机器学习——验证方法
1 、验证的引入
1.1 机器学习中的数据集划分
在机器学习中,我们的训练机器学习模型的目标是得到一个泛化误差小的模型,也就是说在没有参加训练的样本中获得最优的性能。通常情况下,我们会将数据集分成三个部分,包括训练集,验证集和测试集。我们在训练集上对机器学习的模型进行训练,在训练的过程中使用验证集进行测试,当在验证集上获取到最优的参数的时候,可以停止训练。将训练好的模型在测试集上进行测试。
1.2 验证集的作用
我们在训练机器学习模型的时候,总是会有一些超参数需要我们进行人为的进行设置,比如我们在训练神经网络中的网络层数。这种超参数不是机器学习模型学习出来的,而是我们自己进行调节的,如何进行调节呢?这个时候就引出了验证集的作用。一般情况下,我们基于验证集来调节模型的超参数,这种调节的过程的本质也是一个学习的过程。通过验证集,我们能够确定最优的超参数,这样也就确定了最优的机器学习模型结构。同时,当模型十分的复杂的时候,很容易在训练数据上产生过拟合。此时,我们将模型放到验证集上进行及时的测试,可以提早的发现模型的过拟合的现象,及时停止训练,减少过拟合。
一般情况下,我们会先将模型在训练集上进行训练,在训练的的过程中,我们将训练过一定的时间的模型放到验证集上进行验证,最终我们希望的是模型在验证集性能非常的好。此时我们就可以停止训练,然后在测试集上查看泛化误差。
2、验证方法
所谓的验证方法,核心就是我们如何去构造验证集。一般情况下,验证集的构造方法包括三种,留出法,交叉验证法和自助法,下面我们来一一介绍。
2.1、留出法
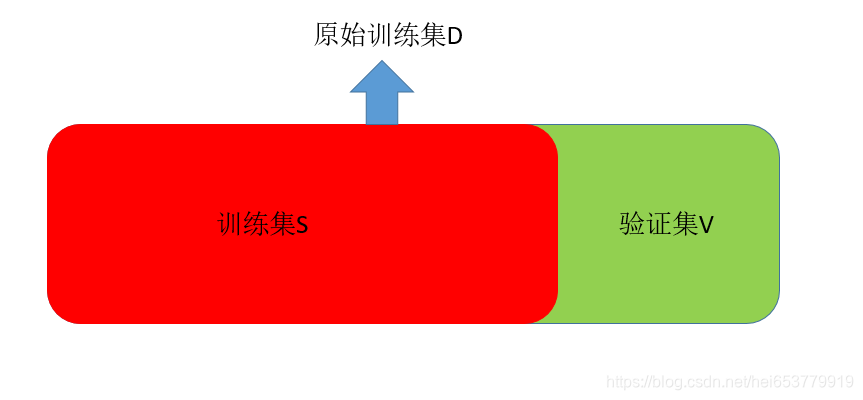
留出法的思路很简单,就是将原始训练数据集D划分成两个部分,两个子集是互斥的,其中一个集合作为训练集S,另外一个集合作为验证集V。我们用数学的形式描述一下就是:
D
=
S
∪
V
,
S
∩
T
=
∅
D=S∪V,S∩T=∅
D=S∪V,S∩T=∅
举一个例子来讲,我们的训练数据D包括1000样本,其中S包括700个样本用于训练,300个样本作为验证集进行验证。
这里值得我们注意的是,我们需要保证训练集S和验证集V尽可能的保证数据的分布是一致的。这样可以避免因为数据分布的不一致性而引入的额外的偏差,而对最终的结果产生影响。
这种一致性最为常见的例子是我们要尽量保证在训练集S和验证集V中的各个类别的样本的比例是一致的。以二分类为例,在S中正负样本比例在1:1左右,则在V中也要尽量去保证正负样本比例在1:1左右。
从采样的角度来看这种比例一致的问题,实际上就是一个分层采样的过程,所谓的分层采样,实际上就是按照不同的类别进行随机采样,还是我们上面的例子,假设原始的样本集D中的样本数量为1000,并且正负样本的数量均为500,我们按照700:300的比例划分成S集和V集,我们首先从正类中进行随机采样,将正类的样本分成350:150的两个集合A,B,在将负类的样本进行随机采样,将负类的样本分成350:150的两个集合C,D,然后将A、C集合合并构成训练集S,B、D集合合并构成验证集V。
