文章目录
从CSDN博客链接至看到苏老师的博客对VAE的解读,感觉豁然开朗,遂自己将整个过程结合部分其他博客的点总结在一起,当做笔记记录,因为苏老师的博客在手机上看时有些公式看不完全,最后将苏老师参考的博客与链接放置在来源参考部分。
本文的符号表

变分自编码器(Variational Auto-Encoder,VAE),原论文《Auto-Encoding Variational Bayes》
目标:希望构建一个从隐变量Z生成目标数据X的模型,假设了Z服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型X=g(Z),这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,目的是进行分布之间的变换。
那现在假设Z服从标准的正态分布,那么我就可以从中采样得到若干个
Z
1
Z_1
Z1,
Z
2
Z_2
Z2,…,
Z
n
Z_n
Zn,然后对它做变换得到
X
1
宝盖
=
g
(
Z
1
)
X_1宝盖=g(Z_1)
X1宝盖=g(Z1),
X
2
宝盖
=
g
(
Z
2
)
X_2宝盖=g(Z_2)
X2宝盖=g(Z2),…,
X
n
宝盖
=
g
(
Z
n
)
X_n宝盖=g(Z_n)
Xn宝盖=g(Zn),我们怎么判断这个通过g构造出来的数据集,它的分布跟我们目标的数据集分布是不是一样的呢?有读者说不是有KL散度吗?当然不行,因为KL散度是根据两个概率分布的表达式来算它们的相似度的,然而目前我们并不知道它们的概率分布的表达式,我们只有一批从构造的分布采样而来的数据{
X
1
宝盖
X_1宝盖
X1宝盖,
X
2
宝盖
X_2宝盖
X2宝盖,…,
X
n
宝盖
X_n宝盖
Xn宝盖},还有一批从真实的分布采样而来的数据{
X
1
X_1
X1,
X
2
X_2
X2,…,
X
n
X_n
Xn}(也就是我们希望生成的训练集)。我们只有样本本身,没有分布表达式,当然也就没有方法算KL散度。
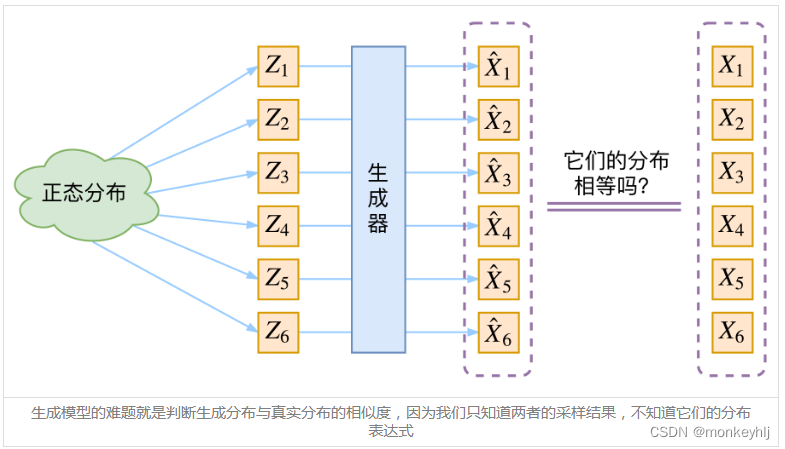
回顾
首先我们有一批数据样本{
X
1
X_1
X1,
X
2
X_2
X2,…,
X
n
X_n
Xn},其整体用X来描述,我们本想根据{
X
1
X_1
X1,
X
2
X_2
X2,…,
X
n
X_n
Xn}得到
X
X
X的分布
p
(
X
)
p(X)
p(X),如果能得到的话,那我直接根据
p
(
X
)
p(X)
p(X)来采样,就可以得到所有可能的
X
X
X了(包括{
X
1
X_1
X1,
X
2
X_2
X2,…,
X
n
X_n
Xn}以外的),这是一个终极理想的生成模型了。当然,这个理想很难实现,于是我们将分布改一改
这里我们就不区分求和还是求积分了,意思对了就行。此时
p
(
X
∣
Z
)
p(X|Z)
p(X∣Z)就描述了一个由
Z
Z
Z来生成
X
X
X的模型,而我们假设
Z
Z
Z服从标准正态分布,也就是
p
(
Z
)
=
N
(
0
,
I
)
p(Z)=N(0,I)
p(Z)=N(0,I)。如果这个理想能实现,那么我们就可以先从标准正态分布中采样一个
Z
Z
Z,然后根据
Z
Z
Z来算一个
X
X
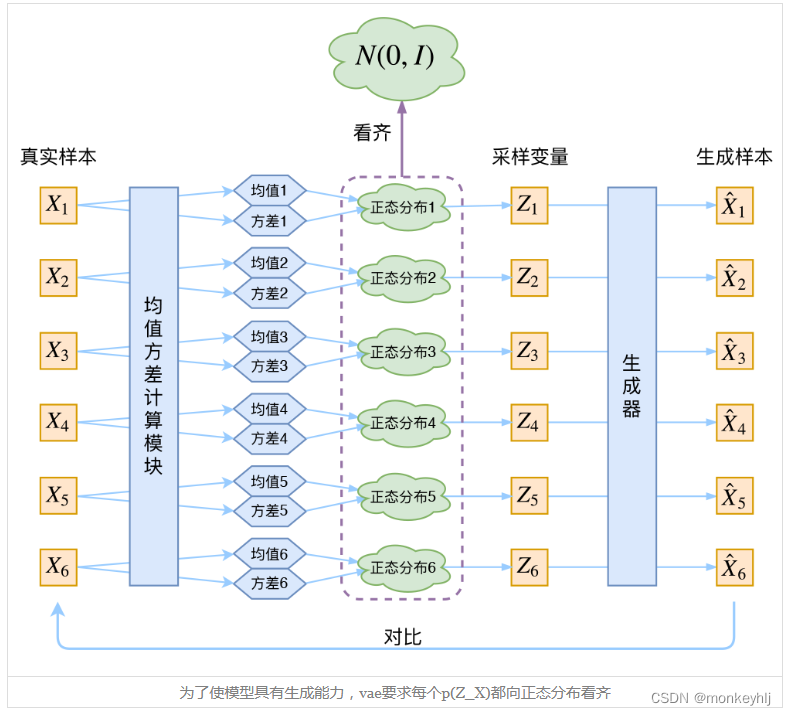
X,也是一个很棒的生成模型。接下来就是结合自编码器来实现重构,保证有效信息没有丢失,再加上一系列的推导,最后把模型实现。框架的示意图如下:

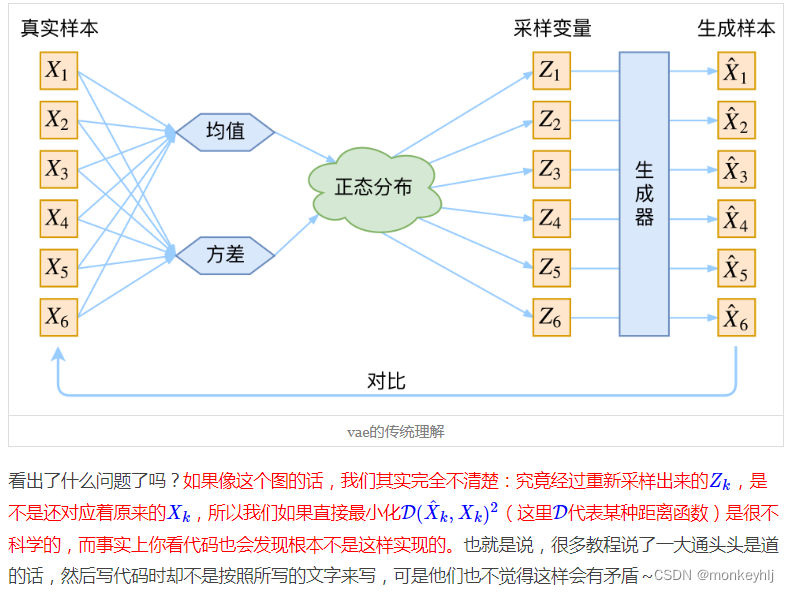
VAE初现
其实,在整个VAE模型中,我们并没有去使用 p ( Z ) p(Z) p(Z)(隐变量空间的分布)是正态分布的假设,我们用的是假设 p ( Z ∣ X ) p(Z|X) p(Z∣X)(后验分布)是正态分布!!
回到本文,这时候每一个
X
k
X_k
Xk都配上了一个专属的正态分布,才方便后面的生成器做还原。但这样有多少个
X
X
X就有多少个正态分布了。我们知道正态分布有两组参数:均值
μ
μ
μ和方差
σ
2
σ^2
σ2(多元的话,它们都是向量),那怎么找出专属于
X
k
X_k
Xk的正态分布
p
(
Z
∣
X
k
)
p(Z|X_k)
p(Z∣Xk)的均值和方差呢?好像并没有什么直接的思路。那好吧,那我就用神经网络来拟合出来吧!这就是神经网络时代的哲学:难算的我们都用神经网络来拟合。

