4 Implementing a GPT model from Scratch To Generate Text
4.6 Coding the GPT model
-
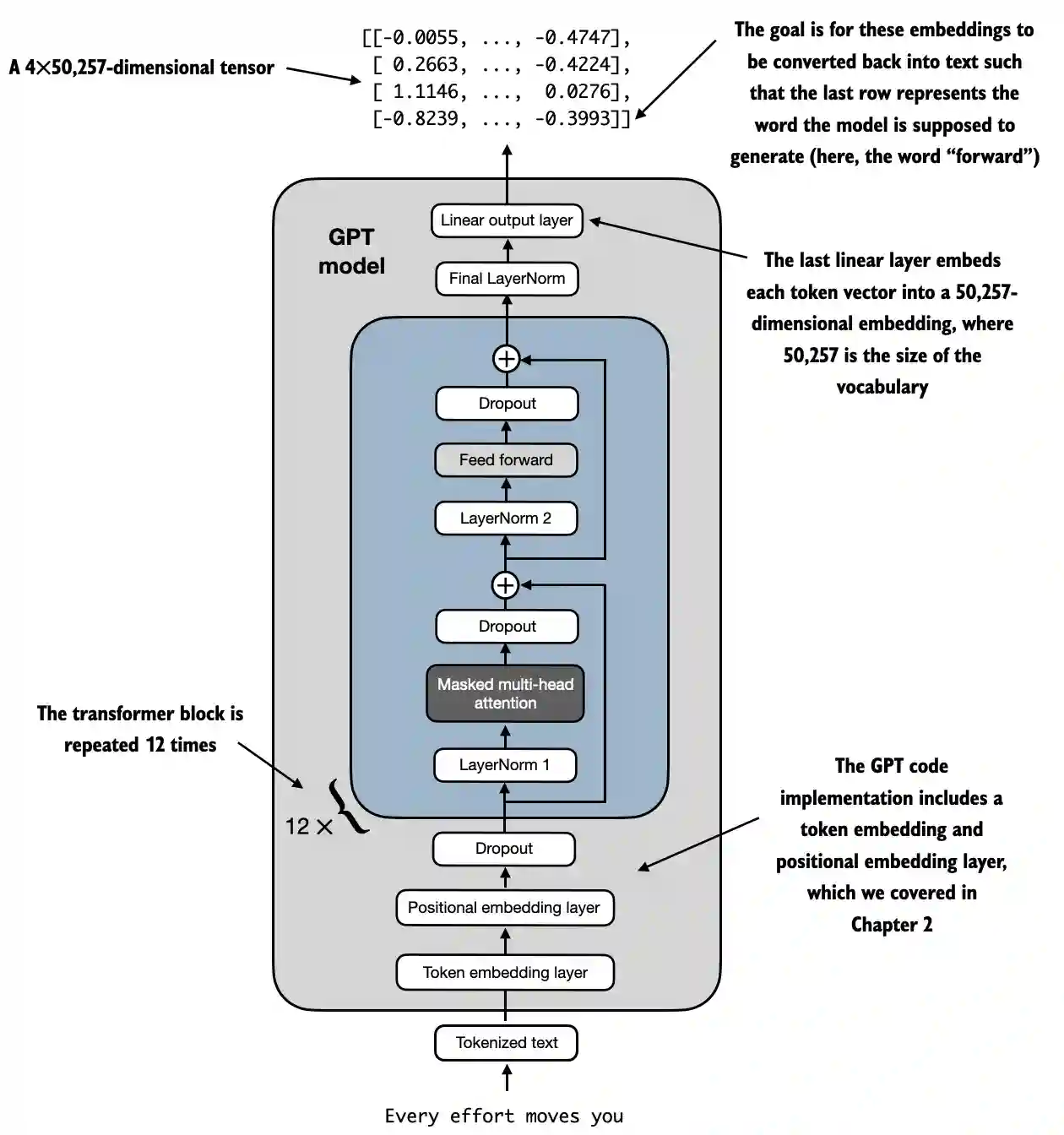
本章从宏观视角介绍了 DummyGPTModel,使用占位符表示其构建模块,随后用真实的 TransformerBlock 和 LayerNorm 类替换占位符,组装出完整的 1.24 亿参数 GPT-2 模型,并计划在后续章节进行预训练和加载 OpenAI 的预训练权重,同时通过下图 展示了结合本章所有概念的 GPT-2 整体结构。通过将变换器块插入到本章开头的架构中并重复 12 次(以 124M GPT-2 模型为例),我们构建了一个完整且可用的 GPT 架构。
从底部开始,tokenized text 首先被转换为 token embeddings,然后通过 positional embeddings 进行增强。这些信息组合成一个张量,随后通过一系列 transformer 块(如中心部分所示,每个块包含多头注意力机制和前馈神经网络层,并应用了 dropout 和层归一化),这些块堆叠在一起,重复 12 次,我们通过 GPT_CONFIG_124M 字典中的“n_layers”条目指定。(在拥有 15.42 亿个参数的最大 GPT-2 模型中,该transformer块重复了 36 次)。
-
上图架构的对应代码实现
class GPTModel(nn.Module): def __init__(self, cfg): super().__init__() self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"]) self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"]) self.drop_emb = nn.Dropout(cfg["drop_rate"]) # 创建 TransformerBlock 模块的顺序堆栈 self.trf_blocks = nn.Sequential( *[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]) self.final_norm = LayerNorm(cfg["emb_dim"]) # self.out_head = nn.Linear( cfg["emb_dim"], cfg["vocab_size"], bias=False ) def forward(self, in_idx): batch_size, seq_len = in_idx.shape tok_embeds = self.tok_emb(in_idx) pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device)) x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size] x = self.drop_emb(x) x = self.trf_blocks(x) x = self.final_norm(x) logits = self.out_head(x) return logits使用 124M 参数模型的配置,我们现在可以用随机初始权重实例化这个 GPT 模型
# 初始化实例化GPT模型 torch.manual_seed(123) tokenizer = tiktoken.get_encoding("gpt2") batch = [] txt1 = "Every effort moves you" txt2 = "Every day holds a" batch.append(torch.tensor(tokenizer.encode(txt1))) batch.append(torch.tensor(tokenizer.encode(txt2))) batch = torch.stack(batch, dim=0) print(batch) model = GPTModel(GPT_CONFIG_124M) out = model(batch) print("Input batch:\n", batch) print("\nOutput shape:", out.shape) print(out) """输出""" Input batch: tensor([[6109, 3626, 6100, 345], [6109, 1110, 6622, 257]]) Output shape: torch.Size([2, 4, 50257]) tensor([[[ 0.1381, 0.0077, -0.1963, ..., -0.0222, -0.1060, 0.1717], [ 0.3865, -0.8408, -0.6564, ..., -0.5163, 0.2369, -0.3357], [ 0.6989, -0.1829, -0.1631, ..., 0.1472, -0.6504, -0.0056], [-0.4290, 0.1669, -0.1258, ..., 1.1579, 0.5303, -0.5549]], [[ 0.1094, -0.2894, -0.1467, ..., -0.0557, 0.2911, -0.2824], [ 0.0882, -0.3552, -0.3527, ..., 1.2930, 0.0053, 0.1898], [ 0.6091, 0.4702, -0.4094, ..., 0.7688, 0.3787, -0.1974], [-0.0612, -0.0737, 0.4751, ..., 1.2463, -0.3834, 0.0609]]], grad_fn=<UnsafeViewBackward0>)如我们所见,输出张量的形状为 [2, 4, 50257],因为我们输入了 2 个文本,每个文本包含 4 个 token。最后一个维度 50,257 对应于 tokenizer 的词汇表大小。在下一节中,我们将了解如何将这些 50,257 维的输出向量转换回 token。
-
不过,关于其大小需要简要说明:我们之前将其称为 1.24 亿参数模型;我们可以通过以下方式再次确认这一数字:
使用 numel() 方法(“元素数量”的缩写),我们可以收集模型参数张量中的参数总数:
total_params = sum(p.numel() for p in model.parameters()) print(f"Total number of parameters: {total_params:,}") """输出""" Total number of parameters: 163,009,536模型参数数量为 163M 而非 124M,原因是未应用权重绑定(weight tying),即 GPT-2 中将token embedding层重用作输出层以减少参数;嵌入层将 50,257 维 one-hot 编码标记投影到 768 维嵌入表示,而输出层将其投影回 50,257 维以转换回单词,两者参数数量一致,需进一步验证模型参数数量为 124M。
print("Token embedding layer shape:", model.tok_emb.weight.shape) print("Output layer shape:", model.out_head.weight.shape) """输出""" Token embedding layer shape: torch.Size([50257, 768]) Output layer shape: torch.Size([50257, 768])相应地,如果我们减去输出层的参数数量,就会得到一个 124M 参数的模型:
total_params_gpt2 = total_params - sum(p.numel() for p in model.out_head.parameters()) print(f"Number of trainable parameters considering weight tying: {total_params_gpt2:,}") """输出""" Number of trainable parameters considering weight tying: 124,412,160即$ 163,009,536 - 50257*768 = 124412160$ ,该模型现在只有 1.24 亿个参数,与 GPT-2 模型的原始大小相匹配。
在实践中,不使用权重共享训练模型更为简便,因此本节未实现权重共享。后续章节将重新考虑权重共享,并在加载预训练权重时应用。此外,计算模型的内存需求也是一个重要的参考点。
-
计算模型内存需求# Calculate the total size in bytes (assuming float32, 4 bytes per parameter) total_size_bytes = total_params * 4 # Convert to megabytes total_size_mb = total_size_bytes / (1024 * 1024) print(f"Total size of the model: {total_size_mb:.2f} MB") """输出""" Total size of the model: 621.83 MB通过计算 GPTModel 对象中 1.63 亿参数的内存需求,并假设每个参数为 32 位浮点数,占用 4 字节,我们发现模型的总大小为 621.83 MB,这说明了即使是相对较小的 LLMs 也需要较大的存储空间。
-
在本节中,我们实现了 GPTModel 架构,并看到它输出了形状为 [batch_size, num_tokens, vocab_size] 的数值张量。
