机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)
机器学习算法与Python实践这个系列主要是参考《机器学习实战》这本书。因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学习算法。恰好遇见这本同样定位的书籍,所以就参考这本书的过程来学习了。
这节学习的是逻辑回归(Logistic Regression),也算进入了比较正统的机器学习算法。啥叫正统呢?我概念里面机器学习算法一般是这样一个步骤:
1)对于一个问题,我们用数学语言来描述它,然后建立一个模型,例如回归模型或者分类模型等来描述这个问题;
2)通过最大似然、最大后验概率或者最小化分类误差等等建立模型的代价函数,也就是一个最优化问题。找到最优化问题的解,也就是能拟合我们的数据的最好的模型参数;
3)然后我们需要求解这个代价函数,找到最优解。这求解也就分很多种情况了:
a)如果这个优化函数存在解析解。例如我们求最值一般是对代价函数求导,找到导数为0的点,也就是最大值或者最小值的地方了。如果代价函数能简单求导,并且求导后为0的式子存在解析解,那么我们就可以直接得到最优的参数了。
b)如果式子很难求导,例如函数里面存在隐含的变量或者变量相互间存在耦合,也就互相依赖的情况。或者求导后式子得不到解释解,例如未知参数的个数大于已知方程组的个数等。这时候我们就需要借助迭代算法来一步一步找到最有解了。迭代是个很神奇的东西,它将远大的目标(也就是找到最优的解,例如爬上山顶)记在心上,然后给自己定个短期目标(也就是每走一步,就离远大的目标更近一点),脚踏实地,心无旁贷,像个蜗牛一样,一步一步往上爬,支撑它的唯一信念是:只要我每一步都爬高一点,那么积跬步,肯定能达到自己人生的巅峰,尽享山登绝顶我为峰的豪迈与忘我。
另外需要考虑的情况是,如果代价函数是凸函数,那么就存在全局最优解,方圆五百里就只有一个山峰,那命中注定了,它就是你要找的唯一了。但如果是非凸的,那么就会有很多局部最优的解,有一望无际的山峰,人的视野是伟大的也是渺小的,你不知道哪个山峰才是最高的,可能你会被命运作弄,很无辜的陷入一个局部最优里面,坐井观天,以为自己找到的就是最好的。没想到山外有山,人外有人,光芒总在未知的远处默默绽放。但也许命运眷恋善良的你,带给你的总是最好的归宿。也有很多不信命的人,觉得人定胜天的人,誓要找到最好的,否则不会罢休,永不向命运妥协,除非自己有一天累了,倒下了,也要靠剩下的一口气,迈出一口气能支撑的路程。好悲凉啊……哈哈。
呃,不知道扯那去了,也不知道自己说的有没有错,有错的话请大家不吝指正。那下面就进入正题吧。正如上面所述,逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏,冥冥人海,滚滚红尘,我们是否找到了最适合的那个她。
一、逻辑回归(LogisticRegression)
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。之前在经典之作《数学之美》中也看到了它用于广告预测,也就是根据某广告被用户点击的可能性,把最可能被用户点击的广告摆在用户能看到的地方,然后叫他“你点我啊!”用户点了,你就有钱收了。这就是为什么我们的电脑现在广告泛滥的原因了。
还有类似的某用户购买某商品的可能性,某病人患有某种疾病的可能性啊等等。这个世界是随机的(当然了,人为的确定性系统除外,但也有可能有噪声或产生错误的结果,只是这个错误发生的可能性太小了,小到千万年不遇,小到忽略不计而已),所以万物的发生都可以用可能性或者几率(Odds)来表达。“几率”指的是某事物发生的可能性与不发生的可能性的比值。
Logistic regression可以用来回归,也可以用来分类,主要是二分类。还记得上几节讲的支持向量机SVM吗?它就是个二分类的例如,它可以将两个不同类别的样本给分开,思想是找到最能区分它们的那个分类超平面。但当你给一个新的样本给它,它能够给你的只有一个答案,你这个样本是正类还是负类。例如你问SVM,某个女生是否喜欢你,它只会回答你喜欢或者不喜欢。这对我们来说,显得太粗鲁了,要不希望,要不绝望,这都不利于身心健康。那如果它可以告诉我,她很喜欢、有一点喜欢、不怎么喜欢或者一点都不喜欢,你想都不用想了等等,告诉你她有49%的几率喜欢你,总比直接说她不喜欢你,来得温柔。而且还提供了额外的信息,她来到你的身边你有多少希望,你得再努力多少倍,知己知彼百战百胜,哈哈。Logistic regression就是这么温柔的,它给我们提供的就是你的这个样本属于正类的可能性是多少。
还得来点数学。(更多的理解,请参阅参考文献)假设我们的样本是{ x, y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:
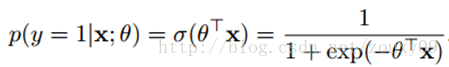
这里θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
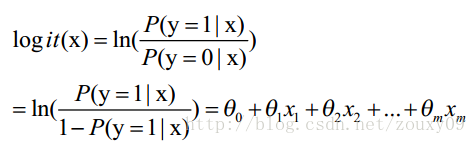
换句话说,y也就是我们关系的变量,例如她喜不喜欢你,与多个自变量(因素)有关,例如你人品怎样、车子是两个轮的还是四个轮的、长得胜过潘安还是和犀利哥有得一拼、有千尺豪宅还是三寸茅庐等等,我们把这些因素表示为x1, x2,…, xm。那这个女