于是我们构建两个神经网络
μ
k
=
f
1
(
X
k
)
,
l
o
g
σ
k
2
=
f
2
(
X
k
)
μ_k=f_1(X_k),logσ_k^2=f_2(X_k)
μk=f1(Xk),logσk2=f2(Xk)来算它们了。我们选择拟合
l
o
g
σ
k
2
logσ_k^2
logσk2而不是直接拟合
σ
k
2
σ_k^2
σk2,是因为
σ
k
2
σ_k^2
σk2总是非负的,需要加激活函数处理,而拟合
l
o
g
σ
k
2
logσ_k^2
logσk2不需要加激活函数,因为它可正可负。到这里,我能知道专属于
X
k
X_k
Xk的均值和方差了,也就知道它的正态分布长什么样了,然后从这个专属分布中采样一个
Z
k
Z_k
Zk出来,然后经过一个生成器得到
X
k
宝盖
=
g
(
Z
k
)
X_k宝盖=g(Z_k)
Xk宝盖=g(Zk),现在我们可以放心地最小化
D
(
X
k
宝盖
,
X
k
)
2
D(X_k宝盖,X_k)^2
D(Xk宝盖,Xk)2,因为
Z
k
Z_k
Zk是从专属
X
k
X_k
Xk的分布中采样出来的,这个生成器应该要把开始的
X
k
X_k
Xk还原回来。于是可以画出VAE的示意图:
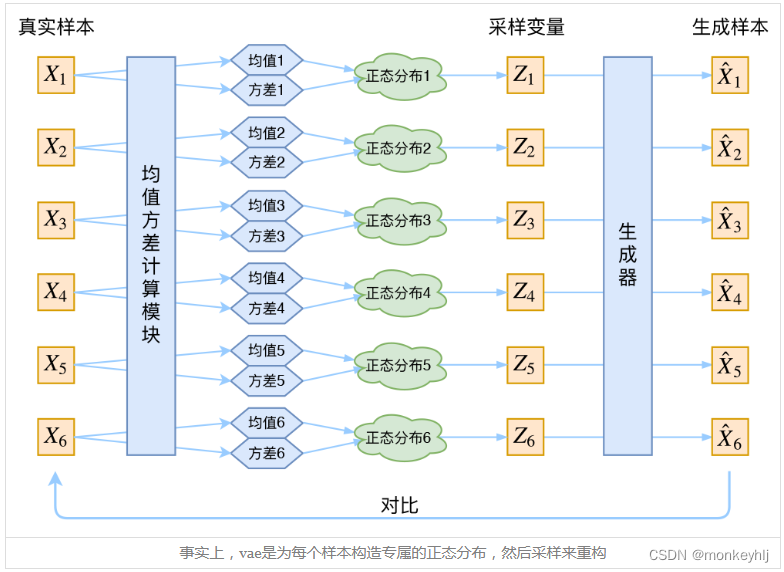
分布标准化
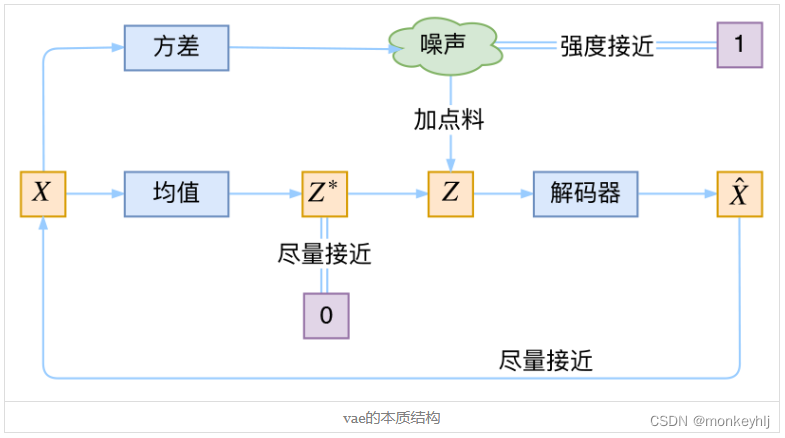
让我们来思考一下,根据上图的训练过程,最终会得到什么结果。
首先,我们希望重构 X X X,也就是最小化 D ( X k 宝盖 , X k ) 2 D(X_k宝盖,X_k)^2 D(Xk宝盖,Xk)2,但是这个重构过程受到噪声的影响,因为 Z k Z_k Zk是通过重新采样过的,不是直接由encoder算出来的。显然噪声会增加重构的难度,不过好在这个噪声强度(也就是方差)通过一个神经网络算出来的,所以最终模型为了重构得更好,肯定会想尽办法让方差为0。而方差为0的话,也就没有随机性了,所以不管怎么采样其实都只是得到确定的结果(也就是均值),只拟合一个当然比拟合多个要容易,而均值是通过另外一个神经网络算出来的。
