2020年,基于自注意力机制的Vision Transformer将用于NLP领域的Transformer模型成功地应用到了CV领域的图像分类上,并在ImageNet数据集上得到88.55%的精度。
然而想要真正地将Transformer模型应用到整个CV领域,有两点问题需要解决。
1、超高分辨率的图像所带来的计算量问题;
2、CV领域任务繁多,如语义分割,目标检测,实力分割等密集预测型任务。而最初的Vision Transformer是不具备多尺度预测的,因此仅在分类一个任务可以很好地工作。
针对第一个问题,通过参考卷积网络的工作方式,以及窗口自注意力模型,Swin Transformer提出了一种带移动窗口的自注意力模型。通过串联窗口自注意力运算(W-MSA)以及滑动窗口自注意力运算(SW-MSA),使得Swin Transformer在获得近乎全局注意力能力的同时,又将计算量从图像大小的平方关系降为线性关系,大大地减少了运算量,提高了模型推理速度。
针对第二个问题,在每一个模块(Swin Transformer Block)中,Swin Transformer通过特征融合的方式(PatchMerging,可参考卷积网络里的池化操作)每次特征抽取之后都进行一次下采样,增加了下一次窗口注意力运算在原始图像上的感受野,从而对输入图像进行了多尺度的特征提取,使得在CV领域的其他密集预测型任务上的表现也是SOTA。
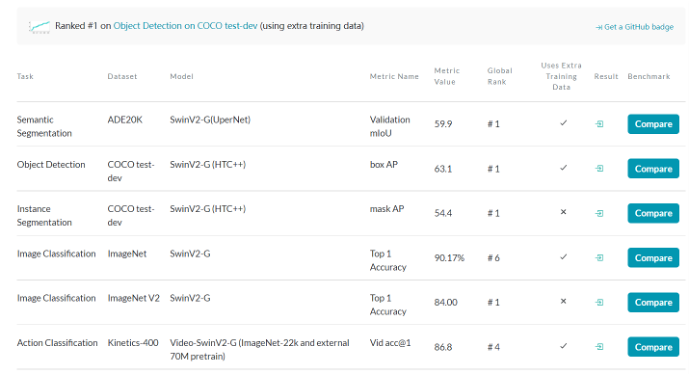
下图为paperwithcode上的截图,截止2022/1/22号,Swin Transformer在各个CV任务上依然呈现霸榜状态。在CV领域,一般在某个任务上可以提高1%就已经很了不起了,而Swin Transformer则是在各个任务上提高了2%~3%的精度。
将Swin Transformer核心
制成SwinT模块的价值
如下图所示,Swin Transformer的核心模块就是黄色部分,我们需要将这个部分制成一个通用的SwinT接口,使得更多熟悉CNN的开发者将Swin Transformer应用到CV领域的不同任务中。

这么做的价值有两点:
1、Swin Transformer自身的能力强大,这个接口将不会过时。①实现超大尺寸整张图片的全局注意力运算所需要的超级计算单元短时间内不会出现(个人开发者也很难拥有这种算力),也就是说,窗口注意力依然能持续使用一到两年;②现在一般认为,简单有效的才是最好的,而Swin Transformer的实现则非常简单,很容易让人看懂并记住其工作原理;③实践上,Swin Transformer也得到了SOTA,并且成功地获得了马尔奖,简单与强大两者加在一起才是能拿马尔奖的原因。
2、实现方便快捷的编程,例如我们要将Unet变成Swin-Unet,我们将只需要直接将Conv2D模块替换成SwinT模块即可。我们通常需要在同一个网络中,不仅使用Swin Transformer中的块,也会使用到Conv2D模块(例如Swin Transformer用在上层抽取全局特征,Conv2D用在下层抽取局部特征),因此我们要对原Swin Transformer模型进行架构上的更改。
移动窗口为什么能有全局特征抽取的能力
Swin Transformer中注意力机制是如何运行的,如下图。首先,我们对每个颜色内的窗口进行自注意力运算,如[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]每个列表内的元素做自注意力运算。
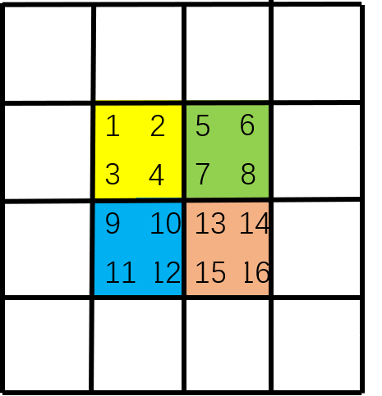
然后,滑动窗口,可以看作背景黑框在图像上滑动对图像进行的重新切分。
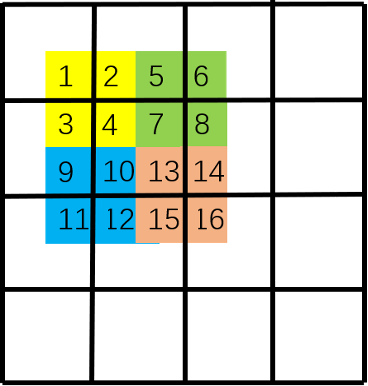
最后,将图像补回原来的大小,这一步是方便代码的编写,并且对窗口中原本不相邻的区域不做注意力运算。注意,窗口是由黑框决定的。也就是说,由于原图像中[4,7,10,13]相邻,因此左上角[4,7,10,13]一起做注意力运算;而[16,11,6,1]原本不相邻,因此右下角[16],[11],[6],[1]单独做注意力运算,而[16],[11]之间不做注意力运算。左下角[12,15],[2,5]各自相邻,因此[12,15]做注意力运算,[2,5]做注意力运算[12,15]和[2,5]之间不做注意力运算。

