需要源码和数据集请点赞关注收藏后评论区留言私信~~~
一、舆情分析
舆情分析很多情况下涉及到用户的情感分析,或者亦称为观点挖掘,是指用自然语言处理技术、文本挖掘以及计算机语言学等方法来正确识别和提取文本素材中的主观信息,通过对带有情感因素主观性文本进行分析,以确定该文本的情感倾向。
文本情感分析的途径: 关键词识别 词汇关联 统计方法 概念级技术
目前主流的情感分析方法主要有两种:基于情感词典的分析法和基于机器学习的分析法
1、 基于情感词典的情感分析
是指根据已构建的专家情感词典,针对对象分析文本进行文本处理抽取关键情感词,计算对象文本的情感倾向。最终分类质量很大程度上取决于专家情感词典的完善度和准确度。目前比较具有代表性的中文情感词典,包括知网情感分析用词语集,台湾大学情感词典,清华大学褒贬词词典等。
2、基于机器学习的情感分析
情感分析本质上也是个二分类的问题,可以采用机器学习的方法识别,选取文本中的情感词作为特征词,将文本矩阵化,利用逻辑回归( logistic Regression )、 朴素贝叶斯(Naive Bayes)、支持向量机(SVM)、K-means以及K-means++等方法进行分类。最终分类效果取决于训练文本的选择以及正确的情感标注。
K-means算法的基本步骤为:
(1)指定聚类数量K(可以通过最优算法获得)。
(2)从数据集中任意随机选取k个对象作为初始聚类中心点或者平均值。
(3)将每个数据点指派给距离其最近的中心点,计算欧几里得距离。
(4)基于k种聚类,计算聚类数据点的新平均值,更新其聚类中心点, 第K个聚类的中心点是一个矢量,该矢量包含此聚类种所有观察点变量的平均值的长度。
(5)迭代计算并最小化总的聚类平方和。重复执行步骤3和步骤4,直到聚类分类结果不再变化或者达到最大迭代次数。
对于K-Means算法可以参见我以下这两篇博客
二、电影评论情感分析实战
下面我们以基于用户的电影评论为基础,使用IMDB电影评论数据,进行主观情感分析,原始数据总共包括正面和负面评价各25000条。
先导入库文件 主要包括Sklearn里面的一些模块 代码如下
#导入库
from sklearn.metrics import classification_report,confusion_matrix,accuracy_score
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import LabelBinarizer
import numpy as np
import pandas as pds
import seaborn as sns
import matplotlib.pyplot as plt
import nltk
from nltk.tokenize.toktok import ToktokTokenizer
from nltk.stem import LancasterStemmer,WordNetLemmatizer
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import SVC
from textblob import TextBlob
from textblob import Word
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize,sent_tokenize
from bs4 import BeautifulSoup
import spacy
import re,string,unicodedata
import seaborn as sns
读入数据 打印正面、负面情感的数值统计结果 各自包含25000条记录

划分训练集和测试机数据,关注评论详细信息以及正面评价或者负面评价的标识信息,分别选定数据的最初45000条记录作为训练集,而剩余的5000条作为测试集,因此测试数据的比例为百分之十,此处可以适当调整,评估的结果也会发生相应变化
接下来用词袋模型和词频-逆文档模型将文本向量化,然后使用逻辑回归模型执行回归处理此处不再赘述 下面直接展示结果
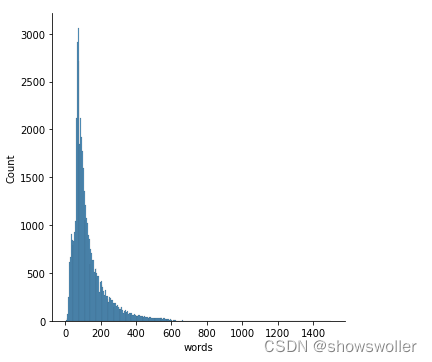
评论的统计结果如下 可以大部分评论在100词左右 也符合实际情况
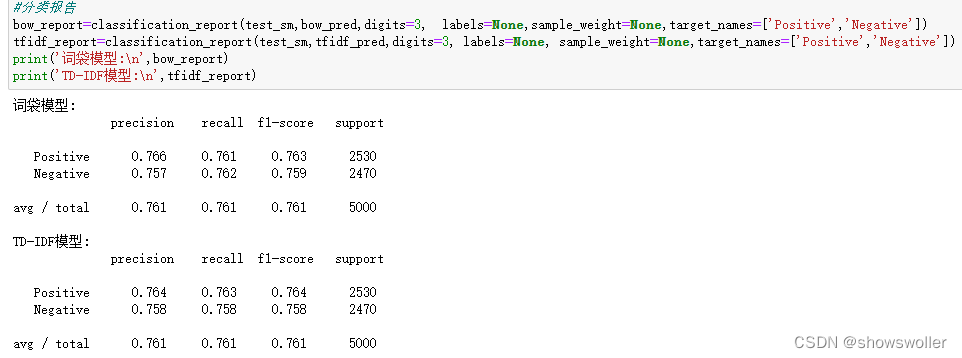
接下来看看两种模型的准确性评估
可见相差不大 两种模型的准确性评估结果为0.75-0.77 维持在大致相当的水平,用户的正面评价和负面评价的指标分析结果没有发生很大差异

三、代码
代码如下 数据集请点赞关注收藏后评论区留言私信~~~
代码主要是jupyter notebook格式 需要python文件格式点赞关注收藏后评论区留言私信即可~
classification_report,confusion_matrix,accuracy_score\n",
"from sklearn.feature_extraction.text import CountVectorizer\n",
"from sklearn.feature_extraction.text import TfidfVectorizer\n",
"from sklearn.preprocessing import LabelBinarizer\n",
"import numpy as np\n",
"import pandas as pds\n",
"import seaborn as sns\n",
"import matplotlib.pyplot as plt\n",
"import nltk\n",
"from nltk.tokenize.toktok import ToktokTokenizer\n",
"from nltk.stem import LancasterStemmer,WordNetLemmatizer\n",
"from sklearn.linear_model import LogisticRegression,SGDClassifier\n",
