一、概要
数据操作是R语言的一大优势,用户可以利用基本包或者拓展包在R语言中进行复杂的数据操作,包括排序、更新、分组汇总等。R数据操作包:data.table和tidyfst两个扩展包。
data.table是当前R中处理数据最快的工具,可以实现快速的数据汇总、连接、删除、分组计算等操作,具有稳定、速度快、省内存、特性丰富、语法简洁等特点。由于其函数语法结构相对来说较为抽象,对于初学者而言往往需要花更多的时间来掌握。
tidyfst包应运而生,用以提高data.table代码的可读性和可维护性。tidyfst包参考了tidyverse体系的语法结构,让用户能够见名知义;同时,其底层由data.table代码构成,因此实现速度非常快。对于较为复杂的data.table操作,tidyfst包提供了简便的调用函数进行实现。
资料来源:《机器学习全解(R语言版)》 黄天元 2024年7月出版
二、数据读写
在data.table包中可以使用fread和fwrite函数对csv格式的文件进行读写。
如果需要保存规模较大的数据,可以使用tidyfst包的import_fst和export_fst函数来进行数据读写,其数据保存格式为以fst为扩展名的二进制文件。它的特点就是数据高保真、读写速度快和压缩效果好,因此保存下来的fst文件往往要比csv格式占用内存更小。
library(pacman)
p_load(tidyfst,data.table)
fwrite(iris,"D:/iris.csv")
ir=fread("D:/iris.csv")
export_fst(iris,"D:/iris.fst")
ir=import_fst("D:/iris.fst")
三、筛选列
1、选择需要的列
library(pacman)
p_load(tidyfst,data.table)
ir=as.data.table(iris)
ir
# 选取上面构造的数据框ir中的第1、3和4列,以下两种写法等价
ir %>% select_dt(1,3,4) #tidyfst
ir[,c(1,3,4)] # data.table
2、选择连续的列
可以使用“:”符号:
# 选择1到3列
ir %>% select_dt(1:3)
ir[,1:3]
3、根据变量名称选择单列
# 选择Sepal.Length列
ir %>% select_dt(Sepal.Length)
ir[,"Sepal.Length"]
4、根据变量名称选择多列
变量名称之间需要用逗号隔开
# 选择Sepal.Length和Petal.Length两列
ir %>% select_dt(Sepal.Length,Petal.Length)
ir[,c("Sepal.Length","Petal.Length")]
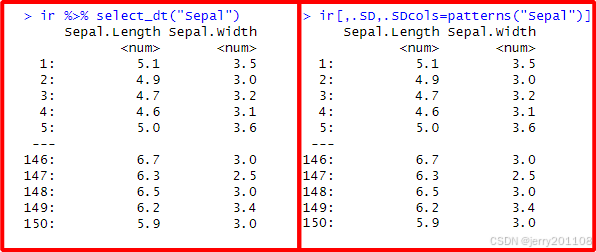
5、根据正则表达式筛选列
# 选择列名称包含“Sepal”的列
ir %>% select_dt("Sepal")
ir[,.SD,.SDcols=patterns("Sepal")]
6、利用特殊函数选择列
# 选择数据类型为因子的列
ir %>% select_dt(is.factor)
ir[,.SD,.SDcols = is.factor]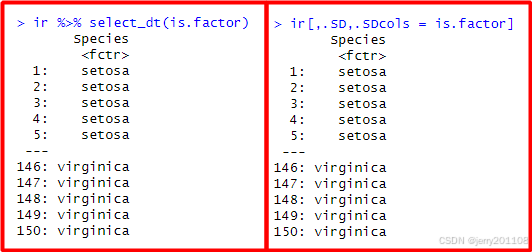
7、排除列
排除一些列,则可以在原来基础上加上减号来实现:
# 排除Sepal.Length和Petal.Length这两列
ir %>% select_dt(-Sepal.Length,-Petal.Length)
ir[,-c("Sepal.Length","Petal.Length")]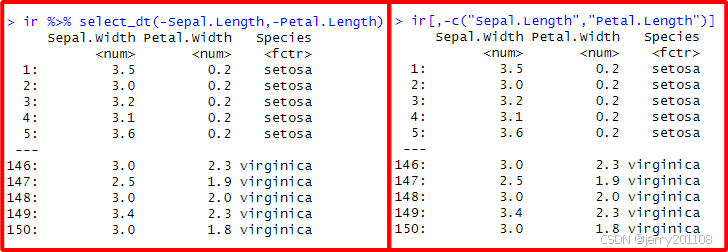
# 排除因子列
ir %>% select_dt(-is.factor)
ir[,.SD,.SDcols = -is.factor]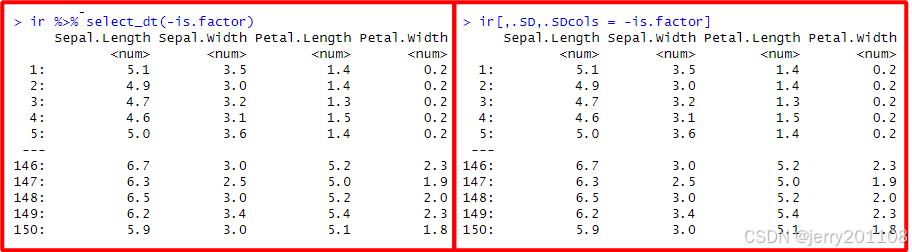
四、筛选行
1、根据单个条件筛选行
# 筛选出Sepal.Length大于7的条目
ir %>% filter_dt(Sepal.Length>7)
ir[Sepal.Length>7]
2、多条件筛选行
如果要附加多个条件,那么条件之间可以利用逻辑运算符&(与)、|(或)和!(非)进行修饰和连接。
# 筛选Species列不为versicolor且Sepal.Length大于6的条目
ir %>% filter_dt(Species != "versicolor" & Sepal.Length > 6)
ir[Species != "versicolor" & Sepal.Length > 6]
3、tidyfst包中现成的筛选函数
| slice_max_dt | 获得Sepal.Length最大的10个条目 ir %>% slice_max_dt(Sepal.Length,10) | |
| slice_min_dt | 获得Sepal.Length最小的10个条目 ir %>% slice_min_dt(Sepal.Length,10) | |
| slice_sample_dt | 随机选择10个条目 ir %>% slice_sample_dt(10) | |
| slice_dt | 根据条目的位置来进行筛选。获得ir数据框的第100行 | |
| ir %>% slice_dt(100) | ir[100] | |
| 选择多行,则可以使用数值向量。选出第100行到第105行 | ||
| ir %>% slice_dt(100:105) | ir[100:105] | |
| unique | 去重 ir %>% unique() | |

五、更新
更新是指对数据框的一列或多列进行修饰,或根据已有列构造新列。
| mutate_dt | 新增常数列、修改列 |
| mutate_when | 按照一定的条件进行列的更新 |
| mutate_vars | 对多个列同时进行原位修饰 |
ir %>% mutate_dt(one=1)
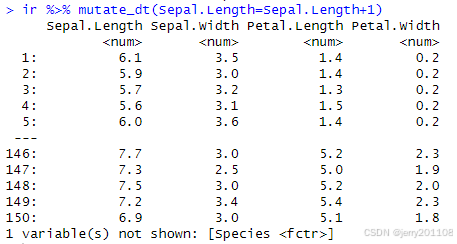
ir %>% mutate_dt(Sepal.Length=Sepal.Length+1)
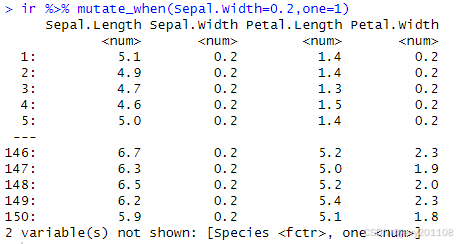
ir %>% mutate_when(Sepal.Width=0.2,one=1)
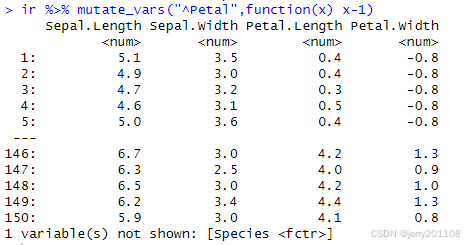
ir %>% mutate_vars("^Petal",function(x) x-1)1、新增一列名为one的常数列,其所有数值均为1
2、让Sepal.Length列的所有数值加1
3、在Petal.Width等于0.2的时候新增名为one的常数列