通过这两步,美妙的事情发生了,我们首先在第一步建立了[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]各自窗口之间的联系,然后在第二步建立了[4,7,10,13]之间的联系。可以观察到,通过这二步,我们得以建立[1,2,3,4,5,6,7,8,9,10,11,12]之间的联系,滑动窗口+原始窗口就如同一个高速通道在图像的左上角和右下角之间建立起了自注意力的联系,从而获得了全局感受野。
我们可以发现,滑窗和不滑窗两步是缺一不可的。只有两者同时存在,我们才能够建立全局的注意力。因此,W-MSA和SW-MSA必须作为一个整体一起使用。后续在我们的SwinT模块的源代码中,将使用W-MSA、SW-MSA和PatchMerging下采样,并将这三部分整合成一个模块。本文章的后续我们将演示这个接口如何使用,利用这个接口真实地搭建一个SwinResnet网络并对其进行性能测试!
SwinT接口的使用方式
SwinT接口的源代码可以参考:
https://aistudio.baidu.com/aistudio/projectdetail/3288357
#导入包,miziha中含有SwinT模块
import paddle
import paddle.nn as nn
import miziha
#创建测试数据
test_data = paddle.ones([2, 96, 224, 224]) #[N, C, H, W]
print(f'输入尺寸:{test_data.shape}')
#创建SwinT层
'''
参数:
in_channels: 输入通道数,同卷积
out_channels: 输出通道数,同卷积
以下为SwinT独有的,类似于卷积中的核大小,步幅,填充等
input_resolution: 输入图像的尺寸大小
num_heads: 多头注意力的头数,应该设置为能被输入通道数整除的值
window_size: 做注意力运算的窗口的大小,窗口越大,运算就会越慢
qkv_bias: qkv的偏置,默认None
qk_scale: qkv的尺度,注意力大小的一个归一化,默认None #Swin-V1版本
dropout: 默认None
attention_dropout: 默认None
droppath: 默认None
downsample: 下采样,默认False,设置为True时,输出的图片大小会变为输入的一半
'''
swint1 = miziha.SwinT(in_channels=96, out_channels=256, input_resolution=(224,224), num_heads=8, window_size=7, downsample=False)
swint2 = miziha.SwinT(in_channels=96, out_channels=256, input_resolution=(224,224), num_heads=8, window_size=7, downsample=True)
conv1 = nn.Conv2D(in_channels=96, out_channels=256, kernel_size=3, stride=1, padding=1)
#前向传播,打印输出形状
output1 = swint1(test_data)
output2 = swint2(test_data)
output3 = conv1(test_data)
print(f'SwinT的输出尺寸:{output1.shape}')
print(f'下采样的SwinT的输出尺寸:{output2.shape}') #下采样
print(f'Conv2D的输出尺寸:{output3.shape}')
运行上述代码,模型将会输出:
输入尺寸:[2, 96, 224, 224]
SwinT的输出尺寸:[2, 256, 224, 224]
下采样的SwinT的输出尺寸:[2, 256, 112, 112]
Conv2D的输出尺寸:[2, 256, 224, 224]使用SwinT替换Resnet中Conv2D模型
创建Swin Resnet并进行测试!
