前言
JavaScript 诞生于 1995 年,最初被设计用于网页内的表单验证。
这些年来 JavaScript 成长飞速,生态圈日益壮大,成为了最受程序员欢迎的开发语言之一。并且现在的 JavaScript 不再局限于网页端,已经扩展到了桌面端、移动端以及服务端。
随着大前端时代的到来,使用 JavaScript 的开发者越来越多,但是许多开发者都只停留在“会用”这个层面,而对于这门语言并没有更多的了解。
如果想要成为一名更好的 JavaScript 开发者,理解内存是一个不可忽略的关键点。
📖 本文主要包含两大部分:
- JavaScript 内存详解
- JavaScript 内存分析指南
看完这篇文章后,相信你会对 JavaScript 的内存有比较全面的了解,并且能够拥有独自进行内存分析的能力。
🧐 话不多说,我们开始吧!
文章篇幅较长,除去代码也有 12000 字左右,需要一定的时间来阅读,但是我保证你所花费的时间都是值得的。
正文
内存(memory)
什么是内存(What is memory)
相信大家都对内存有一定的了解,我就不从盘古开天辟地开始讲了,稍微提一下。
首先,任何应用程序想要运行都离不开内存。
另外,我们提到的内存在不同的层面上有着不同的含义。
💻 硬件层面(Hardware)
在硬件层面上,内存指的是随机存取存储器。
内存是计算机重要组成部分,用来储存应用运行所需要的各种数据,CPU 能够直接与内存交换数据,保证应用能够流畅运行。
一般来说,在计算机的组成中主要有两种随机存取存储器:高速缓存(Cache)和主存储器(Main memory)。
高速缓存通常直接集成在 CPU 内部,离我们比较远,所以更多时候我们提到的(硬件)内存都是主存储器。
💡 随机存取存储器(Random Access Memory,RAM)
随机存取存储器分为静态随机存取存储器(Static Random Access Memory,SRAM)和动态随机存取存储器(Dynamic Random Access Memory,DRAM)两大类。
在速度上 SRAM 要远快于 DRAM,而 SRAM 的速度仅次于 CPU 内部的寄存器。
在现代计算机中,高速缓存使用的是 SRAM,而主存储器使用的是 DRAM。
💡 主存储器(Main memory,主存)
虽然高速缓存的速度很快,但是其存储容量很小,小到几 KB 最大也才几十 MB,根本不足以储存应用运行的数据。
我们需要一种存储容量与速度适中的存储部件,让我们在保证性能的情况下,能够同时运行几十甚至上百个应用,这也就是主存的作用。
