一、集群搭建
1)安装操作系统以及免密环境
所用工具,如图1所示:
图1 vm虚拟机和镜像文件
[1]新建虚拟机,点击下一步,如图1-1-1所示。
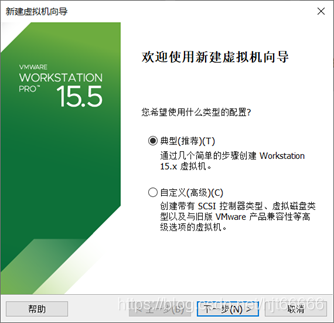
图1-1-1 新建虚拟机
[2]选择“稍后安装操作系统”,点击下一步,如图1-1-2所示。
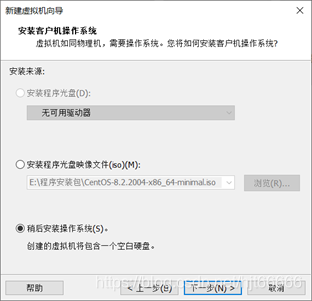
图1-1-2 手动安装Linux
[3]选择“客户机操作系统“为Linux,版本选择CentOS8 64位 如图1-1-3所示。
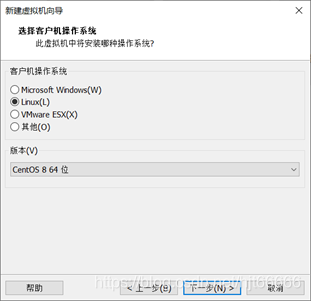
图1-1-3 选择操作系统
[4]命名虚拟机 如图1-1-4所示。
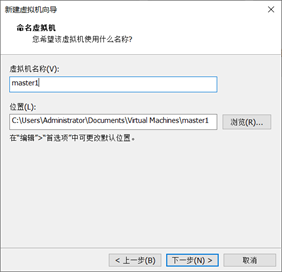
图1-1-4 命名虚拟机
[5]指定磁盘容量,使用默认就行,如图1-1-5所示。
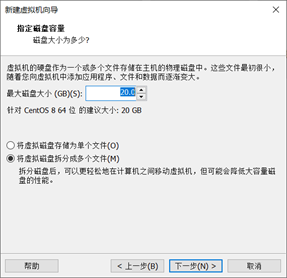
图1-1-5 指定磁盘容量
[6]修改虚拟机配置,如图1-1-6所示。
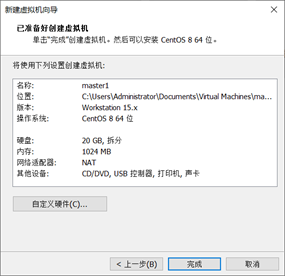
图1-1-6 修改虚拟机配置
[6]使用ISO镜像文件,如图1-1-7所示
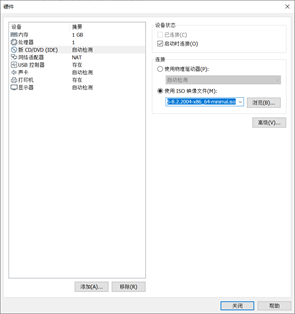
图1-1-7 使用镜像文件
[7]点击完成,到这虚拟机就完成创建了,如图1-1-8所示。
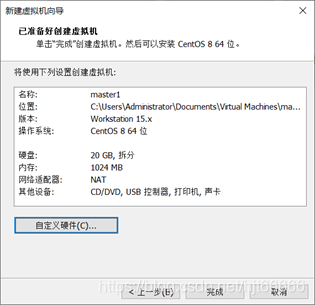
图1-1-8 完成创建
[9]启动虚拟机,选择Install CentOS Linux 8,如图1-1-9所示
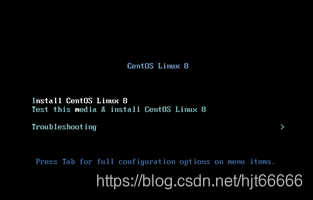
图1-1-9 启动虚拟机
[10]确定虚拟机所使用的语言,点击继续,如图1-1-10所示。
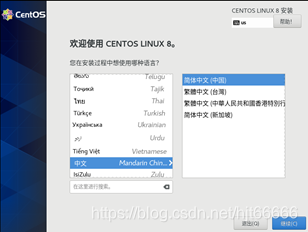
图1-1-10 使用语言
[11]配置安装目标位置,不做任何改动,点击完成,如图1-1-11所示。
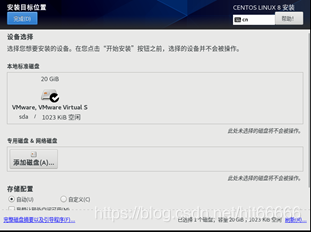
图1-1-11 配置安装目标位置
[12]配置网络和主机名,打开以太网,如图1-1-12所示。
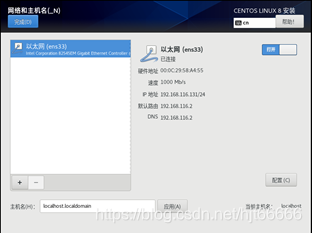
