文章目录
- 1、论文总述
- 2、two drawbacks of the use of anchor boxes.
- 3、two reasons why detecting corners would work better than bounding box centers or proposals
- 4、corner pooling
- 5、用于Grouping Corners的 embedding vector的工作原理
- 6、正负样本的分配方式(改进的focal loss)
- 7、角点的offset预测
- 8、Testing Details>
- 9、MS COCO的使用
- 10、选Hourglass Network还是resnet?
- 11、Error analysis.
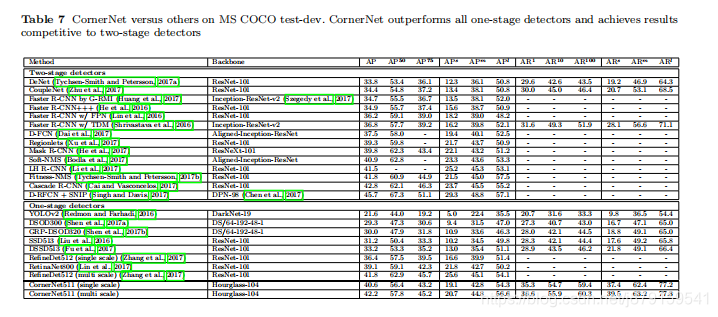
- 12、Comparisons with state-of-the-art detectors
- 参考文献
1、论文总述
本文是2018年ECCV的一篇oral,anchor free的新思路的目标检测的文章,其中2019年的几篇文章都是基于这篇paper改进的(两篇centernet cornernet_lite grid_rcnn等,后面还得看这几篇论文。。),借鉴了这个思路,即将目标检测与关键点检测(目标分割的知识)结合起来,不再采用以前流行的:先提前设定好多不同尺度和shape的anchors然后训练时候不断回归到GT。
本文思路:直接预测各个目标的左上和右下角点,然后这俩角点一组合就能框住这个目标,想法很直接,应该有很多先进的科研工作者尝试过这个想法,但为了让网络能够work,需要设计很多辅助的结构来帮助网络真的提取到各个目标的角点并分组,例如作者 为了 更好地提取角点采用沙漏网络作为backbone(论文中也有数据对比,采用resnet+fpn的话性能不如沙漏网络), 为了 更好通过物体边缘的特征来提取角点设计了corner pooling,为了 更好地将同一个目标的左上和右下角点组合到一起采用了embedding vector,为了 更好地进行难易样本的训练设计了改进版的focal loss等等吧。。
【注】:本文主要是被一篇多人姿态预测的paper启发:Associative embedding: End-to-end learning for joint detection and grouping.(后面看这篇)
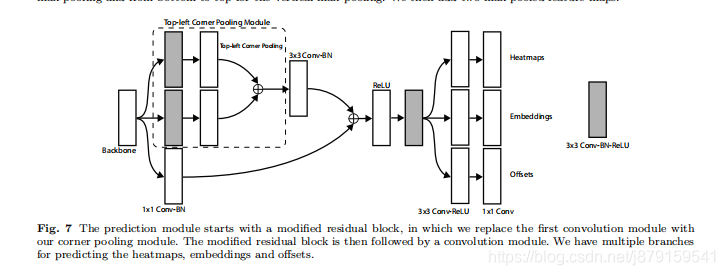
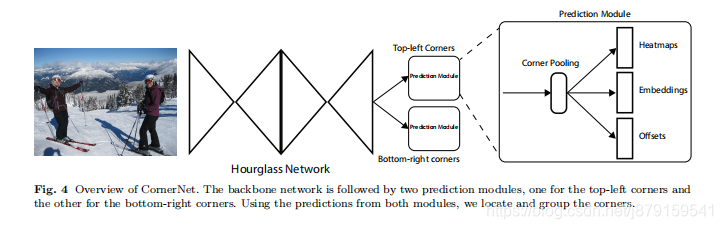
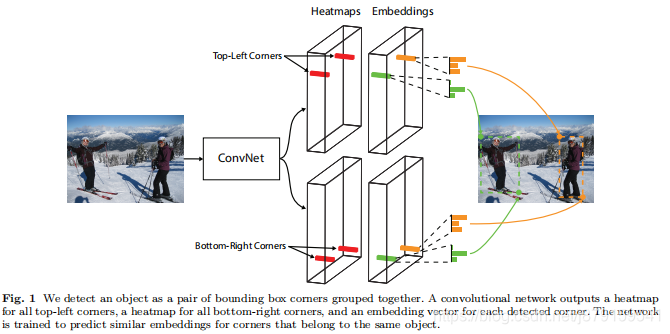
网络forward流程:根据上图,首先经过Hourglass Network backbone提取特征,通过这个backbone Feature map一般降为原图w/4 h/4,feature map尺寸一般比anchor类目标检测网络的要大,所以文中也说到,只把网络的头部加到backbone的最后一层feature map即可,并没有像ssd那样用不同级别的feature map,然后是分成两个模块(一个左上 一个右下模块)分别经过改进的残差块,这个残差块里加了 corner pooling(如上图),然后进过一系列卷积字后即分别得到两个模块的三个部分:heatmaps、embeddings和offsets。
In this paper we introduce CornerNet, a new onestage approach to object detection that does away with
anchor boxes. We detect an object as a pair of keypoints—
the top-left corner and bottom-right corner of the bounding box. We use a single convolutional network to predict a heatmap for the top-left corners of all instances
of the same object category, a heatmap for all bottomright corners, and an embedding vector for each detected corner. The embeddings serve to group a pair of
corners that belong to the same object—the network is
trained to predict similar embeddings for them.
2、two drawbacks of the use of anchor boxes.
But the use of anchor boxes has two drawbacks.
First, we typically need a very large set of anchor boxes,
