论文阅读 Unveiling Memorization in Code Models
key word: LLM for SE, security and privacy
论文链接:https://arxiv.org/abs/2308.09932
仓库链接:https://github.com/yangzhou6666/Privacy-in-CodeModels
【why】
现存模型的出色表现可以归因于先进模型架构的组合(例如Transformer模型等)。尽管取得了显著的进步,但它们面临着一系列隐私和法律挑战。
- 例子
- CoPILOT在其输出中被发现会产生真实的人名和物理地址。
- 三星公司的员工通过ChatGPT意外泄露了公司的机密,ChatGPT保留了这些对话的记录,并可能使用这些数据来训练它的系统。
代码模型可能记住的且可能造成隐私泄露的数据:
software secrets , vuluerable or even malicious code , intellectual property issues
因此,本文探索代码大模型记忆其训练数据能力。
【what】
1.从代码模型中生成输出
4种策略生成代码模型的输出
| 策略 | 特点 |
|---|---|
| Non-Prompt Generation (NPG) | 从initial prompt<s>开始生成输出 |
| Temperature-Decaying Generation (TDG) | 由于NPG缺少多样性 — 根据temperature控制输出多样性的特点,在初始阶段使用高温度,然后逐渐降低 |
| Prompt-Conditioned Generation (PCG) | 由于NPG往往产生很多的许可证信息 — 提取函数定义语句并将其作为提示 |
| Two-Step Generation (TSG) | 使用NPG识别处记忆后,将频率最高的记忆作为提示发送给代码模型补全 |
2. 记忆检测
Type1-clone : 精确克隆 or 相同克隆
是指两个或两个以上的代码片段完全相同的一种特定类型的代码复制,意味着一个模型从训练数据中逐字输出,这是一个更强的记忆证据。
Simian : 识别生成代码 和 训练数据 间的Type1-clone,且只考虑代码长度大于6行的克隆段。
3.记忆预测
在不访问训练数据的情况下,推断一个输出是否包含记忆内容。
记录这个的作用是:如果恶意用户能够正确地推断记忆,那么关于训练数据(例如,私有代码或软件秘密)的信息可能会被泄露,从而带来潜在的安全风险。
| 指标 | 含义 | 衡量标准 |
|---|---|---|
| perplexity | 语言模型对样本的预测能力如何 | 较低的困惑度值可能表明模型进行了回忆 |
| PPL-PPL ratio | 在重要数据上大模型比小模型具有更小的困惑度 | l o g ( P l ) l o g ( P s ) \frac{log(P_l)}{log(P_s)} log(Ps)log(Pl),较小的比例证明输出更可能包含重要记忆 |
| PPL-zlib retio | zlib是一个数据压缩库,一个重复的输入代表更小的zlib熵 | l o g ( P v ) z l i b \frac{log(P_v)}{zlib} zliblog(Pv),较小的比例说明这个输出的文本更可能被记忆,但是重复的可能性较小 |
