题

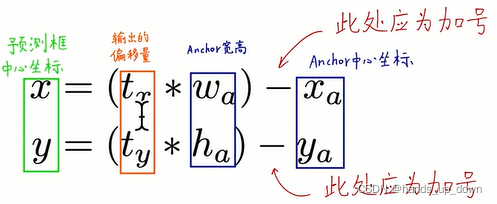
如果说偏移量tx = 1,就相当于预测框的中心点相对于anchor的中心坐标在x方向上移动了一个anchor宽度,就是说预测框中心点的移动是以anchor的宽或高为单位的
那么偏移量是以谁为基准呢???所属的grid cell的中心点??还是相应的anchor的中心点
faster RCNN并没有对tx,ty的值做限制,这就意味着属于某个grid cell的预测框是可以生成在全图的任何位置

那是不是我对yolo1预测框的理解就是不对的啊??似乎yolo1要求bounding box的中心点必须落在grid cell里边
yolo1在定位bbox的中心位置时也采用了偏移量的思路,但是论文指出因为模型是随机初始化的,需要相当长的时间才能稳定学到有意义的偏移量
这个相当长的时间是多少??在我们自己的训练中,或许是50个epoch

yolo2给出了新的预测框中心位置、宽高的计算公式
但这里的限制ground truth到0、1之间是什么意思??ground truth不是标注信息或者说标签值吗??是说将标注做归一化吗??那每个grid cell是不是也要做归一化啊??

对于每一个grid cell会预测5个bounding box,每个bounding box输出5个值
yolo1的每一个grid cell预测2个bounding box, 每个bounding box也是输出5个值,但是计算公式是不同的,而且yolo1要求bounding box的中心坐标必须在其所属的grid cell中

从这个公式来看,预测框的中心坐标被限定在了所属的grid cell里面。5个anchor box的中心点就是所属的grid cell的中心点,这个在之前的图例当中我们也是看到的

这里为什么要对t0做sigmoid激活呢???输出相当于被限定在了0、1之间
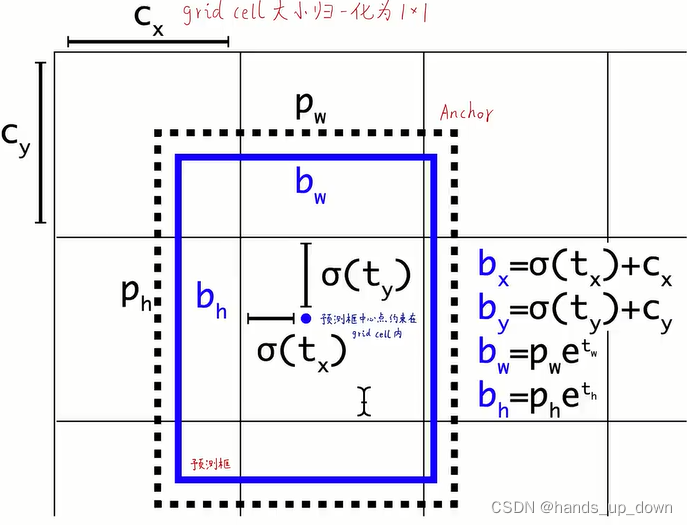
因为预测框的中心点被限制在了所属的grid cell里边,因此也就解决了之前说的模型不稳定、预测框全图乱窜的这种情况

