GitHub - yzfzzz/MyWebServer: Linux高并发服务器项目,参考了TinyWebServer,将在此基础上进行性能改进与功能增加。为方便读者学习,附带详细注释和博客!

TinyWebserver的复现与改进(1):服务器环境的搭建与测试-CSDN博客
TinyWebserver的复现与改进(2):项目的整体框架-CSDN博客
TinyWebserver的复现与改进(3):线程同步机制类封装及线程池实现-CSDN博客
TinyWebserver的复现与改进(4):主线程的具体实现-CSDN博客
TinyWebserver的复现与改进(4):主线程的具体实现-CSDN博客
HTTP 协议是基于 TCP/IP 协议之上的应用层协议,基于 请求-响应 的模式。HTTP 协议规定,请求从客 户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端 在没有接收到请求之前不会发送响应。
HTTP报文的格式

下面就是一段http协议的请求报文1️⃣
GET /index.html HTTP/1.1
Host: 124.223.141.236:10000
Content-Length: 27
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
-
GET /index.html HTTP/1.1是请求行,GET是请求方法(表示向指定的资源发出显示请求),/index.html是客户端想访问的地址(有些是http://194.118.249.130:10000/index.html),HTTP/1.1是http协议的版本 -
每行语句结束后,都会有
'\r'(CR) '\n'(LF)作为结尾,这是我们判断一行行的重要语句
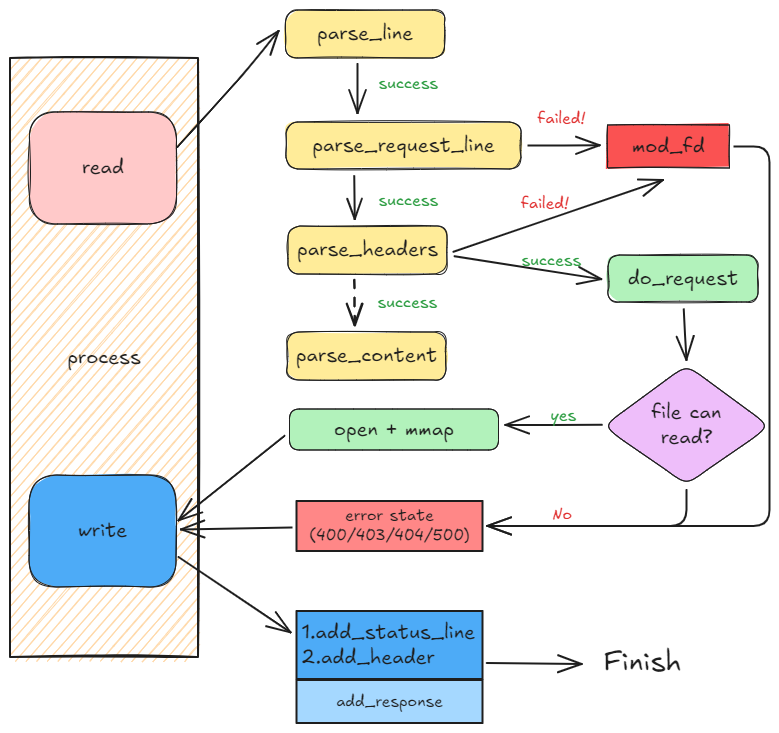
http_conn模块流程图
http_conn 模块将协议的读 read、写 write 放在了process函数里。
在 read 函数中,实现的是一个简单的有限状态机:
-
请求报文解析:程序通过
parse_line函数,依据\r\n作为分隔符,将接收到的请求报文(如1️⃣所示)逐行切割成独立的请求行(如GET /index.html HTTP/1.1)和请求头(如Host: 124.223.141.236:10000)。 -
请求行与请求头解析:随后,程序按照顺序首先尝试解析请求行(通过
parse_request_line函数)。若此步骤成功,则继续解析请求头(即首部行,通过parse_headers函数)。若请求行解析失败,则执行mod_fd操作,以准备下一次通过socket_fd接收数据,并结束当前解析过程,同时向客户端返回错误码。 -
请求处理:若请求头解析成功,则触发
do_request函数的执行。该函数负责检查请求文件的权限、类型等关键信息。若在此过程中发现任何问题,将同样向客户端返回错误码。 -
消息实体解析的省略:理论上,程序接下来会执行
parse_content函数以解析请求的消息实体部分。然而,在本代码实现中,一旦请求头解析成功,程序便直接跳转到文件检查阶段,跳过了parse_content的执行。因此,该步骤在流程图中以虚线表示,表明其在本上下文中被省略。 -
文件处理与响应发送:若文件检查成功,程序将以只读模式打开该文件,并对其进行内存映射,以便高效地处理数据。此时,虽然已准备好客户端所需的数据,但在发送之前,还需构建HTTP响应报文。这一任务由
write函数承担,它负责将HTTP响应报文连同文件内容一起发送给客户端。若文件检查失败,则同样会向客户端返回错误码。
write 函数:
-
http响应报文格式与请求报文格式相同,因此我们只需要 “看图说话即可”,在本项目中,我们的响应报文只写了请求行和请求头,其底层是基于
add_response实现的,此时我们的响应报文将会存储在写缓存区中。 -
当客户端在浏览器中输入http://194.118.249.130:10000/index.html时,说明他想发访问我们的 index.html 文件,如果一切顺利,文件会进行内存映射(将磁盘文件的数据映射到内存,用户通过修改内存就能修改磁盘文件,提高了效率),因此 index.html 文件字符串首地址和响应报文的字符串首地址不同,所以我们要使用
writev函数分散写,writev会将多个缓冲区写入同一个文件描述符fd中
小结
至此,最基本的代码已经完成了,当我们访问(http://123.226.142.236:10000/index.html(换上你的主机ip)后,会得到如下界面:

我们已经实现了服务器解析、响应GET的功能,距离复现完TinyWebServer仍有较长的路要走…
http_conn模块完整代码
http_conn.h
#pragma once
#include <arpa/inet.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <cstdarg>
#include <sys/types.h>
#include <sys/uio.h>
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
class http_conn{
public:
static int m_epollfd;
static int m_user_count;
static const int FILENAME_LEN = 200; // 文件名的最大长度
static const int READ_BUFFER_SIZE = 2048;
static const int WRITE_BUFFER_SIZE = 1024;
// 读缓冲区
char m_read_buf[READ_BUFFER_SIZE];
// 标记读缓冲区空余位置的首地址
int m_read_idx;
// 写缓冲区
char m_write_buf[WRITE_BUFFER_SIZE];
int m_write_idx;
// HTTP请求方法,这里只支持GET
enum METHOD {GET = 0, POST, HEAD, PUT, DELETE, TRACE, OPTIONS, CONNECT};
/*
解析客户端请求时,主状态机的状态
CHECK_STATE_REQUESTLINE:当前正在分析请求行