4、让列名称以Petal开头的列都减去1
六、排序
对数据框进行排序有两种方法,一种是按照行进行排序,另一种是按照列进行排序。
| arrange_dt | 按列排序 |
| relocate_dt | 调整列的位置 |
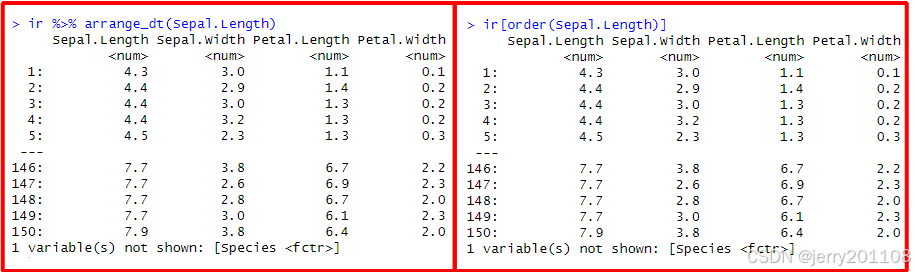
ir %>% arrange_dt(Sepal.Length)
ir[order(Sepal.Length)]
ir %>% arrange_dt(Sepal.Length,Sepal.Width)
ir[order(Sepal.Length,Sepal.Width)]
ir %>% arrange_dt(-Sepal.Length)
ir[order(-Sepal.Length)]
ir %>% relocate_dt(Species,how="first")
ir %>% relocate_dt(Species,how="last")
ir %>% relocate_dt(Petal.Length,how = "after",where = Petal.Width)
# 对列的位置进行重新排列
new_order=names(ir)[c(3,2,4,5,1)]
new_order
ir[,.SD,.SDcols = new_order]
# 直接写上列名称
ir %>% select_mix(Petal.Length,
Sepal.Width,
Petal.Width,
Species,
Sepal.Length)1、按照Sepal.Length列从小到大进行排列
多列:先按照Sepal.Length列进行排列,然后再按照Sepal.Width列进行排列
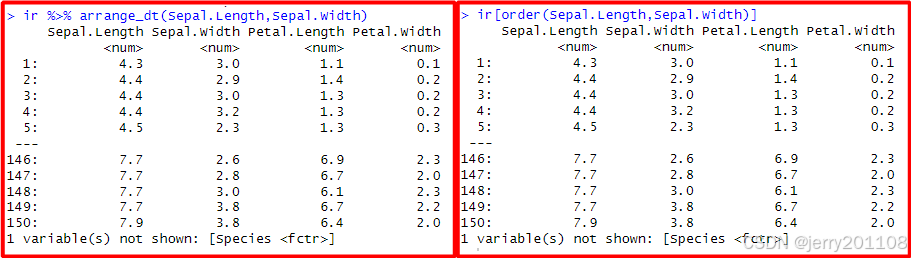
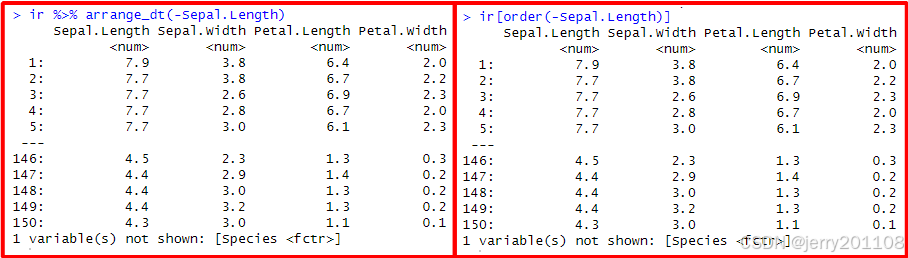
2、从大到小进行排列,在原来的变量之前加入负号
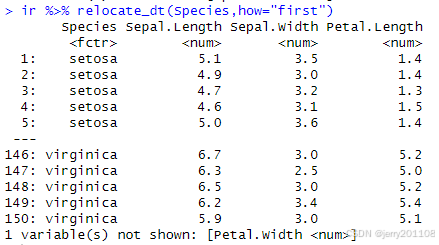
3、调整列的位置
把Species列放到第一列:
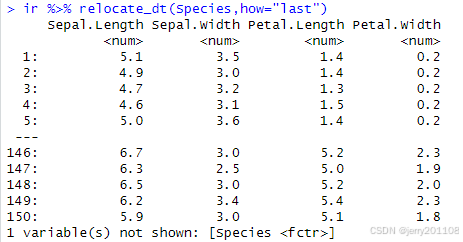
把Sepal.Length列放到最后一列:
七、汇总
汇总的过程是用较少信息表征较多信息的方法。
tidyfst包中使用summarise_dt函数来对数据框中的列进行汇总。
ir %>% summarise_dt(avg=mean(Sepal.Length))
ir %>% summarise_dt(mean=mean(Sepal.Length))
ir %>% summarise_when(Petal.Width==.2,avg=mean(Petal.Length))
ir %>% summarise_vars(2:4,sum)
ir %>% summarise_vars(is.numeric,sum)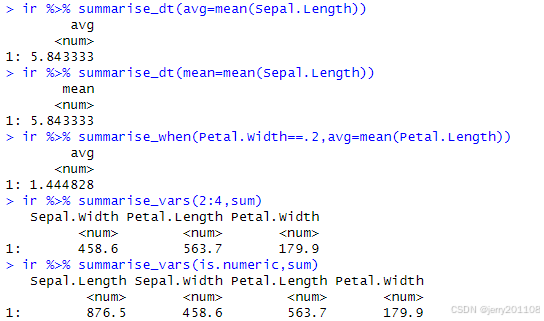
八、分组计算
分组计算就是根据分组结果来对每一个组进行相同的操作。
在tidyfst包中,很多函数都具有by参数,by用来指定分组的变量。
如果需要对多个变量进行分组,那么by参数的指定方式有以下几种:
●在by参数中放入字符串,变量之间以逗号分隔(如by="vs,am");
●在by参数中放入字符向量,字符是分组的列名称(如by=c("vs","am"));