这在yolo2采取的一系列新措施中算是最有效的改进
(5)fine grained features:细粒度特征


什么叫建议网络运行在不同的feature map上来得到一系列的分辨率???
分辨率这个概念和感受野分不开。我最开始的判断是这个分辨率是否就是滤波器的尺寸,但是从定义上来说感受野才是滤波器的尺寸,滤波器越大,感受野越大。这两者等价
在这里分辨率是一种属性,指标,是可以测算的,比如说在服饰识别上,如果网络可以提取到衣领、袖口这样的细节信息,或者说这样的细粒度的特征,我们可以说feature map的分辨率是高的。那为什么不说这个用于提取卷积特征的卷积网络的分辨率是高的呢???
我又突然想到是不是feature map的尺寸就是她的分辨率呢??如果是简单的于尺寸等价的话,是否意味着只要把feature map做大,模型的分辨率就会好??显然是不存在这样的关系的
比如说在yolo2,取消了FC层,要求卷积网络最后输出的feature map是13*13,channels是125
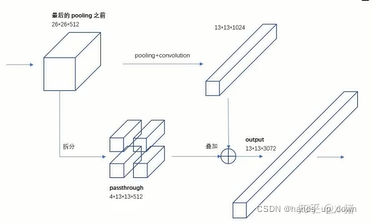
这个拆分我一直没太看懂,子豪兄说的是尺寸变为原来的1/4,通道数变为原来的4倍
可以这样理解:
1.拆分后的feature map每一份的分辨率是2*2 = 4
2.将原feature map的每个channel拆成4份
3.每次从原feature map的一个channel的一份中取一个数,总共是4个数组成一个新的feature map
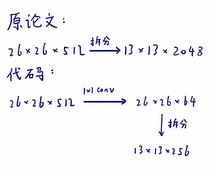
论文的操作和代码的操作是不同的
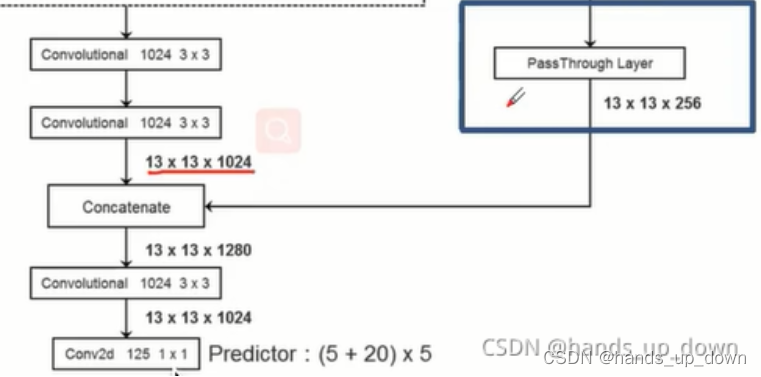
在论文里,要将26*26*512拆分成4*13*13*512
在代码里,显示通过1*1卷积降低了通道数,再进行拆分,得到13*13*256
(6)multi scale training:多尺度融合训练

加入anchor机制之后,yolo2将输入图像的尺寸改成了416*416
进行多尺度融合训练的原因在于让模型有更强的鲁棒性,他在训练过程中就适应了不同分辨率的图像,我们期待这样做能够让模型学习到更多的特征

yolo2不再固定输入图像的尺寸,而是隔几次迭代就改变网络。手动改??注意,迭代是以batch size为单位的。我最开始的猜想是以epoch为单位
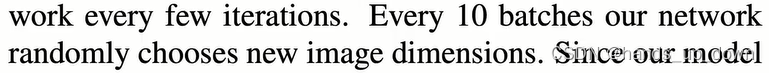
每10个batch就随即更换一次图像的尺寸
那对于我们这些没有大显存GPU的人来说,这一点真是太难了
该模型整体的设计是降采样32倍,而模型最终的输出是13*13
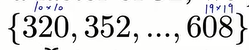
可选择额图像的尺寸都是32的倍数


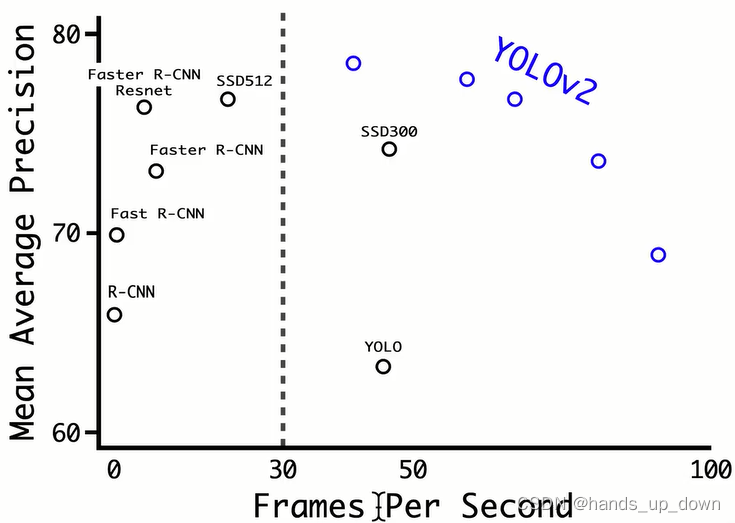
屠榜,诸神黄昏之图
multi scale training可以兼容多种输入尺度的原因之前已经写过,使用全局平均池化
前文中提到所有潜在的输入尺度都是32的倍数,那么最终的feature map的分辨率就是10*10到19*19.全局平均池化就忽略了分辨率的差别,而是由channel的个数来确定最终输出的维度。无论输入的尺度是多少,channel的个数都是512,那么全局平均池化的结果就是输出512个数
QUESTIONMARK:忽略feature map的分辨率,最终只输出和channel数同样数量的特征,这个丢失是不是太大了???
注意全局平均池化这个词,我估计是将一个channel的所有数值做一个均值处理,再将这512个均值输入到softmax里面
参考之前的Yolo1,输入FC的特征个数也不过是1470
如何让模型更快???



