目录
ShardingSphere主键生成策略就是使用雪花算法和UUID两种方式。这两种主要就是通过SPI的方式实现,其主要目的也是为了好扩展,也可以自行实现接口,自定义主键生成策略。
一、何为SPI?
二、源码解析主键生成策略
1)源码查找路径图
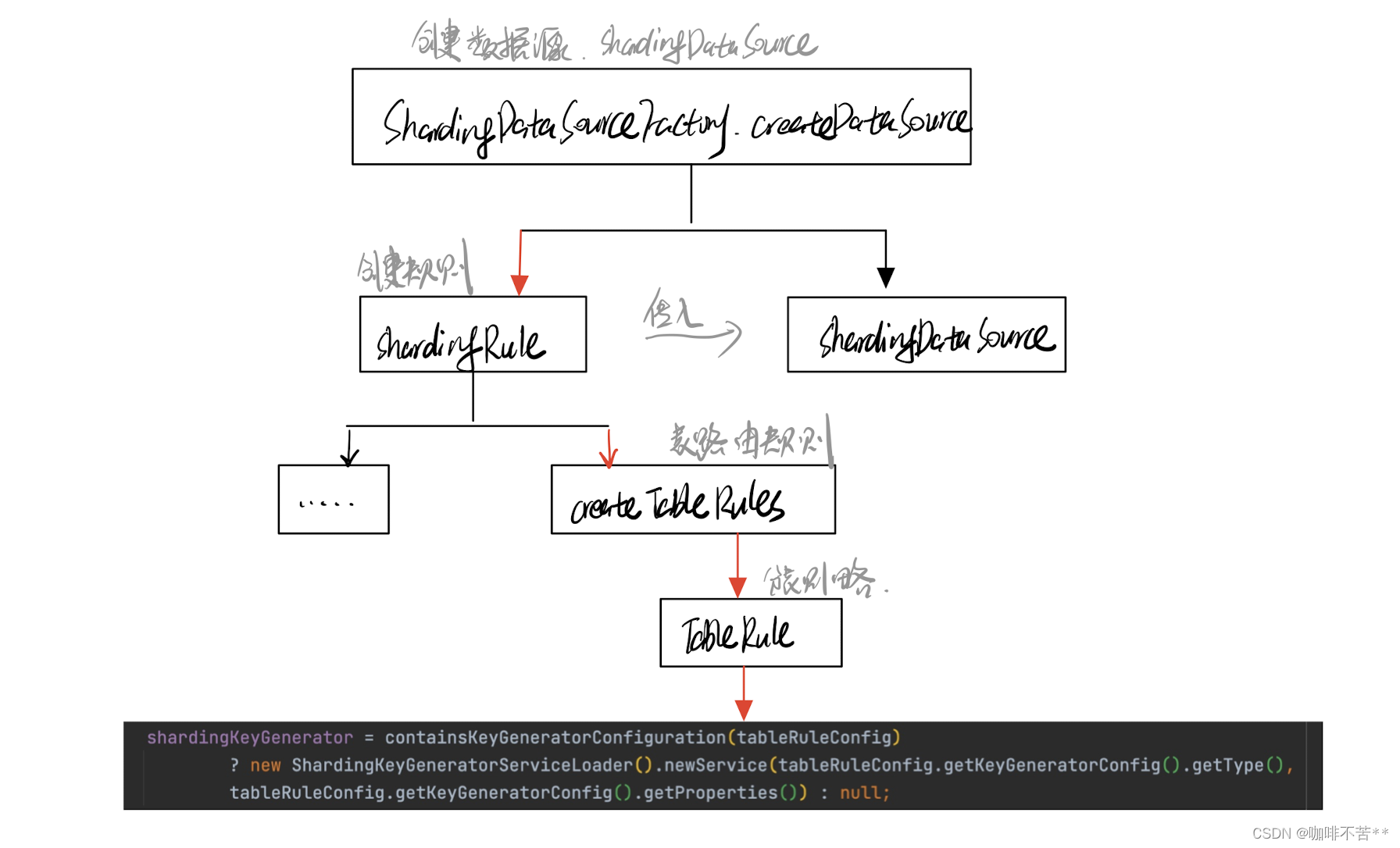
2)源码解析
shardingKeyGenerator = containsKeyGeneratorConfiguration(tableRuleConfig)
? new ShardingKeyGeneratorServiceLoader().newService(tableRuleConfig.getKeyGeneratorConfig().getType(), tableRuleConfig.getKeyGeneratorConfig().getProperties()) : null;
如上逻辑代码,分析,若从配置文件能获取到分片算法值,则通过ShardingKeyGeneratorServiceLoader来解析生成策略,否则就是返回null.