e.g. more than 40k in DSSD (Fu et al., 2017) and more
than 100k in RetinaNet (Lin et al., 2017). This is because the detector is trained to classify whether each
anchor box sufficiently overlaps with a ground truth
box, and a large number of anchor boxes is needed to
ensure sufficient overlap with most ground truth boxes.
As a result, only a tiny fraction of anchor boxes will
overlap with ground truth; this creates a huge imbalance between positive and negative anchor boxes and
slows down training (Lin et al., 2017).
Second, the use of anchor boxes introduces many
hyperparameters and design choices. These include how
many boxes, what sizes, and what aspect ratios. Such
choices have largely been made via ad-hoc heuristics,
and can become even more complicated when combined
with multiscale architectures where a single network
makes separate predictions at multiple resolutions, with
each scale using different features and its own set of anchor boxes (Liu et al., 2016; Fu et al., 2017; Lin et al.,
2017).
缺点1:为了覆盖各种各样的GT,需要大量的anchors,
缺点2:超参数太多,设计复杂,尤其是多尺度输入或者利用多尺度feature map时
3、two reasons why detecting corners would work better than bounding box centers or proposals
First, the center of a box can be harder to localize because it depends on all 4 sides of the object,
whereas locating a corner depends on 2 sides and is thus
easier, and even more so with corner pooling, which encodes some explicit prior knowledge about the definition of corners.
Second, corners provide a more efficient way of densely discretizing the space of boxes: we just need O(wh) corners to represent O(w2h2) possible anchor boxes.
这点就比较有意思了,首先说一下作者的原话,为什么检测角点比检测中心点更好:一是角点利用两条边就能得到,中心点需要4条边得到;二是角点两个点(左上 右下)就可以编码一个框,编码效率高,而中心点需要四个数,例如densebox的相对于左上右下角点的偏移( x1 y1 x2 y2),或者Objects as Points里的相对于中心点的偏移 和 w h,即( x y w h)。
然而 在2019年的工作中,发现作者的这两条假设是 错的!! ,就是因为角点检测利用到的目标特征比较少,只利用边缘特征就可以检测到角点,而中心点需要利用目标内部的特征,所以就导致角点检测误检率很高(这点在本论文中也有实验验证,作者发现角点检测的效果还需要很大提升),而中心点的检测反而效果比较好。
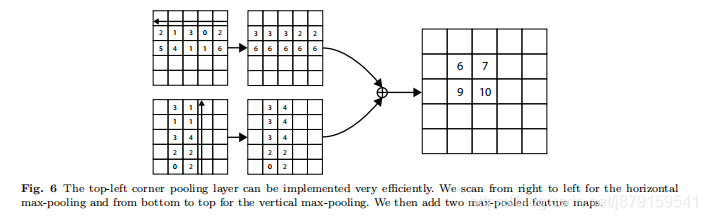
4、corner pooling
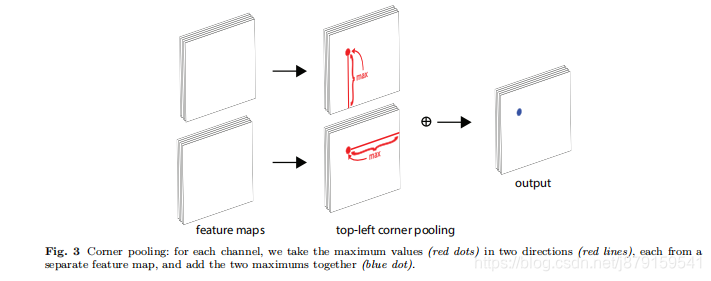
Another novel component of CornerNet is corner pooling,
a new type of pooling layer that helps a convolutional network better localize corners of bounding boxes.