CHECK_STATE_HEADER:当前正在分析头部字段
CHECK_STATE_CONTENT:当前正在解析请求体
*/
enum CHECK_STATE { CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER,
CHECK_STATE_CONTENT };
/*
服务器处理HTTP请求的可能结果,报文解析的结果
NO_REQUEST : 请求不完整,需要继续读取客户数据
GET_REQUEST : 表示获得了一个完成的客户请求
BAD_REQUEST : 表示客户请求语法错误
NO_RESOURCE : 表示服务器没有资源
FORBIDDEN_REQUEST : 表示客户对资源没有足够的访问权限
FILE_REQUEST : 文件请求,获取文件成功
INTERNAL_ERROR : 表示服务器内部错误
CLOSED_CONNECTION : 表示客户端已经关闭连接了
*/
enum HTTP_CODE { NO_REQUEST, GET_REQUEST, BAD_REQUEST, NO_RESOURCE,
FORBIDDEN_REQUEST, FILE_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION };
// 从状态机的三种可能状态,即行的读取状态,分别表示
// 1.读取到一个完整的行 2.行出错 3.行数据尚且不完整
enum LINE_STATUS { LINE_OK = 0, LINE_BAD, LINE_OPEN };
public:
http_conn(){}
~http_conn(){}
void init(int sockfd, const sockaddr_in& addr); // sockaddr_in&: 引用
// 关闭连接
void close_conn();
// 非阻塞读
bool read();
// 非阻塞写
bool write();
void process();
private:
void init();
HTTP_CODE process_read();
bool process_write(HTTP_CODE ret);
LINE_STATUS parse_line();
HTTP_CODE parse_request_line(char* text);
HTTP_CODE parse_headers(char* text);
HTTP_CODE parse_content(char* text);
HTTP_CODE do_request();
char* getline(){return m_read_buf + m_start_line;}
void unmap();
bool add_response(const char* format, ...);
bool add_status_line(int status, const char* title);
bool add_headers( int content_length );
bool add_content_length( int content_length );
bool add_linger();
bool add_blank_line();
bool add_content_type();
bool add_content( const char* content );
private:
int m_sockfd;
int m_checked_idx; // 当前正在分析的字符在读缓冲区中的位置
sockaddr_in m_address;
CHECK_STATE m_check_state;
int m_start_line; // 当前正在解析的起始地址
char* m_url; // 客户请求的目标文件的文件名
METHOD m_method; // 请求方法
char* m_version; // HTTP协议版本号,我们仅支持HTTP1.1
int m_content_length;
bool m_linger; // HTTP请求是否要求保持连接
char* m_host; // 主机名
char m_real_file[FILENAME_LEN]; // 本地路径
struct stat m_file_stat; // 目标文件的状态。通过它我们可以判断文件是否存在、是否为目录、是否可读,并获取文件大小等信息
char* m_file_address; // 客户请求的目标文件被mmap到内存中的起始位置
struct iovec m_iv[2]; // 从多个不同(不连续)的内存区域收集数据发送到一个网络套接字
int m_iv_count;
int bytes_to_send; // 将要发送的数据的字节数
int bytes_have_send; // 已经发送的字节数
};
void addfd(int epollfd, int fd, bool one_shot);
void removefd(int epollfd, int fd);
int setnonblocking(int fd);
http_conn.c
#include "http_conn.h"
// 定义HTTP响应的一些状态信息
const char* ok_200_title = "OK";
const char* error_400_title = "Bad Request";
const char* error_400_form = "Your request has bad syntax or is inherentlyimpossible to satisfy.\n";
const char* error_403_title = "Forbidden";
const char* error_403_form = "You do not have permission to get file from thisserver.\n";
const char* error_404_title = "Not Found";
const char* error_404_form = "The requested file was not found on thisserver.\n";
const char* error_500_title = "Internal Error";