"from sklearn.naive_bayes import MultinomialNB\n",
"from sklearn.svm import SVC\n",
"from textblob import TextBlob\n",
"from textblob import Word\n",
"from nltk.corpus import stopwords\n",
"from nltk.stem.porter import PorterStemmer\n",
"from nltk.stem import WordNetLemmatizer\n",
"from nltk.tokenize import word_tokenize,sent_tokenize\n",
"from bs4 import BeautifulSoup\n",
"import spacy\n",
"import re,string,unicodedata\n",
"import seaborn as sns\n",
"\n",
"\n",
"\n"
25000\n",
"Name: sentiment, dtype: int64"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"#读入数据\n",
"data=pds.read_csv('data/IMDB Dataset.csv')\n",
"data.head(5)\n",
"#统计情感信息\n",
"data['sentiment'].value_counts()"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"_uuid": "d3aaabff555e07feb11c72cc3a6e457615975ffe"
},
"outputs": [],
"source": [
"# 划分训练集和测试集数据\n",
"train_evaluate=data.review[:45000]\n",
"test_evaluate=data.review[45000:]\n",
"\n",
"train_flag=data.sentiment[:45000]\n",
"test_flag=data.sentiment[45000:]\n"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"_uuid": "f000c43d91f68f6668539f089c6a54c5ce3bd819"
},
"outputs": [],
"source": [
"#文本分词\n",
"#tokenizer=ToktokTokenizer()\n",
"#设置停用词\n",
"#stopword=nltk.corpus.stopwords.words('english')"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"_uuid": "219da72b025121fd98081df50ae0fcaace10cc9d"
},
"outputs": [],
"source": [
"#去除特殊字符\n",
"def regex_character_remove(info, remove_digits=True):\n",
" regx=r'[^A-za-z0-9#@$\\s]'\n",
" outcome=re.sub(regx,'',info)\n",
" return outcome\n",
"#针对评论数据删除特殊字符\n",
"data['review']=data['review'].apply(regex_character_remove)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"_uuid": "2295f2946e0ab74c220ad538d0e7adc04d23f697"
},
"outputs": [],
"source": [
"#分词\n",
"def stem(info):\n",
" ps=nltk.porter.PorterStemmer()\n",
" outcome= ' '.join([ps.stem(k) for k in info.split()])\n",
" return outcome\n",
"data['review']=data['review'].apply(stem)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"_uuid": "5dbff82b4d2d188d8777b273a75d8ac714d38885"
},
"outputs": [],
"source": [
"#删除停用词\n",
"stopwords=set(stopwords.words('english'))\n",
"tokenizer=ToktokTokenizer()\n",
"\n",
"def remove_stopwords(info, is_lower_case=False):\n",
" tks = tokenizer.tokenize(info)\n",
" tks = [tk.strip() for tk in tks]\n",
" if is_lower_case:\n",
" ftk = [tk for tk in tks if tk not in stopwords]\n",
" else:\n",
" ftk = [tk for tk in tks if tk.lower() not in stopwords]\n",
" filter_info = ' '.join(ftk) \n",
" return filter_info\n",
"\n",
"data['review']=data['review'].apply(remove_stopwords)"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"_kg_hide-output": true,
