coppelia sim[V-REP]仿真实现 机器人于3D相机手眼标定与实时视觉追踪 二
Coppelia Sim (v-REP)仿真 机器人3D相机手眼标定与实时视觉追踪 (一)
zmq API接口python调用
在官方提供的例子里面已经包含了调用的例子程序,把coppeliasim_zmqremoteapi_client 文件夹拷贝过来就直接可以用
import time
# from zmqRemoteApi import RemoteAPIClient
from coppeliasim_zmqremoteapi_client import RemoteAPIClient
def myFunc(input1, input2):
print('Hello', input1, input2)
return 21
print('Program started')
client = RemoteAPIClient()
sim = client.require('sim')
# Create a few dummies and set their positions:
handles = [sim.createDummy(0.01, 12 * [0]) for _ in range(50)]
for i, h in enumerate(handles):
sim.setObjectPosition(h, -1, [0.01 * i, 0.01 * i, 0.01 * i])
# Run a simulation in asynchronous mode:
sim.startSimulation()
while (t := sim.getSimulationTime()) < 3:
s = f'Simulation time: {t:.2f} [s] (simulation running asynchronously '\
'to client, i.e. non-stepping)'
print(s)
sim.addLog(sim.verbosity_scriptinfos, s)
python获取3D相机的数据
获取彩色相机的数据
visionSensorHandle = sim.getObject('/UR5/3D_camera')
img, [resX, resY] = sim.getVisionSensorImg(visionSensorHandle)
img = np.frombuffer(img, dtype=np.uint8).reshape(resY, resX, 3)
# In CoppeliaSim images are left to right (x-axis), and bottom to top (y-axis)
# (consistent with the axes of vision sensors, pointing Z outwards, Y up)
# and color format is RGB triplets, whereas OpenCV uses BGR:
img = cv2.flip(cv2.cvtColor(img, cv2.COLOR_BGR2RGB), 0)
获取深度相机的数据
deepSensorHandle = sim.getObject('/UR5/3D_camera/depth')
# 获取深度图像
Deepdate = sim.getVisionSensorDepth(deepSensorHandle, 1)
# 解包为浮点数数组
num_floats = Deepdate[1][0] * Deepdate[1][1]
depth_data = struct.unpack(f'{num_floats}f', Deepdate[0])
# 将数据转为 numpy 数组
depth_array = np.array(depth_data)
depth_image = depth_array.reshape((Deepdate[1][1], Deepdate[1][0]))
depth_image = np.flipud(depth_image)
deepcolor = encoding.FloatArrayToRgbImage(
depth_image, scale_factor=256*3.5*1000)
用matpolit显示
class ImageStreamDisplay:
def __init__(self, resolution):
# 创建一个包含两个子图的图形
self.fig, (self.ax1, self.ax2) = plt.subplots(
1, 2, figsize=(10, 6)) # 1行2列
# 设置子图的标题
self.ax1.set_title('RGB img')
self.ax2.set_title('Depth img')
# 初始化两个图像显示对象,使用零数组作为占位符,并设置animated=True以启用动画
self.im_display1 = self.ax1.imshow(
np.zeros([resolution[1], resolution[0], 3]), animated=True)
self.im_display2 = self.ax2.imshow(np.zeros(