图1-1-12 配置网络和主机名
[13]点击开始安装 如图1-1-13所示。
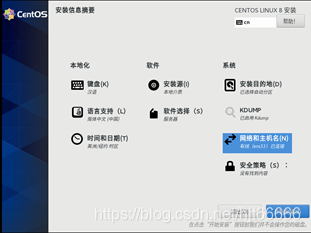
图1-1-13 开始安装
[14]设置登录密码,可以不用设置登录用户,默认用户root,如图1-1-14所示。
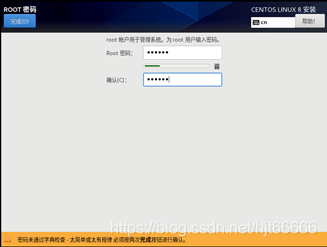
图1-1-14 设置登录密码
[15]点击重启虚拟机,如图1-1-15所示。
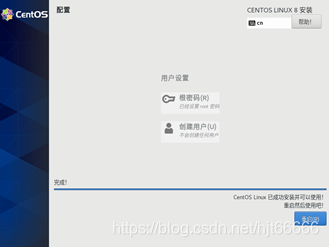
图1-1-15重启虚拟机
slave01和slave02操作步骤和上面一致
[16]安装jdk,如图1-1-16所示
yum install -y java-1.8.0-openjdk.x86_64

图1-1-16 完成jdk下载
根据上述设计构建集群免密环境如下:
—————————————————配置master节点———————————————
1)更改hostname
hostnamectl set-hostname master

2)修改网络地址
先通过ip addr查看系统的ip地址
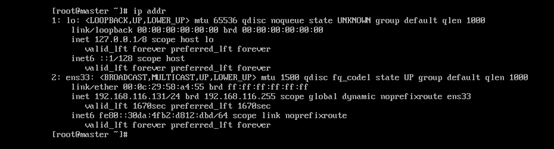
然后通过ip route确定网关
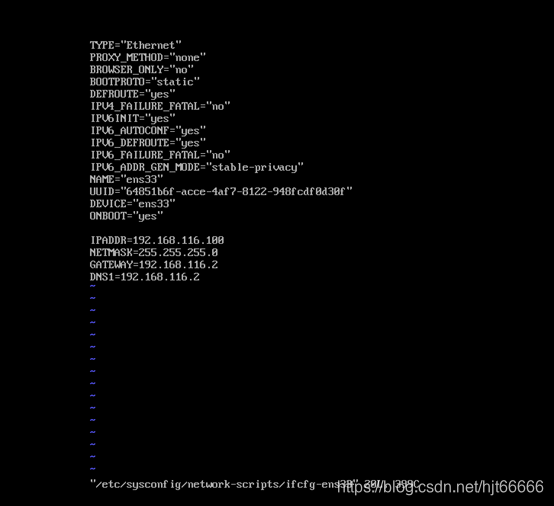
vi /etc/sysconfig/network-scripts/ifcfg-ens??
??是根据系统分配的网络适配器(网卡)而定,可以用tab补全文件名
将文件内容dhcp修改为static
增加如下信息
IPADDR=192.168.???.100
NETMASK=255.255.255.0
GATEWAY=192.168.???.2
DNS1=192.168.???.2
3)配置包含所有节点名称的hosts作为通信依据
vi /etc/hosts
192.168.???.100 master
192.168.???.201 slave01
192.168.???.202 slave02

4)生成免密所需公钥
ssh-keygen -t rsa

—————————————————配置slave01—————————————————
1)更改hostname
hostnamectl set-hostname slave01
2)修改网络地址
vi /etc/sysconfig/network-scripts/ifcfg-ens??