public final class ShardingKeyGeneratorServiceLoader extends TypeBasedSPIServiceLoader<ShardingKeyGenerator> {
static {
//SPI: 加载主键生成策略
NewInstanceServiceLoader.register(ShardingKeyGenerator.class);
}
public ShardingKeyGeneratorServiceLoader() {
super(ShardingKeyGenerator.class);
}
}
我们点开ShardingKeyGeneratorServiceLoader看,他是注册了ShardingKeyGenerator类,其实就是把所有的子类注册一下,也就是把实现类加载到内存中保存一下。注册的过程也就是SPI体现的地方。
通过SPI加载了哪些类呢?我们来看看ShardingKeyGenerator,根据ShardingKeyGenerator的包路径去查找配置文件:
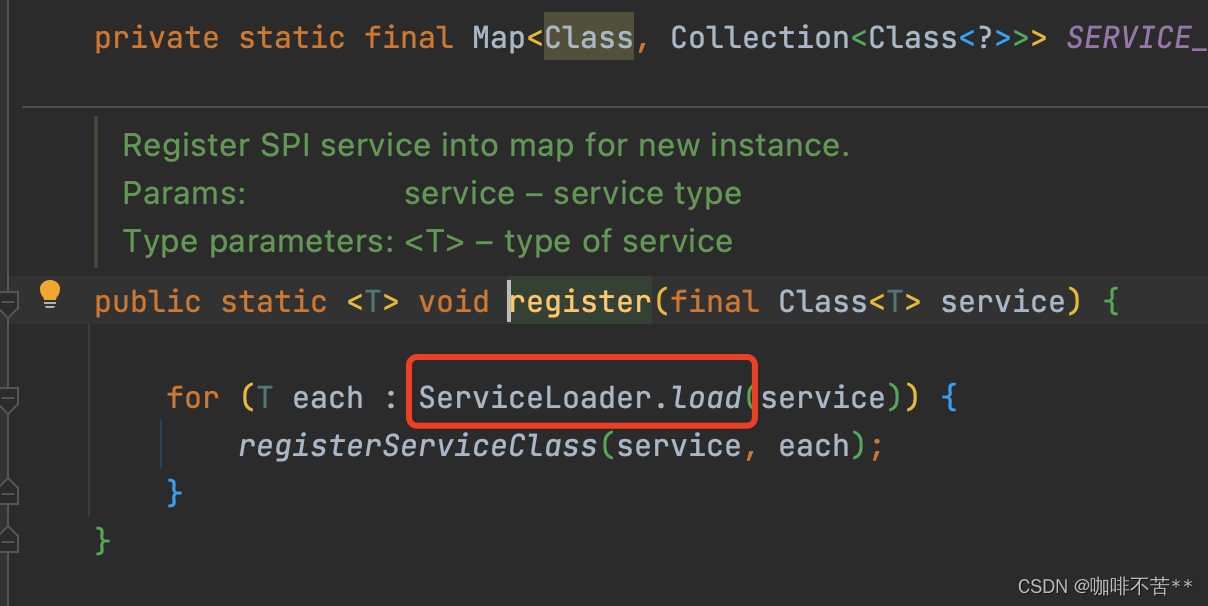

我们发现在文件中加载了两个实现类,一个是SNOWFLAKE,一个是UUID。
把其中一个SnowflakeShardingKeyGenerator点击进去看,发现父类有两个方法:
- getType()
- generateKey()
getType返回的字符串就是我们在配置文件中配置的主键生成策略。
3)UUID
打开UUID的主键生成实现类UUIDShardingKeyGenerator,我们发现它的生成规则只有 UUID.randomUUID() 这么一行代码,额~ 心中默默的感觉有点太简单了吧!