说白了,模型会慢慢退化成普通的AutoEncoder,噪声不再起作用。
这样不就白费力气了吗?说好的生成模型呢?
别急别急,其实VAE还让所有的
p
(
Z
∣
X
)
p(Z|X)
p(Z∣X)都向标准正态分布看齐,这样就防止了噪声为零,同时保证了模型具有生成能力。怎么理解“保证了生成能力”呢?如果所有的
p
(
Z
∣
X
)
p(Z|X)
p(Z∣X)都很接近标准正态分布
N
(
0
,
I
)
N(0,I)
N(0,I),那么根据定义
这样我们就能达到我们的先验假设:
p
(
Z
)
p(Z)
p(Z)是标准正态分布。然后我们就可以放心地从
N
(
0
,
I
)
N(0,I)
N(0,I)中采样来生成图像了。
那怎么让所有的
p
(
Z
∣
X
)
p(Z|X)
p(Z∣X)都向
N
(
0
,
I
)
N(0,I)
N(0,I)看齐呢?如果没有外部知识的话,其实最直接的方法应该是在重构误差的基础上中加入额外的loss:
因为它们分别代表了均值
μ
k
μ_k
μk和方差的对数
l
o
g
σ
k
2
logσ_k^2
logσk2,达到
N
(
0
,
I
)
N(0,I)
N(0,I)就是希望二者尽量接近于0了。不过,这又会面临着这两个损失的比例要怎么选取的问题,选取得不好,生成的图像会比较模糊。所以,原论文直接算了一般(各分量独立的)正态分布与标准正态分布的KL散度
K
L
(
N
(
μ
,
σ
2
)
∥
N
(
0
,
I
)
)
KL(N(μ,σ2)∥N(0,I))
KL(N(μ,σ2)∥N(0,I))作为这个额外的loss,计算结果为
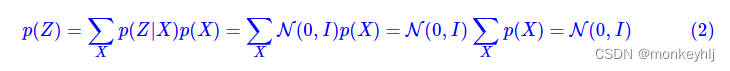
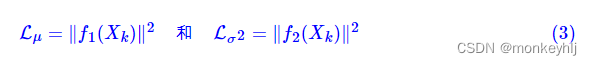
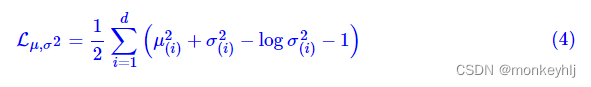