const char* error_500_form = "There was an unusual problem serving the requestedfile.\n";
// 网站的根目录
const char* doc_root = "/home/My_WebServer/resources";
int setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
// 将客户端的socket_fd加入到epoll_fd中
void addfd(int epollfd, int fd, bool one_shot)
{
epoll_event event;
event.data.fd = fd;
// event.events是32位的掩码, EPOLLIN/EPOLLRDHUP表示在32bit的二进制上,只有1bit是1,其余都是0
// event.events = EPOLLIN | EPOLLRDHUP;
// 设为边沿触发
event.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
// 设置该fd只能接受一次数据,再想接收需要调用modfd()函数
if(one_shot)
{
event.events |= EPOLLONESHOT;
}
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
// 设置文件描述符为非阻塞
setnonblocking(fd);
}
// 所有socket上的事件都被注册到同一个epoll内核事件中,所以设置成静态的
int http_conn::m_epollfd = -1;
// 所有的客户数
int http_conn::m_user_count = 0;
// 将客户端的socket_fd从epoll_fd中移除
void removefd(int epollfd, int fd)
{
epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, 0);
close(fd);
}
// 设置该fd只能接受一次数据,再想接收需要调用modfd()函数
void modfd(int epollfd, int fd, int ev)
{
epoll_event event;
event.data.fd = fd;
event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;
epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event);
}
// http_conn类的初始化, 实际上是客户端socket_fd的初始化
void http_conn::init(int sockfd, const sockaddr_in& addr)
{
m_sockfd = sockfd;
// 一个常量可以赋值给一个变量
m_address = addr;
// 设置端口复用
int reuse = 1;
setsockopt(m_sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse));
addfd(m_epollfd, sockfd, true);
m_user_count++;
init();
}
// http_conn类各个成员变量的初始化
void http_conn::init()
{
bytes_to_send = 0;
bytes_have_send = 0;
m_check_state = CHECK_STATE_REQUESTLINE; // 初始状态为检查请求行
m_linger = false; // 默认不保持链接 Connection : keep-alive保持连接
m_method = GET; // 默认请求方式为GET
m_url = 0;
m_version = 0;
m_content_length = 0;
m_host = 0;
m_start_line = 0;
m_checked_idx = 0;
m_read_idx = 0;
m_write_idx = 0;
// !内存地址的计算: 成员变量的存储时连续的吗
bzero(m_read_buf, READ_BUFFER_SIZE);
bzero(m_write_buf, WRITE_BUFFER_SIZE);
bzero(m_real_file, FILENAME_LEN);
}
void http_conn::close_conn()
{
if(m_sockfd != -1)
{
removefd(m_epollfd, m_sockfd);
m_sockfd = -1;
m_user_count--; // 关闭一个连接,客户总量-1
}
}
bool http_conn::read()
{
if(m_read_idx >= READ_BUFFER_SIZE)
{
// 读缓冲满了, 应用层还未处理该缓冲区数据
return false;
}
int byte_read = 0;
while(1)
{
byte_read = recv(m_sockfd, m_read_buf+m_read_idx, READ_BUFFER_SIZE-m_read_idx, 0);
if(byte_read == -1)
{
if(errno == EAGAIN || errno == EWOULDBLOCK)
{
// 没有数据
break;
}
return false;
}
else if(byte_read == 0)
{
// 对方关闭连接
return false;
}
m_read_idx += byte_read;
}
// printf("%s\n", m_read_buf);
return true;
}
// 解绑内存映射
void http_conn::unmap()
{
if(m_file_address)
{
munmap(m_file_address, m_file_stat.st_size);
m_file_address = 0;
}
}
bool http_conn::write()
{
int temp = 0;
if(bytes_to_send == 0)
{
// 将要发送的字节为0,本次响应结束