"_uuid": "b20c242bd091929ca896ea2c6e936ca00efe6ecf"
},
"outputs": [],
"source": [
"\n",
"n_train_reviews=data.review[:45000]\n",
"n_test_reviews=data.review[45000:]\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"_uuid": "1c2a872ffcb6b8076fdbbba641af12081b6022ef"
},
"source": [
"**Bags of words model **\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"_uuid": "35cf9dcefb40b2dc520c5b0d559695324c46cc04"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"词袋模型训练数据: (45000, 6813632)\n",
"词袋模型测试数据: (5000, 6813632)\n"
]
}
],
"source": [
"#词袋模型向量化\n",
"cvr=CountVectorizer(min_df=0,max_df=1,binary=False,ngram_range=(1,3))\n",
"cvr_train_reviews=cvr.fit_transform(n_train_reviews)\n",
"cvr_test_reviews=cvr.transform(n_test_reviews)\n",
"\n",
"print('词袋模型训练数据:',cvr_train_reviews.shape)\n",
"print('词袋模型测试数据:',cvr_test_reviews.shape)\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"_uuid": "52371868f05ff9cf157280c5acf0f5bc71ee176d"
},
"source": [
"**Term Frequency-Inverse Document Frequency model (TFIDF)**\n"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"_uuid": "afe6de957339921e05a6faeaf731f2272fd31946",
"scrolled": false
},
"outputs": [],
"source": [
"#TF-IDF向量化\n",
"td=TfidfVectorizer(min_df=0,max_df=1,use_idf=True,ngram_range=(1,3))\n",
"td_train_reviews=td.fit_transform(n_train_reviews)\n",
"td_test_reviews=td.transform(n_test_reviews)\n"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"_uuid": "60f5d496ce4109d1cdbf08f4284d4d26efd93922"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(50000, 1)\n"
]
}
],
"source": [
"#标注情感数据\n",
"lb=LabelBinarizer()\n",
"sm_data=lb.fit_transform(data['sentiment'])\n",
"print(sm_data.shape)"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"_kg_hide-output": true,
"_uuid": "ca1e4cc917265ac98a72c37cffe57f27e9897408"
},
"outputs": [],
"source": [
"#分割电影评论数据\n",
"train_sm=sm_data[:45000]\n",
"test_sm=sm_data[45000:]\n"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"_uuid": "142d007421900550079a12ae8655bcae678ebaad"
},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"c:\\users\\ichiro\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\sklearn\\utils\\validation.py:578: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().\n",
" y = column_or_1d(y, warn=True)\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"LogisticRegression(C=1, class_weight=None, dual=False, fit_intercept=True,\n",
" intercept_scaling=1, max_iter=500, multi_class='ovr', n_jobs=1,\n",
" penalty='l2', random_state=42, solver='liblinear', tol=0.0001,\n",
