第一章 字符串
1.1 字符串介绍
Python字符串的底层存储结构
-
字符串类
Python的数据类型为str(字符串)<class 'str'> -
字符串的创建
① 单个引号创建
a = 'hello world'
注:如果变量的值使用了特殊符号,例如',需要使用转译符号
② 双引号创建
b = "abcdefg"
说明:代码使用这种写法较多
③ 三个引号的创建 (支持换行)
# 第一种
a = ''' i am Tom,
nice to meet you! '''
# 第二种
b = """ i am Rose,
nice to meet you! """
说明:3种写法中,变量的常用命名中使用第2种较多,但是函数的注释说明使用第3种较多
1.2 格式化输出
-
格式化输出说明
所谓的格式化输出即按照一定的格式输出内容,对输出的内容进行一定格式的转换
-
格式化符号
① 格式化规范
格式符号 转换 %s 字符串 %d 有符号的十进制整数 %f 浮点数 %c 字符 %u 无符号十进制整数 %o 八进制整数 %x 十六进制整数(小写ox) %X 十六进制整数(大写OX) %e 科学计数法(小写’e’) %E 科学计数法(大写’E’) %g %f和%e的简写 %G %f和%E的简写 ② 格式化示例
%06d,表示输出的整数显示位数,不足以0补全,超出当前位数则原样输出 %.2f,表示小数点后显示的小数位数。 -
代码示例
age = 18 name = 'TOM' weight = 75.5 student_id = 1 # 我的名字是TOM print('我的名字是%s' % name) # 我的学号是0001 print('我的学号是%4d' % student_id) # 我的体重是75.50公斤 print('我的体重是%.2f公斤' % weight) # 我的名字是TOM,今年18岁了 print('我的名字是%s,今年%d岁了' % (name, age)) # 我的名字是TOM,明年19岁了 print('我的名字是%s,明年%d岁了' % (name, age + 1)) # 我的名字是TOM,明年19岁了 注意:f-格式化字符串是Python3.6中新增的格式化方法,该方法更简单易读 print(f'我的名字是{name}, 明年{age + 1}岁了') -
print函数换行说明
# print() 函数的默认加了换行符 print('输出的内容') print('输出的内容', end="\n") # 定制print()函数的结尾符,此时不会换行 print(f'Hi,{name}', end='')
1.3 字符串输入
-
输入介绍
在
Python中,程序接收用户输入的数据的功能即是输入。 -
输入的语法
① 当程序执行到
input,等待用户输入,输入完成之后才继续向下执行。② 在Python中,
input接收用户输入后,一般存储到变量,方便使用。③ 在Python中,
input会把接收到的任意用户输入的数据都当做字符串处理。 -
代码示例
# 使用变量接收输入内容 password = input('请输入您的密码:') # 输出password print(f'您输入的密码是{password}')
1.4 转译符号
-
Python中的转义符
转义符 描述 \ 续行符(在行尾时) \ 反斜杠符号 ’ 单引号 " 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 换行 \v 纵向制表符 \t 横向制表符 \r 回车 \f 换页 \oyy 八进制数yy代表的字符,例如:\o12代表换行 \xyy 十进制数yy代表的字符,例如:\x0a代表换行 \other 其它的字符以普通格式输出
1.5 字符串查找
-
字符串索引、下标
“下标”又叫“索引”,就是编号。比如火车座位号,座位号的作用:按照编号快速找到对应的座位。同理,下标的作用即是通过下标快速找到对应的数字name = "abcdef" print(name[1]) print(name[0]) print(name[2]) -
索引查找:find( )
查找子串在字符串中的位置或出现的次数
①
find()检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标 (上一个字符的位置),否则则返回 -1
② 语法
mystr = "hello world and hello python and hello java" # 在15-30下标区间查找‘and’ print(mystr.find('and', 15, 30)) # 整个字符串内查找'and' print(mystr.find('and')) -
索引查找:index( )
①
index()方法介绍检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则报异常
② 语法
mystr = "hello world and itcast and itheima and Python" # 在15-30下标区间查找‘and’ print(mystr.index('and', 15, 30)) # 整个字符串内查找'ands',如果不存在报错 print(mystr.index('ands'))# 报错 -
从右查找
① 方法介绍
和原方法使用相同,从右开始查找
② 使用语法
# 和find()功能相同,但查找方向为==右侧==开始。 rfind() # 和index()功能相同,但查找方向为==右侧==开始 rindex() -
字符串并统计:count( )
① 方法介绍
返回某个子串在字符串中出现的次数
② 使用语法
mystr = "hello world and itcast and itheima and Python" # 在15-30下标区间查找‘and’出现的次数 print(mystr.count('and', 0, 20)) # 1 # 整个字符串内查找'ands'的次数 print(mystr.count('and')) # 3 print(mystr.count('ands')) # 0