UUID 虽然可以做到全局唯一性,但还是不推荐使用它作为主键,因为我们的实际业务中不管是 user_id 还是 order_id 主键多为整型,而 UUID 生成的是个 32 位的字符串。
它的存储以及查询对 MySQL 的性能消耗较大,而且 MySQL 官方也明确建议,主键要尽量越短越好,作为数据库主键 UUID 的无序性还会导致数据位置频繁变动,严重影响性能。一句话其实就是:为了在节约资源的前提下还能保证性能,尽量不要采取UUID。
/**
* UUID key generator.
*/
@Getter
@Setter
public final class UUIDShardingKeyGenerator implements ShardingKeyGenerator {
private Properties properties = new Properties();
@Override
public String getType() {
return "UUID";
}
@Override
public synchronized Comparable<?> generateKey() {
return UUID.randomUUID().toString().replaceAll("-", "");
}
}
4)SNOWFLAKE
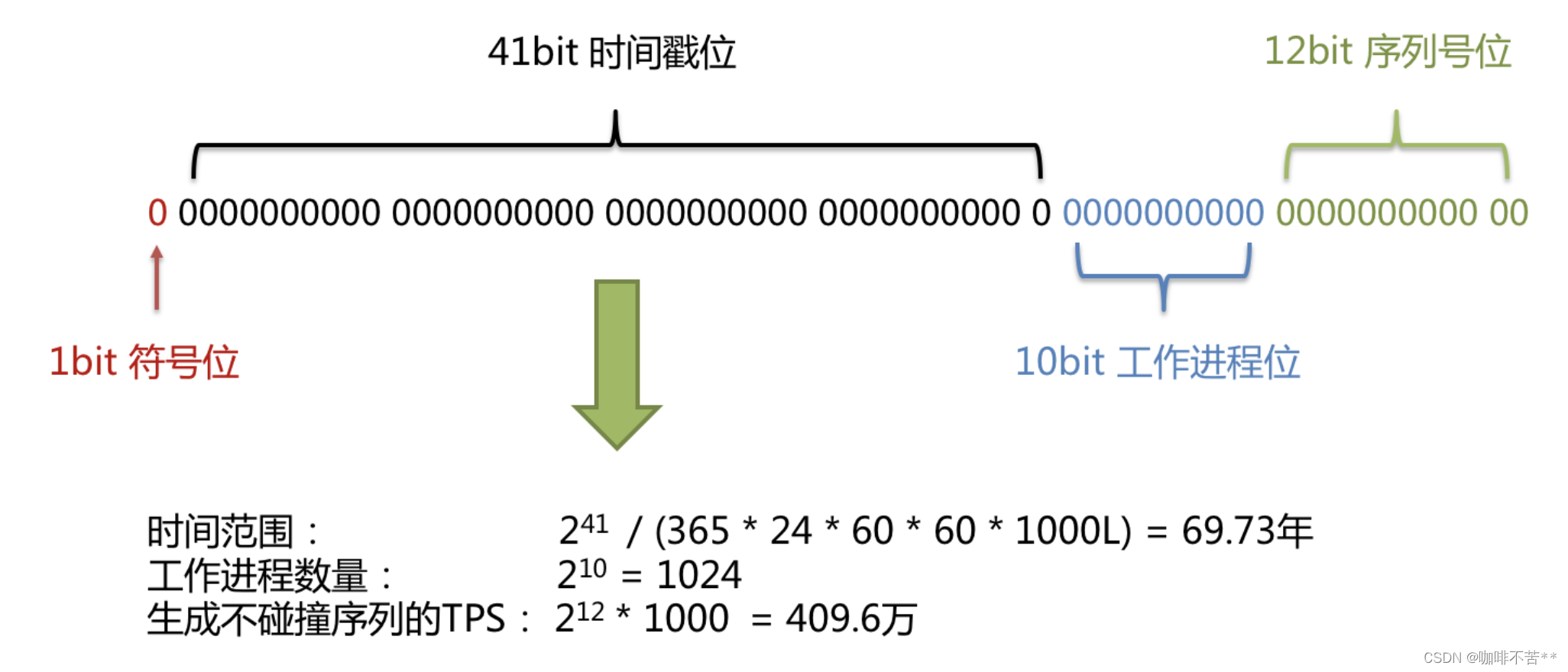
SNOWFLAKE是默认使用的主键生成方案,生成一个 64bit的长整型(Long)数据。
它能够保证不同进程主键的不重复性,相同进程主键的有序性。二进制形式包含4部分,从高位到低位分表为:1bit符号位、41bit时间戳位、10bit工作进程位以及12bit序列号位。
我们看generateKey方法,一眼望去都是时间相关的逻辑,这是一种严重依赖于服务器时间的算法,而依赖服务器时间的就会遇到一个棘手的问题:时钟回拨。
互联网中有一种网络时间协议 ntp 全称 (Network Time Protocol) ,专门用来同步、校准网络中各个计算机的时间。这也是现在我们的智能手机不用对表,但是时间都一样的原因。
服务器时钟回拨会导致产生重复的 ID,SNOWFLAKE 方案中对原有雪花算法做了改进,增加了一个最大容忍的时钟回拨毫秒数。
如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序直接报错;如果在可容忍的范围内,默认分布式主键生成器,会等待时钟同步到最后一次主键生成的时间后再继续工作。
最大容忍的时钟回拨毫秒数,默认值为 0,可通过属性 max.tolerate.time.difference.milliseconds 设置。
# 最大容忍的时钟回拨毫秒数
spring.shardingsphere.sharding.tables.course.key-generator.max.tolerate.time.difference.milliseconds=5