[resolution[1], resolution[0]]), animated=True, cmap='gray', vmin=0, vmax=3.5)
# 自动调整子图布局以避免重叠
self.fig.tight_layout()
# 开启交互模式
plt.ion()
# 显示图形
plt.show()
def displayUpdated(self, rgbBuffer1, rgbBuffer2):
# 更新两个图像显示对象
# 注意:对于imshow,通常使用set_data而不是set_array
self.im_display1.set_data(rgbBuffer1)
self.im_display2.set_data(rgbBuffer2)
# plt.colorbar()
# 刷新事件并暂停以更新显示
self.fig.canvas.flush_events()
plt.pause(0.01) # 暂停一小段时间以允许GUI更新
display = ImageStreamDisplay([640, 480])
display.displayUpdated(img, depth_image)
显示的效果
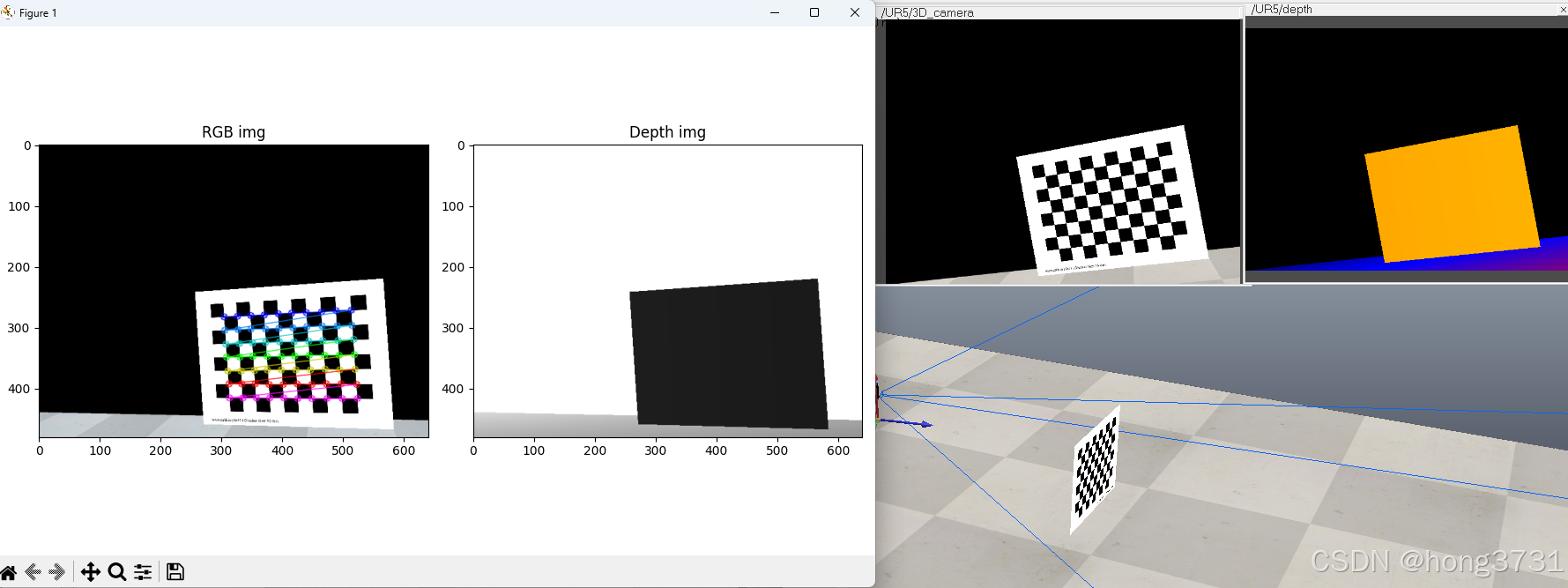
python控制机器人运动
直接控制轴的位置
def moveToConfig(robotColor, handles, maxVel, maxAccel, maxJerk, targetConf):
sim = robotColor
currentConf = []
for i in range(len(handles)):
currentConf.append(sim.getJointPosition(handles[i]))
params = {}
params['joints'] = handles
params['targetPos'] = targetConf
params['maxVel'] = maxVel
params['maxAccel'] = maxAccel
params['maxJerk'] = maxJerk
# one could also use sim.moveToConfig_init, sim.moveToConfig_step and sim.moveToConfig_cleanup
sim.moveToConfig(params)
用IK运动学直接移动到末端姿态
def MovetoPose(robothandle, maxVel, maxAccel, maxJerk, targetpost):
sim = robothandle
params['ik'] = {'tip': tipHandle, 'target': targetHandle}
# params['object'] = targetHandle
params['targetPose'] = targetpost
params['maxVel'] = maxVel
params['maxAccel'] = maxAccel
params['maxJerk'] = maxJerk
sim.moveToPose(params)
相机内参的标定
记录拍照点的位置
targetjoinPos1 = [0 * math.pi / 180, 45 * math.pi / 180, -60 *
math.pi / 180, 0 * math.pi / 180, 90 * math.pi / 180, 0 * math.pi / 180]
targetPos = []
targetPos1 = [-0.1100547923916193, -0.01595811170705489, 0.8466254222789784,
0.560910589456253, -0.5609503047415633, 0.4305463900323013, 0.43051582116844406]
targetPos2 = [-0.16595811170705488, -0.01595811170705487, 0.8216254222789784,
0.5417925804901749, -0.4495188049772251, 0.575726166263469, 0.415852167455231]
targetPos3 = [-0.1100547923916193, -0.01595811170705487, 0.8216254222789784,
3.21292597227468e-05, 0.7932742610364036, -0.6088644721541127, 1.7127530004424877e-05]
targetPos4 = [-0.1100547923916193, -0.01595811170705489, 0.9216254222789784,
1.4077336111962496e-05, 0.7932754374087434, -0.608862940314109, 1.085602215830202e-05]
targetPos5 = [-0.1100547923916193, -0.015958111707054884, 0.8216254222789784,
0.579152193496431, -0.5416388515007398, 0.4546027806731813, 0.40564319680902283]