这部分,我们实际展示了如何使用SwinT来替换掉现有模型中相应的Conv2D模块,整个过程对源码改动小。
源码链接:
https://www.paddlepaddle.org.cn/tutorials/projectdetail/3106582#anchor-10
为了展示实际的效果,我们使用Cifar10数据集(这是一个任务较简单且数据较少的数据集)对模型精度,速度两方面给出了结果,证明了SwinT模块在效果上至少是不差于Conv2D的,由于运行整个流程需要6个小时,因此没有过多调节超参数防止过拟合。虽然普通的resnet50可以调高batch来提高速度,但是batch大小是与模型正则化有关的一个参数,因此将batch都控制在了一个大小进行对比测试。
首先创建卷积批归一化块,在resnet50中使用的是batchnorm,而在SwinT模块中已经自带了layernorm,因此这块代码不需要做改动。
# ResNet模型代码
# ResNet中使用了BatchNorm层,在卷积层的后面加上BatchNorm以提升数值稳定性
# 定义卷积批归一化块
class ConvBNLayer(paddle.nn.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
act=None):
# num_channels, 卷积层的输入通道数
# num_filters, 卷积层的输出通道数
# stride, 卷积层的步幅
# groups, 分组卷积的组数,默认groups=1不使用分组卷积
super(ConvBNLayer, self).__init__()
# 创建卷积层
self._conv = nn.Conv2D(
in_channels=num_channels,
out_channels=num_filters,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
bias_attr=False)
# 创建BatchNorm层
self._batch_norm = paddle.nn.BatchNorm2D(num_filters)
self.act = act
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
if self.act == 'leaky':
y = F.leaky_relu(x=y, negative_slope=0.1)
elif self.act == 'relu':
y = F.relu(x=y)
return y
这部分我们定义残差块,残差块是Resnet最核心的单元,我们需要将其中Conv2D替换为SwinT。
# 定义残差块
# 每个残差块会对输入图片做三次卷积,然后跟输入图片进行短接
# 如果残差块中第三次卷积输出特征图的形状与输入不一致,则对输入图片做1x1卷积,将其输出形状调整成一致
class BottleneckBlock(paddle.nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
resolution,
num_heads=8,
window_size=8,
downsample=False,
shortcut=True):
super(BottleneckBlock, self).__init__()
# 创建第一个卷积层 1x1
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
act='relu')
# 创建第二个卷积层 3x3
# self.conv1 = ConvBNLayer(
# num_channels=num_filters,
# num_filters=num_filters,
# filter_size=3,
# stride=stride,
# act='relu')
#如果尺寸为7x7,启动cnn,因为这个大小不容易划分等大小窗口了
# 使用SwinT进行替换,如下
if resolution == (7,7):
self.swin = ConvBNLayer(num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
stride=1,
act='relu')
else:
self.swin = miziha.SwinT(in_channels=num_filters,
out_channels=num_filters,
input_resolution=resolution,
num_heads=num_heads,
window_size=window_size,
downsample=downsample)
# 创建第三个卷积 1x1,但输出通道数乘以4
self.conv2 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters * 4,
filter_size=1,
act=None)
# 如果conv2的输出跟此残差块的输入数据形状一致,则shortcut=True
# 否则shortcut = False,添加1个1x1的卷积作用在输入数据上,使其形状变成跟conv2一致
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
swin = self.swin(y)
conv2 = self.conv2(swin)
# 如果shortcut=True,直接将inputs跟conv2的输出相加
# 否则需要对inputs进行一次卷积,将形状调整成跟conv2输出一致
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2)
y = F.relu(y)
return y