1.6 字符串切片
-
字符串切片说明
切片是指对操作的对象截取其中一部分的操作,字符串、列表、元组都支持切片操作
-
字符串切片语法(左闭右开)
序列 [开始位置下标 : 结束位置下标 : 步长]
① 不包含结束位置下标对应的数据, 正负整数均可
② 步长是选取间隔,正负整数均可,默认步长为1
-
代码示例
name = "abcdefg" print(name[2:5:1]) # cde print(name[2:5]) # cde print(name[:5]) # abcde print(name[1:]) # bcdefg print(name[:]) # abcdefg print(name[::2]) # aceg print(name[:-1]) # abcdef, 负1表示倒数第一个数据 print(name[-4:-1]) # def print(name[::-1]) # gfedcba
1.7 字符串修改
注:字符串类型的数据修改的时候不能改变原有字符串,属于不能直接修改数据的类型即是不可变类型
-
replace( )
① 介绍
替换目标字符串中的符合条件的字符串片段,替换后生成一个新的字符串,目标字符串不变
# 替换次数为字符串片段在字符串中出现的次数,如果不指定次数则替换所有符合条件的字符串片段 字符串序列.replace(旧子串, 新子串, 替换次数)② 使用语法
mystr = "hello world and itcast and itheima and Python" # 不指定次数,替换所有符合条件的字符串片段 print(mystr.replace('and', 'he'))# 结果:hello world he itcast he itheima he Python print(mystr.replace('and', 'he', 1)) # 结果:hello world and itcast and itheima and Python print(mystr) -
split()
① 使用说明
按照指定字符分割字符串
② 使用语法
# 使用语法(num表示的是分割字符出现的次数,即将来返回数据个数为num+1个) 字符串序列.split(分割字符, num) # 使用案例 mystr = "hello world and itcast and itheima and Python" # 不带切割次数:会切割所有匹配的字符串 mystr.split('and') # 结果:['hello world ', ' itcast ', ' itheima ', ' Python'] # 带切割次数:按照切割次数从左到右进行切割 mystr.split('and', 1) # 结果:['hello world ', ' itcast and itheima and Python']③ 注意事项
如果分割字符是原有字符串中的子串,分割后则丢失该子串
-
join()
① 使用说明
用一个字符或子串合并字符串,即是将多个字符串合并为一个新的字符串
② 使用语法
# 使用语法 字符或子串.join(多字符串组成的序列) # 使用案例:将字符串组合到元组或者集合中,得到一个新的字符串 list1 = ['chuan', 'zhi', 'bo', 'ke'] t1 = ('aa', 'b', 'cc', 'ddd') '_'.join(list1) # 结果:chuan_zhi_bo_ke '...'.join(t1) # 结果:aa...b...cc...ddd # 使用案例:将两个字符传进行组合,会先把目标字符串拆分为集合,然后进行拼接 mystr='hello' mystr1='-' mystr1.join(mystr) # 结果:h-e-l-l-o -
capitalize()
① 使用说明
将字符串第一个字符转换成大写
② 使用语法
mystr='hello' mystr.capitalize() # 结果:Hello -
title()
① 使用说明
将字符串每个单词首字母转换成大写
② 使用语法
mystr = "hello world and itcast and itheima and Python" mystr.title() # 结果:Hello World And Itcast And Itheima And Python -
lower()
① 使用说明
将字符串转为小写
② 使用语法
mystr = "HELLO" mystr.lower() # 结果:hello world and itcast and itheima and python -
upper()
① 使用说明
将字符串转为大写
② 使用语法
mystr = "hello world and itcast and itheima and Python" mystr.upper() # 结果:HELLO WORLD AND ITCAST AND ITHEIMA AND PYTHON -
strip()
① strip()
删除字符串两侧的空白字符
② lstrip()
删除字符串左侧的空白字符
③ rstrip()
删除字符串右侧的空白字符
-
rjust()、ljust()、center()
① ljust()
返回一个原字符串左对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串
② rjust()
返回一个原字符串右对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串,语法和ljust()相同
③ center()
返回一个原字符串居中对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串,语法和ljust()相同
mystr='hello' # ljust() mystr.ljust(10,'.') # 结果:'hello.....' # rjust() mystr.rjust(10,'.') # 结果:'.....hello' # center() mystr.center(10,'.') # 结果:'..hello...'