在下一节中,我们将编写代码将这些输出张量转换为文本。## Coding the GPT model -
本章从宏观视角介绍了 DummyGPTModel,使用占位符表示其构建模块,随后用真实的 TransformerBlock 和 LayerNorm 类替换占位符,组装出完整的 1.24 亿参数 GPT-2 模型,并计划在后续章节进行预训练和加载 OpenAI 的预训练权重,同时通过下图 展示了结合本章所有概念的 GPT-2 整体结构。通过将变换器块插入到本章开头的架构中并重复 12 次(以 124M GPT-2 模型为例),我们构建了一个完整且可用的 GPT 架构。
从底部开始,tokenized text 首先被转换为 token embeddings,然后通过 positional embeddings 进行增强。这些信息组合成一个张量,随后通过一系列 transformer 块(如中心部分所示,每个块包含多头注意力机制和前馈神经网络层,并应用了 dropout 和层归一化),这些块堆叠在一起,重复 12 次,我们通过 GPT_CONFIG_124M 字典中的“n_layers”条目指定。(在拥有 15.42 亿个参数的最大 GPT-2 模型中,该transformer块重复了 36 次)。
-
上图架构的对应代码实现
class GPTModel(nn.Module): def __init__(self, cfg): super().__init__() self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"]) self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"]) self.drop_emb = nn.Dropout(cfg["drop_rate"]) # 创建 TransformerBlock 模块的顺序堆栈 self.trf_blocks = nn.Sequential( *[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]) self.final_norm = LayerNorm(cfg["emb_dim"]) # self.out_head = nn.Linear( cfg["emb_dim"], cfg["vocab_size"], bias=False ) def forward(self, in_idx): batch_size, seq_len = in_idx.shape tok_embeds = self.tok_emb(in_idx) pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device)) x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size] x = self.drop_emb(x) x = self.trf_blocks(x) x = self.final_norm(x) logits = self.out_head(x) return logits使用 124M 参数模型的配置,我们现在可以用随机初始权重实例化这个 GPT 模型
# 初始化实例化GPT模型 torch.manual_seed(123) tokenizer = tiktoken.get_encoding("gpt2") batch = [] txt1 = "Every effort moves you" txt2 = "Every day holds a" batch.append(torch.tensor(tokenizer.encode(txt1))) batch.append(torch.tensor(tokenizer.encode(txt2))) batch = torch.stack(batch, dim=0) print(batch) model = GPTModel(GPT_CONFIG_124M) out = model(batch) print("Input batch:\n", batch) print("\nOutput shape:", out.shape) print(out) """输出""" Input batch: tensor([[6109, 3626, 6100, 345], [6109, 1110, 6622, 257]]) Output shape: torch.Size([2, 4, 50257]) tensor([[[ 0.1381, 0.0077, -0.1963, ..., -0.0222, -0.1060, 0.1717], [ 0.3865, -0.8408, -0.6564, ..., -0.5163, 0.2369, -0.3357], [ 0.6989, -0.1829, -0.1631, ..., 