大家好,我是herosunly。985院校硕士毕业,现担任算法t研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。
本文详细介绍了大模型微调数据集构建方法,希望能对学习大模型的同学们有所帮助。
1. 前言
随着时间的齿轮转动到2024年,各种行业大模型如雨后春笋般涌现。如何基于基座模型和领域数据构建行业大模型成为了近期研究和落地的热点方向。因此基于大模型进行微调和部署成为了大多数企业的日常操作,但模型微调存在相当的技术门槛,稍有差池或者经验不足极易造成过拟合(严重的灾难性遗忘)、或者欠拟合(无法有效学习特定领域知识)的情形。
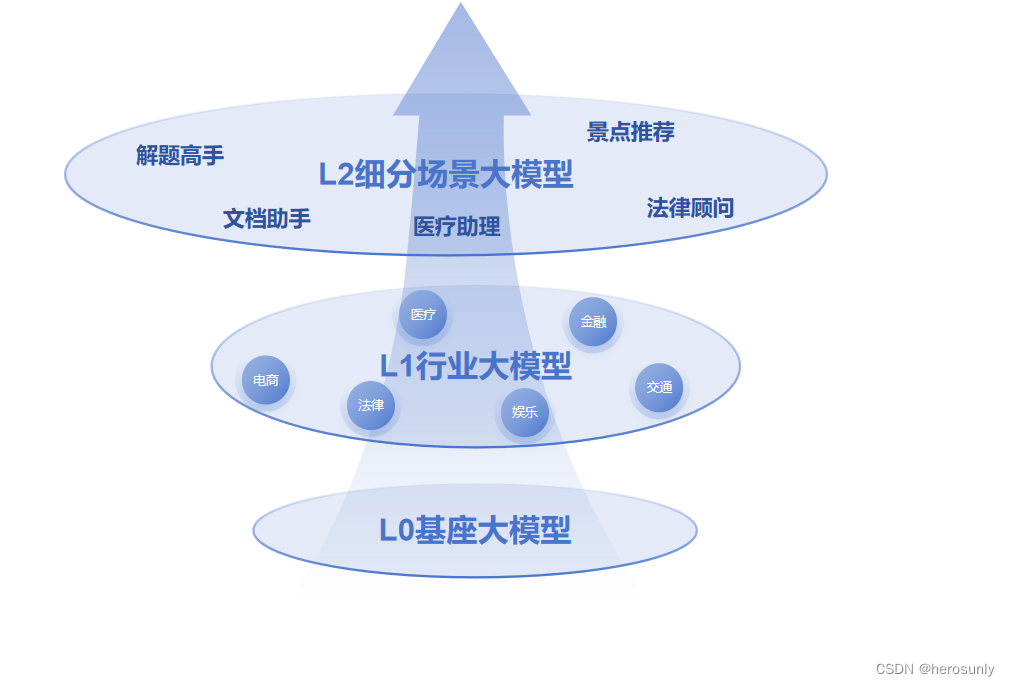
在之前的文章