1.8 判断
-
startswith()、endswith()
如果设置开始和结束位置下标,则在指定范围内检查
① startswith()
检查字符串是否是以指定子串开头,是则返回 True,否则返回 False
② endswith()
检查字符串是否是以指定子串结尾,是则返回 True,否则返回 False
③ 使用方法
mystr = "hello world and itcast and itheima and Python" # 结果:True print(mystr.endswith('Python')) # 结果:False print(mystr.endswith('python')) # 结果:False print(mystr.endswith('Python', 2, 20)) -
isalpha()、isdigit()、isalnum()
① isalpha()
如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False
② isdigit()
如果字符串只包含数字则返回 True 否则返回 False
③ isalnum()
如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False
④ 使用方法
mystr1 = 'aaa12345' mystr2 = '12345-' # 结果:True print(mystr1.isalnum()) # 结果:False print(mystr2.isalnum()) -
isspace()
如果字符串中只包含空白,则返回 True,否则返回 False
1.9 正则表达式
-
正则表达式
正则表达式就是记录文本规则的代码
-
re模块的使用
import re # 使用match方法进行匹配操作 result = re.match("hundsun","com.hundsun") # 获取匹配结果 info = result.group() print(info) # hundsun -
匹配单个字符
代码 功能 . 匹配任意1个字符(除了\n) [ ] 匹配[ ]中列举的字符 \d 匹配数字,即0-9 \D 匹配非数字,即不是数字 \s 匹配空白,即 空格,tab键 \S 匹配非空白 \w 匹配非特殊字符,即a-z、A-Z、0-9、_、汉字 \W 匹配特殊字符,即非字母、非数字、非汉字 import re ret = re.match("t.o","too") print(ret.group()) # too # 匹配0到9第一种写法 ret = re.match("[0123456789]Hello Python","7Hello Python") print(ret.group()) # 7Hello Python # 匹配0到9第二种写法 ret = re.match("[0-9]Hello Python","7Hello Python") print(ret.group()) # 7Hello Python ret = re.match("嫦娥\d号","嫦娥2号发射成功") print(ret.group()) # 嫦娥2号 ret = re.match("嫦娥\d号","嫦娥3号发射成功") print(ret.group()) # 嫦娥3号 match_obj = re.match("\D", "f") print(match_obj.group()) # f # 匹配非特殊字符中的一位 match_obj = re.match("\w", "A") print(match_obj.group()) # A -
匹配多个字符
代码 功能 * 匹配前一个字符出现0次或者无限次,即可有可无 + 匹配前一个字符出现1次或者无限次,即至少有1次 ? 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 {m} 匹配前一个字符出现m次 {m,n} 匹配前一个字符出现从m到n次 # 匹配出一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可 有可无 ret = re.match("[A-Z][a-z]*","Aabcdef") print(ret.group()) # Aabcdef # 匹配一个字符串,第一个字符是t,最后一个字符串是o,中间至少有一个字符 match_obj = re.match("t.+o", "two") print(match_obj.group()) # two # 匹配出这样的数据,但是https 这个s可能有,也可能是http 这个s没有 match_obj = re.match("https?", "http") print(match_obj.group()) # https # 匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线 ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66") print(ret.group()) # 1ad12f23s34455ff66 -
匹配开头和结尾
代码 功能 ^ 匹配字符串开头 $ 匹配字符串结尾 # 匹配以数字结尾的数据 match_obj = re.match(".*\d$", "hello5") print(match_obj.group()) # hello5 # 匹配以数字开头中间内容不管以数字结尾 match_obj = re.match("^\d.*\d$", "4hello4") print(match_obj.group()) # 4hello4 # 第一个字符除了aeiou的字符都匹配 match_obj = re.match("[^aeiou]", "h") print(match_obj.group()) # h -
