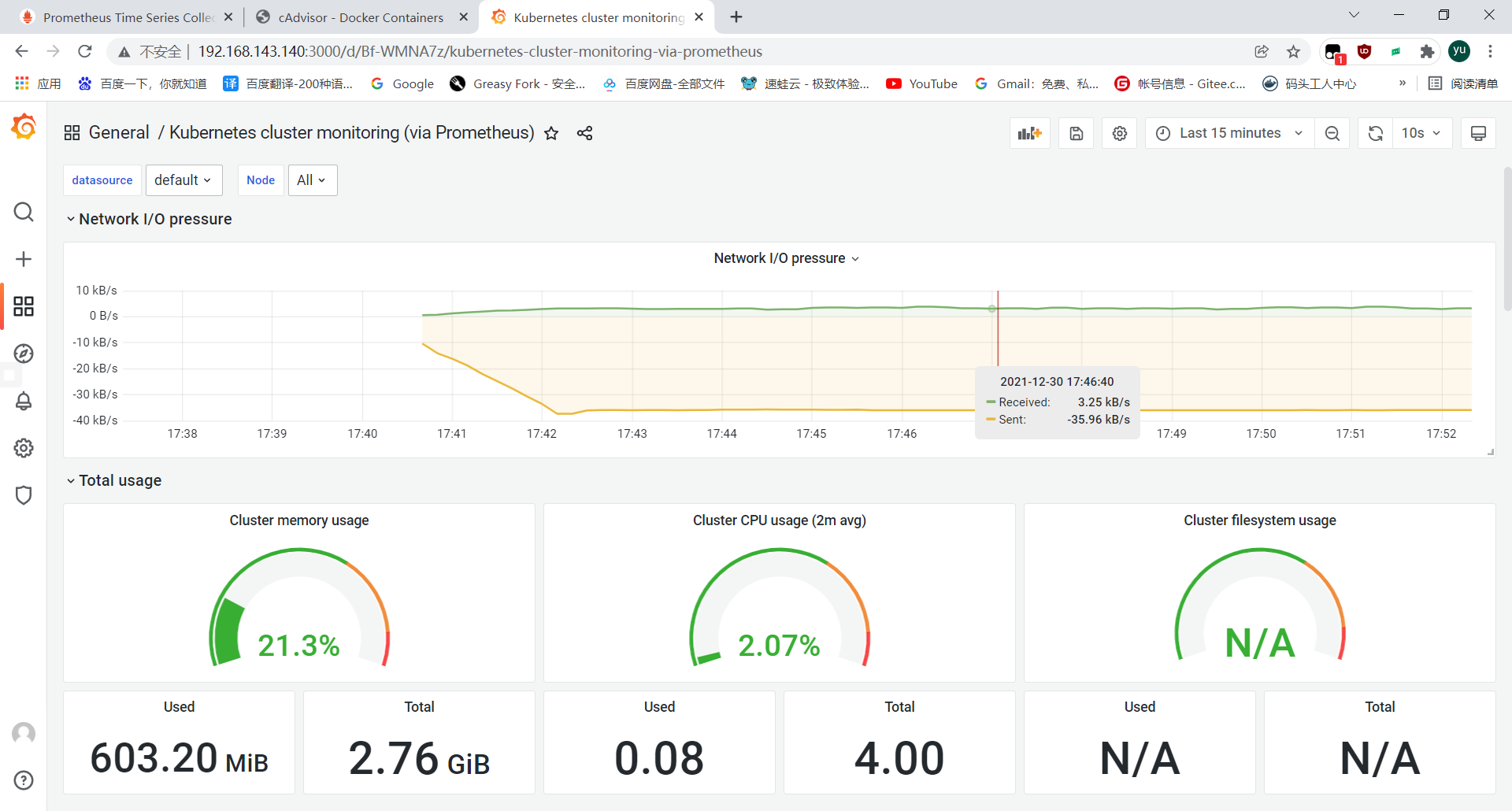
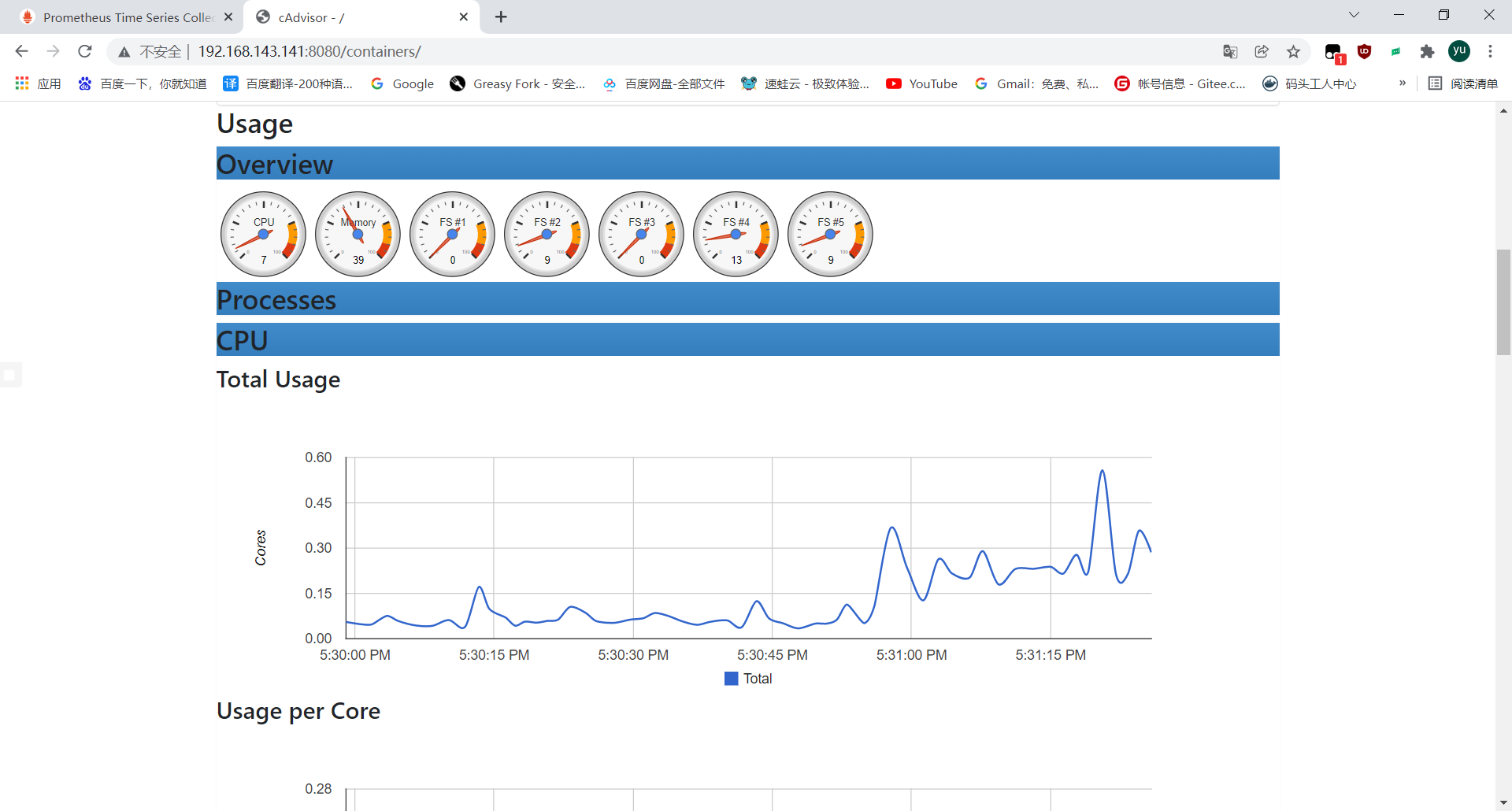
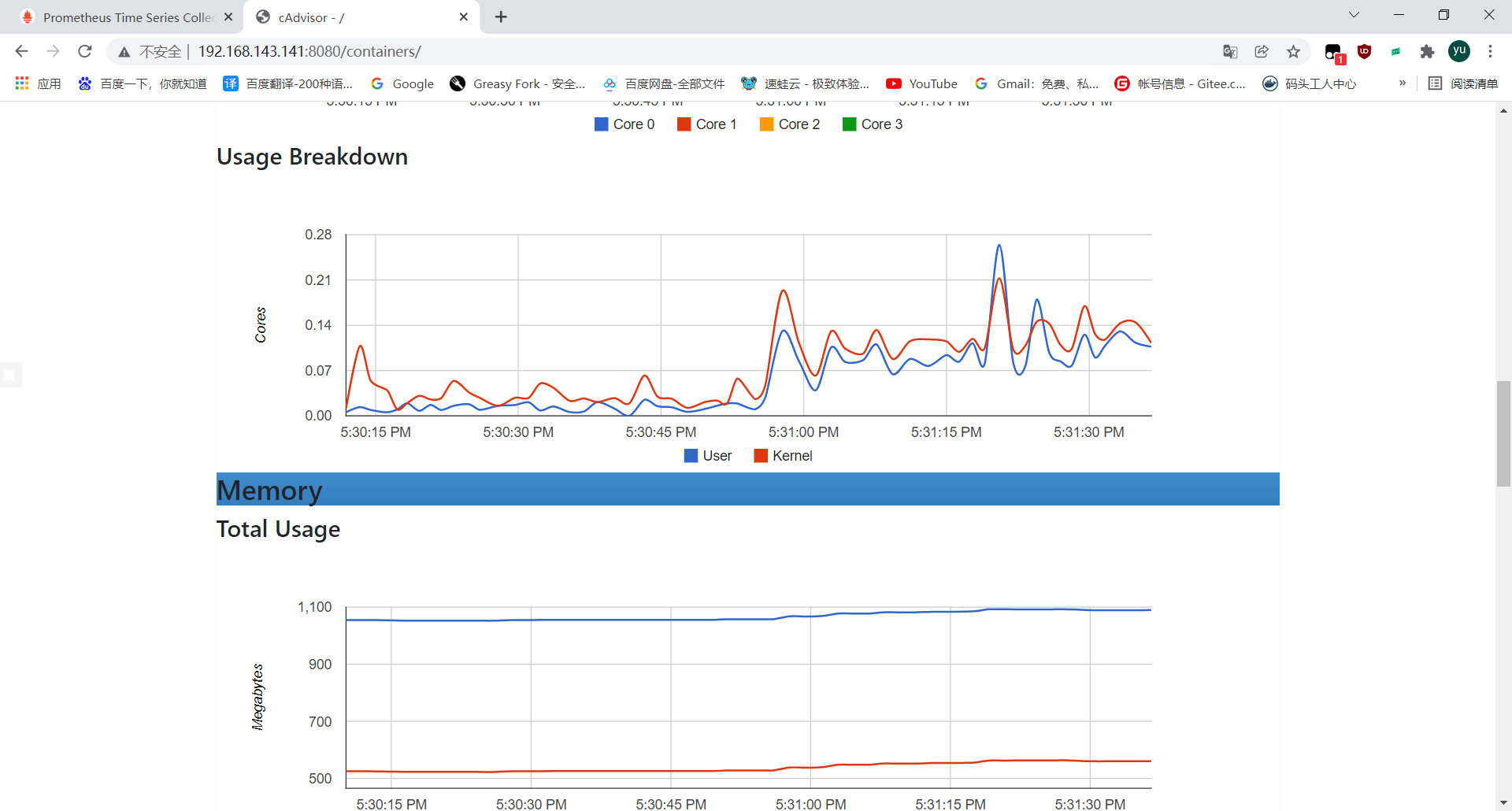
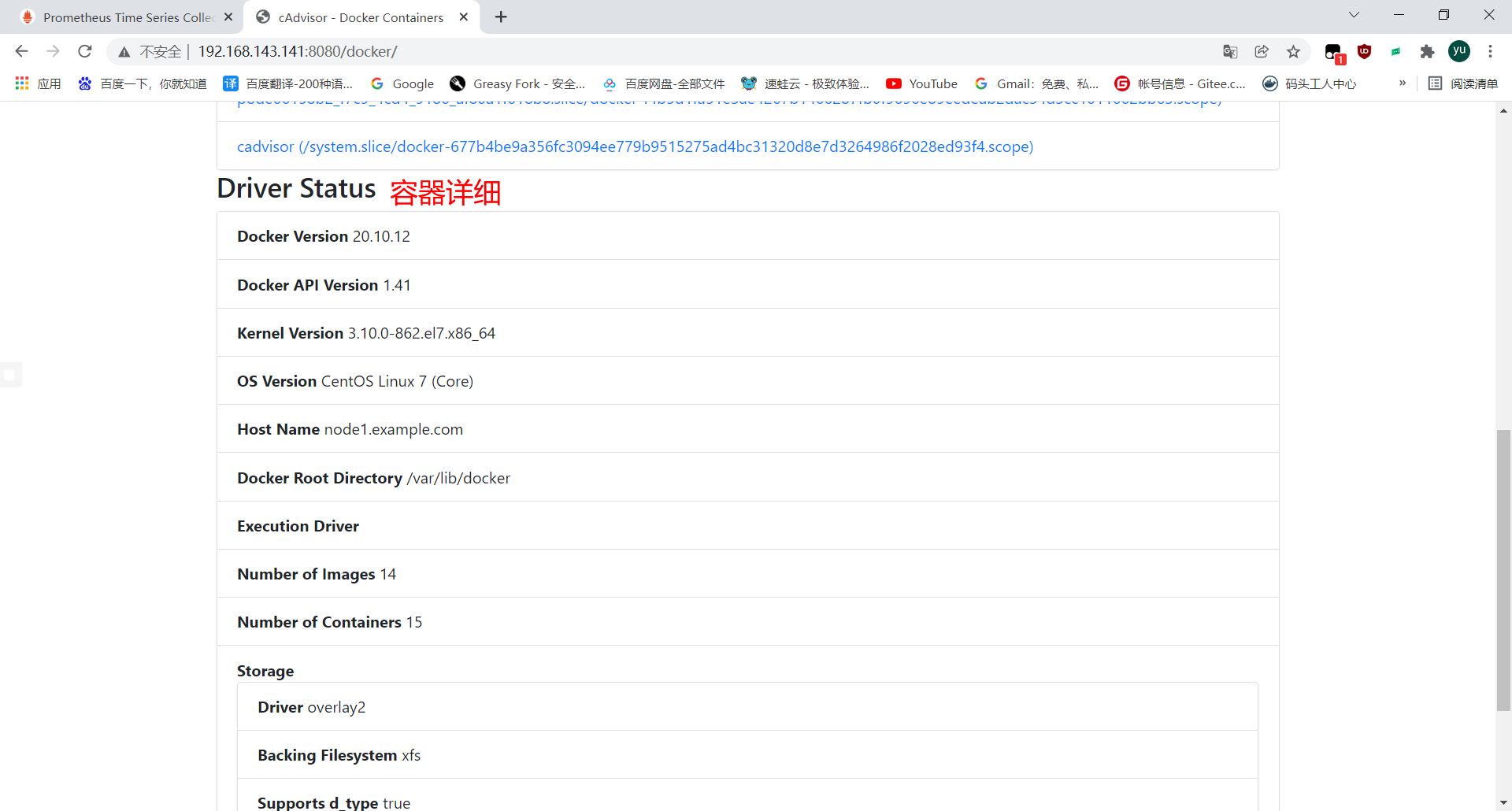
Cadvisor 进行收集,通过 Prometheus 作为数据源,利用 Grafana 进行展示。
环境说明:
已做工作可以参考上一篇文章Prometheus、Grafan基于docker部署
| 主机名 | IP | 部署功能 |
|---|---|---|
| master | 192.168.143.140 | Grafan 容器 Prometheus 容器 node_exporter |
| node1 | 192.168.143.141 | cadvisor容器 node_exporter |
node1主机上 用此命令运行容器google/cadvisor官方镜像
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
google/cadvisor
[root@node1 ~]# docker run \
> --volume=/:/rootfs:ro \
> --volume=/var/run:/var/run:ro \
> --volume=/sys:/sys:ro \
> --volume=/var/lib/docker/:/var/lib/docker:ro \
> --volume=/dev/disk/:/dev/disk:ro \
> --publish=8080:8080 \
> --detach=true \
> --name=cadvisor \
> --privileged \
> --device=/dev/kmsg \
> google/cadvisor

在 master 主机上配置prometheus.yml文件
使prometheus能够接受到node1采集的信息
[root@master ~]# vim /opt/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["192.168.143.140:9100"]
- job_name: "Linux Server"
static_configs:
- targets:
- 192.168.143.141:9100
- 192.168.143.142:9100
//新增配置
- job_name: "cadvisor Service "
static_configs:
- targets: ["192.168.143.141:8080"]
//重启docker,也可以docekr restart prometheus
[root@master ~]# systemctl restart docker
//master上面查看,监控状态发现有新的节点
//发现原来的模板监控不了,此时添加新的模板
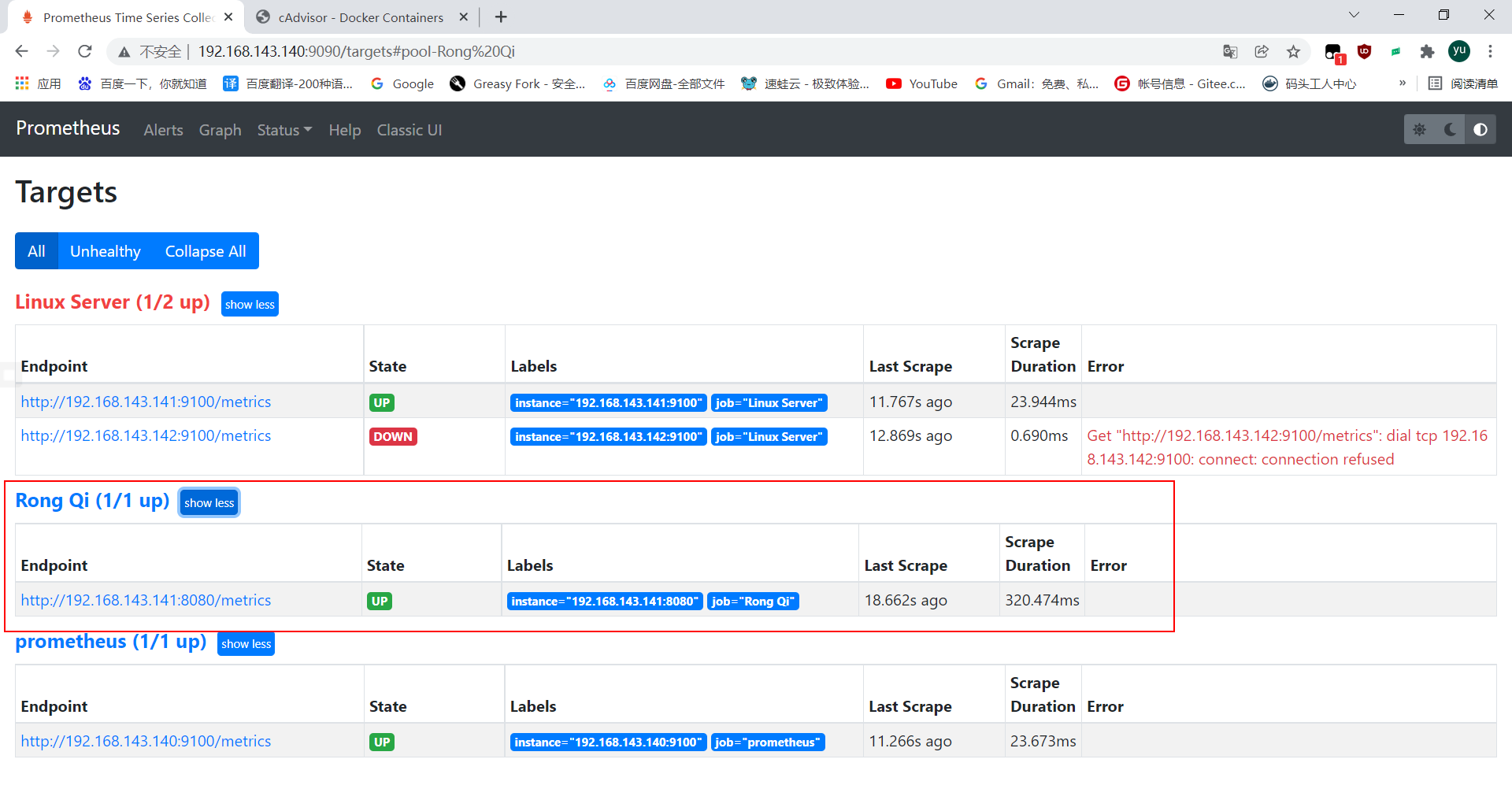
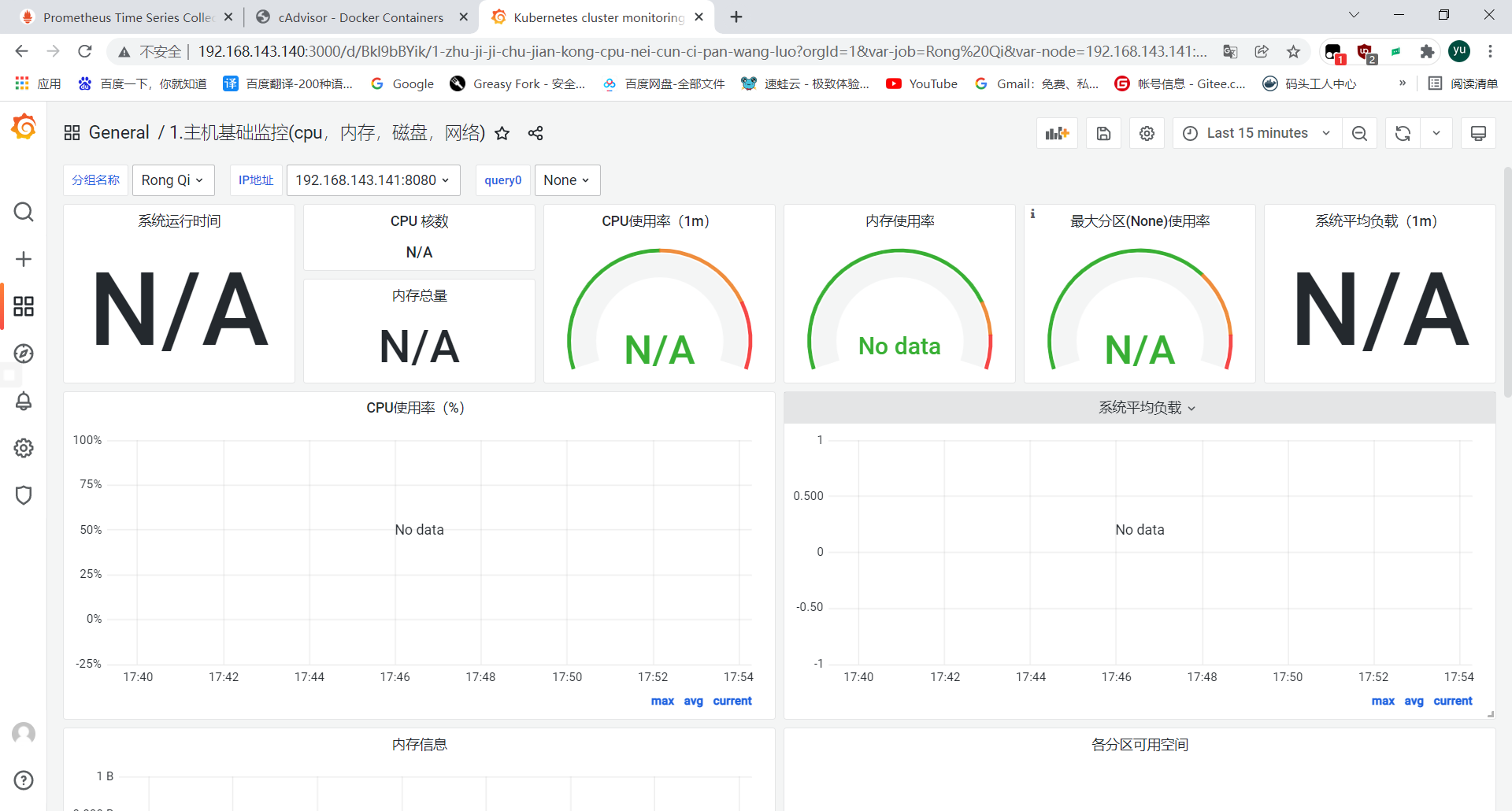
添加新的模板