??是根据系统分配的网络适配器(网卡)而定,可以用tab补全文件名
将文件内容dhcp修改为static
增加如下信息
IPADDR=192.168.???.201
NETMASK=255.255.255.0
GATEWAY=192.168.???.2
DNS1=192.168.???.2
3)生成免密所需公钥
ssh-keygen -t rsa
4)将公钥传输给master节点
scp -r /root/.ssh/id_rsa.pub root@master:/root/.ssh/slave01.pub
——————————————————配置slave02————————————————
1)更改hostname
hostnamectl set-hostname slave02
2)修改网络地址
vi /etc/sysconfig/network-scripts/ifcfg-ens??
??是根据系统分配的网络适配器(网卡)而定,可以用tab补全文件名
将文件内容dhcp修改为static
增加如下信息
IPADDR=192.168.???.202
NETMASK=255.255.255.0
GATEWAY=192.168.???.2
DNS1=192.168.???.2
3)生成免密所需公钥
ssh-keygen -t rsa
4)将公钥传输给master节点
scp -r /root/.ssh/id_rsa.pub root@master:/root/.ssh/slave02.pub
————————————————生成公钥链——————————————————
在master节点上创建钥匙链
1)创建钥匙链
cat id_rsa.pub >> authorized_keys
cat slave01.pub >> authorized_keys
cat slave02.pub >> authorized_keys
2)将authorized_keys发送到slave01和slave02
scp -r /root/.ssh/authorized_keys root@slave01:/root/.ssh/authorized_keys
scp -r /root/.ssh/authorized_keys root@slave02:/root/.ssh/authorized_keys
—————————————————¬¬¬¬—测试环境—————————————————
若在master节点,则可通过如下指令测试是否配置成功
ssh slave01
若成功,则无需输入密钥
退出登录执行
exit
2)安装Hadoop以及相应配置
[1] 安装wget,如图1-2-1所示。
图1-2-1 安装wget
[2] 下载hadoop,如图1-2-2所示。
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.5/
图1-2-2 下载Hadoop