匹配分组
代码 功能 | 匹配左右任意一个表达式 (ab) 将括号中字符作为一个分组 \num引用分组num匹配到的字符串 (?P<name>)分组起别名 (?P=name) 引用别名为name分组匹配到的字符串 # 在列表中["apple", "banana", "orange", "pear"],匹配apple和pear fruit_list = ["apple", "banana", "orange", "pear"] # 遍历数据 for value in fruit_list: # | 匹配左右任意一个表达式 match_obj = re.match("apple|pear", value) if match_obj: print("%s是我想要的" % match_obj.group()) else: print("%s不是我要的" % value) # 匹配出163、126、qq等邮箱 match_obj = re.match("[a-zA-Z0-9_]{4,20}@(163|126|qq|sina|yahoo)\.com", "[email protected]") if match_obj: print(match_obj.group()) # 获取分组数据 print(match_obj.group(1)) else: print("匹配失败") # 匹配qq:10567这样的数据,提取出来qq文字和qq号码 match_obj = re.match("(qq):([1-9]\d{4,10})", "qq:10567") if match_obj: print(match_obj.group()) # 分组:默认是1一个分组,多个分组从左到右依次加1 print(match_obj.group(1)) # 提取第二个分组数据 print(match_obj.group(2)) else: print("匹配失败") # 匹配出<html><h1>www.itcast.cn</h1></html> match_obj = re.match("<([a-zA-Z1-6]+)><([a-zA-Z1-6]+)>.*</\\2></\\1>", "<html><h1>www.itcast.cn</h1></html>") if match_obj: print(match_obj.group()) else: print("匹配失败") # 匹配出<html><h1>www.itcast.cn</h1></html> match_obj = re.match("<(?P<name1>[a-zA-Z1-6]+)><(?P<name2>[a-zA-Z1-6]+)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>") if match_obj: print(match_obj.group()) else: print("匹配失败")
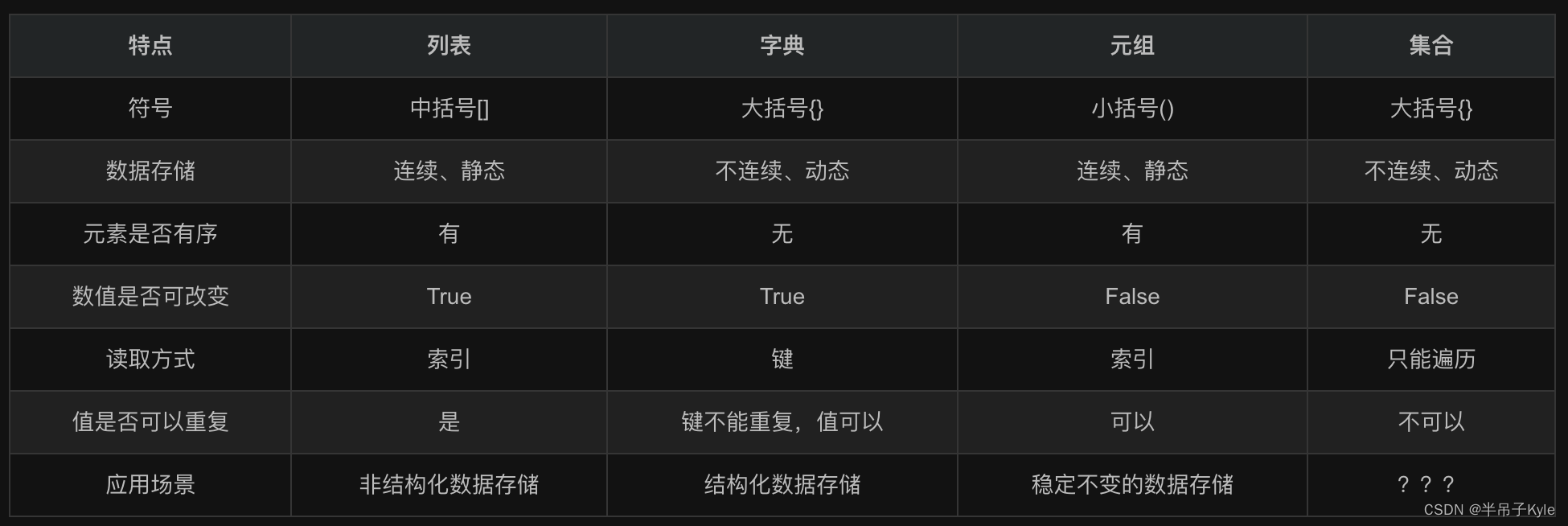
第二章 列表
2.1 列表介绍
-
列表介绍
① 可以存储多个数据,按序存
② 可以存储不同类型的数据,可重复(存储的数据不是结构化,太灵活)
③ 列表有正序、倒序两种索引
2.2 获取列表中的信息
-
index()
在指定的下标范围内查找符合条件的元素的下标
注意:如果查找的数据不存在则报错
# 语法 列表序列.index(数据, 开始位置下标, 结束位置下标) # 示例 name_list = ['Tom', 'Lily', 'Rose'] name_list.index('Lily', 0, 2) # 1 -
count()
统计指定数据在当前列表中出现的次数
name_list = ['Tom', 'Lily', 'Rose'] name_list.count('Lily') # 1 -
len()
访问列表长度,即列表中数据的个数
name_list = ['Tom', 'Lily', 'Rose'] len(name_list) # 3
2.3 判断元素是否存在
-
in
判断指定数据在某个列表序列,如果在返回True,否则返回False
name_list = ['Tom', 'Lily', 'Rose'] # 结果:True print('Lily' in name_list) # 结果:False print('Lilys' in name_list) -
not in
判断指定数据不在某个列表序列,如果不在返回True,否则返回False
name_list = ['Tom', 'Lily', 'Rose'] # 结果:False print('Lily' not in name_list) # 结果:True print('Lilys' not in name_list)
2.4 列表添加
-
append()
列表结尾追加数据,如果数据为一个列表,则追加整个列表到列表
注意:列表追加数据的时候,直接在原列表里面追加了指定数据,即修改了原列表,故列表为可变类型数据
name_list = ['Tom', 'Lily', 'Rose'] # 追加普通数据 name_list.append('xiaoming') # 结果:['Tom', 'Lily', 'Rose', 'xiaoming'] # 追加列表 name_list.append(['xiaoming', 'xiaohong']) # 结果:['Tom', 'Lily', 'Rose', ['xiaoming', 'xiaohong']] -
extend()
列表结尾追加数据,如果数据是一个序列,则将这个序列的数据逐一添加到列表
个人理解:把追加的元素拆分成最小的元素,然后逐一添加到列表中
