Video Swin Transformer
- 发表:ICCV 2021
- idea:使用image recognition任务中提出的Swin Transformer来解决video recognition任务。至于Swin Transformer,请看上一篇文章.
与图像相比,视频需要更多的输入标记来表示它们,因为视频还具有时间维度。因此,全局自我注意模块不适合视频任务,因为这将导致巨大的计算和内存开销。这篇文章通过follow Swin Transformer在自我注意模块中引入了一个局部感应偏置。 - 代码:Video-Swin-Transformer
详细设计
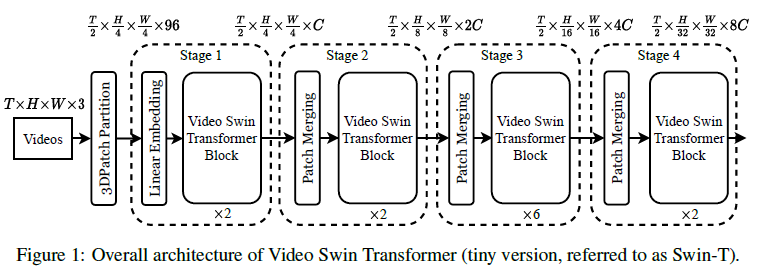
Video Swin Transformer,严格遵循原始Swin Transformer的层次结构,但将局部注意力计算的范围从仅空间域扩展到了时空域。由于局部注意力是在非重叠窗口上计算的,所以原始的Swin Transformer移位窗口机制也被重新表述为处理时空输入。
3D Patch Partition:将大小为2443的每个3D小块视为一个标记token。3D Patch Partition layer获得
T
/
2
∗
H
/
4
∗
W
/
4
T/2 * H/4 * W/4
T/2∗H/4∗W/4个3维tokens,每个patch/token由96维特征组成
Linear Embedding:将每个token的特征投影到C维。
Patch Merging Layer:连接每组22个空间相邻的patch的特征,并应用线性层将连接的特征投影到其尺寸的一半
Video Swin Transformer block:它是通过将标准transformer中的多头自关注(MSA)模块替换为基于3D移动窗口的多头自关注模块并保持其他组件不变。
ps:基本都一样,只是引入了时间纬度。
- image–>video的改变
(1)原始的image recognition中的Swing Transformer中的embedding layer的size是video中的一半(时间纬度为2),因此作者直接将其复制两次,然后乘以0.5以保证均值和方差。
(2)对于relative position bias,原始的是(2M-1,2M-1),而video中是(2P-1,2M-1,2M-1),也是直接复制2P-1次以保证每一帧中的相对位置偏差一致