[3] 使用 tar -xzvf Hadoop-3.3.0.tar.gz命令解压Hadoop,如图1-2-3所示。
cd /home
tar -xzvf hadoop-3.3.0.tar.gz
图1-2-3 解压Hadoop
[4] 使用yum install -y java-1.8.0-openjdk.x86_64命令安装Hadoop所需的Java环境,如图1-2-4所示。
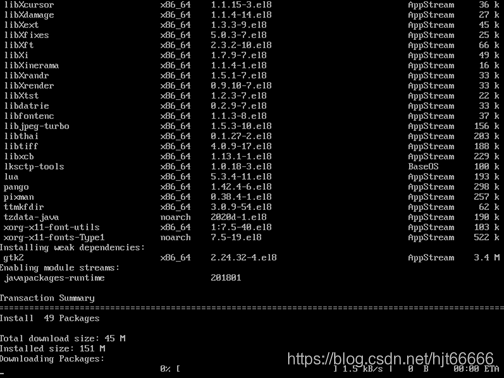
图1-2-4 安装JDK
[5]配置环境变量并激活环境变量,如图1-2-5所示。
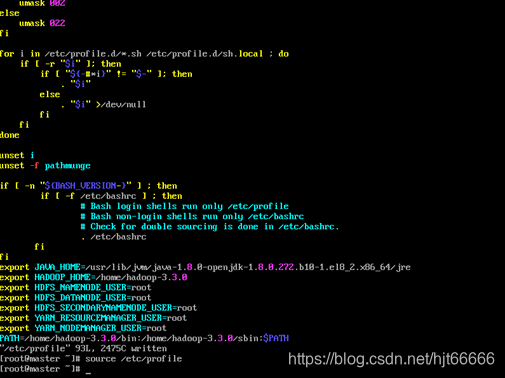
图1-2-5 配置并激活环境
[6]配置hadoop-env.sh,如图1-2-6所示。
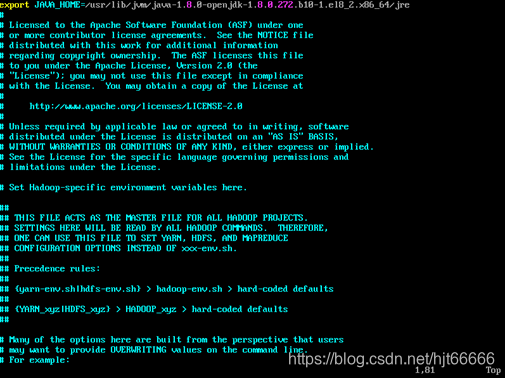
图1-2-6 配置hadoop-env.sh
[7]配置core-site.xml,如图1-2-7所示。
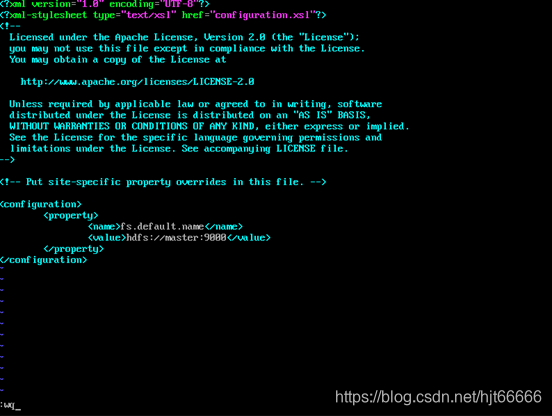
图1-2-7 配置core-site.xml
[8]配置hdfs-site.xml,如图1-2-8所示。
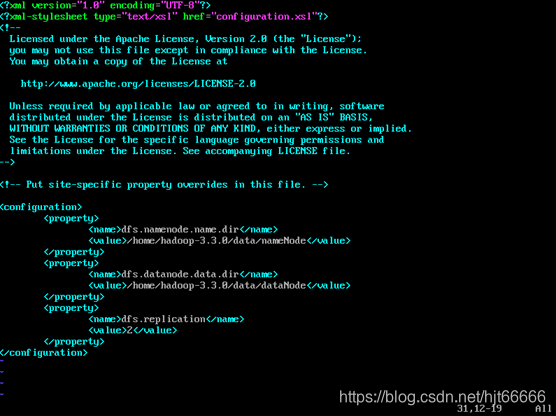
图1-2-8 配置hdfs-site.xml
[9]配置mapped-site.xml,如图1-2-9所示。
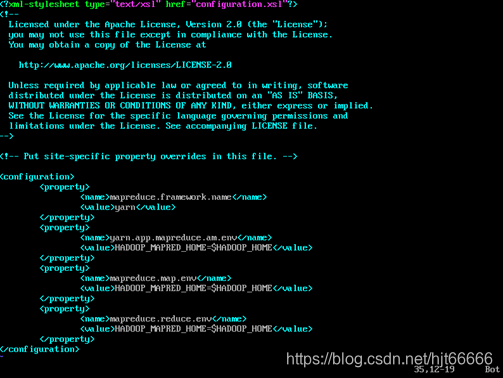
图1-2-9 配置mapped-site.xml
[10]配置yarn-site.xml,如图1-2-10所示。
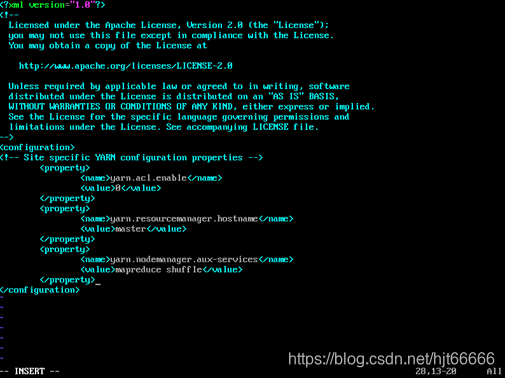
图1-2-10 配置yarn-site.xml
[11]配置workers,如图1-2-11所示。

图1-2-11 配置workers
至此,Hadoop安装配置完成。
3)Hadoop自带wordcount实例测试
[1]创建HDFS空间,如图1-3-1所示。
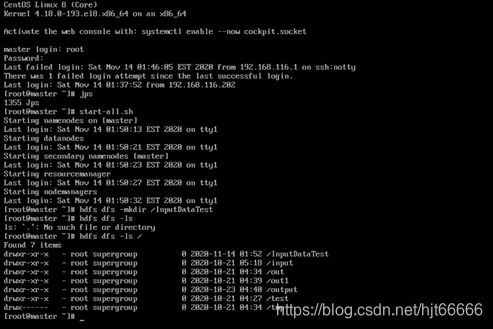
图1-3-1 创建HDFS空间
[2]进行wordcount,如图1-3-2所示。
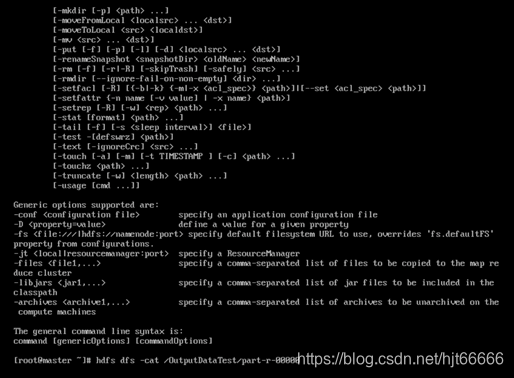
图1-3-2 wordcount
[3]进计算完成,如图1-3-3及图1-3-4所示。
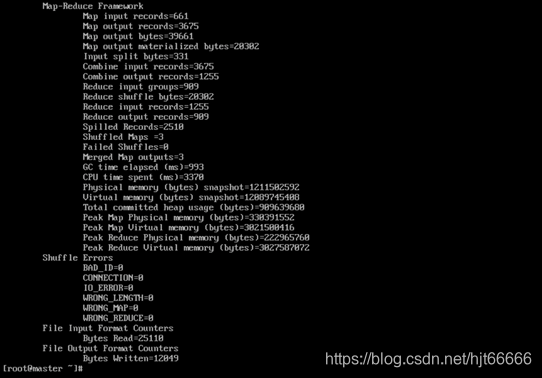
图1-3-3 计算结果

图1-3-4 输出结果
至此,Hadoop自带wordcount实例测试完成。
二、大规模数据分析
1)数据的来源以及意义
该数据集是由 Allen Institute for AI 与Chan Zuckerberg Initiative,乔治敦大学安全与新兴技术中心,微软研究院以及美国国立卫生研究院国家医学图书馆与美国白宫办公室合作创建的科技政策。涵盖目前所有的冠状病毒文献,旨在通过其丰富的元数据和结构化全文本来促进文本发掘和信息检索系统的开发;汇聚计算机界,生物医学界专家和决策者,以寻求有效的COVID-19的治疗和管理政策。