A corner of a bounding box is often outside the
object—consider the case of a circle as well as the examples in Fig. 2. In such cases a corner cannot be localized based on local evidence. Instead, to determine
whether there is a top-left corner at a pixel location, we
need to look horizontally towards the right for the
topmost boundary of the object, and look vertically towards the bottom for the leftmost boundary. (以下为具体操作)
This motivates our corner pooling layer: it takes in two feature
maps; at each pixel location it max-pools all feature
vectors to the right from the first feature map, maxpools all feature vectors directly below from the second
feature map, and then adds the two pooled results together. An example is shown in Fig. 3
例子:找左上角点,该点向右看找最大值找到的是‘上’ 该点向下看找到的最大值是‘左’ 这样左上这个角点即找到了,右下这个角点同理。下图为具体例子:

5、用于Grouping Corners的 embedding vector的工作原理
这篇paper中对左上和右下角点的检测是分开的,就是在两个feature map上分分别检测左上和右下角点,即这张feature map上都是同类别的目标的左上角点,而另一个模块的某张feature map上都是同类别的目标的右下角点,那想组成框的话需要把同一个目标的左上和右下角点组合在一起,这就是embedding vector的作用,至于作者为什么没有在一张feature map上同时进行左上和右下角点的检测,这个不清楚,可能是参考的那篇人体姿态的论文的关系,毕竟检测人体关键点的时候,只有人一个类别,然后heatmap的channel个数为k,这个k是指人体关键点。
接下来说一下自己对embedding vector工作原理的理解:
如上图所示:embeddings是根据heatmap上每个点及其周围的特征产生的一个n维向量,即每个角点都会产生一个n维的向量,这个向量编码了这个角点对应目标的信息,如果某左上角点和右下角点是同一个目标的,那对应的这两个embedding vector应该很相似,也就是这个两个向量之间的距离很小,因为他们编码的是同一个目标的信息,然后根据这种理论,不断训练网络,让embedding vector确实可以学到每对角点对应的embedding vector,而且他们之间距离很近,但不同目标的角点之间距离很大,要让网络学成这样才能效果好,
但 我自己对这个总觉得有点不靠谱,感觉让网络学成这样有点难,不同类别的embedding vector之间距离很大,这个可能还好说,但同一个类别之间的物体很相似,让他们之间的embedding vector距离很大感觉有点困难,这可能就是cornernet会误检多的原因,具体的还得去看参考的那篇人体姿态的论文,因为embedding vector出自那篇论文,这个只是我的一点猜想。
embedding vector训练时的损失函数如下:

【注】:heatmaps是C个channel,C为目标类别,同一个channel的heatmap是同一个类别的所有目标的左上角点。
6、正负样本的分配方式(改进的focal loss)
基于anchor的目标检测网络一般都是根绝anchor和GT之间的iou来定正负样本:IOU大于多少为正样本,小于多少为负样本,但由于这个网络只用检测角点,所以正样本就是各个目标GT的左上和右下角点对应的那个位置,值为1,其他位置为负样本,但这样的话,正样本太少,负样本很多,所以作者提出了一种 减小挨正样本挨得近负样本的损失,挨得越近它的值越大,但不超过1,离正样本越远(但在某个半径之内,这个半径实验中根据具体目标大小而定,而且让这对角点产生的框与GT的IOU大于某个阈值)值越小,衰减速度是用的高斯核函数,正负样本的损失函数为:


7、角点的offset预测
Hence, a location (x, y) in the image is mapped to the location
( ⌊ x n ⌋ , ⌊ y n ⌋ ) \left(\left\lfloor\frac{x}{n}\right\rfloor,\left\lfloor\frac{y}{n}\right\rfloor\right) (⌊nx⌋,⌊ny⌋)
in the heatmaps, where n is the downsampling factor. When we remap the locations from the
heatmaps to the input image, some precision may be
lost, which can greatly affect the IoU of small bounding
boxes with their ground truths. To address this issue we
predict location offsets to slightly adjust the corner locations before remapping them to the input resolution