●在by参数中放入一个指定分组变量的列表(如by=list(vs,am))。
ir %>% summarise_dt(avg=mean(Sepal.Length),by=Species)
ir %>% summarise_vars(is.numeric,sum,by=Species)
mt=as_dt(mtcars)
mt
mt %>% summarise_dt(avg=mean(mpg),by="vs,am")
mt %>% summarise_dt(avg=mean(mpg),by=c("vs","am"))
mt %>% summarise_dt(avg=mean(mpg),by=list(vs,am))
mt %>% summarise_dt(avg=mean(mpg),by=.(vs,am))


九、列的重命名
tidyfst包中使用rename_dt函数来对列进行重命名。对多个列进行重命名,只要用逗号隔开即可。
ir %>% rename_dt(sl=Sepal.Length)
ir %>% rename_dt(sl=Sepal.Length,sw=Sepal.Width)
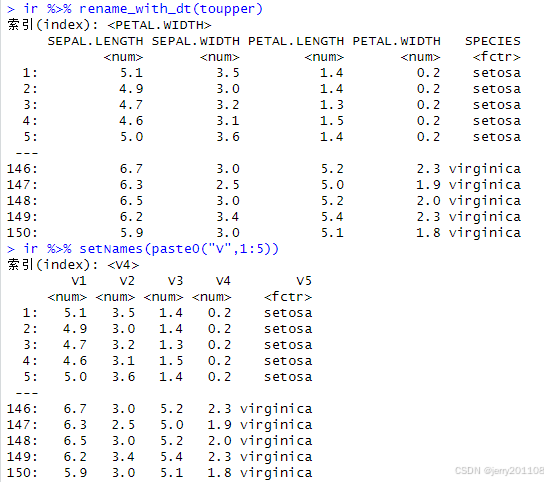
ir %>% rename_with_dt(toupper)
ir %>% setNames(paste0("V",1:5))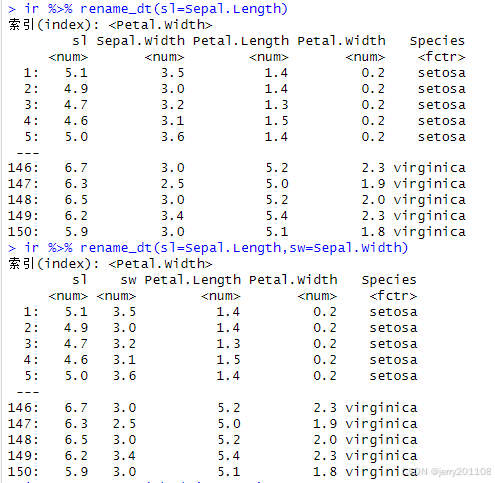
十、多表连接
连接是指根据表格所包含的共同信息来对多个表格进行合并的过程。基本的连接可以分为内连接、全连接、左连接和右连接。
内连接又称为自然连接,该操作会从结果表中删除与其他被连接表中没有匹配行的所有行,只保留两个表格中都包含的数据条目。
全连接会保留所有表格的所有信息。
左连接则仅会保证左边(即第一个出现的)表格的信息会被完全保留,右边(第二个)表格的信息只有与第一个表格的信息匹配的才能够保留。
右连接是左连接的逆运算,即完全保留第二个表格的信息,而第一个表格中只有与第二个表格的信息匹配的内容才能保留。
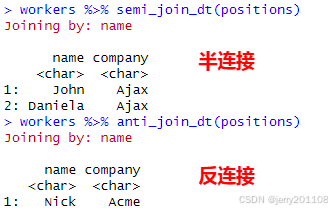
还有一种特殊的连接方式叫作过滤型连接,它包括反连接和半连接。
半连接与左连接相似,但是它只保留了左表格的所有列,而右表格的列则不会放入结果。这相当于只提取了右表格的匹配列,然后与左表格进行连接。
反连接则与半连接相反,它会保留左表和右表对应列相异的部分。
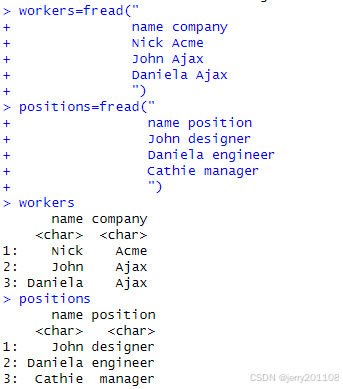
workers=fread("
name company
Nick Acme
John Ajax
Daniela Ajax
")
positions=fread("
name position
John designer
Daniela engineer
Cathie manager
")
workers
positions
workers %>% inner_join_dt(positions)
workers %>% merge(positions)
workers %>% full_join_dt(positions)
workers %>% merge(positions,all = T)
workers %>% left_join_dt(positions)
workers %>% merge(positions,all.x = T)