name_list = ['Tom', 'Lily', 'Rose'] # 添加单个数据 name_list.extend('xiaoming') # 结果:['Tom', 'Lily', 'Rose', 'x', 'i', 'a', 'o', 'm', 'i', 'n', 'g'] # 添加列表 name_list.extend(['xiaoming', 'xiaohong']) # 结果:['Tom', 'Lily', 'Rose', 'xiaoming', 'xiaohong'] -
insert()
指定位置新增数据
# 语法 列表序列.insert(位置下标, 数据) # 案例 name_list = ['Tom', 'Lily', 'Rose'] name_list.insert(1, 'xiaoming') # 结果:['Tom', 'xiaoming', 'Lily', 'Rose']
2.5 列表删除
-
del()
删除列表中的指定数据,会直接对列表进行修改,不会生成新的列表
name_list = ['Tom', 'Lily', 'Rose'] # 删除列表 del name_list # 结果:报错提示:name 'name_list' is not defined # 删除列表中指定数据 del name_list[0] # 结果:['Lily', 'Rose'] -
pop()
删除指定下标的数据(默认为最后一个),并返回该数据
name_list = ['Tom', 'Lily', 'Rose'] del_name = name_list.pop(1) # 结果:Lily print(del_name) # 结果:['Tom', 'Rose'] print(name_list) -
remove()
移除列表中某个数据的第一个匹配项
# 语法 列表序列.remove(数据) # 案例 name_list = ['Tom', 'Lily', 'Rose'] name_list.remove('Rose') # 结果:['Tom', 'Lily'] print(name_list) -
clear()
列表清空
name_list = ['Tom', 'Lily', 'Rose'] name_list.clear() print(name_list) # 结果: []
2.6 列表修改
-
修改指定下标数据
name_list = ['Tom', 'Lily', 'Rose'] name_list[0] = 'aaa' # 结果:['aaa', 'Lily', 'Rose'] print(name_list) -
reverse()
逆置列表
num_list = [1, 5, 2, 3, 6, 8] num_list.reverse() # 结果:[8, 6, 3, 2, 5, 1] print(num_list) -
sort()
对列表中的数据排序
注意:reverse表示排序规则,reverse = True 降序, reverse = False 升序(默认)
num_list = [1, 5, 2, 3, 6, 8] num_list.sort() # 结果:[1, 2, 3, 5, 6, 8] print(num_list)
2.7 列表复制
-
copy()
根据目标列表复制出新的列表
name_list = ['Tom', 'Lily', 'Rose'] name_li2 = name_list.copy() # 结果:['Tom', 'Lily', 'Rose'] print(name_li2)
2.8 列表循环遍历
-
While循环
name_list = ['Tom', 'Lily', 'Rose'] i = 0 while i < len(name_list): print(name_list[i]) i += 1 -
For循环
name_list = ['Tom', 'Lily', 'Rose'] for i in name_list: print(i)
2.9 列表嵌套
-
列表嵌套
列表嵌套指的就是一个列表里面包含了其他的子列表
-
案例
name_list = [['小明', '小红', '小绿'], ['Tom', 'Lily', 'Rose'], ['张三', '李四', '王五']] # 寻找李四数据 # 第一步:按下标查找到李四所在的列表 print(name_list[2]) # 第二步:从李四所在的列表里面,再按下标找到数据李四 print(name_list[2][1])
第三章 元组
3.1 元组介绍
-
元组介绍
① 可以存储多个数据
② 数据定义后不可修改 (如果元组中的元素类型为类表,数据仍然可以改变,注意该数据不可变的相对性)
③ 数据类型可以不同
④ 使用索引读取数据
-
元组的定义
① 单个数据元组
注意:如果定义的元组只有一个数据,那么这个数据后面也好添加逗号,否则数据类型为唯一的这个数据的数据类型
# 单个数据元组 t2 = (10,) print(type(t2)) # tuple # 不带 ',' 号的元组 t3 = (20) print(type(t3)) # int② 多数据元组
# 单一类型元组 t1 = (10, 20, 30) # 多类型元组 t1: tuple = (['01', '02'], '23', 45) print(t1)
3.2 元组的常见操作
-
元素查找
① 根据下标查找数据
tuple1 = ('aa', 'bb', 'cc', 'bb') print(tuple1[0]) # aa② 根据数据查找下标
注意:查找某个数据,如果数据存在返回对应的下标,否则报错,语法和列表、字符串的index方法相同
tuple1 = ('aa', 'bb', 'cc', 'bb') print(tuple1.index('aa')) # 0 -