@Override
public synchronized Comparable<?> generateKey() {
//当前系统时间毫秒数
long currentMilliseconds = timeService.getCurrentMillis();
//判断是否需要等待容忍时间差,如果需要,则等待时间差过去,然后再获取当前系统时间
if (waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) {
currentMilliseconds = timeService.getCurrentMillis();
}
//如果最后一次毫秒与 当前系统时间毫秒相同,即还在同一毫秒内
if (lastMilliseconds == currentMilliseconds) {
/**
* &位与运算符:两个数都转为二进制,如果相对应位都是1,则结果为1,否则为0
* 当序列为4095时,4095+1后的新序列与掩码进行位与运算结果是0
* 当序列为其他值时,位与运算结果都不会是0
* 即本毫秒的序列已经用到最大值4096,此时要取下一个毫秒时间值
*/
if (0L == (sequence = (sequence + 1) & SEQUENCE_MASK)) {
currentMilliseconds = waitUntilNextTime(currentMilliseconds);
}
} else {
//上一毫秒已经过去,把序列值重置为-1
vibrateSequenceOffset();
sequence = sequenceOffset;
}
lastMilliseconds = currentMilliseconds;
/**
* XX......XX XX000000 00000000 00000000 时间差 XX
* XXXXXX XXXX0000 00000000 机器ID XX
* XXXX XXXXXXXX 序列号 XX
* 三部分进行|位或运算:如果相对应位都是0,则结果为0,否则为1
*/
return ((currentMilliseconds - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (getWorkerId() << WORKER_ID_LEFT_SHIFT_BITS) | sequence;
}
三、自定义主键生成策略
实现自定义主键生成器其实比较简单,只有两步。
1)第一步:实现 ShardingKeyGenerator 接口,并重写其内部方法
采用时间获取主键自增ID,加入了Atomic保证了高并发下的原子性。
/**
* @description:自定义的主键生成策略
* @author: huoyajing
* @time: 2021/12/22 11:44 上午
*/
