介绍grep之前先介绍一下,正则表达式和通配符
通配符
shell中的通配符,一般只用于文件名的匹配。简单来说有四种。
*星号
星号用于匹配0到多个任意字符,下面是使用ls a*c命令前后

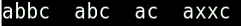
?问号
问号用于匹配一个未知字符,下面是使用ls a?c命令前后

[ ]中括号
[ab]指,该位置有一个a或者b,下面是使用ls a[bx][bx]c命令前后
[^ab]指,该位置有一个字符,但不是a也不是b,下面是使用ls a[^x][^x]c命令前后

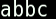
{ }花括号
{bb,xx,b}指,该位置存在一个字符串,可能是它们三个之一,下面是使用ls a{bb,xx,b}c命令前后
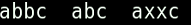
【注】点并不是通配符
下面是使用ls *c命令前后


下面是使用ls *.c命令前后

grep与正则表达式
使用vi,grep等匹配字符串时,可以使用正则表达式。
grep的使用方式:gerp <匹配字符串> <查找位置> <选项>
下面有4个文件,并且文件内容都相同。
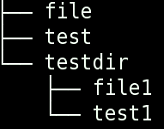
下面是几个例子
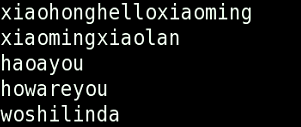
1 普通查找
先弄个最普通的 grep 'hello' test
去test中查找含有hello的行

2 同样是星号,意义却不同。-n和-r选项
=》 grep ‘el*’ t*
查找当前目录下以t开头的文件中,e后面存在0或多个l的行。
el的星号是个正则符,t的星号是个通配符。
=》grep ‘el*’ t* -n
加上 -n选项 能够显示匹配字符串所在的行数
=》grep ‘el*’ t* -r -n
-r 能够让grep对所匹配的目录下的所有文件也生效
下面我们使用grep ‘el*’ * -r -n
让grep搜索路径下的全部文件!


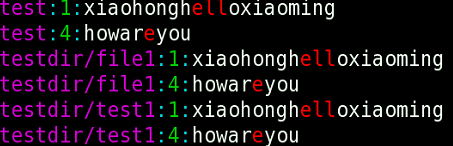
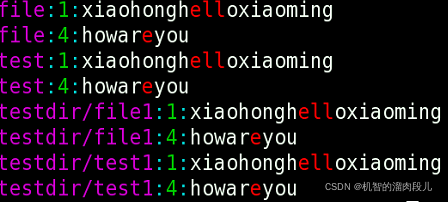
3 行首行尾正则,使用管道符正向过滤和反向过滤
下面我们来深入玩玩正则表达式
^ 锚定行的开始 grep '^xiao' file -n
匹配以xiao开头的行
$ 锚定行的结束 grep 'lan$' file -n
匹配以lan结束的行
有效利用管道符 grep '^xiao' file -n | grep 'lan$'查找以xiao开头的行,以lan结束的行
grep '^xiao' file -n | grep 'lan$' -v查找以xiao开头的行,且不以lan结束的行(-v选项用于反向查找)




4 点,星号,中括号正则
点用于匹配一个任意但是非换行符的字符,grep 'hel.o' file -n
星号,星号不单独使用,会自动和前面的字符形成整体
表示这个位置有零到多个前面的那个字符,grep 'hell*o' file -n,grep 'hel*o' file -n效果是一样的
将点和星号一起使用,就是表示这个位置有0到多个任意字符grep 'h.*l' file -n
中括号代表这个位置有一个字符,是中括号内的某个, grep '[io]ng' file -n
中括号内加入乘方符号,代表这个位置有一个字符,却都不是中括号里的。grep 'ao[^mh]' file -n




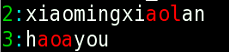
5 花括号
x\{m\}表示此位置会出现字符x,出现次数为m, grep 'el\{2\}o' file -n
还可以把字符的出现次数设置成一个范围
x\{m,\}表示x字符至少出现m次
x\{m,n\}表示x字符至少出现m次,但不会多于n次。

6 字母和数字表示符
\w表示这个位置会出现一个字母和数字,与[A-Za-z0-9]作用相同
\W表示这个位置会出现一个除字母和数字外的字符,如逗号句号等。
7 单词锁定
\bwordb\ 这样在grep的时候就只会匹配单词word,而worda,wordb这样的单词则不会被选中。
egrep
egrep或grep -E中增加了加号+等更多正则的表现形式
1 加号
加号与星号类似,与前面的字符组合使用,表示这位置会出现一个或多个前面的字符。(星号表示0或多个)
2 问号
?问号也是与它前面的字符组合使用,表示这个位置可能会有一个前面的字符,也可能是没有 grep 'l?o' file -n
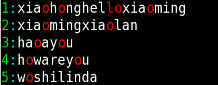
3 或符号
|或符号,表示这个位置可能出现或号两侧的单词一次,或号可以连续使用
grep 'ho|mi|you' file -n
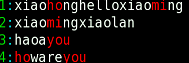
4 括号
终于来到了括号,括号能将以前的单个字符匹配,变成多个字符匹配。而且也能将一句话中多个正则分隔开,十分好用!
grep '(ho|mi)ng' file -n
grep '((he)*)(l+)(oxia)' file -n
这句话表示,这个字符串,最开始有0或多个he,然后跟着1或多个l,然后跟着一个oxia
嗯~


5 花括号
x{m},x{m,},x{m,n} :作用与grep的 x\{m\},x\{m,\},x\{m,n\} 相同
fgrep
使用fgerp能让所有正则全部失效,星号点加号等正则符号,全部和还原为普通字符。
还有一些选项
除了上文提到的 -v反转 -r目录递归 -n显示行号外,还有一些常用选项
-i 忽略大小写
-l 只显示匹配文件的文件名