目录
| 序号 | 函数 | 说明 |
|---|---|---|
| 1 | describe() | 查看每一列的描述性统计量【必须是数字】 |
| 2 | df.info() | 查看数据信息 |
| 3 | df.std() | 可以求得DataFrame对象每一列的标准差 |
| 4 | df.drop() | 删除特定索引 |
| 5 | unique() | 唯一、去重【只能用于一维数组Series】 |
| 6 | query() | 按条件查询 |
| 7 | df.sort_values() | 根据值排序 |
| 8 | df.sort_index() | 根据索引排序 |
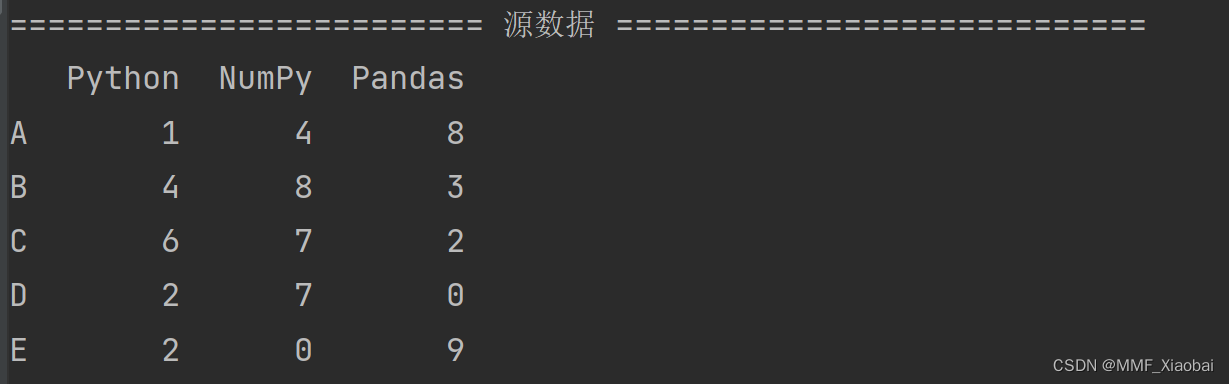
1. 源数据
data = np.random.randint(0, 10, size=(5, 3))
df = pd.DataFrame(data=data, index=list('ABCDE'), columns=['Python', 'NumPy', 'Pandas'])