计算机中的主存其实就是我们平时说的内存条(硬件)。
硬件内存不是我们今天的主题,所以就说这么多,想要深入了解的话可以根据上面提到关键词进行搜索。
🧩 软件层面(Software)
在软件层面上,内存通常指的是操作系统从主存中划分(抽象)出来的内存空间。
此时内存又可以分为两类:栈内存和堆内存。
接下来我将围绕 JavaScript 这门语言来对内存进行讲解。
在后面的文章中所提到的内存均指软件层面上的内存。
栈与堆(Stack & Heap)
栈内存(Stack memory)
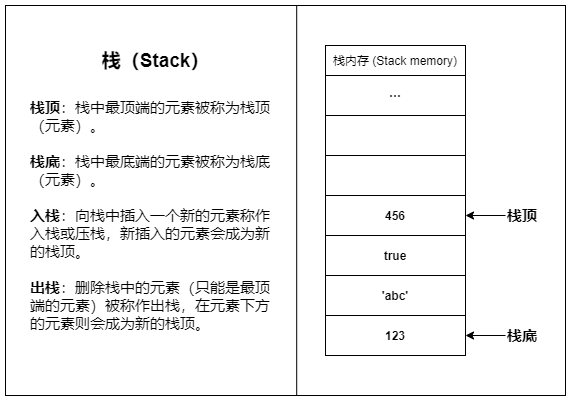
💡 栈(Stack)
栈是一种常见的数据结构,栈只允许在结构的一端操作数据,所有数据都遵循后进先出(Last-In First-Out,LIFO)的原则。
现实生活中最贴切的的例子就是羽毛球桶,通常我们只通过球桶的一侧来进行存取,最先放进去的羽毛球只能最后被取出,而最后放进去的则会最先被取出。
栈内存之所以叫做栈内存,是因为栈内存使用了栈的结构。
栈内存是一段连续的内存空间,得益于栈结构的简单直接,栈内存的访问和操作速度都非常快。
栈内存的容量较小,主要用于存放函数调用信息和变量等数据,大量的内存分配操作会导致栈溢出(Stack overflow)。
栈内存的数据储存基本都是临时性的,数据会在使用完之后立即被回收(如函数内创建的局部变量在函数返回后就会被回收)。
简单来说:栈内存适合存放生命周期短、占用空间小且固定的数据。
💡 栈内存的大小
栈内存由操作系统直接管理,所以栈内存的大小也由操作系统决定。
通常来说,每一条线程(Thread)都会有独立的栈内存空间,Windows 给每条线程分配的栈内存默认大小为 1MB。
堆内存(Heap memory)
💡 堆(Heap)
堆也是一种常见的数据结构,但是不在本文讨论范围内,就不多说了。
堆内存虽然名字里有个“堆”字,但是它和数据结构中的堆没半毛钱关系,就只是撞了名罢了。
堆内存是一大片内存空间,堆内存的分配是动态且不连续的,程序可以按需申请堆内存空间,但是访问速度要比栈内存慢不少。
堆内存里的数据可以长时间存在,无用的数据需要程序主动去回收,如果大量无用数据占用内存就会造成内存泄露(Memory leak)。
简单来说:堆内存适合存放生命周期长,占用空间较大或占用空间不固定的数据。

💡 堆内存的上限
在 Node.js 中,堆内存默认上限在 64 位系统中约为 1.4 GB,在 32 位系统中约为 0.7 GB。
而在 Chrome 浏览器中,每个标签页的内存上限约为 4 GB(64 位系统)和 1 GB(32 位系统)。