count()
统计某个数据在当前元组出现的次数
tuple1 = ('aa', 'bb', 'cc', 'bb') print(tuple1.count('bb')) # 2
第四章 字典
4.1 字典介绍
-
字典的使用场景
主要用来存储多个键值对,数据存储更加灵活
-
字典的使用特点
① 字典数据和数据的顺序没有关系,字典不支持下标查找,只支持按照
key去查找value② 存储多个键值对
③ 数据可变 (可变类型)
-
字典的创建方式
① 有数据的字典
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}② 空字典
dict2 = {}③ 函数创建
dict3 = dict()
4.2 字典基础操作
-
查询字典项
① 根据
key值查找注意 : 如果不存在会报错
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} print(dict1['name']) # Tom print(dict1['id']) # 报错② get() 查找
注意:存在则返回,不存在则返回None,有默认值则返回默认值
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} # key存在返回value print(dict1.get('name')) # Tom # key不存在返回设置的默认值 print(dict1.get('id', 110)) # 110 # key不存在返回None print(dict1.get('id')) # None③ keys() : 返回字典的key列表
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} dict1_list = dict1.keys() print(dict1_list)④ values():返回字典的值列表
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} keys_list = dict1.keys() print(keys_list) # keys_list(['name', 'age', 'gender'])⑤ items():返回字典内容
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} print(dict1.items()) # dict_items([('name', 'Tom'), ('age', 20), ('gender', '男')]) -
新增字典项
# 示例一 : 存在则修改 dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} dict1['name'] = 'Rose' print(dict1) # {'name': 'Rose', 'age': 20, 'gender': '男'}# 示例二 : 不存在则新增 dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} dict1['id'] = 110 print(dict1) # {'name': 'Rose', 'age': 20, 'gender': '男', 'id': 110} -
删除字典项
① del() / del:删除字典或删除字典中指定键值对
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} # 第一种删除 del dict1['gender'] # 第二种删除 del (dict1['age']) print(dict1) # {'name': 'Tom', 'age': 20}② clear():清空字典
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} dict1.clear() print(dict1) # {}
4.3 升级操作
-
循环遍历
① 遍历字典key列表
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} # 遍历字典key列表 for key in dict1.keys(): print(key)② 遍历值列表
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} for value in dict1.values(): print(value)③ 遍历字典元素(内容)
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} for item in dict1.items(): print(item)④ 遍历键值对
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'} for key, value in dict1.items(): print(f'{key} = {value}')
第五章 集合
4.1 集合介绍
-
集合介绍
集合在实际使用场景的效率没有
list、dict、tuple的场景那么多,使用的场景比较单一 -
集合特点
① 集合可以去掉重复数据
② 集合数据是无序的,故不支持下标
③ 可变,与之对应的不可变的为
frozenset -
集合的创建
# 非空集合的创建 set1 = {10, 20, 30, 30, 50} # 空集合的创建 set2 = set() # 空字典的创建(注意区分) dict1 = {}
4.2 集合的常见操作
-
增加数据