重参数技巧

本质是什么 ?
VAE的本质是什么?VAE虽然也称是AE(AutoEncoder)的一种,但它的做法(或者说它对网络的诠释)是别具一格的。在VAE中,它的Encoder有两个,一个用来计算均值,一个用来计算方差,这已经让人意外了:Encoder不是用来Encode的,是用来算均值和方差的,这真是大新闻了,还有均值和方差不都是统计量吗,怎么是用神经网络来算的?
事实上,我觉得VAE从让普通人望而生畏的变分和贝叶斯理论出发,最后落地到一个具体的模型中,虽然走了比较长的一段路,但最终的模型其实是很接地气的:它本质上就是在我们常规的自编码器的基础上,对encoder的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”,使得结果decoder能够对噪声有鲁棒性;而那个额外的KL loss(目的是让均值为0,方差为1),事实上就是相当于对encoder的一个正则项,希望encoder出来的东西均有零均值。
那另外一个encoder(对应着计算方差的网络)的作用呢?它是用来动态调节噪声的强度的。直觉上来想,当decoder还没有训练好时(重构误差远大于KL loss),就会适当降低噪声(KL loss增加),使得拟合起来容易一些(重构误差开始下降);反之,如果decoder训练得还不错时(重构误差小于KL loss),这时候噪声就会增加(KL loss减少),使得拟合更加困难了(重构误差又开始增加),这时候decoder就要想办法提高它的生成能力了。
说白了,重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的。所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。从这个角度看,VAE的思想似乎还高明一些,因为在GAN中,造假者在进化时,鉴别者是安然不动的,反之亦然。当然,这只是一个侧面,不能说明VAE就比GAN好。GAN真正高明的地方是:它连度量都直接训练出来了,而且这个度量往往比我们人工想的要好(然而GAN本身也有各种问题,这就不展开了)。
从这个讨论中,我们也可以看出,当然,每个 p ( Z ∣ X ) p(Z|X) p(Z∣X)是不可能完全精确等于标准正态分布,否则 p ( Z ∣ X ) p(Z|X) p(Z∣X)就相当于跟 X X X无关了,重构效果将会极差。最终的结果就会是, p ( Z ∣ X ) p(Z|X) p(Z∣X)保留了一定的 X X X信息,重构效果也还可以,并且 ( 2 ) (2) (2)近似成立,所以同时保留着生成能力。
为什么选择正态分布?

变分在哪里?