modfd(m_epollfd, m_sockfd, EPOLLIN);
init();
return true;
}
while(1)
{
// 分散写
temp = writev(m_sockfd, m_iv, m_iv_count);
if(temp <= -1)
{
// 如果tcp没有写缓冲的空间,则等待下一轮可写事件
if(errno == EAGAIN)
{
modfd(m_epollfd, m_sockfd, EPOLLOUT);
return true;
}
unmap();
return false;
}
bytes_to_send -= temp;
bytes_have_send += temp;
// 发完m_iv[0]了
if(bytes_have_send >= m_iv[0].iov_len)
{
m_iv[0].iov_len = 0;
m_iv[1].iov_base = m_file_address +(bytes_have_send-m_write_idx);
m_iv[1].iov_len = bytes_to_send;
}
// 发完m_iv[0]的部分数据,还有一部分没发
else
{
m_iv[0].iov_base = m_write_buf + bytes_have_send;
m_iv[0].iov_len = m_iv[0].iov_len - temp;
}
if(bytes_to_send <= 0)
{
// 没有数据要发送了
unmap();
modfd(m_epollfd, m_sockfd, EPOLLIN);
if(m_linger)
{
init();
return true;
}
else
{
return false;
}
}
}
}
// 预处理, 解析出一行一行, 判断依据: \r\n
http_conn::LINE_STATUS http_conn::parse_line()
{
char temp;
for(;m_checked_idx < m_read_idx; m_checked_idx++)
{
temp = m_read_buf[m_checked_idx];
if(temp == '\r')
{
if((m_checked_idx+1) == m_read_idx)
{
// 数据不完整
return LINE_OPEN;
}
else if(m_read_buf[m_checked_idx+1] == '\n')
{
m_read_buf[m_checked_idx++] = '\0'; // 先变成'\0', 再+1
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
// 上一次末尾是'\r', 这一次开头是'\n'
else if(temp == '\n')
{
if((m_checked_idx > 1)&&(m_read_buf[m_checked_idx-1]=='\r'))
{
m_read_buf[m_checked_idx-1] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
}
return LINE_OPEN;
}
// 对请求行进行处理, 获取请求方法、目标URL、HTTP版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char* text)
{
// 需要解析的请求行内容: GET /index.html HTTP/1.1
m_url = strpbrk(text, " "); // 找出第一个 " "在text出现的位置
if(!m_url)
{
return BAD_REQUEST;
}
*m_url++ = '\0'; // m_url 当前指向的地址被解引用(*m_url),然后将这个位置的字符设置为 '\0'。然后,将 m_url 自增,使其指向下一个字符的位置。
// 当前请求行内容: GET\0/index.html HTTP/1.1
char* method = text;
if(strcasecmp(method, "GET") == 0)
{
// 忽略大小写比较
m_method = GET;
}
else
{
return BAD_REQUEST;
}
// 此时m_url经过++后,指向 /index.html HTTP/1.1
m_version = strpbrk(m_url, " ");
if(!m_version)
{
return BAD_REQUEST;
}
*m_version++ = '\0';
// m_version指向 HTTP/1.1
if(strcasecmp(m_version, "HTTP/1.1") != 0)
{
return BAD_REQUEST;
}
// 有些请求不是 /index.html, 而是 http://192.168.110.129:10000/index.html
if(strncasecmp(m_url, "http://", 7) == 0)
{
m_url += 7;
// m_url指向 192.168.110.129:10000/index.html
m_url = strchr(m_url, '/'); // s搜索字符串中第一次出现 '/’ 的位置
}
// m_url指向 /index.html
if(!m_url || m_url[0] != '/')
{
return BAD_REQUEST;
}
// 检查状态变成检查头
m_check_state = CHECK_STATE_HEADER;
return NO_REQUEST;
}
http_conn::HTTP_CODE http_conn::parse_headers(char* text)
{
// 因为parse_line()预处理时,已经把\r\n替换为\0\0
if(text[0] == '\0')
{
// 如果HTTP请求有消息体,则还需要读取m_content_length字节的消息体,
// 状态机转移到CHECK_STATE_CONTENT状态
if(m_content_length != 0)
{
m_check_state = CHECK_STATE_CONTENT;
return NO_REQUEST;
}
// 否则得到一个完整的HTTP请求