workers %>% right_join_dt(positions)
workers %>% merge(positions,all.y = T)
workers %>% left_join_dt(positions,by="name")
workers %>% merge(positions,all.x = T,by="name")
positions2=setNames(positions,c("worker","position"))
workers
positions2
workers %>% inner_join_dt(positions2,by=c("name"="worker"))
workers %>% inner_join_dt(positions2,on="name==worker")
workers %>% merge(positions2,by.x="name",by.y = "worker")
workers %>% semi_join_dt(positions)
workers %>% anti_join_dt(positions)


十一、长宽转换
tidyfst包中的longer_dt函数实现将“宽数据”转换成“长数据”。
tidyfst包中的wider_dt函数实现“长数据”转成“宽数据”。
stocks=data.frame(
time=as.Date('2009-01-01')+0:9,
X=rnorm(10,0,1),
Y=rnorm(10,0,2),
Z=rnorm(10,0,4)
)
stocks
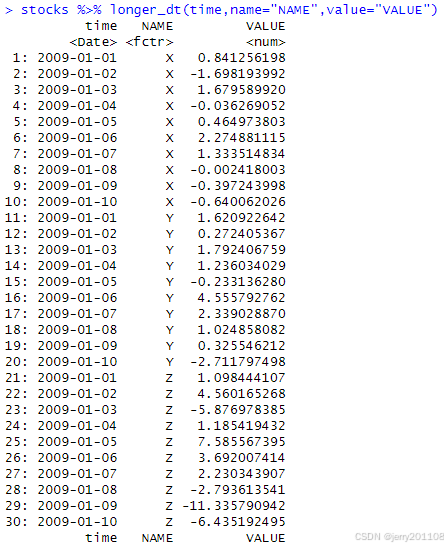
# 转成长数据
stocks %>% longer_dt(time) -> long_stocks
long_stocks
stocks %>% longer_dt(time,name="NAME",value="VALUE")
# 转成宽数据
wide_stockes=long_stocks %>% wider_dt(name="name",value="value")
wide_stockes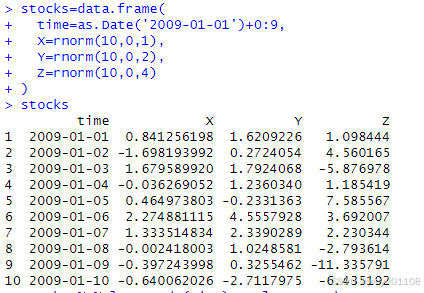
十二、集合运算
| tidyfst包函数 | data.table包函数 | |
|---|---|---|
| 交集 | intersect_dt | fintersect |
| 并集 | union_dt | funion |
| 差集 | setdiff_dt | fsetdiff |
注意:tidyfst包会自动地把任意数据框转化为data.table格式。
十三、缺失值处理
1、删除缺失记录
na.omit函数可以删掉任意包含缺失值的行。
tidyfst包的drop_na_dt函数可以实现删除某一列中存在缺失值的条目。
2、缺失值填充
tidyfst包中的replace_na_dt函数实现填充指定的值。
tidyfst包的fill_na_dt函数实现将上一个观测值作为下面缺失的填充值。
tidyfst包中的impute_dt函数实现使用非缺失数值的均值、中位数或众数来对缺失值进行填充。
十四、列表列的应用
列表列(list column)是R语言中相对较新的一个概念,它能够根据分组把一整块数据集成在一起成为一列,而这个列的数据类型为列表(list)。在tidyfst包中可以使用nest_dt函数进行实现。