💡 进程、线程与堆内存
通常来说,一个进程(Process)只会有一个堆内存,同一进程下的多个线程会共享同一个堆内存。
在 Chrome 浏览器中,一般情况下每个标签页都有单独的进程,不过在某些情况下也会出现多个标签页共享一个进程的情况。
函数调用(Function calling)
明白了栈内存与堆内存是什么后,现在让我们看看当一个函数被调用时,栈内存和堆内存会发生什么变化。
当函数被调用时,会将函数推入栈内存中,生成一个栈帧(Stack frame),栈帧可以理解为由函数的返回地址、参数和局部变量组成的一个块;当函数调用另一个函数时,又会将另一个函数也推入栈内存中,周而复始;直到最后一个函数返回,便从栈顶开始将栈内存中的元素逐个弹出,直到栈内存中不再有元素时则此次调用结束。
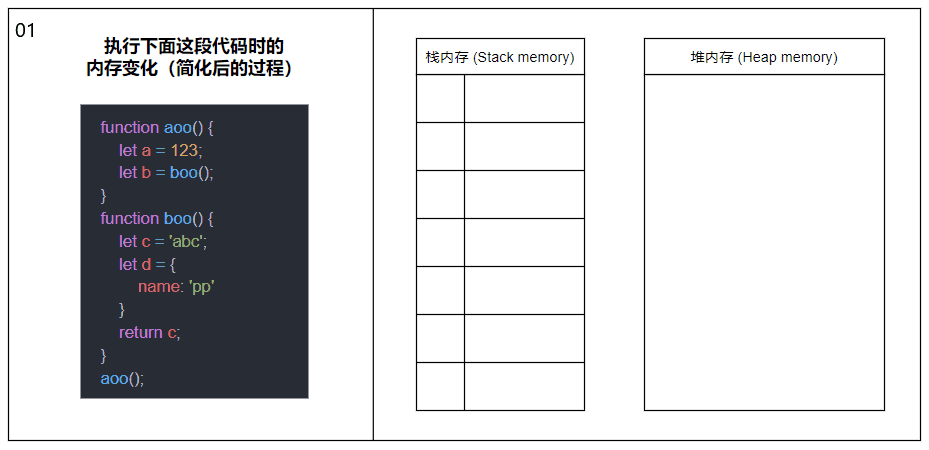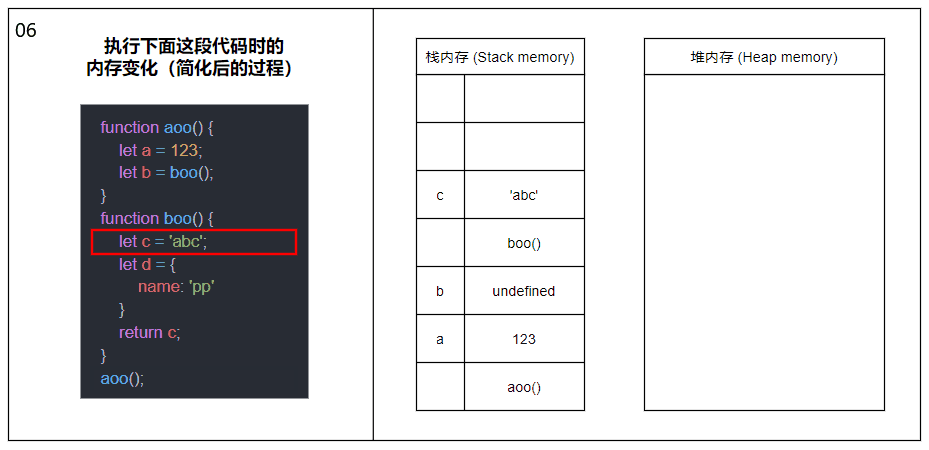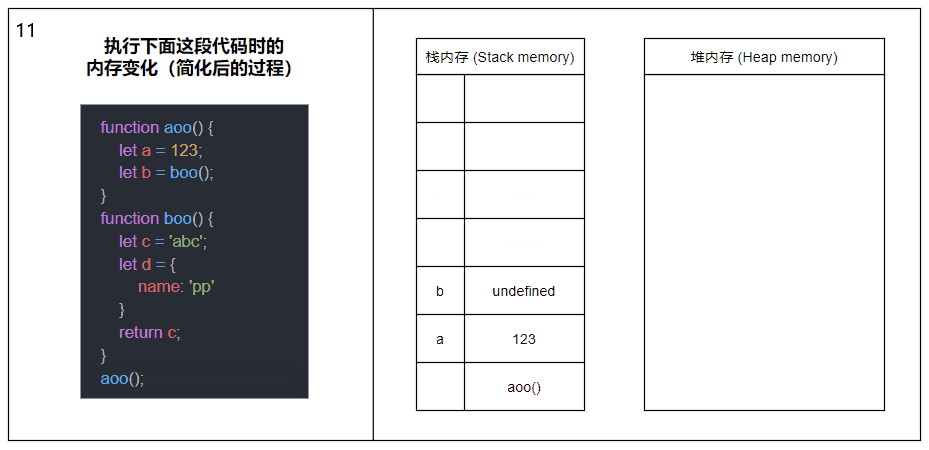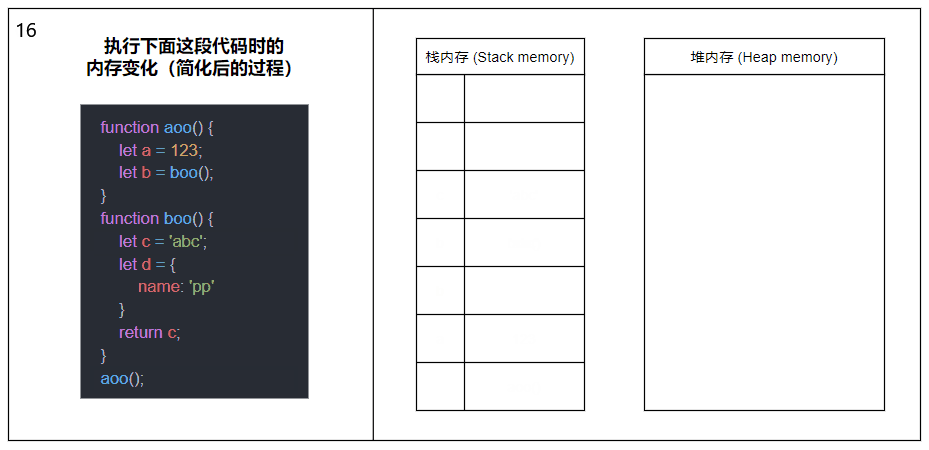
上图中的内容经过了简化,剥离了栈帧和各种指针的概念,主要展示函数调用以及内存分配的大概过程。
在同一线程下(JavaScript 是单线程的),所有被执行的函数以及函数的参数和局部变量都会被推入到同一个栈内存中,这也就是大量递归会导致栈溢出(Stack overflow)的原因。
关于图中涉及到的函数内部变量内存分配的详情请接着往下看。
储存变量(Store variables)
当 JavaScript 程序运行时,在非全局作用域中产生的局部变量均储存在栈内存中。
但是,只有原始类型的变量是真正地把值储存在栈内存中。
而引用类型的变量只在栈内存中储存一个引用(reference),这个引用指向堆内存里的真正的值。
💡 原始类型(Primitive type)
原始类型又称基本类型,包括
string、number、bigint、boolean、undefined、null和symbol(ES6 新增)。原始类型的值被称为原始值(Primitive value)。
补充:虽然
typeof null返回的是'object',但是null真的不是对象,会出现这样的结果其实是 JavaScript 的一个 Bug~
💡 引用类型(Reference type)
除了原始类型外,其余类型都属于引用类型,包括
Object、Array、Function、Date、RegExp、String、Number、Boolean等等…实际上
