Compressing Pre-trained Models of Code into 3 MB
key word: code PLM, compression, GA算法
论文:https://dl.acm.org/doi/pdf/10.1145/3551349.3556964
代码:https://github.com/soarsmu/Compressor.git
【why】
1.问题描述: code LLM 在广泛使用过程中存在障碍,模型占内存大+在个人设备上运行缓慢
2. Idea的起源:vscode建议发布 IDE组件 or 编辑器插件 给用户的开发者,将组件大小限制为50MB,3MB的模型为最佳模型大小,且延时应被降至0.1s
3. 现有的方法存在的问题:
model pruning ===> 无法将codeBERT和GraphCodeBERT压缩至50MB以下
model quantization ===> 压缩后的模型在推理上并不快或消耗更少的CPU内存,且在运行时需要专门的硬件
knowledge distillation ===> 知识蒸馏训练一个小的student model去模仿一个大的teacher model,但是小模型不能有效的从大模型中吸收知识
4. 解决上述问题,获得一个合适的模型结构的挑战:
(1)寻找合适的体系结构本质上是一个搜索空间巨大的组合问题
(2)通过训练和测试来评估每个可能的候选模型在计算上是不可行的,从而难以指导搜索
【what】
提出了 Compressor,通过遗传算法将PLM压缩成极小的模型,而性能损失忽略不计。