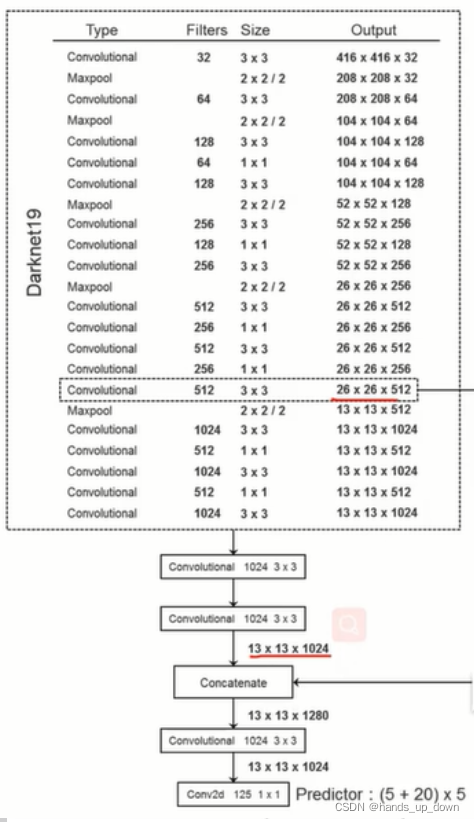
yolo2的backbone是darknet19,基于VGG-16修改的结果,常用的filter感受野是3*3,每次池化之后channel数翻倍