targetPos6 = [-0.1100547923916193, -0.015958111707054884, 0.8216254222789784,
0.5415953148716405, -0.5791980963813808, 0.4056650408034863, 0.45457667640033966]
targetPos7 = [-0.2100547923916193, -0.015958111707054898, 0.8816254222789784,
0.5212515544329563, -0.5212938037943111, 0.4777945964218841, 0.47776763259657323]
targetPos8 = [-0.15000547923916193, -0.015958111707054898, 0.8016254222789784,
0.5212515544329563, -0.5212938037943111, 0.4777945964218841, 0.47776763259657323]
targetPos9 = [-0.15000547923916193, -0.015958111707054898, 0.8016254222789784,
0.5212515544329563, -0.5212938037943111, 0.4777945964218841, 0.47776763259657323]
targetPos10 = [-0.1010000547923916193, -0.015958111707054898, 0.8016254222789784,
0.5212515544329563, -0.5212938037943111, 0.4777945964218841, 0.47776763259657323]
targetPos11 = []
targetPos12 = []
targetPos.append(targetPos1)
targetPos.append(targetPos2)
targetPos.append(targetPos3)
targetPos.append(targetPos4)
targetPos.append(targetPos5)
targetPos.append(targetPos6)
targetPos.append(targetPos7)
targetPos.append(targetPos8)
targetPos.append(targetPos9)
targetPos.append(targetPos10)
标定板大小的及坐标的设置
# 设置棋盘格规格(内角点的数量)
chessboard_size = (10, 7)
# 3D 世界坐标的点准备(标定板的真实物理尺寸)
square_size = 0.015 # 假设每个格子的边长是15毫米(可以根据实际情况调整)
objp = np.zeros((chessboard_size[0]*chessboard_size[1], 3), np.float32)
objp[:, :2] = np.mgrid[0:chessboard_size[0],
0:chessboard_size[1]].T.reshape(-1, 2) * square_size
# 储存所有图片的3D点和2D点
objpoints = [] # 3D 点 (真实世界空间坐标)
imgpoints = [] # 2D 点 (图像平面中的点)
robot_poses_R = [] # 10 个旋转矩阵
robot_poses_t = [] # 10 个平移向量
camera_poses_R = [] # 10 个相机的旋转矩阵
camera_poses_t = [] # 10 个相机的平移向量
初始化获取相关的资源句柄
targetHandle = sim.getObject('/UR5/Target')
tipHandle = sim.getObject('/UR5/Tip')
robotHandle = sim.getObject('/UR5')
visionSensorHandle = sim.getObject('/UR5/3D_camera')
deepSensorHandle = sim.getObject('/UR5/3D_camera/depth')
chessboardHandle = sim.getObject('/Plane')
jointHandles = []
for i in range(6):
jointHandles.append(sim.getObject('/UR5/joint', {'index': i}))
机器人运动参数设置
jvel = 310 * math.pi / 180
jaccel = 100 * math.pi / 180
jjerk = 80 * math.pi / 180
jmaxVel = [jvel, jvel, jvel, jvel, jvel, jvel]
jmaxAccel = [jaccel, jaccel, jaccel, jaccel, jaccel, jaccel]
jmaxJerk = [jjerk, jjerk, jjerk, jjerk, jjerk, jjerk]
vel = 30