利用遗传算法搜索,知识蒸馏找到小模型,利用预训练模型中的知识对小模型训练
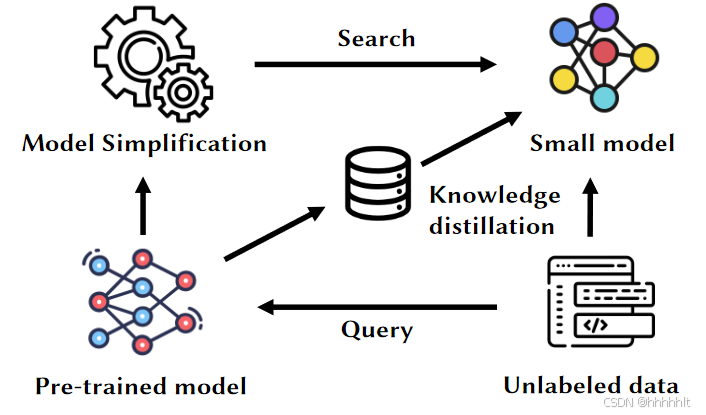
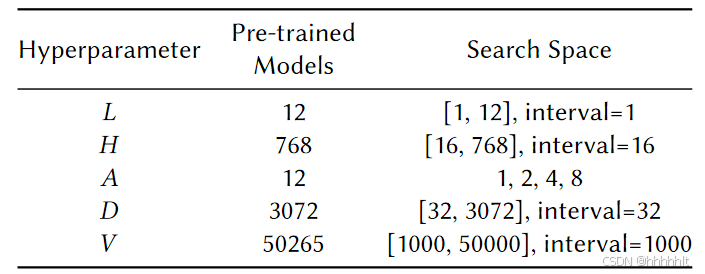
- 问题搜索空间
调整网络层数( L ),网络层的维度( H ),注意力头的数量( A ),前馈层的维度( D )和词汇量( V )
- GA 算法指导模型简化
(1)Chromosome Representation => 通过随机设置其中每个键值对的值
(2)Fitness Function => 衡量候选目标的质量。
使用 GFLOPs 表示计算模型需要进行前向传递的乘法和累加操作的次数,更大的 GFLOPs 意味着模型具有更大的capacity。
T 表示给定的模型大小,ts 表示 微小模型的尺寸。| ts-T | 是当前搜索模型的模型尺寸与目标模型尺寸的差值。
(3)Operators & Selection
算子选择使用算法:crossover (r的概率) & mutation (1-r的概率) - 使用 unlabeled 数据进行数据蒸馏
应用特定于下游任务的蒸馏方法 Distilling the Knowledge in a Neural Network 。将 unlabeled data 输入到PLM中,收集 output probability values,接着训练获得的 tiny model。
训练的loss函数为:
n表示训练样本数,pi是大模型输出,qi是小模型输出