Object是最基本的引用类型,其他引用类型均继承自Object。也就是说,所有引用类型的值实际上都是对象。引用类型的值被称为引用值(Reference value)。
🎃 简单来说
在多数情况下,原始类型的数据储存在栈内存,而引用类型的数据(对象)则储存在堆内存。
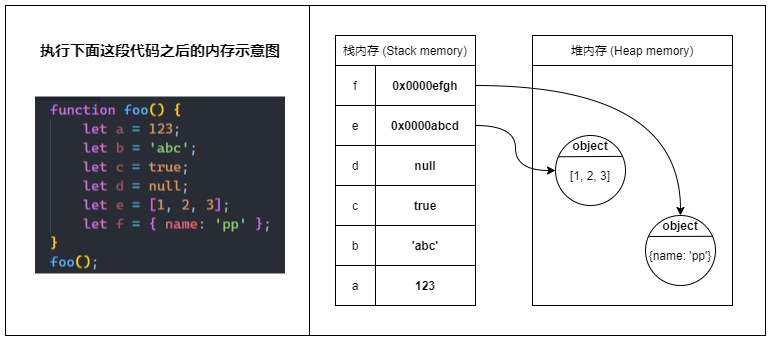
特别注意(Attention)
全局变量以及被闭包引用的变量(即使是原始类型)均储存在堆内存中。
🌐 全局变量(Global variables)
在全局作用域下创建的所有变量都会成为全局对象(如 window 对象)的属性,也就是全局变量。
而全局对象储存在堆内存中,所以全局变量必然也会储存在堆内存中。
不要问我为什么全局对象储存在堆内存中,一会我翻脸了啊!
📦 闭包(Closures)
在函数(局部作用域)内创建的变量均为局部变量。
当一个局部变量被当前函数之外的其他函数所引用(也就是发生了逃逸),此时这个局部变量就不能随着当前函数的返回而被回收,那么这个变量就必须储存在堆内存中。
而这里的“其他函数”就是我们说的闭包,就如下面这个例子:
function getCounter() {
let count = 0;
function counter() {
return ++count;
}
return counter;
}
// closure 是一个闭包函数
// 变量 count 发生了逃逸
let closure = getCounter();
closure(); // 1
closure(); // 2
closure(); // 3
闭包是一个非常重要且常用的概念,许多编程语言里都有闭包这个概念。这里就不详细介绍了,贴一篇阮一峰大佬的文章。
学习 JavaScript 闭包:http://www.ruanyifeng.com/blog/2009/08/learning_javascript_closures.html
💡 逃逸分析(Escape Analysis)
实际上,JavaScript 引擎会通过逃逸分析来决定变量是要储存在栈内存还是堆内存中。
简单来说,逃逸分析是一种用来分析变量的作用域的机制。
不可变与可变(Immutable and Mutable)
栈内存中会储存两种变量数据:原始值和对象引用。
不仅类型不同,它们在栈内存中的具体表现也不太一样。
原始值(Primitive values)
🚫 Primitive values are immutable!