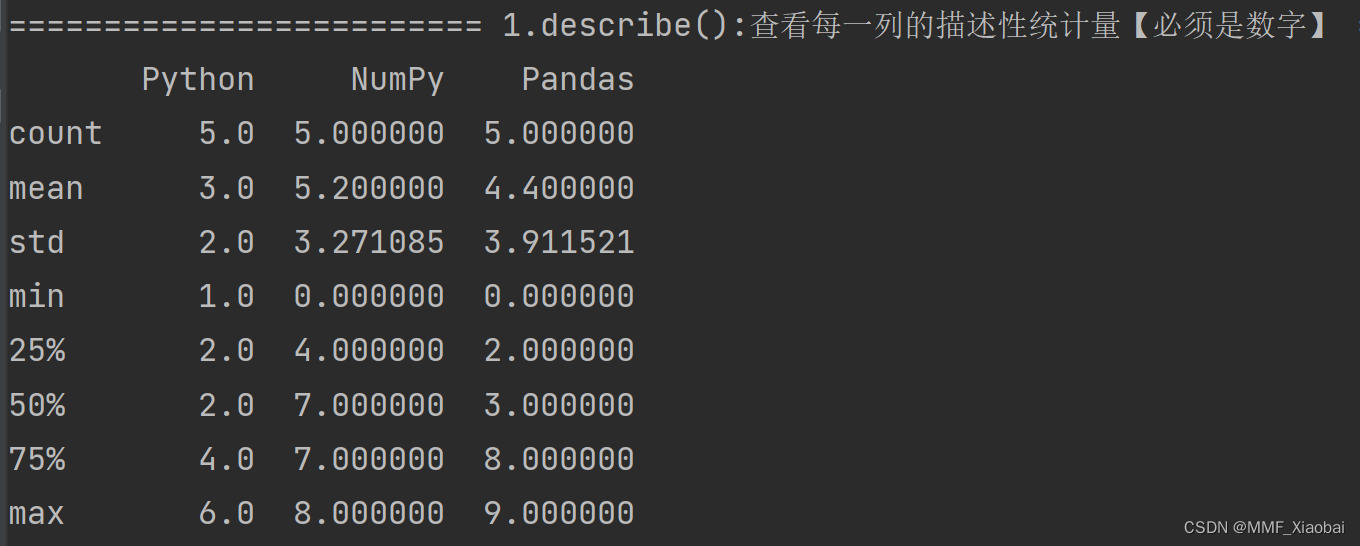
2. describe()
"""
count:数量统计,此列共有多少有效值
mean:均值
std:标准差
min:最小值
25%:四分之一分位数
50%:二分之一分位数
75%:四分之三分位数
max:最大值
"""
df.describe()
# .T行列转换 自行规定百分比
df.describe([0.01, 0.3, 0.4, 0.9, 0.99]).T

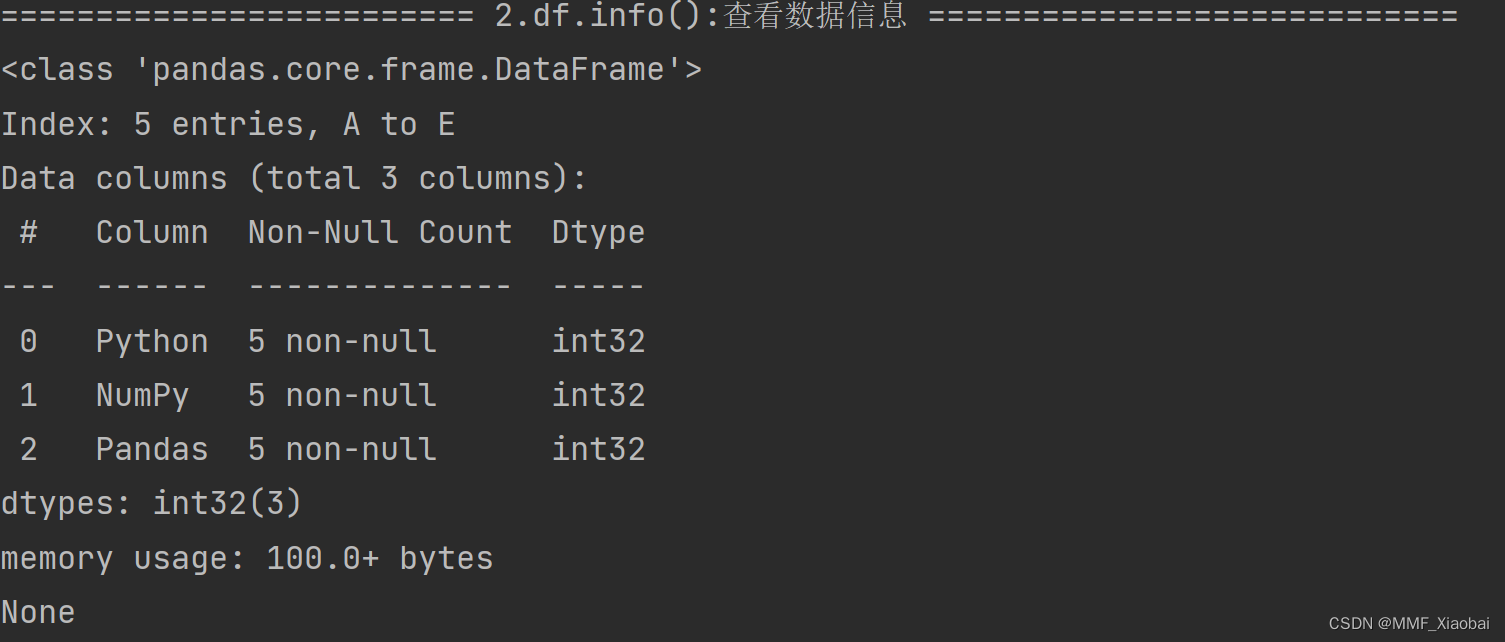
3.df.info()
df.info()
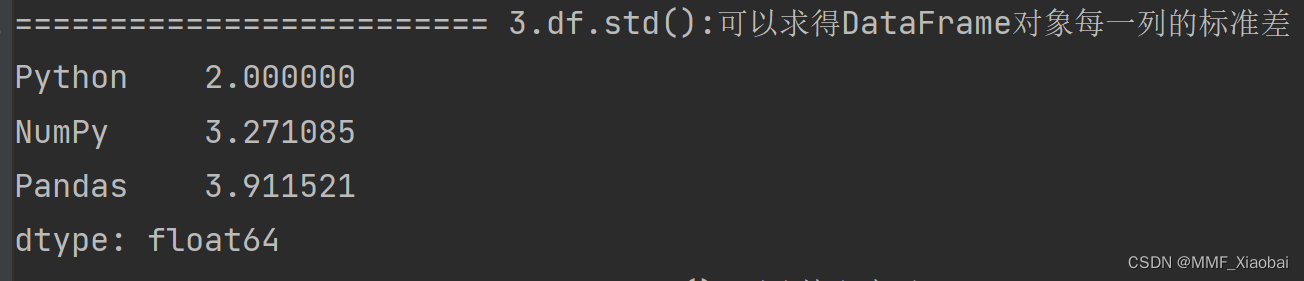
4. df.std()
df.std()
5.df.drop()
print(df2.drop(['A', 'B'])) # 行