| Average PPL | 由于记忆的内容可能被非记忆的输出所包围,设计了一个六行的滑动的窗口 | 计算每个窗口的困惑度,然后计算所有窗口的平均PPL,平均PPL对输出进行升序排列 |
【how】
代码模型:CodeParrot(基于1.5B的GPT2), CodeParrot-small(基于110M的GPT2)
数据集:CodeParrot数据集,由Google‘s的BigQuery创建
硬件环境:an NVIDIA GeForce A5000 GPU with 24 GB of memory
【result】
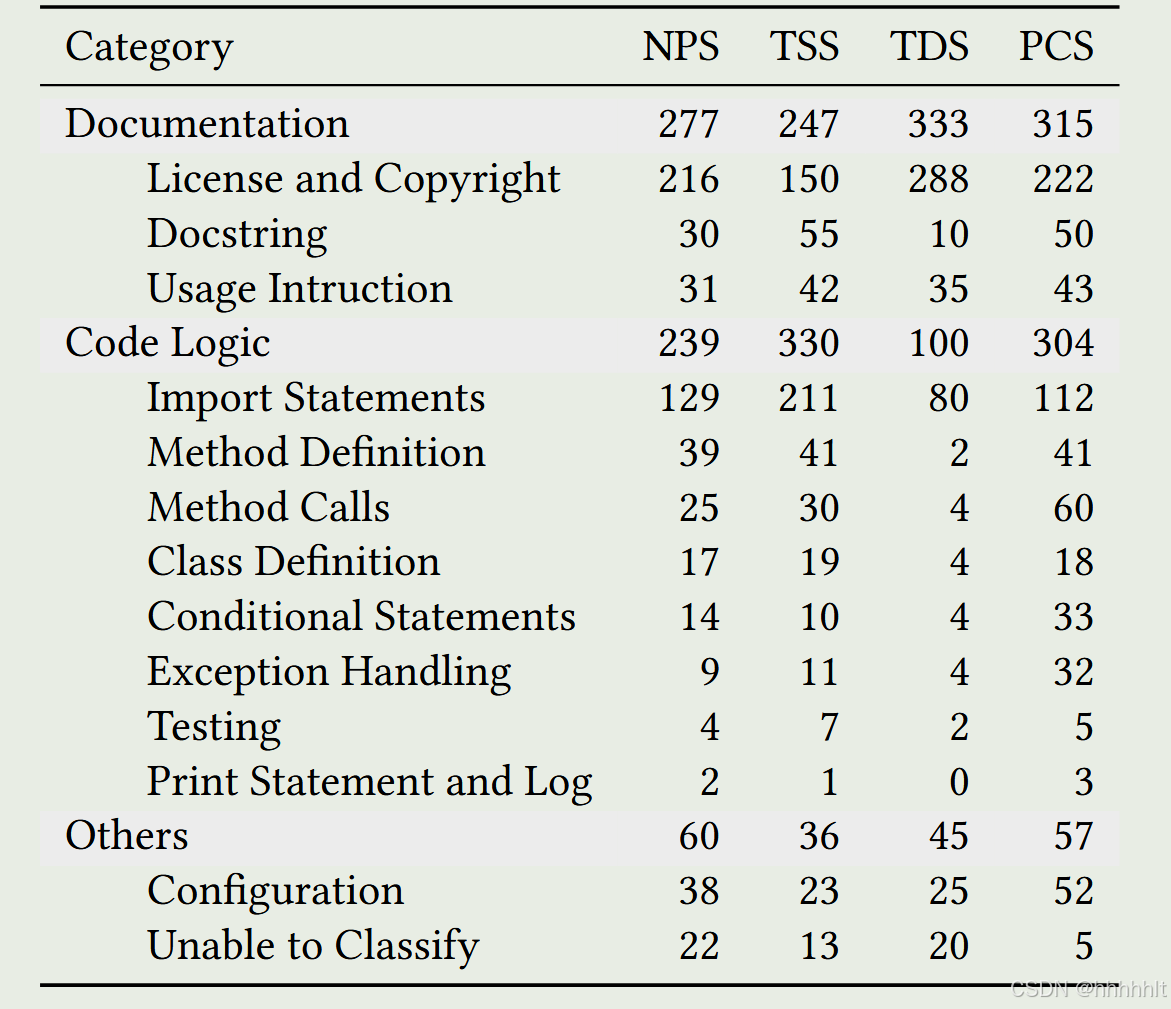
- code model 记住了什么信息的统计数据
我比较关注的sensitive information的检测,其中 detect-secrets
可以扫描产生的敏感信息
- 什么因素影响记忆
( 1 )给定相同架构的模型尺寸;
( 2 ) top - k采样中的超参数k;
( 3 )生成输出的长度;
( 4 )生成产出数量;
( 5 )代码片段在训练数据中出现的频率。 - 如何判断一个输出中包含记忆信息 (假设不知道训练数据)
四个指标中有三个可以准确地推断记忆。PPL - PPL比值排名靠前的识记多样性较高,而其他指标排名靠前的识记主要是许可信息。
可能有用的参考文献:
- Setu Kumar Basak, Lorenzo Neil, Bradley Reaves, and Laurie Williams. 2023. SecretBench: A Dataset of Software Secrets. In Proceedings of the 20th International Conference on Mining Software Repositories (MSR ’23). 5 pages.
- Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel HerbertVoss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. 2021. Extracting Training Data from Large Language Models. In USENIX Security Symposium.
- Runhan Feng, Ziyang Yan, Shiyan Peng, and Yuanyuan Zhang. 2022. Automated Detection of Password Leakage from Public GitHub Repositories. In 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE). 175–186. https://doi.org/10.1145/3510003.3510150
- David Lo. 2023. Trustworthy and Synergistic Artificial Intelligence for Software Engineering: Vision and Roadmaps. arXiv:2309.04142 [cs.SE]
- Ali Al-Kaswan and Maliheh Izadi. 2023. The (ab)use of Open Source Code to Train Large Language Models. arXiv:2302.13681 [cs.SE]