补充学习:条件VAE
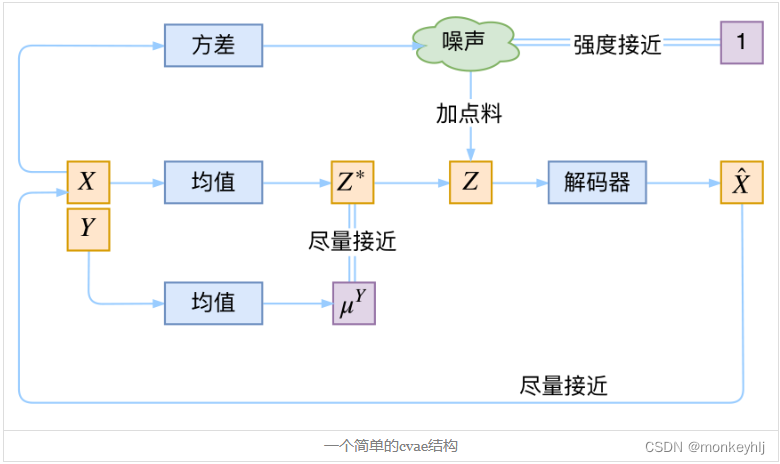
最后,因为目前的VAE是无监督训练的,因此很自然想到:如果有标签数据,那么能不能把标签信息加进去辅助生成样本呢?这个问题的意图,往往是希望能够实现控制某个变量来实现生成某一类图像。当然,这是肯定可以的,我们把这种情况叫做Conditional VAE,或者叫CVAE。(相应地,在GAN中我们也有个CGAN。)
但是,CVAE不是一个特定的模型,而是一类模型,总之就是把标签信息融入到VAE中的方式有很多,目的也不一样。这里基于前面的讨论,给出一种非常简单的VAE。
在前面的讨论中,我们希望
X
X
X经过编码后,
Z
Z
Z的分布都具有零均值和单位方差,这个“希望”是通过加入了KL loss来实现的。如果现在多了类别信息
Y
Y
Y,我们可以希望同一个类的样本都有一个专属的均值
μ
Y
μ^Y
μY(方差不变,还是单位方差),这个
μ
Y
μ^Y
μY让模型自己训练出来。这样的话,有多少个类就有多少个正态分布,而在生成的时候,我们就可以通过控制均值来控制生成图像的类别。事实上,这样可能也是在VAE的基础上加入最少的代码来实现CVAE的方案了,因为这个“新希望”也只需通过修改KL loss实现:
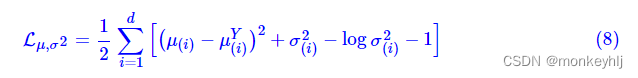
==========================
从贝叶斯观点出发
数值计算vs采样计算
已知概率密度函数
p
(
x
)
p(x)
p(x),那么
x
x
x的期望也就定义为:
如果要对它进行数值计算,也就是数值积分,那么可以选若干个有代表性的点
x
0
<
x
1
<
x
2
<
⋯
<
x
n
x_0<x_1<x_2<⋯<x_n
x0<x1<x2<⋯<xn,然后得到:
这里不讨论“有代表性”是什么意思,也不讨论提高数值计算精度的方法。这样写出来,是为了跟采样计算对比。如果从
p
(
x
)
p(x)
p(x)中采样若干个点
x
1
,
x
2
,
…
,
x
n
x_1,x_2,…,x_n
x1,x2,…,xn,那么我们有:
我们可以比较
(
2
)
(2)
(2)跟
(
3
)
(3)
(3),它们的主要区别是
(
2
)
(2)
(2)中包含了概率的计算而
(
3
)
(3)
(3)中仅有
x
x
x的计算,这是因为在
(
3
)
(3)
(3)中
x
i
x_i
xi是从
p
(
x
)
p(x)
p(x)中依概率采样出来的,概率大的
x
i
x_i
xi出现的次数也多,所以可以说采样的结果已经包含了
p
(
x
)
p(x)
p(x)在里边,就不用再乘以
p
(
x
i
)
p(x_i)
p(xi)了。

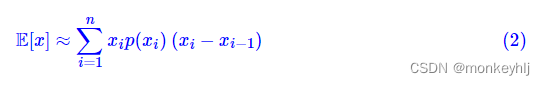
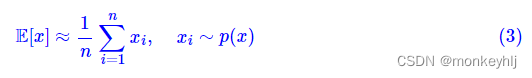
更一般地,我们可以写出:
这就是蒙特卡洛模拟的基础。
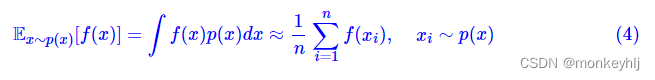
这里通过直接对联合分布进行近似的方式,简明快捷地给出了VAE的理论框架。
直面联合分布
出发点依然没变,这里再重述一下。首先我们有一批数据样本
x
1
,
…
,
x
n
{x1,…,xn}
x1,…,xn,其整体用
x
x
x来描述,我们希望借助隐变量
z
z
z描述
x
x
x的分布
p
(
x
)
波浪线
p(x)波浪线
p(x)波浪线:
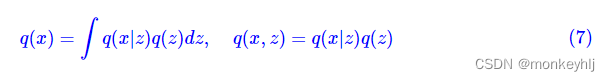




采样计算技巧

==========================
前文之要
回顾一下前面关于VAE的一些原理。
VAE希望通过隐变量分解来描述数据
X
X
X的分布:

采样之惑
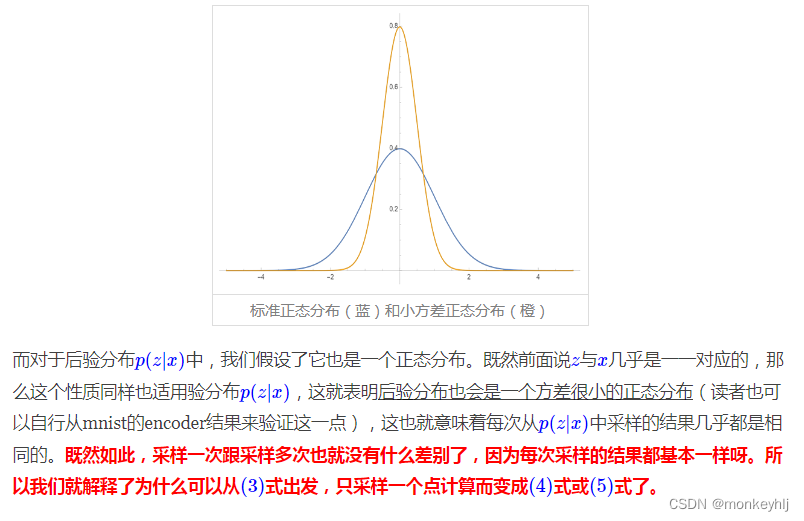
在这部分内容中,我们试图对VAE的原理做细致的追问,以求能回答VAE为什么这样做,最关键的问题是,为什么这样做就可行。
采样一个点就够

为什么一个点就够了?

一个点确实够了
这就得再分析一下我们对
q
(
x
∣
z
)
q(x|z)
q(x∣z)的想法了,我们称
q
(
x
∣
z
)
q(x|z)
q(x∣z)为生成模型部分,一般情况下我们假设它为伯努利分布或高斯分布,考虑到伯努利分布应用场景有限,这里只假设它是正态分布,那么:
其中
μ
(
z
)
μ(z)
μ(z)是用来计算均值的网络,
σ
2
(
z
)
σ^2(z)
σ2(z)是用来计算方差的网络,很多时候我们会固定方差,那就只剩一个计算均值的网络了。
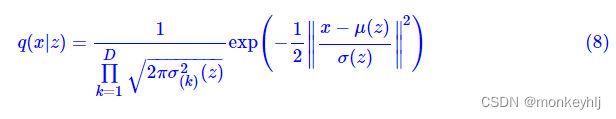
注意,
q
(
x
∣
z
)
q(x|z)
q(x∣z)只是一个概率分布,我们从
q
(
z
)
q(z)
q(z)中采样出
z
z
z后,代入
q
(
x
∣
z
)
q(x|z)
q(x∣z)后得到
q
(
x
∣
z
)
q(x|z)
q(x∣z)的具体形式,理论上我们还要从
q
(
x
∣
z
)
q(x|z)
q(x∣z)中再采样一次才得到
x
x
x。但是,我们并没有这样做,我们直接把均值网络
μ
(
z
)
μ(z)
μ(z)的结果就当成
x
x
x。而能这样做,表明
q
(
x
∣
z
)
q(x|z)
q(x∣z)是一个方差很小的正态分布(如果是固定方差的话,则训练前需要调低方差,如果不是正态分布而是伯努利分布的话,则不需要考虑这个问题,它只有一组参数),每次采样的结果几乎都是相同的(都是均值
μ
(
z
)
μ(z)
μ(z)),此时
x
x
x和
z
z
z之间“几乎”具有一一对应关系,接近确定的函数
x
=
μ
(
z
)
x=μ(z)
x=μ(z)。
感谢大佬们的总结!
【来源】苏剑林. (Mar. 26, 2019). 《科学空间浏览指南(FAQ) 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6508
【参考】https://spaces.ac.cn/archives/5253
【参考】https://spaces.ac.cn/archives/5343
【参考】https://spaces.ac.cn/archives/5383
【参考】https://blog.csdn.net/mch2869253130/article/details/102885243
【参考】https://blog.csdn.net/mch2869253130/article/details/106725342