# print(df2.drop(['Python'], axis=1)) # 列

6.unique()【唯一、去重【只能用于一维数组Series】】
df['Python'].unique()

7.query()【按条件查询】
# == > <
# and &
# or |
# in 成员运算符
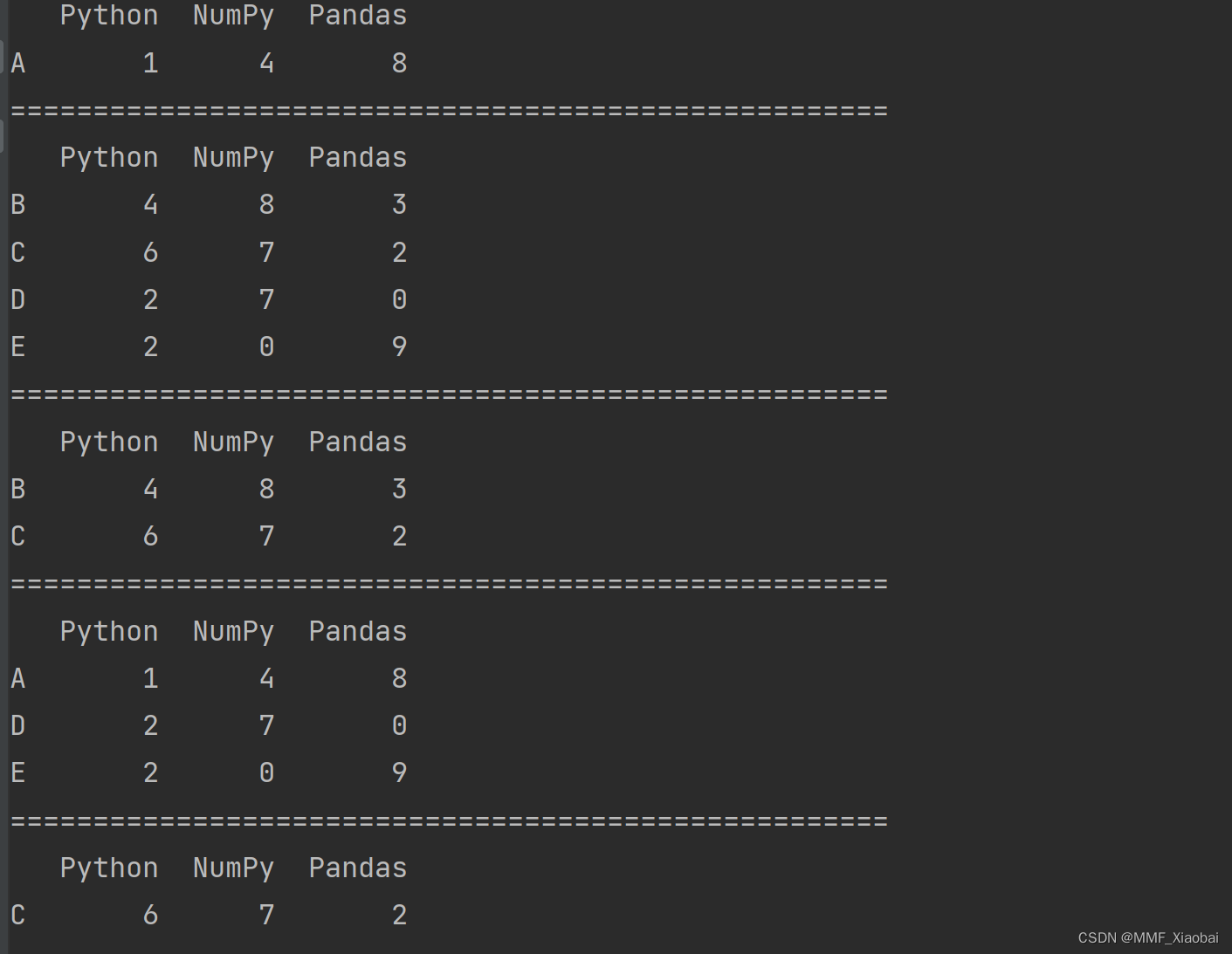
print(df.query('Python == 1')) # 查询Python列中等于1的所有行
print("=====================================================")
print(df.query('Python > 1'))
print("=====================================================")
print(df.query('Python > 3 & Python < 9'))
print("=====================================================")
print(df.query('Python in [1,2,3]'))
print("=====================================================")
n = 5
print(df.query('Python > @n')) # @n 表示使用n的值
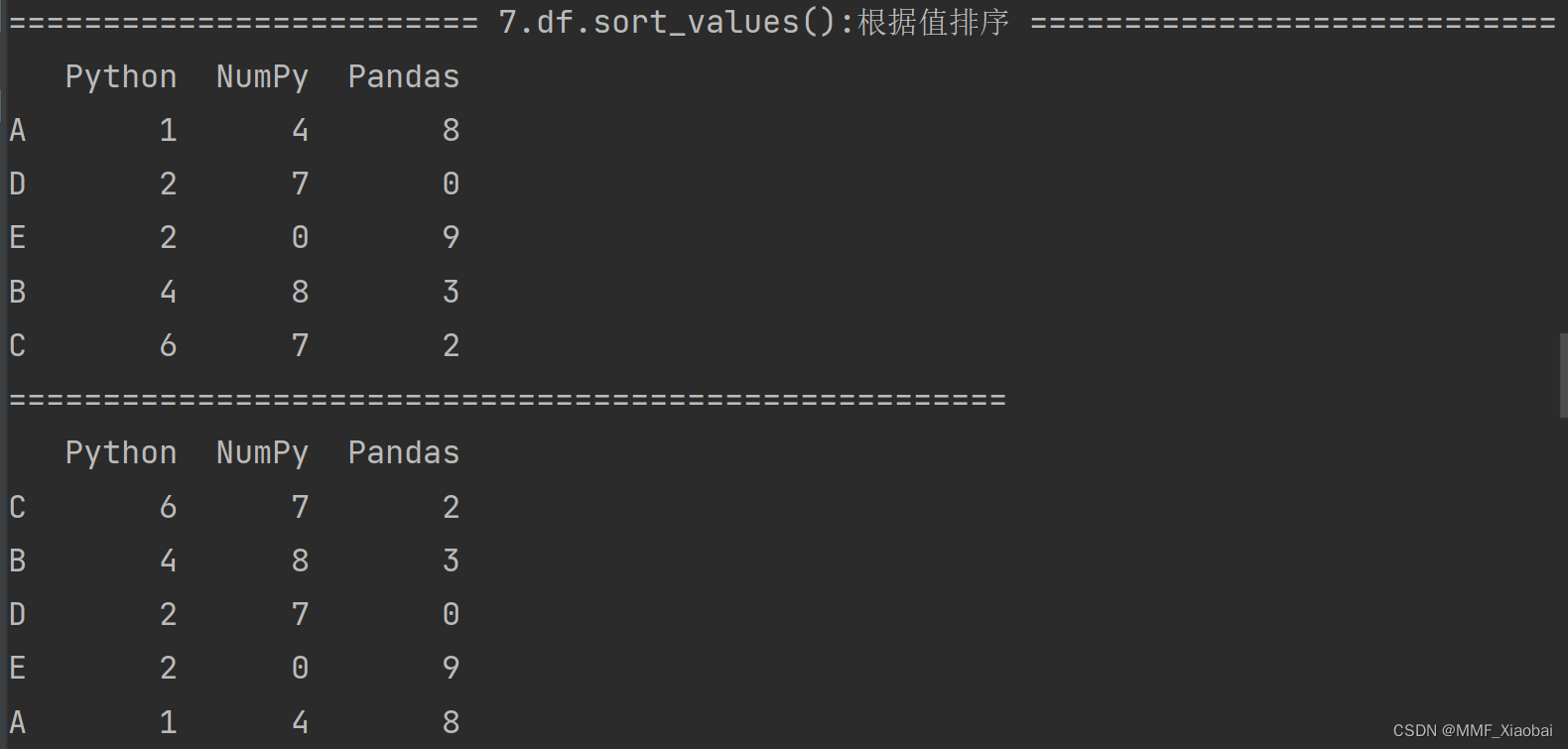
8. df.sort_values()【根据值排序】
# 按照列名进行排序,默认是升序
df.sort_values('Python')
# 降序
df.sort_values('Python', ascending=False)
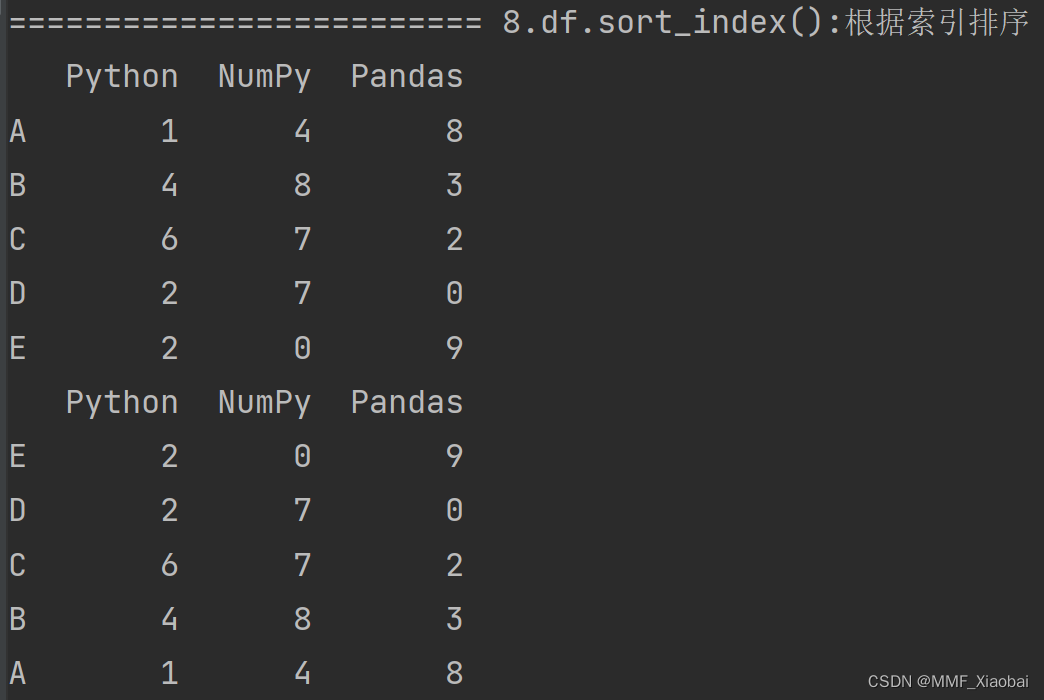
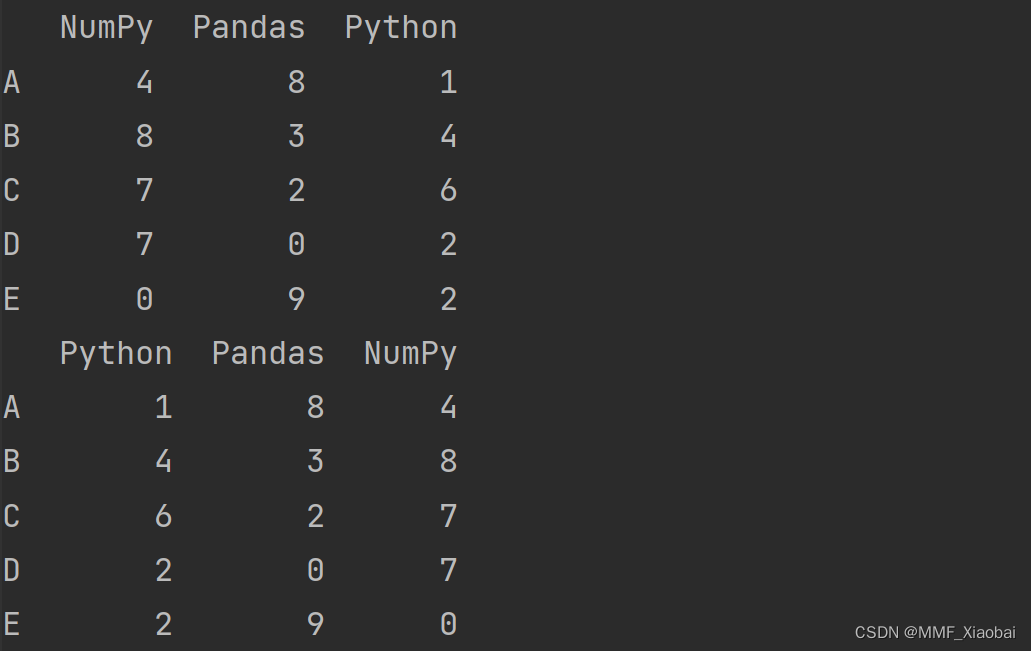
9.df.sort_index()【根据索引排序】
# 行索引
print(df.sort_index(axis=0)) # 升序
print(df.sort_index(axis=0, ascending=False)) # 降序
# 列索引
print(df.sort_index(axis=1)) # 升序
print(df.sort_index(axis=1, ascending=False)) # 降序
10.练习
新建一个形状10000*3的标准正态分布的DataFrame(np.random.randn)
去除所有满足以下情况的行:其中任一元素绝对值大于3倍标准差
df = pd.DataFrame(np.random.randn(10000, 3))
print(df.head())
# 过滤掉 大于3倍标准差的行
# 标准差
print("=====================================================")
print(df.abs()) # 绝对值
print("=====================================================")
print(df.std()) # 每一列的标准差
print("=====================================================")
print(df.std() * 3) # 3倍标准差
print("=====================================================")
cond = df.abs() > df.std() * 3
print(cond.any(axis=1)) # 判断是否有符合条件的
print("=====================================================")
print(df[cond.any(axis=1)]) # 通过Boolean值索引过滤数据