return GET_REQUEST;
}
else if(strncasecmp(text, "Connection:", 11) == 0)
{
// 处理Connection字段 Connection: keep-alive
text += 11;
text += strspn(text, " "); // 返回text字符串中,前缀部分(' ')的长度
if(strcasecmp(text, "keep-alive") == 0)
{
m_linger = true;
}
}
else if(strncasecmp(text, "Content-Length:", 15) == 0)
{
// 处理Content-Length头部字段
text +=15;
text += strspn(text, " ");
m_content_length = atoi(text);
}
else if(strncasecmp(text, "HOST:", 5) == 0)
{
// 处理HOST头部字段
text += 5;
text += strspn(text, " ");
m_host = text;
}
else
{
printf("oop! unknow header %s\n", text);
}
return NO_REQUEST;
}
// 解析HTTP请求的消息体
http_conn::HTTP_CODE http_conn::parse_content(char* text)
{
if(m_read_idx >= (m_content_length + m_checked_idx))
{
text[m_content_length] = '\0';
return GET_REQUEST;
}
return NO_REQUEST;
}
// 当得到一个完整、正确的HTTP请求时,我们就分析目标文件的属性,
// 如果目标文件存在、对所有用户可读,且不是目录,则使用mmap将其
// 映射到内存地址m_file_address处,并告诉调用者获取文件成功
http_conn::HTTP_CODE http_conn::do_request()
{
// "/home/WebServer/resources"
strcpy(m_real_file, doc_root); // 于将一个字符串(doc_root)复制到另一个字符串(m_real_file)中
int len = strlen(doc_root);
// strncpy 从源字符串m_url复制最多FILENAME_LEN-len-1字符到目标字符串m_real_file+len中。
// 如果m_url的长度小于FILENAME_LEN-len-1,则m_real_file+len中剩余的部分会用空字符 '\0' 填充
strncpy(m_real_file+len, m_url, FILENAME_LEN-len-1);
// 获取文件的状态
if(stat(m_real_file, &m_file_stat) < 0)
{
return NO_RESOURCE;
}
// 判断访问权限
if(!(m_file_stat.st_mode & S_IROTH))
{
return FORBIDDEN_REQUEST;
}
// 判断是否为目录
if(S_ISDIR(m_file_stat.st_mode))
{
return BAD_REQUEST;
}
// 以只读的方式打开文件
int fd = open(m_real_file, O_RDONLY);
// !创建内存映射
m_file_address = (char*)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
close(fd);
return FILE_REQUEST;
}
// 客户端一旦请求,服务器就发送数据给客户端
void http_conn::process()
{
// 客户端发送请求, 服务器解析http请求
HTTP_CODE read_ret = process_read();
if(read_ret == NO_REQUEST)
{
modfd(m_epollfd, m_sockfd, EPOLLIN);
return;
}
// 生成响应,服务器发送数据给客户端
bool write_ret = process_write(read_ret);
if(!write_ret)
{
close_conn();
}
// 表示有数据发送
modfd(m_epollfd, m_sockfd, EPOLLOUT);
}
// 主状态机, 解析请求
http_conn::HTTP_CODE http_conn::process_read()
{
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char* text = 0;
// CHECK_STATE_CONTENT:当前正在解析请求体
while( ((m_check_state == CHECK_STATE_CONTENT)&&(line_status == LINE_OK)) ||
((line_status = parse_line()) == LINE_OK) )
{
// 成功读到一行
text = getline();
// 更新下一次解析的起始位置
m_start_line = m_checked_idx;
// printf("got a http line: %s\n", text);
switch(m_check_state)
{
// 解析请求行
case CHECK_STATE_REQUESTLINE:
{
ret = parse_request_line(text);
if(ret == BAD_REQUEST)
{
return BAD_REQUEST;
}
break;
}
// 解析请求头
case CHECK_STATE_HEADER:
{
ret = parse_headers(text);
if(ret == BAD_REQUEST)
{
return BAD_REQUEST;
}
else if(ret == GET_REQUEST)
{
return do_request();
}
break;
}
// 解析消息体
case CHECK_STATE_CONTENT:
{
