1 数据集加载
import seaborn as sns
sns.set(font_scale=1.5,style="white")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import copy
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torch.utils.data as Data
from torchvision import transforms
## 准备训练数据集Minist
train_data = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
## 定义一个数据加载器
train_loader = Data.DataLoader(
dataset = train_data, ## 使用的数据集
batch_size=64, # 批处理样本大小
shuffle = True, # 每次迭代前打乱数据
num_workers = 2, # 使用两个进程
)
## 可视化训练数据集的一个batch的样本来查看图像内容
for step, (b_x, b_y) in enumerate(train_loader):
if step > 0:
break
## 输出训练图像的尺寸和标签的尺寸,都是torch格式的数据
print(b_x.shape)
print(b_y.shape)
train_data
输出
torch.Size([64, 1, 28, 28])
torch.Size([64])
Dataset MNIST
Number of datapoints: 60000
Root location: ./data
Split: Train
StandardTransform
Transform: ToTensor()
## 准备需要使用的测试数据集
test_data = torchvision.datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
## 定义一个数据加载器
test_loader = Data.DataLoader(
dataset = test_data, ## 使用的数据集
batch_size=64, # 批处理样本大小
shuffle = True, # 每次迭代前打乱数据
num_workers = 2, # 使用两个进程
)
## 可视化训练数据集的一个batch的样本来查看图像内容
for step, (b_x, b_y) in enumerate(train_loader):
if step > 0:
break
## 输出训练图像的尺寸和标签的尺寸,都是torch格式的数据
print(b_x.shape)
print(b_y.shape)
test_data
输出
torch.Size([64, 1, 28, 28])
torch.Size([64])
Dataset MNIST
Number of datapoints: 10000
Root location: ./data
Split: Test
StandardTransform
Transform: ToTensor()
2 搭建RNN模型
class RNNimc(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim):
"""
input_dim:输入数据的维度(图片每行的数据像素点)
hidden_dim: RNN神经元个数
layer_dim: RNN的层数
output_dim:隐藏层输出的维度(分类的数量)
"""
super(RNNimc, self).__init__()
self.hidden_dim = hidden_dim ## RNN神经元个数
self.layer_dim = layer_dim ## RNN的层数
# RNN
self.rnn = nn.RNN(input_dim, hidden_dim, layer_dim,
batch_first=True, nonlinearity='relu')
# 连接全连阶层
self.fc1 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# x:[batch, time_step, input_dim]
# 本例中time_step=图像所有像素数量/input_dim
# out:[batch, time_step, output_size]
# h_n:[layer_dim, batch, hidden_dim]
out, h_n = self.rnn(x, None) # None表示h0会使用全0进行初始化
# 选取最后一个时间点的out输出
out = self.fc1(out[:, -1, :])
return out
## 模型的调用
input_dim=28 # 图片每行的像素数量
hidden_dim=128 # RNN神经元个数
layer_dim = 1 # RNN的层数
output_dim=10 # 隐藏层输出的维度(10类图像)
MyRNNimc = RNNimc(input_dim, hidden_dim, layer_dim, output_dim)
print(MyRNNimc)
输出
RNNimc(
(rnn): RNN(28, 128, batch_first=True)
(fc1): Linear(in_features=128, out_features=10, bias=True)
)
3 训练模型
## 对模型进行训练
optimizer = torch.optim.RMSprop(MyRNNimc.parameters(), lr=0.0003)
criterion = nn.CrossEntropyLoss() # 损失函数
train_loss_all = []
train_acc_all = []
test_loss_all = []
test_acc_all = []
num_epochs = 30
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
MyRNNimc.train() ## 设置模型为训练模式
corrects = 0
train_num = 0
for step,(b_x, b_y) in enumerate(train_loader):
# input :[batch, time_step, input_dim]
xdata = b_x.view(-1, 28, 28)
output = MyRNNimc(xdata)
pre_lab = torch.argmax(output,1)
loss = criterion(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss += loss.item() * b_x.size(0)
corrects += torch.sum(pre_lab == b_y.data)
train_num += b_x.size(0)
## 计算经过一个epoch的训练后在训练集上的损失和精度
train_loss_all.append(loss / train_num)
train_acc_all.append(corrects.double().item()/train_num)
print('{} Train Loss: {:.4f} Train Acc: {:.4f}'.format(
epoch, train_loss_all[-1], train_acc_all[-1]))
## 设置模型为验证模式
MyRNNimc.eval()
corrects = 0
test_num = 0
for step,(b_x, b_y) in enumerate(test_loader):
# input :[batch, time_step, input_dim]
xdata = b_x.view(-1, 28, 28)
output = MyRNNimc(xdata)
pre_lab = torch.argmax(output,1)
loss = criterion(output, b_y)
loss += loss.item() * b_x.size(0)
corrects += torch.sum(pre_lab == b_y.data)
test_num += b_x.size(0)
## 计算经过一个epoch的训练后在测试集上的损失和精度
test_loss_all.append(loss / test_num)
test_acc_all.append(corrects.double().item()/test_num)
print('{} Test Loss: {:.4f} Test Acc: {:.4f}'.format(
epoch, test_loss_all[-1], test_acc_all[-1]))
4 模型保存和加载
# 保存
torch.save(MyRNNimc, 'rnn.pkl')
model = torch.load('rnn.pkl')
print(model)
输出
RNNimc(
(rnn): RNN(28, 128, batch_first=True)
(fc1): Linear(in_features=128, out_features=10, bias=True)
)
模型测试
import cv2
import matplotlib.pyplot as plt
# 第一步:读取图片
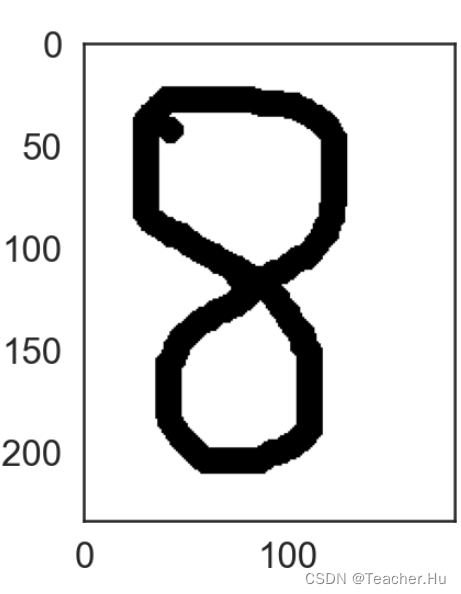
img = cv2.imread('./data/test/8.png')
print(img.shape)
# 第二步:将图片转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
print(img.shape)
plt.imshow(img,cmap='Greys')
# 第三步:将图片的底色和字的颜色取反
img = cv2.bitwise_not(img)
plt.imshow(img,cmap='Greys')
# 第四步:将底变成纯白色,将字变成纯黑色
img[img<=144]=0
img[img>140]=255 # 130
# 显示图片
plt.imshow(img,cmap='Greys')
# 第五步:将图片尺寸缩放为输入规定尺寸
img = cv2.resize(img,(28,28))
# 第六步:将数据类型转为float32
img = img.astype('float32')
# 第七步:数据正则化
img /= 255
img = img.reshape(1,784)
# 第八步:增加维度为输入的规定格式
_img = torch.from_numpy(img).float()
# _img = torch.from_numpy(img).unsqueeze(0)
输出
(234, 182, 3)
(234, 182)
model.eval()
_img = _img.view(-1, 28, 28)
# 第九步:预测
outputs = model(_img)
# 第十步:输出结果
print(outputs.argmax())