" verbose=0, warm_start=False)\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"c:\\users\\ichiro\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\sklearn\\utils\\validation.py:578: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().\n",
" y = column_or_1d(y, warn=True)\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"LogisticRegression(C=1, class_weight=None, dual=False, fit_intercept=True,\n",
" intercept_scaling=1, max_iter=500, multi_class='ovr', n_jobs=1,\n",
" penalty='l2', random_state=42, solver='liblinear', tol=0.0001,\n",
" verbose=0, warm_start=False)\n"
]
}
],
"source": [
"#使用逻辑回归模型\n",
"lr=LogisticRegression(penalty='l2',max_iter=500,C=1,random_state=42)\n",
"#基于词袋模型拟合\n",
"lr_fit=lr.fit(cvr_train_reviews,train_sm)\n",
"print(lr_fit)\n",
"#基于TF-IDF模型拟合\n",
"lr_tfidf=lr.fit(td_train_reviews,train_sm)\n",
"print(lr_tfidf)\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"<seaborn.axisgrid.FacetGrid at 0x1fdb01eda20>"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAWAAAAFgCAYAAACFYaNMAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjMuNCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8QVMy6AAAACXBIWXMAAAsTAAALEwEAmpwYAAAczUlEQVR4nO3df5RfdX3n8eebmcyAiZWgMUuBc4ia7S7dsyIbEbW2VleItKfoOUrDcSWwaGqFVotrD+hu7Y/1nNpWKa6CRklFjwXRak0tiiki6qpIUOSnyPhrSQ4kUfyRGZqkmbz3j+/nG74MM5kf+d7vZ74zz8c53zP3fu693+97bmZeufO5935uZCaSpN47onYBkrRYGcCSVIkBLEmVGMCSVIkBLEmVDNYuoAlr167Nz33uc7XLkKS2mKxxQR4B//jHP65dgiRNa0EGsCT1AwNYkioxgCWpEgNYkioxgCWpEgNYkioxgCWpEgNYkioxgCWpEgNYkioxgCWpEgNYkioxgOcoMxkdHcVn6kmaKwN4jsbGxlh3+WcZGxurXYqkPmUAH4aBoaNqlyCpjxnAklRJYwEcEUdGxDci4tsRcXdE/FlpXxURt0TESER8LCKGSvtwmR8py0/seK9LS/t9EXFGUzVLUi81eQS8F3hRZj4TOBlYGxGnAe8ALsvMZwA/BS4o618A/LS0X1bWIyJOAtYBvwqsBa6IiIEG65aknmgsgLNltMwuKa8EXgR8orRfDbysTJ9V5inLXxwRUdqvzcy9mfkDYAQ4tam6JalXGu0DjoiBiLgd2AlsAb4H/Cwz95dVtgHHlenjgAcAyvKfA0/ubJ9km87P2hARWyNi665duxr4biSpuxoN4Mwcz8yTgeNpHbX+hwY/a2NmrsnMNStWrGjqYySpa3pyFURm/gy4CXgucHREDJZFxwPby/R24ASAsvxJwE862yfZRpL6VpNXQayIiKPL9FHAS4B7aQXxK8pq64FPl+nNZZ6y/AvZus1sM7CuXCWxClgNfKOpuiWpVwanX2XOjgWuLlcsHAFcl5mfiYh7gGsj4n8D3wKuKutfBXwkIkaAh2ld+UBm3h0R1wH3APuBCzNzvMG6JaknGgvgzLwDeNYk7d9nkqsYMnMP8Mop3uvtwNu7XaMk1eSdcJJUiQE8B+2R0CTpcBjAczA2NsZ5V2zhwLhd0ZLmzgCeo4GhI2uXIKnPGcCSVIkBLEmVGMCSVIkBLEmVGMCSVIkBLEmVGMCSVIkBLEmVGMCSVIkBLEmVGMCSVIkBLEmVGMCSVIkBLEmVGMCSVIkBLEmVGMCSVIkBfBj27/1Xnw0nac4MYEmqxACWpEoMYEmqxACWpEoMYEmqxACWpEoMYEmqxACWpEoMYEmqxACWpEoMYEmqxACWpEoMYEmqxACWpEoMYEmqxACWpEoaC+CIOCEiboqIeyLi7oh4Q2n/04jYHhG3l9eZHdtcGhEjEXFfRJzR0b62tI1ExCVN1SxJvTTY4HvvB96Umd+MiCcCt0XElrLsssz8m86VI+IkYB3wq8AvA/8SEf++LH4v8BJgG3BrRGzOzHsarF2SGtdYAGfmg8CDZXp3RNwLHHeITc4Crs3MvcAPImIEOLUsG8nM7wNExLVlXQNYUl/rSR9wRJwIPAu4pTRdFBF3RMSmiFhe2o4DHujYbFtpm6pdkvpa4wEcEcuAfwDemJm/AK4Eng6cTOsI+Z1d+pwNEbE1Irbu2rWrG28pSY1qNIAjYgmt8P1oZn4SIDN3ZOZ4Zh4APsCj3QzbgRM6Nj++tE3V/hiZuTEz12TmmhUrVnT/m5GkLmvyKogArgLuzcx3dbQf27Hay4G7yvRmYF1EDEfEKmA18A3gVmB1RKyKiCFaJ+o2N1W3JPVKk1dBPB94NXBnRNxe2t4CnBMRJwMJ/BD4PYDMvDsirqN1cm0/cGFmjgNExEXADcAAsCkz726wbknqiSavgvgKEJMsuv4Q27wdePsk7dcfajtJ6kfeCSdJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJASxJlRjAklSJATxLmcno6Ojj5jOzYlWS+pEBPEtjY2Ocd8UWDoyPA/DII4+w7vLPMjY2VrkySf3GAJ6DgaEjJ8wfVakSSf3MAJakSgxgSarEAJakSgxgSarEAJakSgxgSaqksQCOiBMi4qaIuCci7o6IN5T2YyJiS0TcX74uL+0REe+OiJGIuCMiTul4r/Vl/fsjYn1TNUtSLzV5BLwfeFNmngScBlwYEScBlwA3ZuZq4MYyD/BSYHV5bQCuhFZgA28DngOcCrytHdqS1M8aC+DMfDAzv1mmdwP3AscBZwFXl9WuBl5Wps8CPpwtXweOjohjgTOALZn5cGb+FNgCrG2qbknqlZ70AUfEicCzgFuAlZn5YFn0ELCyTB8HPNCx2bbSNlX7xM/YEBFbI2Lrrl27uvsNSFIDGg/giFgG/APwxsz8ReeybI1g05VRbDJzY2auycw1K1as6MZbSlKjGg3giFhCK3w/mpmfLM07StcC5evO0r4dOKFj8+NL21TtktTXmrwKIoCrgHsz810dizYD7SsZ1gOf7mg/t1wNcRrw89JVcQNwekQsLyffTi9tktTXBht87+cDrwbujIjbS9tbgL8ErouIC4AfAWeXZdcDZwIjwCPA+QCZ+XBE/AVwa1nvzzPz4QbrlqSeaCyAM/MrQEyx+MWTrJ/AhVO81yZgU/eqk6T6vBNOkioxgLvAxxJJmgsDuAvG9+3h/I03+1giSbNiAHfJ4ITHFEnSdAxgSarEAJakSgxgSarEAJakSgzgw5CZXvkgac4M4MMwvm8vb7xmKwfGx2uXIqkPGcCHaXBouHYJkvqUASxJlRjAklSJASxJlRjAklSJAdwljogmabYM4C5xRDRJs2UAd5EjokmaDQNYkioxgCWpkhkFcEQ8fyZtkqSZm+kR8P+ZYZskaYYO+Vj6iHgu8DxgRURc3LHol4CBJguTpIXukAEMDAHLynpP7Gj/BfCKpoqSpMXgkAGcmTcDN0fEhzLzRz2qSZIWhemOgNuGI2IjcGLnNpn5oiaKkqTFYKYB/HHgfcAHAUcfl6QumGkA78/MKxutRJIWmZlehvZPEfH6iDg2Io5pvxqtTJIWuJkeAa8vX9/c0ZbA07pbjiQtHjMK4Mxc1XQhkrTYzCiAI+Lcydoz88PdLUeSFo+ZdkE8u2P6SODFwDcBA7hDe1D2pUuXEhG1y5E0z820C+IPOucj4mjg2iYK6mftQdk/fvFvsWzZstrlSJrn5joc5Rhgv/AkHJRd0kzNtA/4n2hd9QCtQXj+I3BdU0VJ0mIw0z7gv+mY3g/8KDO3NVCPJC0aM+qCKIPyfIfWiGjLgX1NFiVJi8FMn4hxNvAN4JXA2cAtEeFwlJJ0GGZ6Eu6twLMzc31mngucCvyvQ20QEZsiYmdE3NXR9qcRsT0ibi+vMzuWXRoRIxFxX0Sc0dG+trSNRMQls/v2JGn+mmkAH5GZOzvmfzKDbT8ErJ2k/bLMPLm8rgeIiJOAdcCvlm2uiIiBiBgA3gu8FDgJOKesK0l9b6Yn4T4XETcA15T53wWuP9QGmfmliDhxhu9/FnBtZu4FfhARI7SOsgFGMvP7ABFxbVn3nhm+ryTNW4c8io2IZ0TE8zPzzcD7gf9cXl8DNs7xMy+KiDtKF8Xy0nYc8EDHOttK21Ttk9W6ISK2RsTWXbt2zbE0Seqd6boR/pbW89/IzE9m5sWZeTHwqbJstq4Eng6cDDwIvHMO7zGpzNyYmWsyc82KFSu69baS1JjpuiBWZuadExsz885ZdC90brejPR0RHwA+U2a3Ayd0rHp8aeMQ7ZLU16Y7Aj76EMuOmu2HRcSxHbMvB9pXSGwG1kXEcESsAlbTuuztVmB1RKyKiCFaJ+o2z/ZzJWk+mu4IeGtEvDYzP9DZGBGvAW471IYRcQ3wQuApEbENeBvwwog4mdZtzT8Efg8gM++OiOtonVzbD1yYmePlfS4CbqB1C/SmzLx7Nt+gJM1X0wXwG4FPRcSreDRw1wBDtI5gp5SZ50zSfNUh1n878PZJ2q9nmisuJKkfHTKAS5/t8yLiN4H/VJr/OTO/0HhlkrTAzXQ84JuAmxquRZIWlbmOByxJOkwGsCRVYgBLUiUGsCRVYgBLUiUGcJe1H02fmdOvLGlRM4C7rP1o+rGxsdqlSJrnDOAG+Gh6STNhAEtSJQawJFViAEtSJQawJFViAEtSJQawJFViAEtSJQawJFViAEtSJQawJFViAEtSJQZwAxwRTdJMGMANcEQ0STNhADfEEdEkTccAlqRKDGBJqsQAlqRKDGBJqsQAlqRKDGBJqsQAlqRKDGBJqsQAlqRKDGBJqsQAbogD8kiajgHcEAfkkTQdA7hBDsgj6VAM4FlodytMZ//ePYwfGO9BRZL6mQE8C2NjY5x3xRYOjBuukg5fYwEcEZsiYmdE3NXRdkxEbImI+8vX5aU9IuLdETESEXdExCkd26wv698fEeubqnemBmbRreCJOEmH0uQR8IeAtRPaLgFuzMzVwI1lHuClwOry2gBcCa3ABt4GPAc4FXhbO7T7gSfiJB1KYwGcmV8CHp7QfBZwdZm+GnhZR/uHs+XrwNERcSxwBrAlMx/OzJ8CW3h8qM9rnoiTNJVe9wGvzMwHy/RDwMoyfRzwQMd620rbVO2PExEbImJrRGzdtWtXd6uWpAZUOwmXrY7RrnWOZubGzFyTmWtWrFjRrbeVpMb0OoB3lK4FytedpX07cELHeseXtqnaJanv9TqANwPtKxnWA5/uaD+3XA1xGvDz0lVxA3B6RCwvJ99OL22S1PcGm3rjiLgGeCHwlIjYRutqhr8ErouIC4AfAWeX1a8HzgRGgEeA8wEy8+GI+Avg1rLen2fmxBN7ktSXGgvgzDxnikUvnmTdBC6c4n02AZu6WJokzQveCTdDM70NWZJmygCeIW9DltRtBvAhTLyVeDa3IUvSdAzgQxgbG2Pd5Z89rFuJHQ9C0lQM4GkMDB11WNs7HoSkqRjAPeB4EJImYwBLUiUGcA/YDyxpMgbwNLoRnvYDS5qMATyN8X17OO/9X2Tnzp3Tr3wI9gNLmsgAnoEAXrfpK96EIamrDOAZGhwarl2CpAXGAJakSgxgSarEAJ6B/Xv3MH7A/l9J3WUAS1IlBrAkVWIA94h3w0mayADuEe+GkzSRAdxD3g0nqZMBLEmVGMA9ZD+wpE4GcA/ZDyypkwHcY/YDS2ozgCWpEgN4Cu3+WklqigE8hbGxMc67YotjAEtqjAF8CAP210pqkAHcY5nJ7t272b17t5ejSYucAdxj4/v2cO57Ps/Zl13v5WjSImcAT6LpE3CDQ8NejibJAJ6MJ+Ak9YIBPAVPwElqmgHcIz7WSNJEBrAkVWIAS1IlBrAkVWIAV5SZPPTQQ+zevbt2KZIqMIAral/u5g0Z0uJUJYAj4ocRcWdE3B4RW0vbMRGxJSLuL1+Xl/aIiHdHxEhE3BERp9SouSle7iYtXjWPgH8zM0/OzDVl/hLgxsxcDdxY5gFeCqwurw3AlT2vtAGZ6ZGvtMjNpy6Is4Cry/TVwMs62j+cLV8Hjo6IYyvU11Xj+/bwuk1fYXz/fsbGxhyYR1qEagVwAp+PiNsiYkNpW5mZD5bph4CVZfo44IGObbeVtseIiA0RsTUitu7ataupurtqcGiY8X17+f0P3+LRsLQIDVb63F/LzO0R8VRgS0R8p3NhZmZEzOqQMDM3AhsB1qxZ01eHk4PD9gNLi1GVI+DM3F6+7gQ+BZwK7Gh3LZSvO8vq24ETOjY/vrQtGI4RLC1OPQ/giFgaEU9sTwOnA3cBm4H1ZbX1wKfL9Gbg3HI1xGnAzzu6KhYExwiWFqcaXRArgU9FRPvz/z4zPxcRtwLXRcQFwI+As8v61wNnAiPAI8D5vS+5eY4RLC0+PQ/gzPw+8MxJ2n8CvHiS9gQu7EFpktRT8+kyNElaVAzgeaj9SCRPyEkLmwE8z2QmO3bsYN3ln/WEnLTAGcDzTHuAnhgYql2KpIYZwPOQA/RIi4MBLEmVGMDz1P69/8ro6GjtMiQ1yACep9rDVXolhLRwGcDzlKOkSQufATyPOUqatLAZwH3AGzOkhckAnsfawTs6OuqNGdICZADPIxOfEze+bw/nb7yZsbExBoaOqliZpCYYwPNI+zlxB8bHD7Y5RKW0cBnA88zg0HDtEiT1iAE8z/n4emnhMoDnuc7H1/vcOGlhqfVU5HmrfeXBfNJ6fH3ruXGDw0dy3R+dSUSwdOlSyqOdJPUhj4AnaA8H2XkibL5oPzdubGyM3/3b69mxY4dHw1IfM4An0R/DQcbBS9Qk9ScDuM/s3/uvB0N3YMmw/cJSHzOA+1i7X/jsy673SFjqQwZwn5l4WVq7X1hS//EqiD4zvm8vb7xmK8NHPuFgW2aye/duDhw4QESwbNkyr46Q+oAB3Icm3i3X7oqA1hCWH7/4t1i2bFmN0iTNgl0QC0SrK6LVHeHwlVJ/MIAXmMxk586dDl8p9QEDeIFp37rMEUsOHgV7RCzNTwbwArF/7x7GD7Tu3mvfunz+xpvZsWMHO3bs8IhYmoc8CbeADSwZPjiuhQO6S/OPAbyAje/bw2vffyMxuIQn/NIxjI6OsnTpUqA15oWD+Uh12QWxwA0uGX5Ml8To6OjBLon28+bsG5bqMIAXkfZIauddsQWOWOLVElJldkEsIu3bmAeGjmTv7p/x2g/ezNInPfngnXSZ6Z10Ug8ZwB3m42Ds3dS+RK19J93g0PDB64YvvPqrjI8fOHgn3dKlS+0nlhpmF0SH+TwYe7dMdhvz6zZ9hRhYwuDQ8MEhLh966KHHDPrePkp26EupezwCnmBg6MgFHcCTaYdy+1rig+NKDA1z3vu/yHtetQaAiz78NRhYwt9t+I2DR8ZLly7lkUce8UhZmgMDWI/TeZQccPBStvYIbO2Azkzete4ULt38HT54wQseE8rtE3v2J0tTM4A1rcElw8SSJY/Odxwxt4fGbIfywNAwf/Xyk3jTx77FwNDwwaPlQxkdHSUiWLlypcGtRaVvAjgi1gKXAwPABzPzL7v9GaOjo4uu++FwdZ7Qa3vDR77GkicsI3j0aBlg/749xOASBo4YeMx77N+3h8GjlvG+9adx4dVffUw3B2BXhxasvgjgiBgA3gu8BNgG3BoRmzPznm59xsQnTWjuBpc8GsaPOemXSSx5fACTSQSPuULj3Pd8/mBgDx35BN77357NH15zG1e95td56lOfytjY2CEvm2v/exrYms/6IoCBU4GRzPw+QERcC5wFdC2Ax8bGuOC913PE8NLHH6H9214iD5CH0d6N92i6vXYtA0cMsH/fXiYa37eX17xvC4NDR3HOO/+Ry1/9PC7++1sYHx9ncOhIPvIHax83AP3o6CjnXbGFD73+JQ5Or67p9s9S9MMlRRHxCmBtZr6mzL8aeE5mXtSxzgZgQ5n9FeC+WX7MU4Afd6HcbplP9VjL1OZTPfOpFphf9dSu5ceZuXZiY78cAU8rMzcCG+e6fURszcw1XSzpsMyneqxlavOpnvlUC8yveuZTLZ365UaM7cAJHfPHlzZJ6lv9EsC3AqsjYlVEDAHrgM2Va5Kkw9IXXRCZuT8iLgJuoHUZ2qbMvLvLHzPn7ouGzKd6rGVq86me+VQLzK965lMtB/XFSThJWoj6pQtCkhYcA1iSKjGAad3mHBH3RcRIRFzSg887ISJuioh7IuLuiHhDaT8mIrZExP3l6/LSHhHx7lLfHRFxSgM1DUTEtyLiM2V+VUTcUj7zY+XkJxExXOZHyvITG6jl6Ij4RER8JyLujYjn1to3EfFH5d/oroi4JiKO7OW+iYhNEbEzIu7qaJv1voiI9WX9+yNifRdr+evy73RHRHwqIo7uWHZpqeW+iDijo70rv2+T1dOx7E0RkRHxlDLf6L6Zs/ZYr4v1Reuk3veApwFDwLeBkxr+zGOBU8r0E4HvAicBfwVcUtovAd5Rps8EPktrcLLTgFsaqOli4O+Bz5T564B1Zfp9wO+X6dcD7yvT64CPNVDL1cBryvQQcHSNfQMcB/wAOKpjn5zXy30D/DpwCnBXR9us9gVwDPD98nV5mV7epVpOBwbL9Ds6ajmp/C4NA6vK79hAN3/fJquntJ9A64T9j4Cn9GLfzPnft1cfNF9fwHOBGzrmLwUu7XENn6Y1zsV9wLGl7VjgvjL9fuCcjvUPrtelzz8euBF4EfCZ8kP6445frIP7qPxgP7dMD5b1oou1PKmEXkxo7/m+oRXAD5RfzsGyb87o9b4BTpwQerPaF8A5wPs72h+z3uHUMmHZy4GPlunH/B619023f98mqwf4BPBM4Ic8GsCN75u5vOyCePSXrG1baeuJ8mfqs4BbgJWZ+WBZ9BCwskc1/i3wx8CBMv9k4GeZuX+SzztYS1n+87J+t6wCdgF/V7pEPhgRS6mwbzJzO/A3wP8DHqT1vd5GvX3TNtt90auf8f9O6yizWi0RcRawPTO/PWFR7X0zKQO4oohYBvwD8MbM/EXnsmz9d9z4NYIR8dvAzsy8renPmqFBWn9WXpmZzwLGaP2ZfVAP981yWoM+rQJ+GVgKPO5+/pp6tS+mExFvBfYDH61YwxOAtwB/UquG2TKAK93mHBFLaIXvRzPzk6V5R0QcW5YfC+zsQY3PB34nIn4IXEurG+Jy4OiIaN+o0/l5B2spy58E/KRLtUDrCGRbZt5S5j9BK5Br7Jv/CvwgM3dl5r8Bn6S1v2rtm7bZ7otGf8Yj4jzgt4FXlf8QatXydFr/WX67/DwfD3wzIv5dpXqmZQBXuM05IgK4Crg3M9/VsWgz0D4Lu55W33C7/dxyJvc04Ocdf4Ielsy8NDOPz8wTaX3vX8jMVwE3Aa+YopZ2ja8o63ftCCwzHwIeiIhfKU0vpjXsaM/3Da2uh9Mi4gnl36xdS5V902G2++IG4PSIWF6O6k8vbYctWg9K+GPgdzLzkQk1ritXhqwCVgPfoMHft8y8MzOfmpknlp/nbbROdj9EhX0z06IX/YvWGdLv0jo7+9YefN6v0fqz8Q7g9vI6k1Z/4Y3A/cC/AMeU9YPWgPTfA+4E1jRU1wt59CqIp9H6hRkBPg4Ml/Yjy/xIWf60Buo4Gdha9s8/0jo7XWXfAH8GfAe4C/gIrbP6Pds3wDW0+p//jVagXDCXfUGrf3akvM7vYi0jtPpQ2z/H7+tY/62llvuAl3b7922yeiYs/yGPnoRrdN/M9eWtyJJUiV0QklSJASxJlRjAklSJASxJlRjAklSJASzNQUScFxHvqV2H+psBLM1ARAzUrkELjwGsBS8i3hwRf1imL4uIL5TpF0XERyPinIi4M1pj/r6jY7vRiHhnRHwbeG5EnB8R342Ib9C6Jbm93ivLtt+OiC/1+vtT/zKAtRh8GXhBmV4DLCtjcbyA1h1Z76A1BsbJwLMj4mVl3aW0xo19Jq07qP6MVvD+Gq3xbtv+BDijrPc7jX4nWlAMYC0GtwH/JSJ+CdgLfI1WEL8A+BnwxWwNuNMezevXy3bjtAZMAnhOx3r7gI91vP//BT4UEa+lNeC4NCMGsBa8bI1k9gNaT7P4Kq0j4t8EnkFrvICp7MnM8Rm8/+uA/0lrVK3bIqKJMYC1ABnAWiy+DPwP4Etl+nXAt2gNmvMbEfGUcqLtHODmSba/paz35NJ98cr2goh4embekpl/Qmsw+RMm2V56nMHpV5EWhC/TGp3ra5k5FhF7gC9n5oPlwZA30Rox658z89MTNy7r/Smt7ouf0Rr5q+2vI2J12f5GWs85k6blaGiSVIldEJJUiQEsSZUYwJJUiQEsSZUYwJJUiQEsSZUYwJJUyf8Hl/42sRZtj6IAAAAASUVORK5CYII=\n",
"text/plain": [
"<Figure size 360x360 with 1 Axes>"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"\n",
"data['words'] = data['review'].apply(lambda y: len(y.split()))\n",
"sns.displot(data=data, x=\"words\")"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"_uuid": "52ad86935b76117f97b79e6672a3ba12352b9461"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1 1 0 ... 0 1 1]\n",
"[1 1 0 ... 0 1 1]\n"
]
}
],
"source": [
"#词袋模型预测\n",
"bow_pred=lr.predict(cvr_test_reviews)\n",
"print(bow_pred)\n",
"##TF-IDF模型预测\n",
"tfidf_pred=lr.predict(td_test_reviews)\n",
"print(tfidf_pred)"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"词袋模型准确性: 0.7612\n",
"TF-IDF模型准确性: 0.7608\n"
]
}
],
"source": [
"#模型准确性评估\n",
"bow_score=accuracy_score(test_sm,bow_pred)\n",
"tfidf_score=accuracy_score(test_sm,tfidf_pred)\n",
"print(\"词袋模型准确性:\",bow_score)\n",
"print(\"TF-IDF模型准确性:\",tfidf_score)"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"词袋模型:\n",
" precision recall f1-score support\n",
"\n",
" Positive 0.766 0.761 0.763 2530\n",
" Negative 0.757 0.762 0.759 2470\n",
"\n",
"avg / total 0.761 0.761 0.761 5000\n",
"\n",
"TD-IDF模型:\n",
" precision recall f1-score support\n",
"\n",
" Positive 0.764 0.763 0.764 2530\n",
" Negative 0.758 0.758 0.758 2470\n",
"\n",
"avg / total 0.761 0.761 0.761 5000\n",
"\n"
]
}
],
"source": [
"#分类报告 \n",
"bow_report=classification_report(test_sm,bow_pred,digits=3, labels=None,sample_weight=None,target_names=['Positive','Negative'])\n",
"tfidf_report=classification_report(test_sm,tfidf_pred,digits=3, labels=None, sample_weight=None,target_names=['Positive','Negative'])\n",
"print('词袋模型:\\n',bow_report)\n",
"print('TD-IDF模型:\\n',tfidf_report)"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'0.19.2'"
]
},
"execution_count": 18,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"import sklearn\n",
"sklearn.__version__"
]
},
{
"cell_type": "markdown",
"metadata": {
"_uuid": "ac2ec8353acb5e0f548e1e4a590fbe6f34f4a686"
},
"source": [
"**Print the classification report**"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.5"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
创作不易 觉得有帮助请点赞关注收藏~~~