2)数据的详细介绍
CORD-19的资源超过47,000篇学术文章,其中包括36,000篇以上的全文,涉及COVID-19,SARS-CoV-2和相关的冠状病毒。这份数据集包括csv元数据和json文件,可以用于信息检索,信息抽取,知识图谱,问答对,预训练模型,摘要,推荐,蕴含,辅助文献综述,增强阅读等多个方向。
3)数据分析的目标以及思路
数据分析的目标:统计2020年5月1日,12日,19日,26日到2020年5月31日title中出现词频数,分析出五月份热度比较高的几个词。
分析思路,以及分析的方法:需要以title中的单词作为Key,它的个数作为value值,通过MapReduce方法将出现的单词个数做出累计和,统计每个单词出现次数的情况。
4)数据分析结果展示
将处理过后的数据,通过可视化的方式展示出来,并配合文字描述,说明数据表现的原因。
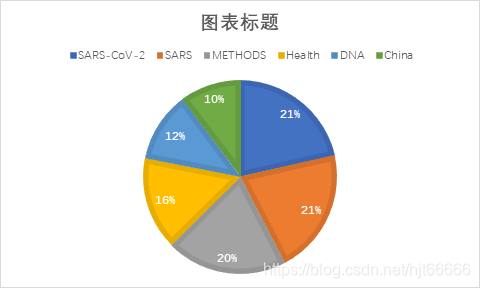
通过分析这几个比较高频的词汇得知SARS病毒是危害健康的,SARS病毒应该是以DNA为遗传物质的,SRAS病毒在中国应该大规模发生过,SARS病毒应该是有着方法可以治愈的。
5)附上Java部分的代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CovAnalysis {
static class TempMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] tmp = line.split(",");
if(tmp.length>3){
String itr_tmp=tmp[3].toString().replaceAll("[^a-zA-Z ]"," ");
StringTokenizer itr = new StringTokenizer(itr_tmp);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
}
static class TempReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
String dst = "hdfs://master:9000/cov";
String dstOut = "hdfs://master:9000/output-cov5";
Configuration hadoopConfig = new Configuration();
Job job = new Job(hadoopConfig);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
System.out.println("Finished");
}
}