ret = parse_content(text);
if(ret == GET_REQUEST)
{
if(ret == GET_REQUEST)
{
return do_request();
}
// 有错误,退出解析循环
line_status = LINE_OPEN;
break;
}
}
default:{
/*
指代系统、应用程序或服务内部发生的错误,这种错误通常是由于程序或系统内部逻辑问题、配置错误、
或意外状态引起的。它不是由用户操作引起的错误,而是由于代码或系统状态的缺陷所导致的。
*/
return INTERNAL_ERROR;
}
}
}
}
// !!! 往写缓冲区中发送数据
// 函数声明中的`...`(称为可变参数列表或省略号)表示该函数可以接受一个不确定数量的参数,这些参数的类型和数量在编译时是不确定的
bool http_conn::add_response(const char* format, ...)
{
if(m_write_idx >= WRITE_BUFFER_SIZE)
{
return false;
}
va_list arg_list; // 可变参数列表类型
va_start(arg_list, format); // 设置了 arg_list 变量,使其指向 format 参数之后的位置
int len = vsnprintf(m_write_buf+m_write_idx, WRITE_BUFFER_SIZE-1-m_write_idx, format, arg_list);
if(len >= (WRITE_BUFFER_SIZE-1-m_write_idx))
{
return false;
}
m_write_idx += len;
va_end(arg_list);
return true;
}
bool http_conn::add_status_line(int status, const char* title)
{
return add_response("%s %d %s\r\n", "HTTP/1.1", status, title);
}
bool http_conn::add_headers(int content_len)
{
add_content_length(content_len);
add_content_type();
add_linger();
add_blank_line();
}
bool http_conn::add_content_length(int content_length)
{
return add_response("Content-Length: %d\r\n", content_length);
}
bool http_conn::add_linger()
{
return add_response("Connection: %s\r\n", (m_linger == true)? "keep-alive":"close");
}
bool http_conn::add_blank_line()
{
return add_response("%s", "\r\n");
}
bool http_conn::add_content_type()
{
return add_response("Content-Type:%s\r\n", "text/html");
}
bool http_conn::add_content( const char* content )
{
return add_response( "%s", content );
}
bool http_conn::process_write(HTTP_CODE ret)
{
switch(ret)
{
case INTERNAL_ERROR:
add_status_line(500, error_500_title);
add_headers(strlen(error_500_form));
if(!add_content(error_500_form))
{
return false;
}
break;
case BAD_REQUEST:
add_status_line(400, error_400_title);
add_headers(strlen(error_400_form));
if(!add_content(error_400_form))
{
return false;
}
break;
case NO_RESOURCE:
add_status_line(404, error_404_title);
add_headers(strlen(error_404_form));
if(!add_content(error_404_form))
{
return false;
}
break;
case FORBIDDEN_REQUEST:
add_status_line(403, error_403_title);
add_headers(strlen(error_403_form));
if(!add_content(error_403_form))
{
return false;
}
break;
case FILE_REQUEST:
add_status_line(200, ok_200_title);
add_headers(m_file_stat.st_size);
// iov_base 是一个指向缓冲区的指针,该缓冲区包含要读取或写入的数据。
// iov_len 指定了 iov_base 指向的缓冲区中数据的长度(以字节为单位)
// m_iv[0]: 响应数据报
// m_iv[1]: 网页数据
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv[1].iov_base = m_file_address;
m_iv[1].iov_len = m_file_stat.st_size;
m_iv_count = 2;
bytes_to_send = m_write_idx + m_file_stat.st_size;
return true;
default:
return false;
}
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv_count = 1;
bytes_to_send = m_write_idx;
return true;
}