集合有去重功能,所以,当向集合内追加的数据是当前集合已有数据的话,则不进行任何操作
# add() s1 = {10, 20} s1.add(100) s1.add(10) print(s1) # {100, 10, 20} # update():只能添加有 iterable 的元素 set1 = {10, 20, 30, 40, 50} set1.update('abc') set1.update([10, 20, 30]) -
删除数据
# remove():删除集合中的指定数据,如果数据不存在则报错 set1 = {10, 20, 30, 40, 50} set1.remove(60) # discard(),删除集合中的指定数据,如果数据不存在不会报错 set1 = {10, 20, 30, 40, 50} set1.discard(60) # pop(),随机删除集合中的某个数据,并返回这个数据 set1 = {10, 20, 30, 40, 50} set1.pop() -
查询数据
set1 = {10, 20, 30, 40, 50} # in:判断数据在集合序列 print(10 in s1) # not in:判断数据不在集合序列 print(10 not in s1)
第六章 公共操作
6.1 运算符
-
常用的运算符
运算符 描述 支持的容器类型 + 合并 字符串、列表、元组 * 复制 字符串、列表、元组 in 元素是否存在 字符串、列表、元组、字典 not in 元素是否不存在 字符串、列表、元组、字典 -
# 1. 字符串 str1 = 'aa' str2 = 'bb' str3 = str1 + str2 print(str3) # aabb # 2. 列表 list1 = [1, 2] list2 = [10, 20] list3 = list1 + list2 print(list3) # [1, 2, 10, 20] # 3. 元组 t1 = (1, 2) t2 = (10, 20) t3 = t1 + t2 print(t3) # (10, 20, 100, 200) -
# 1. 字符串 print('-' * 10) # ---------- # 2. 列表 list1 = ['hello'] print(list1 * 4) # ['hello', 'hello', 'hello', 'hello'] # 3. 元组 t1 = ('world',) print(t1 * 4) # ('world', 'world', 'world', 'world') -
in或not in
# 1. 字符串 print('a' in 'abcd') # True print('a' not in 'abcd') # False # 2. 列表 list1 = ['a', 'b', 'c', 'd'] print('a' in list1) # True print('a' not in list1) # False # 3. 元组 t1 = ('a', 'b', 'c', 'd') print('aa' in t1) # False print('aa' not in t1) # True
6.2 公共方法
-
len():计算容器中的元素个数
# 1. 字符串 str1 = 'abcdefg' print(len(str1)) # 7 # 2. 列表 list1 = [10, 20, 30, 40] print(len(list1)) # 4 # 3. 元组 t1 = (10, 20, 30, 40, 50) print(len(t1)) # 5 # 4. 集合 s1 = {10, 20, 30} print(len(s1)) # 3 # 5. 字典 dict1 = {'name': 'Rose', 'age': 18} print(len(dict1)) # 2 -
del 或 del():删除元素
# 1. 字符串 str1 = 'abcdefg' del str1 # python有GC机制,所以,del语句作用在变量上,删除的是变量,内存中的数据仍然存在 print(str1) # 2. 列表 list1 = [10, 20, 30, 40] del(list1[0]) # del list1[0] print(list1) # [20, 30, 40] -
max():返回容器中元素最大值
# 1. 字符串 str1 = 'abcdefg' print(max(str1)) # g # 2. 列表 list1 = [10, 20, 30, 40] print(max(list1)) # 40 -
min():返回容器中元素最小值
# 1. 字符串 str1 = 'abcdefg' print(min(str1)) # a # 2. 列表 list1 = [10, 20, 30, 40] print(min(list1)) # 10 -
range():生成从start到end的数字,步长为 step,供for循环使用
注:range()生成的序列不包含end数字
# 1 2 3 4 5 6 7 8 9 for i in range(1, 10, 1): print(i) # 1 3 5 7 9 for i in range(1, 10, 2): print(i) # 0 1 2 3 4 5 6 7 8 9 for i in range(10): print(i) -
enumerate()
# 语法:start参数用来设置遍历数据的下标的起始值,默认为0 enumerate(可遍历对象, start=0) # 使用方法 list1 = ['a', 'b', 'c', 'd', 'e'] for i in enumerate(list1): print(i) for index, char in enumerate(list1, start=1): print(f'下标是{index}, 对应的字符是{char}')
6.3 容器类型转换