accel = 1.0
jerk = 1
maxVel = [vel, vel, vel, vel]
maxAccel = [accel, accel, accel, accel]
maxJerk = [jerk, jerk, jerk, jerk]
进行拍照和内参标定
print('------Perform camera calibration------')
# 初始拍照位置
moveToConfig(sim, jointHandles, jmaxVel, jmaxAccel, jmaxJerk, targetjoinPos1)
index = 0
for i in range(10):
goalTr = targetPos[i].copy()
params = {}
params['ik'] = {'tip': tipHandle, 'target': targetHandle}
# params['object'] = targetHandle
params['targetPose'] = goalTr
params['maxVel'] = maxVel
params['maxAccel'] = maxAccel
params['maxJerk'] = maxJerk
sim.moveToPose(params)
# 这里是尝试转动角度的
# EulerAngles=sim.getObjectOrientation(targetHandle,tipHandle)
# # EulerAngles[1]+=15* math.pi / 180
# EulerAngles[0]+=25* math.pi / 180
# sim.setObjectOrientation(targetHandle,EulerAngles,tipHandle)
# goalTr=sim.getObjectPose(targetHandle,robotHandle)
# # goalTr[0]=goalTr[1]-0.15
# params = {}
# params['ik'] = {'tip': tipHandle, 'target': targetHandle}
# # params['object'] = targetHandle
# params['targetPose'] = goalTr
# params['maxVel'] = maxVel
# params['maxAccel'] = maxAccel
# params['maxJerk'] = maxJerk
# sim.moveToPose(params)
img, [resX, resY] = sim.getVisionSensorImg(visionSensorHandle)
img = np.frombuffer(img, dtype=np.uint8).reshape(resY, resX, 3)
# In CoppeliaSim images are left to right (x-axis), and bottom to top (y-axis)
# (consistent with the axes of vision sensors, pointing Z outwards, Y up)
# and color format is RGB triplets, whereas OpenCV uses BGR:
img = cv2.flip(cv2.cvtColor(img, cv2.COLOR_BGR2RGB), 0)
# img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 找到棋盘格的角点
ret, corners = cv2.findChessboardCorners(gray, chessboard_size, None)
# 如果找到角点,添加到点集
if ret == True:
objpoints.append(objp)
imgpoints.append(corners)
# 显示角点
img = cv2.drawChessboardCorners(img, chessboard_size, corners, ret)
# 使用 solvePnP 获取旋转向量和平移向量
# ret, rvec, tvec = cv2.solvePnP(objpoints, imgpoints, camera_matrix, dist_coeffs)
# 获取深度图像
Deepdate = sim.getVisionSensorDepth(deepSensorHandle, 1)
# 解包为浮点数数组
num_floats = Deepdate[1][0] * Deepdate[1][1]
depth_data = struct.unpack(f'{num_floats}f', Deepdate[0])
# 将数据转为 numpy 数组
depth_array = np.array(depth_data)
depth_image = depth_array.reshape((Deepdate[1][1], Deepdate[1][0]))
depth_image = np.flipud(depth_image)
deepcolor = encoding.FloatArrayToRgbImage(
depth_image, scale_factor=256*3.5*1000)