public class MyKeyGenerator implements ShardingKeyGenerator {
/**
* 增加原子操作,避免高并发下有重复值
*/
private AtomicLong atomicLong=new AtomicLong();
/**
* 核心方法-生成主键ID
* @return
*/
@Override
public Comparable<?> generateKey() {
LocalDateTime localDateTime=LocalDateTime.now();
String valueString = DateTimeFormatter.ofPattern("HHmmssSSS").format(localDateTime);
return Long.parseLong(valueString+atomicLong.incrementAndGet());
}
/**
* 自定义的生成方案类型
* @return
*/
@Override
public String getType() {
return "DATETIMEKEY";
}
@Override
public Properties getProperties() {
return null;
}
@Override
public void setProperties(Properties properties) {
}
}
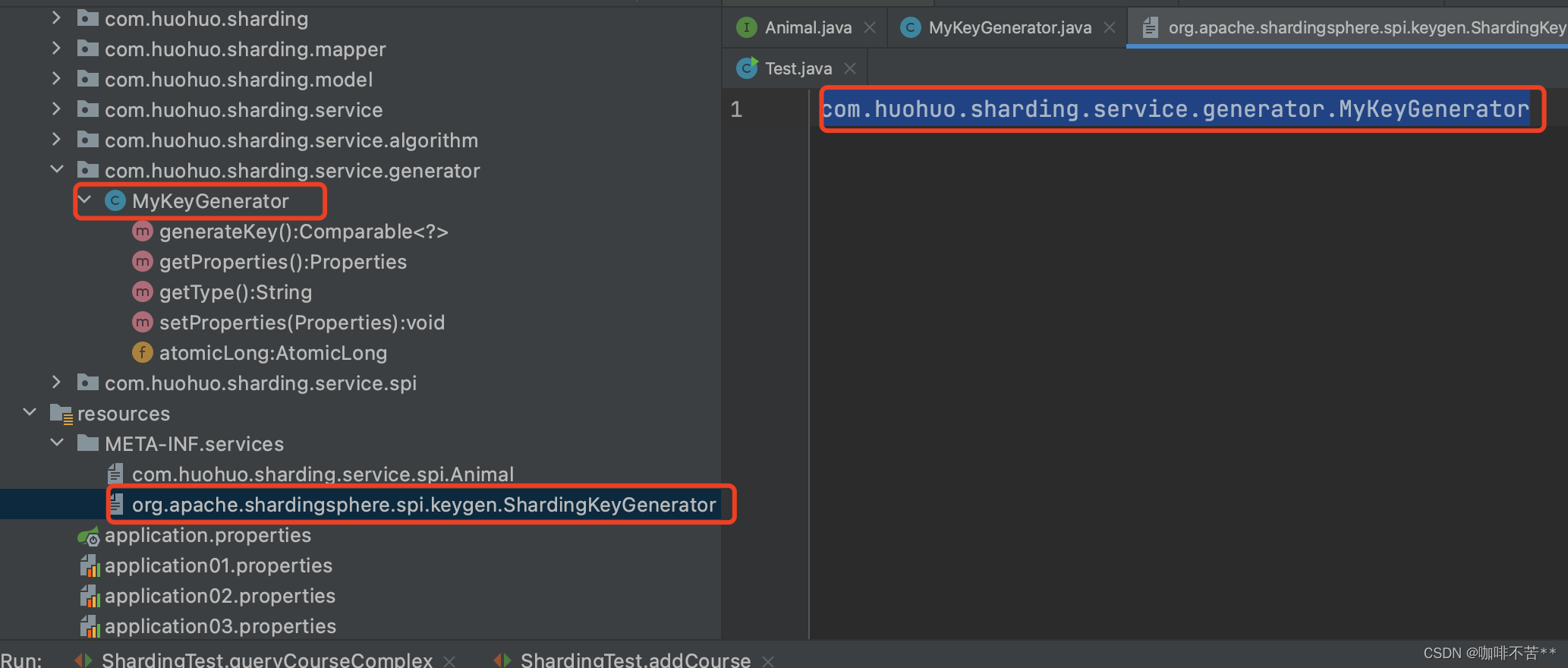
2)META-INF/services 文件中配置自定义的主键生成策略路径
文件路径不要编写错误:
org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator
在里边加入咱们自己自定义的主键生成策略类路径
com.huohuo.sharding.service.generator.MyKeyGenerator
3)测试
修改一下key-generator.type,改为自定义的value
spring.shardingsphere.sharding.tables.course.key-generator.column=id
spring.shardingsphere.sharding.tables.course.key-generator.type=DATETIMEKEY
测试类:
@Test
public void addCourse() {
for (int i = 1; i <= 10; i++) {
Course c = new Course();
c.setName("shardingsphere");
c.setType(Long.valueOf(i));
courseMapper.insert(c);
}
}
四、总结
为何要实现自定义主键生成策略呢,通过分析我们晓得不管是雪花还是UUID,可读性都很差,我们可以自定义实现具有业务属性的策略。