o k = ( x k n − ⌊ x k n ⌋ , y k n − ⌊ y k n ⌋ ) \boldsymbol{o}_{k}=\left(\frac{x_{k}}{n}-\left\lfloor\frac{x_{k}}{n}\right\rfloor, \frac{y_{k}}{n}-\left\lfloor\frac{y_{k}}{n}\right\rfloor\right) ok=(nxk−⌊nxk⌋,nyk−⌊nyk⌋)
where ok is the offset, xk and yk are the x and y coordinate for corner k. In particular, we predict one set of
offsets shared by the top-left corners of all categories,
and another set shared by the bottom-right corners. For
training, we apply the smooth L1 Loss (Girshick, 2015)
at ground-truth corner locations:
注意:这个预测的角点的偏移是由于下采样导致的与原图不对应,而且对每个点只预测两个偏移,一个x的,一个y的,不分类别,应该是只有2个channel,而不是2C个channel。
损失函数为:
L
o
f
f
=
1
N
∑
k
=
1
N
SmoothL
1
L
cos
(
o
k
,
o
^
k
)
L_{o f f}=\frac{1}{N} \sum_{k=1}^{N} \operatorname{SmoothL} 1 \mathrm{L} \cos \left(\boldsymbol{o}_{k}, \hat{\boldsymbol{o}}_{k}\right)
Loff=N1k=1∑NSmoothL1Lcos(ok,o^k)
至此网络的总损失函数为:
L = L d e t + α L p u l l + β L p u s h + γ L o f f L=L_{d e t}+\alpha L_{p u l l}+\beta L_{p u s h}+\gamma L_{o f f} L=Ldet+αLpull+βLpush+γLoff
8、Testing Details>
During testing, we use a simple post-processing algorithm to generate bounding boxes from the heatmaps, embeddings and offsets. We first apply non-maximal
suppression (NMS) by using a 3×3 max pooling layer on
the corner heatmaps. Then we pick the top 100 top-left
and top 100 bottom-right corners from the heatmaps.
The corner locations are adjusted by the corresponding offsets. We calculate the L1 distances between the
embeddings of the top-left and bottom-right corners.
Pairs that have distances greater than 0.5 or contain
corners from different categories are rejected. The average scores of the top-left and bottom-right corners are
used as the detection scores.
Instead of resizing an image to a fixed size, we maintain the original resolution of the image and pad it with zeros before feeding it to CornerNet. Both the original
and flipped images are used for testing. We combine the
detections from the original and flipped images, and apply soft-nms (Bodla et al., 2017) to suppress redundant
detections. Only the top 100 detections are reported.
The average inference time is 244ms per image on a
Titan X (PASCAL) GPU.
测试时候流程:先分别挑出100个左上角点 和100个右下角点,然后用预测出的offset进行调整,最后根据计算 embbeding 之间的距离对角点进行分组。
9、MS COCO的使用
We evaluate CornerNet on the very challenging MS
COCO dataset (Lin et al., 2014). MS COCO contains
80k images for training, 40k for validation and 20k for
testing. All images in the training set and 35k images in
the validation set are used for training. The remaining
5k images in validation set are used for hyper-parameter
searching and ablation study.
10、选Hourglass Network还是resnet?

在检测关键点方面,还是沙漏网络更胜一筹。
11、Error analysis.