另外,提到了位于3*3卷积之间的1*1卷积

先用1*1卷积进行降维,再使用3*3卷积进行升维,这种结构现在被固定为bottleneck,瓶颈结构
之后使用BN层来稳定模型,加速训练,并且正则化模型。之前也已经解释过,正则化表示要在公式中增加约束项,核心的公式部分也就是loss function
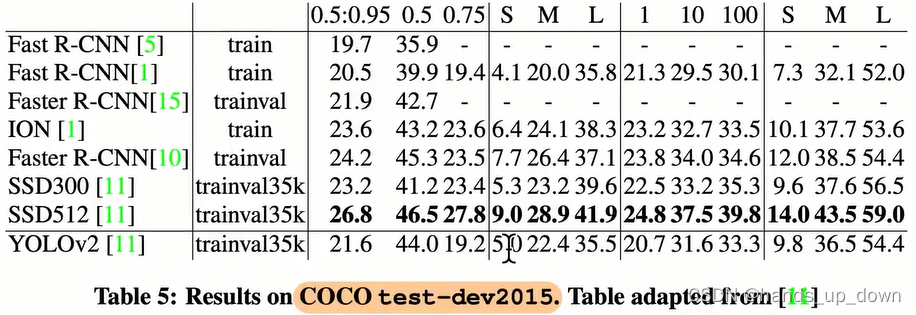
前面说过,yolo2相比于yolo1在浮点运算量上减少了37%,那么相对于作为backbone的VGG-16,浮点原算量只有它的1/6
下面是分类结构和定位结构,两者还是有明显的区别。所有我还没有理解abstract中所说的同时在分类数据集和定位数据集训练是什么意思????
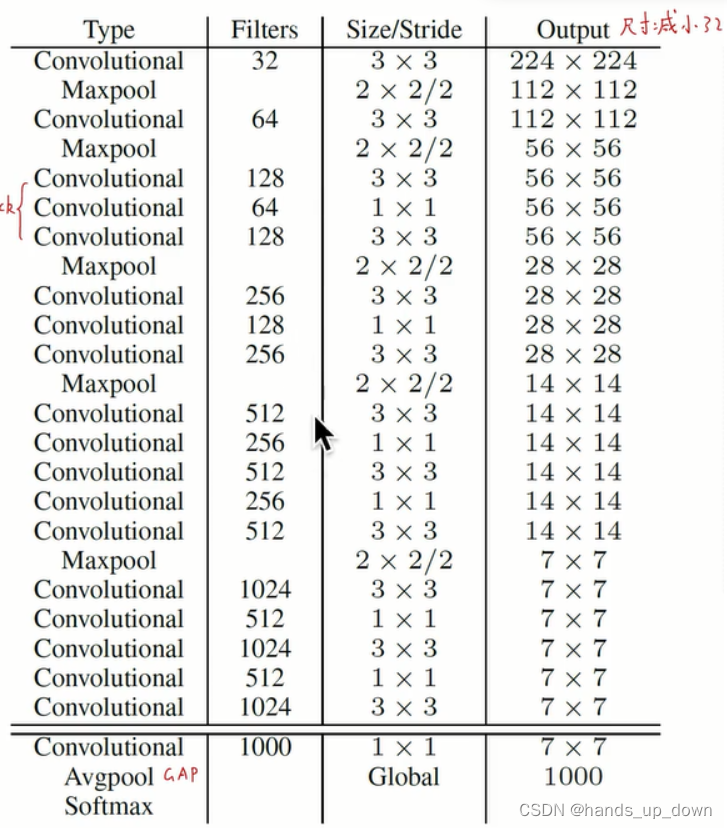
在分类结构的darknet19中,卷积层19个,池化层5个。我们可以看到两种bottleneck,一个三层的,一个5层的。
虽然表中给出了输出的尺寸,但因为模型兼容多尺度输入,其实给出的输出尺寸也就只有参考意义
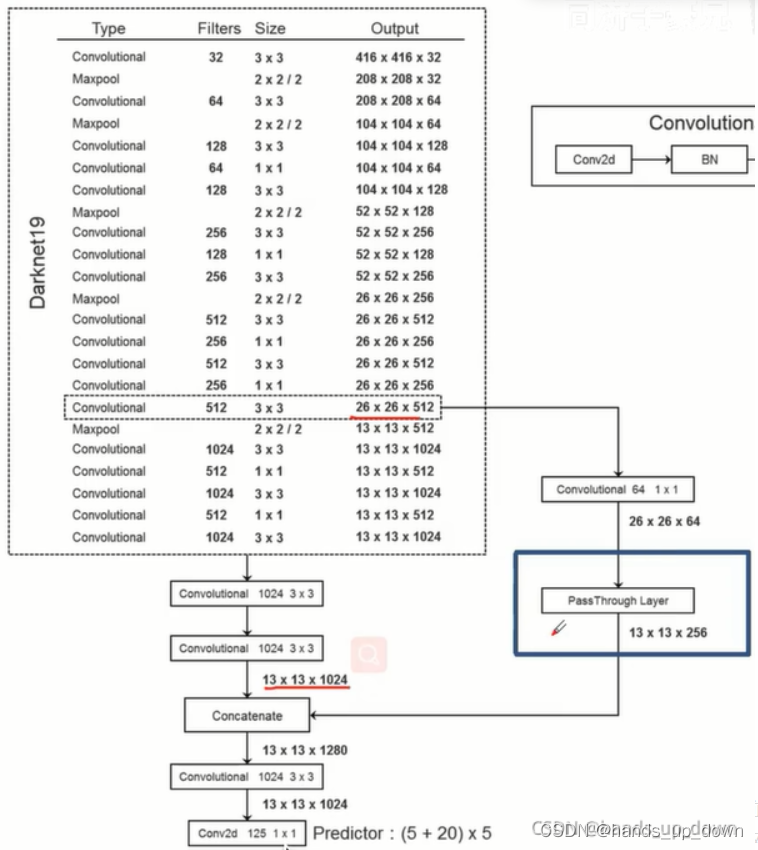
定位结构的darknet19中包含22个卷积层,最后一个卷积层只进行单纯的卷积,5个池化层,同样有两种结构的bottleneck