前面有说到:原始类型的数据(原始值)直接储存在栈内存中。
⑴ 当我们定义一个原始类型变量的时候,JavaScript 会在栈内存中激活一块内存来储存变量的值(原始值)。
⑵ 当我们更改原始类型变量的值时,实际上会再激活一块新的内存来储存新的值,并将变量指向新的内存空间,而不是改变原来那块内存里的值。
⑶ 当我们将一个原始类型变量赋值给另一个新的变量(也就是复制变量)时,也是会再激活一块新的内存,并将源变量内存里的值复制一份到新的内存里。
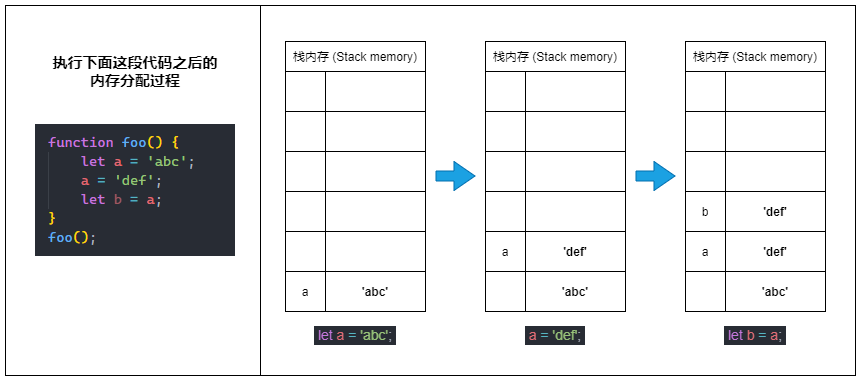
🤠 总之就是:栈内存中的原始值一旦确定就不能被更改(不可变的)。
原始值的比较(Comparison)
当我们比较原始类型的变量时,会直接比较栈内存中的值,只要值相等那么它们就相等。
let a = '123';
let b = '123';
let c = '110';
let d = 123;
console.log(a === b); // true
console.log(a === c); // false
console.log(a === d); // false
对象引用(Object references)
🧩 Object references are mutable!
前面也有说到:引用类型的变量在栈内存中储存的只是一个指向堆内存的引用。
⑴ 当我们定义一个引用类型的变量时,JavaScript 会先在堆内存中找到一块合适的地方来储存对象,并激活一块栈内存来储存对象的引用(堆内存地址),最后将变量指向这块栈内存。
💡 所以当我们通过变量访问对象时,实际的访问过程应该是:
变量 -> 栈内存中的引用 -> 堆内存中的值
⑵ 当我们把引用类型变量赋值给另一个变量时,会将源变量指向的栈内存中的对象引用复制到新变量的栈内存中,所以实际上只是复制了个对象引用,并没有在堆内存中生成一份新的对象。
⑶ 而当我们给引用类型变量分配为一个新的对象时,则会直接修改变量指向的栈内存中的引用,新的引用指向堆内存中新的对象。
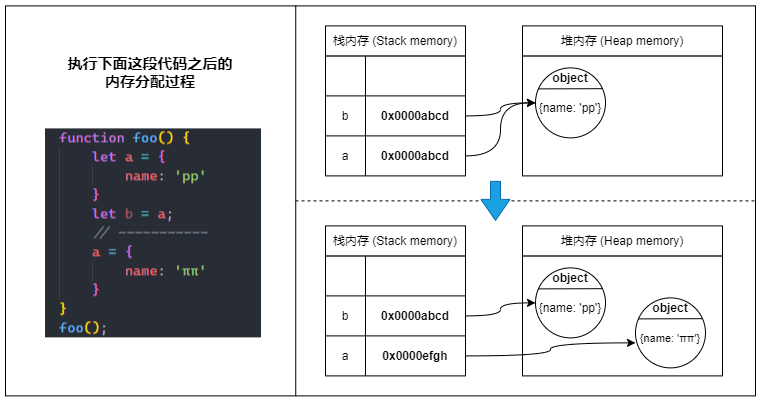
🤠 总之就是:栈内存中的对象引用是可以被更改的(可变的)。
对象的比较(Comparison)
所有引用类型的值实际上都是对象。
当我们比较引用类型的变量时,实际上是在比较栈内存中的引用,只有引用相同时变量才相等。
即使是看起来完全一样的两个引用类型变量,只要他们的引用的不是同一个值,那么他们就是不一样。
// 两个变量指向的是两个不同的引用
// 虽然这两个对象看起来完全一样
// 但它们确确实实是不同的对象实例
let a = {
name: 'pp' }
let b = {
name: 'pp' }
console.log(a === b); // false
// 直接赋值的方式复制的是对象的引用
let c = a;
console.log(a === c); // true
对象的深拷贝(Deep copy)
当我们搞明白引用类型变量在内存中的表现时,就能清楚地理解为什么浅拷贝对象是不可靠的。
在浅拷贝中,简单的赋值只会复制对象的引用,实际上新变量和源变量引用的都是同一个对象,修改时也是修改的同一个对象,这显然不是我们想要的。
想要真正的复制一个对象,就必须新建一个对象,将源对象的属性复制过去;如果遇到引用类型的属性,那就再新建一个对象,继续复制…
此时我们就需要借助递归来实现多层次对象的复制,这也就是我们说的深拷贝。
对于任何引用类型的变量,都应该使用深拷贝来复制,除非你很确定你的目的就是复制一个引用。