尽管我们能够保证S和V集合的中的各类样本的比例是一致的,但是这仍然存在一定的问题,我们继续看上面的例子,我们在将正类切分为350和150是两个部分的时候,我们可以将500个正例样本中的前350个作为第一个部分,也可以将500个正例样本中的后350个作为第一个部分。这些不同划分方式会产生不同的S和V集。不同的S和V集可能会导致模型的评估结果不同,为了解决这个问题,我们往往采用的方式是进行多次划分,分成不同的S/V集,进行多次训练和评估模型,最后取均值或者投票法来确定最终的结果。
最后,我们在说明这种方法的一个局限性,我们将原始的训练数据集D划分成了两个不相交的子集S和V,当S集特别大的时候,模型的训练结果接近于D,但是V过小,会导致验证集的评估结果不够稳定。如果缩小S集并扩大V集,这样会导致模型训练的欠拟合问题。这个问题没有完美的解决方法,一般情况下,我们一般将 2 3 \frac{2}{3} 32到 4 5 \frac{4}{5} 54的样本用于训练,其余的样本用于验证。
最后,我们用一张图来展示一下留出法的基本思想:
2.2 交叉验证法
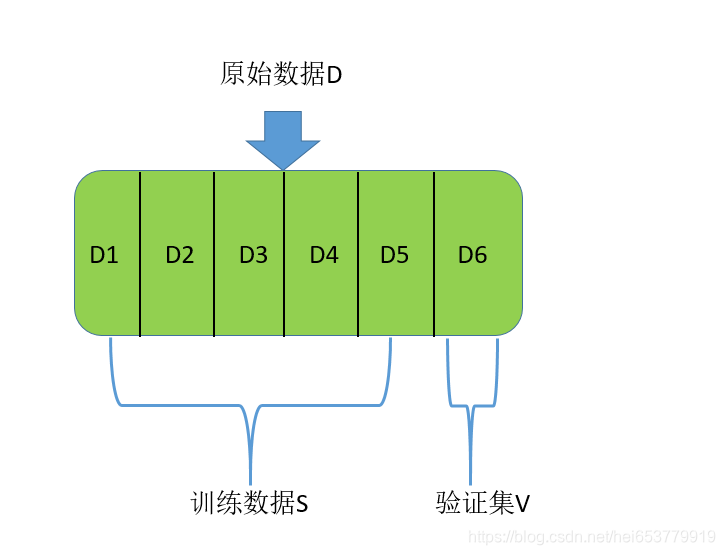
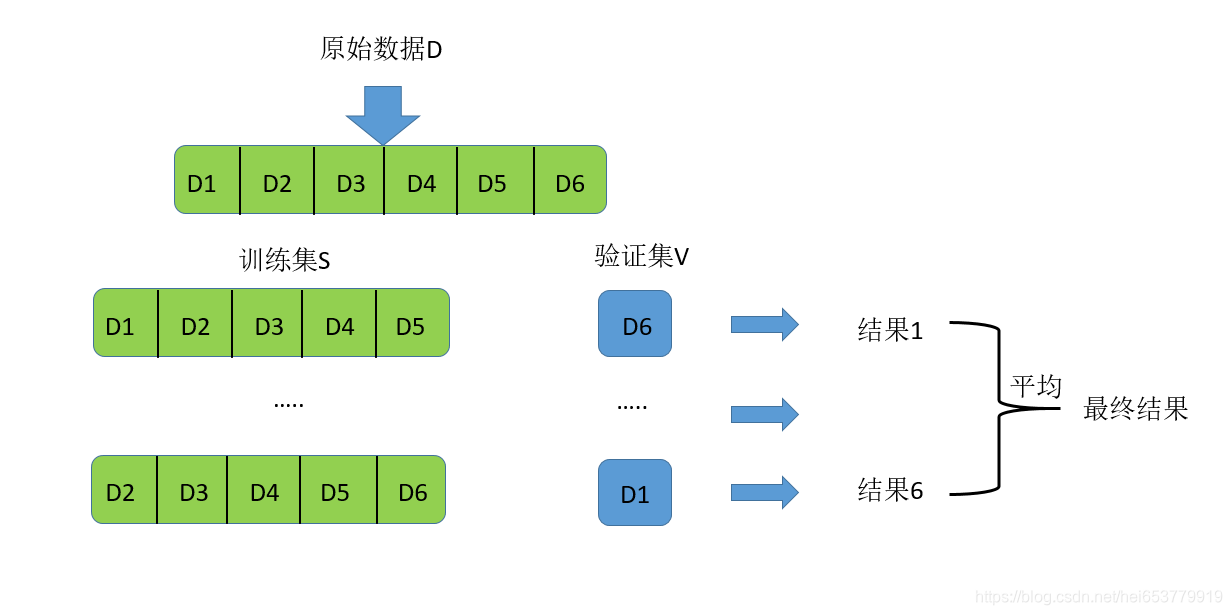
交叉验证法的思想是首先将数据集D划分成K个大小相似的互斥子集,即D=D1∪D2∪…∪Dk,其中Di∩Dj=∅(i≠j)。我们采用分层抽样的方法保证每个数据集中的数据分布尽可能的一致。然后,我们每次用k-1个子集作为训练集S,剩下的那个子集作为验证集V,这样就得到了k组训练集S和验证集V,然后进行k次训练,最终返回的是这k个结果的均值。
我们用一张图来展示一下划分的过程:
我们再用一张图来真实整个流程:
与留出法类似,我们在生成不同的子集的时候,存在着很多种划分的方式,为了减少因为样本划分不同而引入的差别,我们通常需要随机的进行不同的划分过程P次,也就是说我们对于上面的过程重复了P次,最终在每一次结果的基础上在取均值作为最终的验证结果。这种方式称为p次k折交叉验证。
2.2.1 留一法
这里,我们介绍一种交叉验证的特殊形式,我们将含有m个样本的原始样本集合D划分成为m份,也就是说每一个子集中包含一个样本。使用这种方式的好处在于不会受到随机样本划分的影响,因为m个样本只有一种方式来划分,使得每一个子集中包含一个样本。这种方式使得训练集只是比原始的数据集少了一个样本,这就使得在绝大多数的情况向留一法和使用原始数据D来训练的效果很相似。而这种方法的缺陷在于,当数据量m特别大的时候,我们要训练m个模型,这个可能是相对比较复杂的。而且,我们使用一个样本作为验证集,这种评估的结果不一定是稳定的。
2.3 自助法
所谓的自助法,其实就是利用BootStrap方式进行抽样,其基本思想如下图所示:
也就是说,我们将D’作为训练集S,剩余没有被抽样的,大约36.8%的样本作为验证集V,这种方式在数据集比较小,很难有效的划分的时候很有用。

3 参考
- 周志华《机器学习》
- 评估机器学习模型的几种方法(验证集的重要性)