display.displayUpdated(img, depth_image)
# 进行相机标定
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(
objpoints, imgpoints, gray.shape[::-1], None, None)
# 计算标定的误差
total_error = 0
errors = []
# 遍历每张图像
for objp, imgp, rvec, tvec in zip(objpoints, imgpoints, rvecs, tvecs):
# 将三维物体点转换为相机坐标系下的二维图像点
projected_imgpoints, _ = cv2.projectPoints(objp, rvec, tvec, mtx, dist)
# 计算原始 imgpoints 和 projected_imgpoints 之间的误差
error = cv2.norm(imgp, projected_imgpoints, cv2.NORM_L2) / \
len(projected_imgpoints)
errors.append(error)
total_error += error
# 计算所有图像的平均误差
mean_error = total_error / len(objpoints)
# 打印每幅图像的误差
for i, error in enumerate(errors):
print(f"图像 {i+1} 的误差: {error}")
# 打印平均误差
print(f"所有图像的平均误差: {mean_error}")
# 打印相机内参和畸变系数
print("Camera Matrix:\n", mtx)
print("Distortion Coefficients:\n", dist)
print('camera carlibraed Done')
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
内参标定结果及标定板的姿态显示
------Perform camera calibration------
图像 1 的误差: 0.02561960222938916
图像 2 的误差: 0.029812235820557646
图像 3 的误差: 0.025746131185086674
图像 4 的误差: 0.026949289915749124
图像 5 的误差: 0.02779773110640927
图像 6 的误差: 0.02970027985427542
图像 7 的误差: 0.02793374910087122
图像 8 的误差: 0.025625364208011148
图像 9 的误差: 0.02599937961290829
图像 10 的误差: 0.028105922281836906
所有图像的平均误差: 0.027328968531509484
Camera Matrix:
[[581.55412313 0. 317.88732972]
[ 0. 581.24563369 240.0350863 ]
[ 0. 0. 1. ]]
Distortion Coefficients:
[[-0.0309966 0.15304087 0.00125555 -0.00093788 -0.27333318]]
camera carlibraed Done
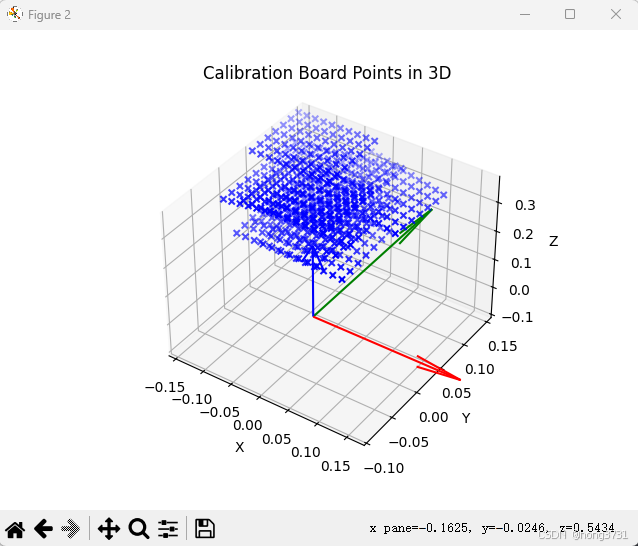
进行手眼标定
参数说明
相机坐标系下的点可以根据内参标定的结果,使用solvePnP,获取棋盘格在相机坐标下的3D点,用sim.getObjectPose获取到机器人的姿态
print('------Perform hand-eye calibration------')
# 初始拍照位置
moveToConfig(sim, jointHandles, jmaxVel, jmaxAccel, jmaxJerk, targetjoinPos1)
for i in range(10):
goalTr = targetPos[i].copy()
# goalTr[2] = goalTr[2] - 0.2
params = {}
params['ik'] = {'tip': tipHandle, 'target': targetHandle}
# params['object'] = targetHandle
params['targetPose'] = goalTr
params['maxVel'] = maxVel
params['maxAccel'] = maxAccel
params['maxJerk'] = maxJerk
sim.moveToPose(params)
img, [resX, resY] = sim.getVisionSensorImg(visionSensorHandle)
img = np.frombuffer(img, dtype=np.uint8).reshape(resY, resX, 3)