最后,我们搭建完整的SwinResnet。
#搭建SwinResnet
class SwinResnet(paddle.nn.Layer):
def __init__(self, num_classes=12):
super().__init__()
depth = [3, 4, 6, 3]
# 残差块中使用到的卷积的输出通道数,图片的尺寸信息,多头注意力参数
num_filters = [64, 128, 256, 512]
resolution_list = [[(56,56),(56,56)],[(56,56),(28,28)],[(28,28),[14,14]],[(14,14),(7,7)]]
num_head_list = [4, 8, 16, 32]
# SwinResnet的第一个模块,包含1个7x7卷积,后面跟着1个最大池化层
#[3, 224, 224]
self.conv = ConvBNLayer(
num_channels=3,
num_filters=64,
filter_size=7,
stride=2,
act='relu')
#[64, 112, 112]
self.pool2d_max = nn.MaxPool2D(
kernel_size=3,
stride=2,
padding=1)
#[64, 56, 56]
# SwinResnet的第二到第五个模块c2、c3、c4、c5
self.bottleneck_block_list = []
num_channels = 64
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
# c3、c4、c5将会在第一个残差块使用downsample=True;其余所有残差块downsample=False
bottleneck_block = self.add_sublayer(
'bb_%d_%d' % (block, i),
BottleneckBlock(
num_channels=num_channels,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
downsample=True if i == 0 and block != 0 else False,
num_heads=num_head_list[block],
resolution=resolution_list[block][0] if i == 0 and block != 0 else resolution_list[block][1],
window_size=7,
shortcut=shortcut))
num_channels = bottleneck_block._num_channels_out
self.bottleneck_block_list.append(bottleneck_block)
shortcut = True
# 在c5的输出特征图上使用全局池化
self.pool2d_avg = paddle.nn.AdaptiveAvgPool2D(output_size=1)
# stdv用来作为全连接层随机初始化参数的方差
import math
stdv1 = 1.0 / math.sqrt(2048 * 1.0)
stdv2 = 1.0 / math.sqrt(256 * 1.0)
# 创建全连接层,输出大小为类别数目,经过残差网络的卷积和全局池化后,
# 卷积特征的维度是[B,2048,1,1],故最后一层全连接的输入维度是2048
self.out = nn.Sequential(nn.Dropout(0.2),
nn.Linear(in_features=2048, out_features=256,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(-stdv1, stdv1))),
nn.LayerNorm(256),
nn.Dropout(0.2),
nn.LeakyReLU(),
nn.Linear(in_features=256,out_features=num_classes,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(-stdv2, stdv2)))
)
def forward(self, inputs):
y = self.conv(inputs)
y = self.pool2d_max(y)
for bottleneck_block in self.bottleneck_block_list:
y = bottleneck_block(y)
y = self.pool2d_avg(y)
y = paddle.reshape(y, [y.shape[0], -1])
y = self.out(y)
return y使用搭建的网络进行模型的训练
Mode = 0 #修改此处即可训练三个不同的模型
import paddle
import paddle.nn as nn
from paddle.vision.models import resnet50, vgg16, LeNet
from paddle.vision.datasets import Cifar10
from paddle.optimizer import Momentum
from paddle.regularizer import L2Decay
from paddle.nn import CrossEntropyLoss
from paddle.metric import Accuracy
from paddle.vision.transforms import Transpose, Resize, Compose
from model import SwinResnet