这里讲到分类训练的策略,没有提到是否使用预训练权重
我自己在训练的时候有这样的疑问,预训练权重是针对于改动之前的网络,预训练权重可以兼容改动之后的模型吗???实际操作上是可以的
所以,问题就变成了程序究竟是如何使用权重文件的???
总结yolo2的分类训练:
1.160个epoch
2.采用SGD
3.initial learning rate = 0.1,采用4次多项式进行学习率衰减,epoch越大,learning rate的衰减也是很严重
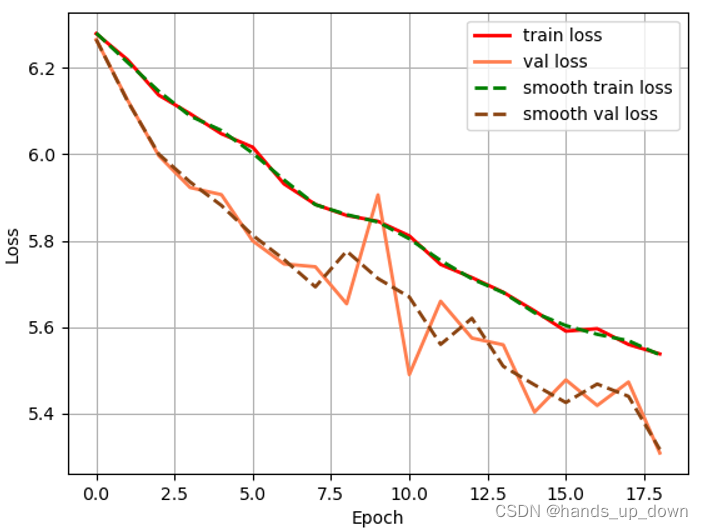
这个部分大概是从第27个epoch开始训练,在18个epoch中,loss只是从6.2降到5.4
4.对loss function进行L2正则,参数是万分之5
5.动量法优化参数为0.9

yolo2的训练仍然使用了数据增强,data augmentation.随即裁剪,旋转,HSV转换

这个地方没太理清训练的方法,主要是因为多尺度融合训练的问题。前面展示的分类网络的结构图可以看到,全局平均池化是放在分类网络的,定位网络是没有这个结构的
但是这里对训练过程的描述是说,初步的训练是在224*224的样本上完成的,然后在448*448的样本上做fine tune,但是只训练10个epoch,同时learning rate的初始值要改成千分之一
前面不是说分类得训练160个epoch吗????
而且是不是说明在实际操作中多尺度融合训练也就两个尺度,还是说剩下得那几十个epoch都是像前面说的每10个batch随机更换一次尺度
具体的操作是不是说:跟anchor类似,一个列表里面存好了预设得尺寸,选好新的尺寸之后,resize就行了
这是我们自己训练得中间结果,一张是50epoch得map,一张是100epoch得map



定位网络的训练:这里跟最初的猜测一致了,的确是要在中间修改网络。虽然从目标检测上yolo是一阶段的,一个网络得到所需的全部结构,但结构上或者说训练还是两阶段的,分类和定位各有一个结构

换掉了分类网络中最后一个卷积层,相反将其换成了3个卷积层,最后还有1个1*1卷积,这是一个纯粹卷积

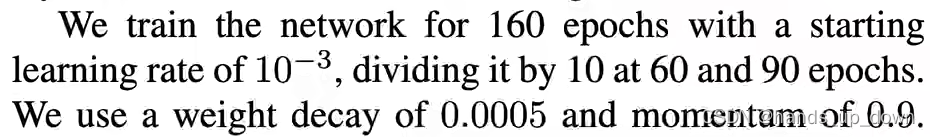
定位网络也要训练160个epoch,初始learning rate设为千分之一,分别咋10、60、90做衰减,按照某个四次多项式公式衰减
基本如此了,少年,去复现代码吧