# In CoppeliaSim images are left to right (x-axis), and bottom to top (y-axis)
# (consistent with the axes of vision sensors, pointing Z outwards, Y up)
# and color format is RGB triplets, whereas OpenCV uses BGR:
img = cv2.flip(cv2.cvtColor(img, cv2.COLOR_BGR2RGB), 0)
# img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 找到棋盘格的角点
ret, corners = cv2.findChessboardCorners(gray, chessboard_size, None)
# 如果找到角点,添加到点集
if ret == True:
# 使用 solvePnP 获取旋转向量和平移向量
ret, rvec, tvec = cv2.solvePnP(objp, corners, mtx, dist)
# 将 rvec 转换为旋转矩阵
R, _ = cv2.Rodrigues(rvec)
camera_tvec_matrix = tvec.reshape(-1)
# 获取到机器人夹爪的姿态
Targetpost = sim.getObjectPose(tipHandle)
pose_matrix = sim.poseToMatrix(Targetpost)
# 提取旋转矩阵 (3x3)
robot_rotation_matrix = np.array([
[pose_matrix[0], pose_matrix[1], pose_matrix[2]],
[pose_matrix[4], pose_matrix[5], pose_matrix[6]],
[pose_matrix[8], pose_matrix[9], pose_matrix[10]]
])
# 提取平移向量 (P0, P1, P2)
robot_tvec_matrix = np.array(
[pose_matrix[3], pose_matrix[7], pose_matrix[11]])
# 加入到手眼标定数据
robot_poses_R.append(robot_rotation_matrix)
robot_poses_t.append(robot_tvec_matrix)
camera_poses_R.append(R)
camera_poses_t.append(camera_tvec_matrix)
img = draw_axes(img, mtx, dist, rvec, tvec, 0.015*7)
# 获取深度图像
Deepdate = sim.getVisionSensorDepth(deepSensorHandle, 1)
# 解包为浮点数数组
num_floats = Deepdate[1][0] * Deepdate[1][1]
depth_data = struct.unpack(f'{num_floats}f', Deepdate[0])
# 将数据转为 numpy 数组
depth_array = np.array(depth_data)
depth_image = depth_array.reshape((Deepdate[1][1], Deepdate[1][0]))
depth_image = np.flipud(depth_image)
deepcolor = encoding.FloatArrayToRgbImage(
depth_image, scale_factor=256*3.5*1000)
display.displayUpdated(img, depth_image)
print("开始手眼标定...")
R_cam2gripper, t_cam2gripper = cv2.calibrateHandEye(
robot_poses_R, robot_poses_t, camera_poses_R, camera_poses_t, method=cv2.CALIB_HAND_EYE_TSAI
)
camera_pose_intip = sim.getObjectPose(visionSensorHandle, tipHandle)
camera_matrix_intip = sim.poseToMatrix(camera_pose_intip)
eulerAngles = sim.getEulerAnglesFromMatrix(camera_matrix_intip)
print("相机到机器人末端的旋转矩阵:\n", R_cam2gripper)
print("相机到机器人末端的平移向量:\n", t_cam2gripper)
标定结果说明
开始手眼标定...
相机到机器人末端的旋转矩阵:
[[ 0.00437374 -0.99998866 0.00188594]
[ 0.99998691 0.00436871 -0.00266211]
[ 0.00265384 0.00189756 0.99999468]]
相机到机器人末端的平移向量:
[[ 0.04918588]
[-0.00012231]
[ 0.00194761]]
手眼标定完成
在虚拟环境中量出的结果和相机的标定结果,由于图像的坐标系和Sim的坐标系的坐标轴是相差90°,所有顺序不一样
接下来使用标定好的结果进行跟踪标定板的位置