# 确保从paddle.vision.datasets.Cifar10中加载的图像数据是np.ndarray类型
paddle.vision.set_image_backend('cv2')
# 加载模型
resnet = resnet50(pretrained=False, num_classes=10)
import math
stdv1 = 1.0 / math.sqrt(2048 * 1.0)
stdv2 = 1.0 / math.sqrt(256 * 1.0)
#修改resnet最后一层,加强模型拟合能力
resnet.fc = nn.Sequential(nn.Dropout(0.2),
nn.Linear(in_features=2048, out_features=256,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(-stdv1, stdv1))),
nn.LayerNorm(256),
nn.Dropout(0.2),
nn.LeakyReLU(),
nn.Linear(in_features=256,out_features=10,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(-stdv2, stdv2)))
)
model = SwinResnet(num_classes=10) if Mode == 0 else resnet
#打包模型
model = paddle.Model(model)
# 创建图像变换
transforms = Compose([Resize((224,224)), Transpose()]) if Mode != 2 else Compose([Resize((32, 32)), Transpose()])
# 使用Cifar10数据集
train_dataset = Cifar10(mode='train', transform=transforms)
valid_dadaset = Cifar10(mode='test', transform=transforms)
# 定义优化器
optimizer = Momentum(learning_rate=0.01,
momentum=0.9,
weight_decay=L2Decay(1e-4),
parameters=model.parameters())
# 进行训练前准备
model.prepare(optimizer, CrossEntropyLoss(), Accuracy(topk=(1, 5)))
# 启动训练
model.fit(train_dataset,
valid_dadaset,
epochs=40,
batch_size=80,
save_dir="./output",
num_workers=8)测试结果分析
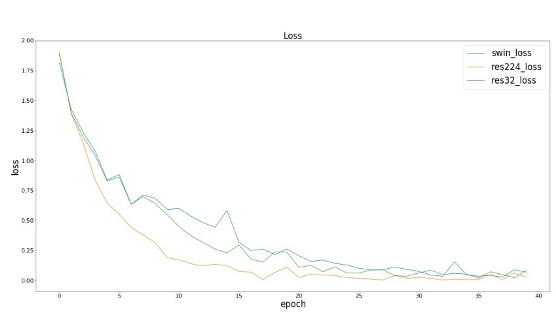
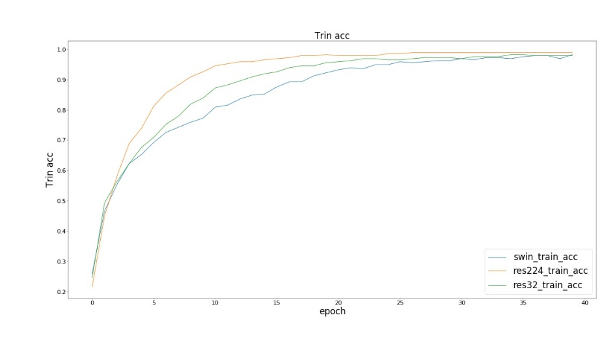
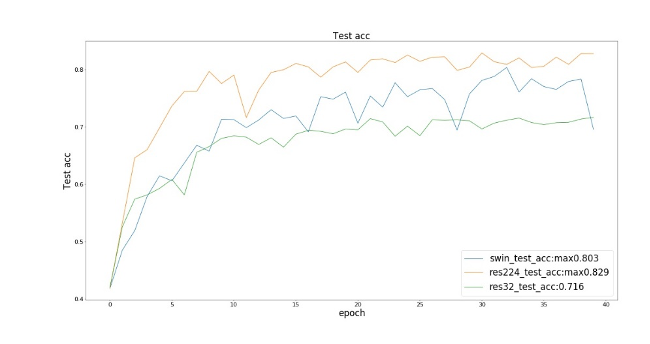
以下res224指Resnet50输入图像尺寸为224x224,res32指Resnet50输入图像尺寸为32x32。
我们观察到在训练损失和训练集精度上,三个模型(SwinResnet、res224、res32)达到的效果接近;而在测试精度上,SwinResnet精度达到80.3%,res224精度达到82.9%,res32精度达到71.6%。
① 在精度上,SwinResnet与res224差距不大,由于这是一个小数据集,所以实际上SwinResnet的能力是受限的,而且SwinResnet整体精度是几乎线性的一个提升。
② 在速度上,SwinResnet为950ms一个batch,而res224是250ms一个batch, 因此运算速度是四倍的差距实际上是可以接受的。
另一方面,我们也发现,由于Cifar10数据集图片大小实际上是32x32的,但是将其插值到224之后再接Resnet比直接接Resnet的精度提高了11.3%。这是一个巨大的提升,尽管我们没有引入任何额外的信息量。一个解释是:因为Resnet是用来做Imagenet图片分类的,而图像大小为224x224,因此不适用于32x32图片作为模型的输入,尽管两张图片的信息量完全没有差别。这揭示了卷积核对尺寸大小变化的一个不适应性,难以捕捉不同尺寸物体的信息,这是由于卷积核固定的大小所造成的。
SwinT的应用场景
> 1、使用SwinT模块搭建完整的Swin Transformer模型复现论文。
> 2、可以将现有的骨干为Conv2D的模型替换为SwinT从而搭建性能更好的网络,如Swin-Unet,以及在平常各种场景中需要叠加很多层CNN才能抽取深度特征的地方,可以将几个Conv2D层替换为一个SwinT。
> 3、由于SwinT输入输出完全同Conv2D,因此也可以用在语义分割、目标检测等复杂任务上。
> 4、可以同时使用SwinT和Conv2D进行模型搭建,在需要提取高级全局特征的时候使用SwinT在需要局部信息时使用Conv2D,非常灵活。
总结
我们将Swin Transformer最核心的模块制作成了SwinT接口,使用形式类似Conv2D。首先,这极大的方便了开发者们进行网络模型的编写,尤其是要自定义模型架构时,并混合使用Conv2D和SwinT;然后,我们认为SwinT接口的内容非常简单并且高效,因此这个接口短期内将不会过时,可以拥有时效性上的保证;最后,我们真实地对该接口进行了测试,证明了该接口的易用性以及精度性能。
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/3288357