-
tuple():将某个序列转换成元组
list1 = [10, 20, 30, 40, 50, 20] s1 = {100, 200, 300, 400, 500} print(tuple(list1)) print(tuple(s1)) -
list():将某个序列转换成列表
t1 = ('a', 'b', 'c', 'd', 'e') s1 = {100, 200, 300, 400, 500} print(list(t1)) print(list(s1)) -
set():将某个序列转换成集合
list1 = [10, 20, 30, 40, 50, 20] t1 = ('a', 'b', 'c', 'd', 'e') print(set(list1)) print(set(t1))
6.4 推导式(生成式)
-
推导式介绍
用一个表达式创建一个有规律的列表或控制一个有规律列表
-
列表推导式(列表生成式)
# 使用一般方式创建 list1 = [] for item in range(1, 10): list1.append(item) print(list1) # 使用推导式创建 list1 = [i for i in range(10)] print(list1) # 只增加偶数:步长实现 list1 = [i for i in range(0, 10, 2)] print(list1) # 只增加偶数:if实现 list1 = [i for i in range(10) if i % 2 == 0] print(list1) # 多个for循环实现列表推导式 # [(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)] list1 = [(i, j) for i in range(1, 3) for j in range(3)] print(list1) -
字典推导式
快速合并列表为字典或提取字典中目标数据
list6 = ['MBP', 'HP', 'DELL', 'Lenovo', 'acer'] list7 = [268, 125, 201, 199, 99] # 语法 dict1 = {list6[i]: list7[i] for i in range(len(list6))} # {'MBP': 268, 'HP': 125, 'DELL': 201, 'Lenovo': 199, 'acer': 99} -
集合推导式
快速生成集合
list1 = ['MBP', 'HP', 'DELL', 'Lenovo', 'acer'] set1 = {list1[i] for i in range(len(list1))} print(set1) # {'DELL', 'Lenovo', 'HP', 'acer', 'MBP'} # <class 'set'>
6.4 生成器
-
生成器介绍
根据程序员制定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成处理,而是使用一个,再生成一个,可以节约大量的内存
-
生成器的创建方式
① 生成器推导式
与列表推导式类似,只不过生成器推导式使用小括号
② yield关键字
-
生成器推导式
# 创建生成器 my_generator = (i * 2 for i in range(5)) print(my_generator) # next获取生成器下一个值 # value = next(my_generator) # print(value) # 遍历生成器 for value in my_generator: print(value) -
yiled关键字
def mygenerater(n): for i in range(n): print('开始生成...') yield i print('完成一次...') if __name__ == '__main__': g = mygenerater(2) # 获取生成器中下一个值 # result = next(g) # print(result) # while True: # try: # result = next(g) # print(result) # except StopIteration as e: # 生成完成后会报异常 # break # # for遍历生成器, for 循环内部自动处理了停止迭代异常,使用起来更加方便 for i in g: print(i) -
yiled 的执行原理
代码执行到 yield 会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
生成器如果把数据生成完成,再次获取生成器中的下一个数据会抛出一个StopIteration 异常,表示停止迭代异常
while 循环内部没有处理异常操作,需要手动添加处理异常操作
for 循环内部自动处理了停止迭代异常,使用起来更加方便,推荐大家使用
-
斐波拉契数列通过生成器实现
def fibonacci(num): a = 0 b = 1 # 记录生成fibonacci数字的下标 current_index = 0 while current_index < num: result = a a, b = b, a + b current_index += 1 # 代码执行到yield会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行 yield result fib = fibonacci(5) # 遍历生成的数据 for value in fib: print(value)