0.1472, -0.6504, -0.0056], [-0.4290, 0.1669, -0.1258, ..., 1.1579, 0.5303, -0.5549]], [[ 0.1094, -0.2894, -0.1467, ..., -0.0557, 0.2911, -0.2824], [ 0.0882, -0.3552, -0.3527, ..., 1.2930, 0.0053, 0.1898], [ 0.6091, 0.4702, -0.4094, ..., 0.7688, 0.3787, -0.1974], [-0.0612, -0.0737, 0.4751, ..., 1.2463, -0.3834, 0.0609]]], grad_fn=<UnsafeViewBackward0>)如我们所见,输出张量的形状为 [2, 4, 50257],因为我们输入了 2 个文本,每个文本包含 4 个 token。最后一个维度 50,257 对应于 tokenizer 的词汇表大小。在下一节中,我们将了解如何将这些 50,257 维的输出向量转换回 token。
-
不过,关于其大小需要简要说明:我们之前将其称为 1.24 亿参数模型;我们可以通过以下方式再次确认这一数字:
使用 numel() 方法(“元素数量”的缩写),我们可以收集模型参数张量中的参数总数:
total_params = sum(p.numel() for p in model.parameters()) print(f"Total number of parameters: {total_params:,}") """输出""" Total number of parameters: 163,009,536模型参数数量为 163M 而非 124M,原因是未应用权重绑定(weight tying),即 GPT-2 中将token embedding层重用作输出层以减少参数;嵌入层将 50,257 维 one-hot 编码标记投影到 768 维嵌入表示,而输出层将其投影回 50,257 维以转换回单词,两者参数数量一致,需进一步验证模型参数数量为 124M。
print("Token embedding layer shape:", model.tok_emb.weight.shape) print("Output layer shape:", model.out_head.weight.shape) """输出""" Token embedding layer shape: torch.Size([50257, 768]) Output layer shape: torch.Size([50257, 768])相应地,如果我们减去输出层的参数数量,就会得到一个 124M 参数的模型:
total_params_gpt2 = total_params - sum(p.numel() for p in model.out_head.parameters()) print(f"Number of trainable parameters considering weight tying: {total_params_gpt2:,}") """输出""" Number of trainable parameters considering weight tying: 124,412,160即$ 163,009,536 - 50257*768 = 124412160$ ,该模型现在只有 1.24 亿个参数,与 GPT-2 模型的原始大小相匹配。
在实践中,不使用权重共享训练模型更为简便,因此本节未实现权重共享。后续章节将重新考虑权重共享,并在加载预训练权重时应用。此外,计算模型的内存需求也是一个重要的参考点。
-
计算模型内存需求# Calculate the total size in bytes (assuming float32, 4 bytes per parameter) total_size_bytes = total_params * 4 # Convert to megabytes total_size_mb = total_size_bytes / (1024 * 1024) print(f"Total size of the model: {total_size_mb:.2f} MB") """输出""" Total size of the model: 621.83 MB通过计算 GPTModel 对象中 1.63 亿参数的内存需求,并假设每个参数为 32 位浮点数,占用 4 字节,我们发现模型的总大小为 621.83 MB,这说明了即使是相对较小的 LLMs 也需要较大的存储空间。
-
在本节中,我们实现了 GPTModel 架构,并看到它输出了形状为 [batch_size, num_tokens, vocab_size] 的数值张量。
在下一节中,我们将编写代码将这些输出张量转换为文本。