题目
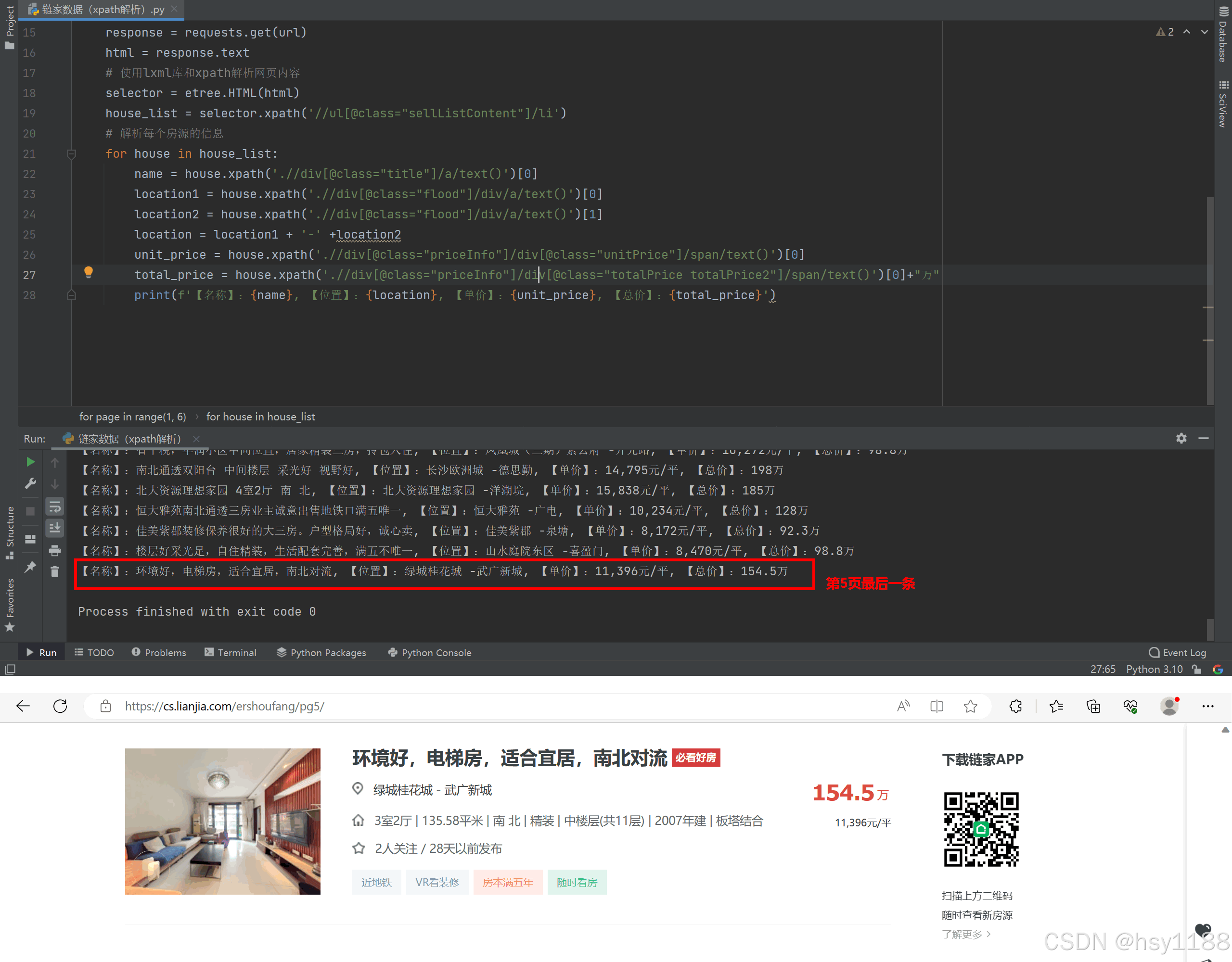
链家网前五页数据
1、名称,2、位置,3、单价,4、总价
https://cs.lianjia.com/ershoufang/
代码
import requests
from lxml import etree
# 爬取前五页的房源信息
for page in range(1, 6):
url = f"https://cs.lianjia.com/ershoufang/pg{page}"
# 发送请求并获取网页内容
response = requests.get(url)
html = response.text
# 使用lxml库和xpath解析网页内容
selector = etree.HTML(html)
house_list = selector.xpath('//ul[@class="sellListContent"]/li')
# print(house_list)
# 解析每个房源的信息
for house in house_list:
name = house.xpath('.//div[@class="title"]/a/text()')[0]
location1 = house.xpath('.//div[@class="flood"]/div/a/text()')[0]
print(location1)
location2 = house.xpath('.//div[@class="flood"]/div/a/text()')[1]
print(location2)
location = location1 + '-' +location2
unit_price = house.xpath('.//div[@class="priceInfo"]/div[@class="unitPrice"]/span/text()')[0]
total_price = house.xpath('.//div[@class="priceInfo"]/div[@class="totalPrice totalPrice2"]/span/text()')[0]+"万"
print(f'【名称】:{name}, 【位置】:{location}, 【单价】:{unit_price}, 【总价】:{total_price}')