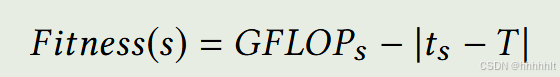
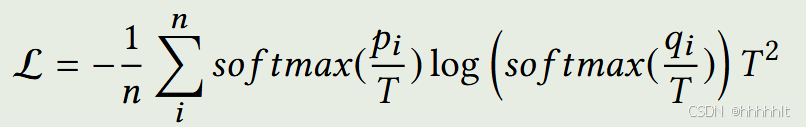
【how】
1.实验配置
硬件环境: Ubuntu 18.04 server with an Intel Xeon E5-2698 CPU, 504GB RAM, and 8 Tesla P100 GPUs
模型: CodeBert and GraphCodeBert
下游任务和数据集:
Vulnerability Prediction ==> Devign,是CodeXGLUE中的一部分
Clone Detection ==> BigCloneBench
GA算法: 保存50个候选模型,crossover rate = 0.6,迭代次数为 100
衡量指标: computational cost [GFLOPS]
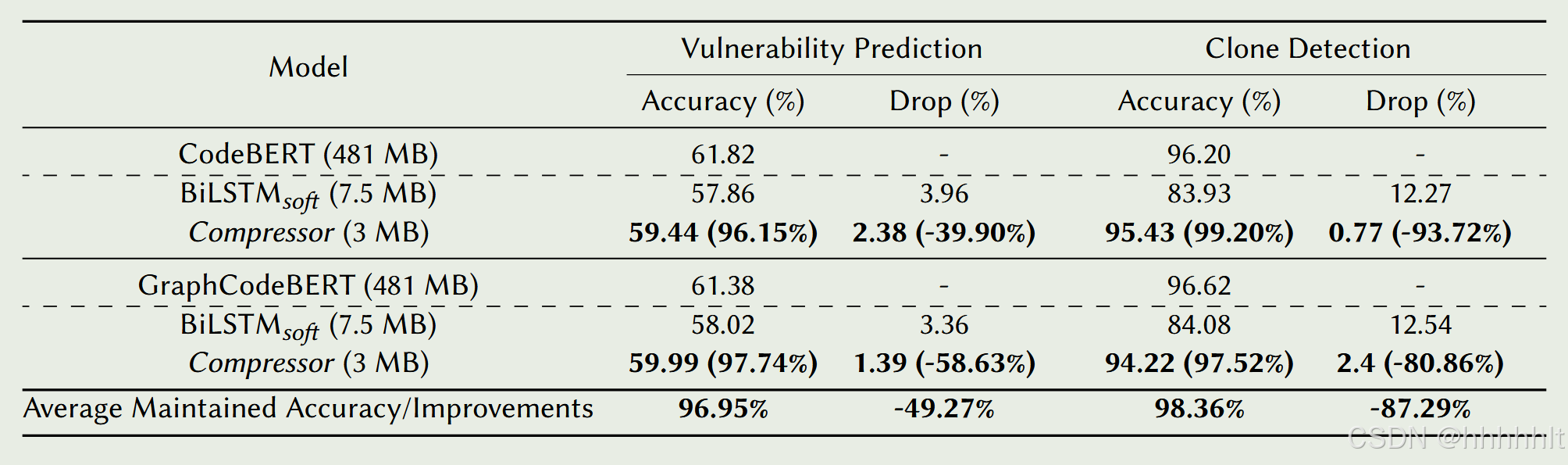
baseline: 基于特定任务的知识蒸馏方法BiLSTMsoft,其能将模型压缩至7.5MB左右
2.实验结果
(1)精度下降 + 模型缩小率
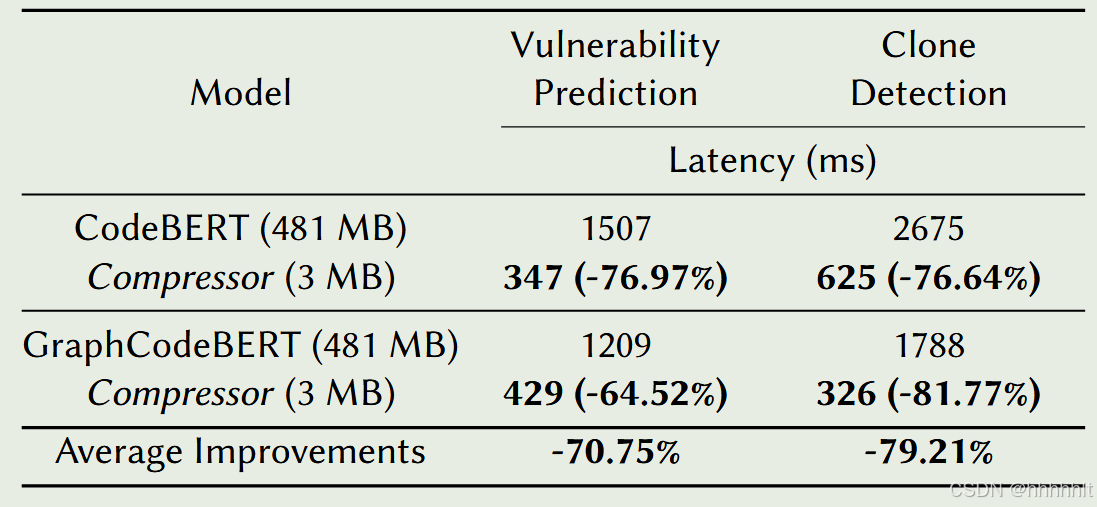
(2)延时比较
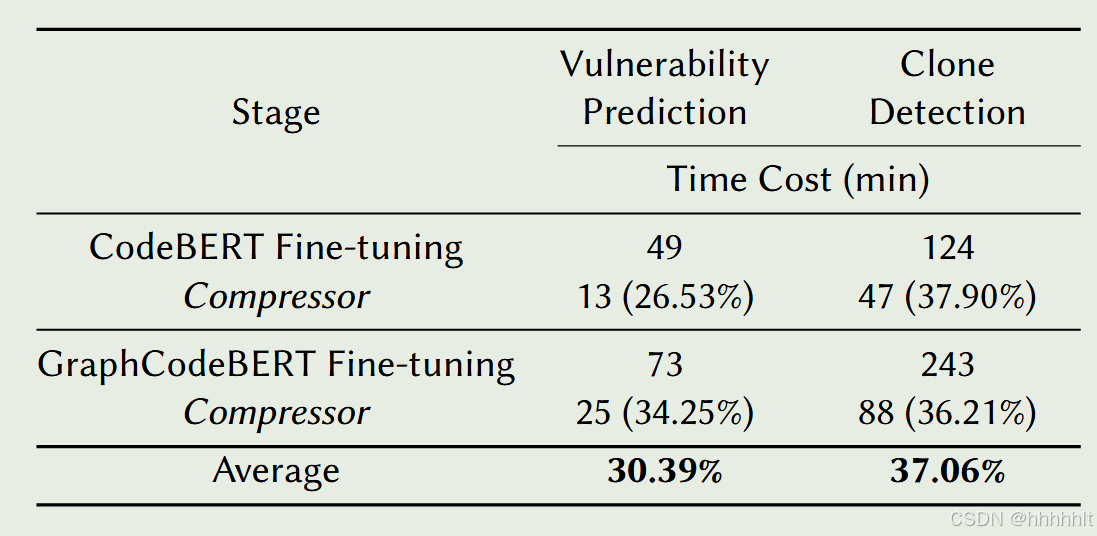
(3)压缩预训练模型所需使用的时间
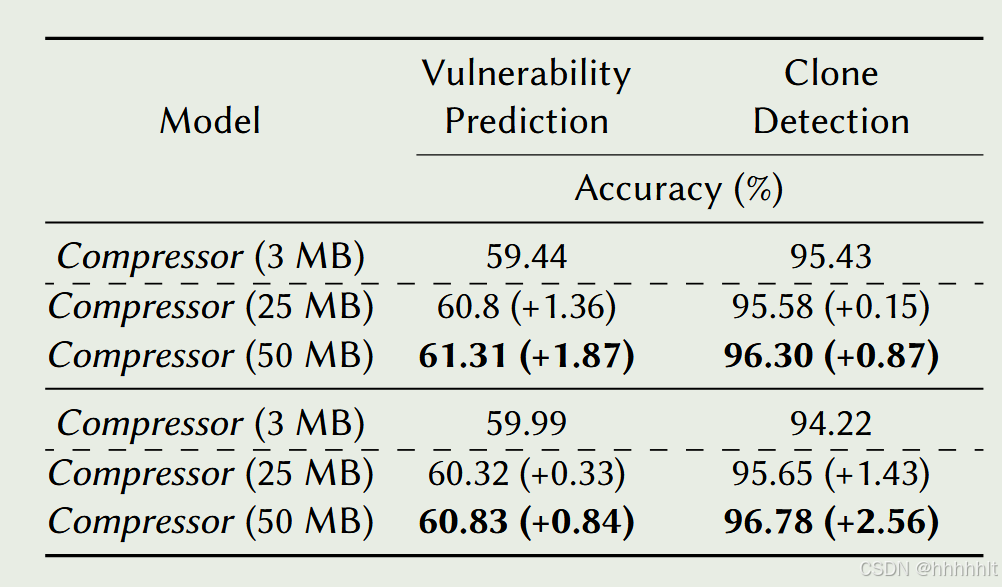
(4)模型大小与模型精度的关系