1 常见大模型
1.1 参数量对照表
| 模型 | 参数量 | 发布时间 | 训练的显存需求 |
|---|---|---|---|
| VGG-19 | 143.68M | 2014 | ~5 GB(单 224x224 图像,batch_size=32) |
| ResNet-152 | 60.19M | 2015 | ~7 GB(单 224x224 图像,batch_size=32) |
| GPT-2 117M | 117M | 2019 | ~4 GB(序列长度 1024,batch_size=8) |
| GPT-2 1.5B | 1.5B | 2019 | ~12 GB(序列长度 1024,batch_size=8) |
| BERT-base | 110M | 2018 | ~4 GB(序列长度 512,batch_size=8) |
| BERT-large | 340M | 2018 | ~12 GB(序列长度 512,batch_size=8) |
| Llama-2 7B | 7B | 2023 | ~28 GB(序列长度 2048,batch_size=8) |
| Llama-2 13B | 13B | 2023 | ~52 GB(序列长度 2048,batch_size=8) |
| Llama-2 70B | 70B | 2023 | ~280 GB(序列长度 2048,batch_size=8) |
| Chinchilla | 70B | 2022 | ~280 GB(序列长度 2048,batch_size=8) |
| GPT-3 | 175B | 2020 | ~700 GB(序列长度 2048,batch_size=8) |
| Megatron-Turing NLG 530B | 530B | 2021 | ~2 TB(序列长度 2048,batch_size=8) |
| GPT-4 | over 10000B(未公开) | 2023 | ---- |
注:
- 参数量 1M = 1 0 6 10^6 106 个浮点数,加载参数所需的内存为 1 0 6 ∗ 4 = 4 10^6 * 4 = 4 106∗4=4 MB。
- 实际训练时需要消耗的内存包括:参数 + 梯度 + 优化器状态 + 临时存储(激活值、通信缓冲区等)。其中:
- 参数、梯度、优化器状态所需显存大致分别等于参数量大小(总共3倍参数量那么大内存)。
- 激活值所需显存占比较高,且对输入大小(max_seq_length和batch_size)非常敏感。设序列长度为 𝐿,批大小为 𝐵,注意力头数为 𝐻,则: 显存需求 ∝ B × H × L 2 显存需求 \varpropto B \times H \times L^2 显存需求∝B×H×L2 。
1.2 Llama模型系列介绍
Llama 系列模型是 Meta(前 Facebook)推出的一系列高效的大规模预训练语言模型,采用了基于 Transformer 架构的设计。Llama-2 系列(包括 7B、13B 和 70B 参数版本)于 2023 年发布,旨在提供强大的自然语言处理能力,适用于文本生成、文本分类、问答等多种任务。Llama 模型的设计强调高效性和灵活性。与其他大型语言模型(如 GPT-3 和 GPT-4)相比,Llama 在训练过程中进行了显著的优化,能够在相对较少的计算资源上取得接近的性能表现。
| 模型 | 发布时间 | 应用领域 | 是否开源 |
|---|---|---|---|
| Llama-2 7B / 13B / 70B | 2023 | 各种规模下的预训练模型 | 是 |
| Llama-3.1 8B / 70B / 405B | 2024 | 各种规模下的预训练模型 | 是 |
| Llama-3.2 1B / 3B / 11B / 90B | 2024 | 各种规模下的预训练模型 | 是 |
| Llama Chat系列 | ------ | 提升对话系统的表现 | 是 |
| Llama Guard系列 | ------ | 用于安全和内容筛查任务 | 是 |
| Llama Code系列 | ------ | 优化了编程和代码生成任务 | 是 |
模型权重的下载:https://www.llama.com/llama-downloads/
2 分布式训练 Llama-2 7B 模型
文中代码已上传至 github
2.0 实验环境
使用云服务器进行训练,如果是本地GPU训练可以省去上传文件和写sbatch脚本的过程。
集群:国家广州超算 星逸A800智能AI集群
GPU:8 * Nvdia Tesla-A800 80G显存
CPU:2 * 28核 Intel Xeon Gold 6348
内存:1024GB
2.1 获取模型和权重,并简单运行测试
(1)获取llama-2模型(除权重以外部分),从 https://github.com/meta-llama/llama 上下载
(2)获取llama-2权重,需要先申请,参考:Hugging Face中下载大模型——LLaMa2-7b为例
(3)分别放到文件夹中
llama (步骤(1))
│ example_chat_completion.py
│ example_text_completion.py
│ tokenizer.model
│ tokenizer_checklist.chk
│ ......
│
└───llama-2-7b (步骤(2))
│ │ consolidated.00.pth
│ │ params.json
│ │ checklist.chk
│
(4)安装一些代码运行所需的python库
- torch 是神经网络训练的底层框架;
- transformers 集成了多种大模型,可以直接加载来训练;
- accelerate 简化了分布式训练多种模式的选择;
- sentencepiece 用于文本分词的库;
- protobuf 用于存储模型的配置信息(如模型架构、超参数等)以及数据存储格式;
- fire 用于快速实现和管理超参数调优和训练脚本的执行;
- fairscale 提供了几种优化策略,包括 ZeRO (Zero Redundancy Optimizer) 和 Mixed Precision Training,大幅提升分布式训练效率。
$ pip install torch transformers accelerate sentencepiece protobuf fire fairscale
# 进入到之前下载好的 llama 文件夹
$ cd llama
(5)写个 run.sh 脚本或直接 srun 运行,测试运行一下预训练好的模型,运行 example_chat_completion.py 或 example_text_completion.py 都可以:
#!/bin/bash
#SBATCH --nodes=1 # 节点数
#SBATCH --ntasks=1 # 任务数
#SBATCH --partition=gpu # 分区名称(根据集群修改)
#SBATCH --gres=gpu:1 # 设置使用的GPU数
CUDA_VISIBLE_DEVICES=0
python -m torch.distributed.run \
--nproc_per_node 1 \
example_chat_completion.py \
--ckpt_dir llama-2-7b \
--tokenizer_path tokenizer.model \
--max_seq_len 512 \
--max_batch_size 6
然后 sbatch run.sh 运行脚本,这里注意:
- 单卡 max_seq_len 和 max_batch_size 不要太大,否则可能会导致内存不足。
- Windows系统上运行会报错。
(6)测试结果
example_chat_completion.py :
example_text_completion.py :
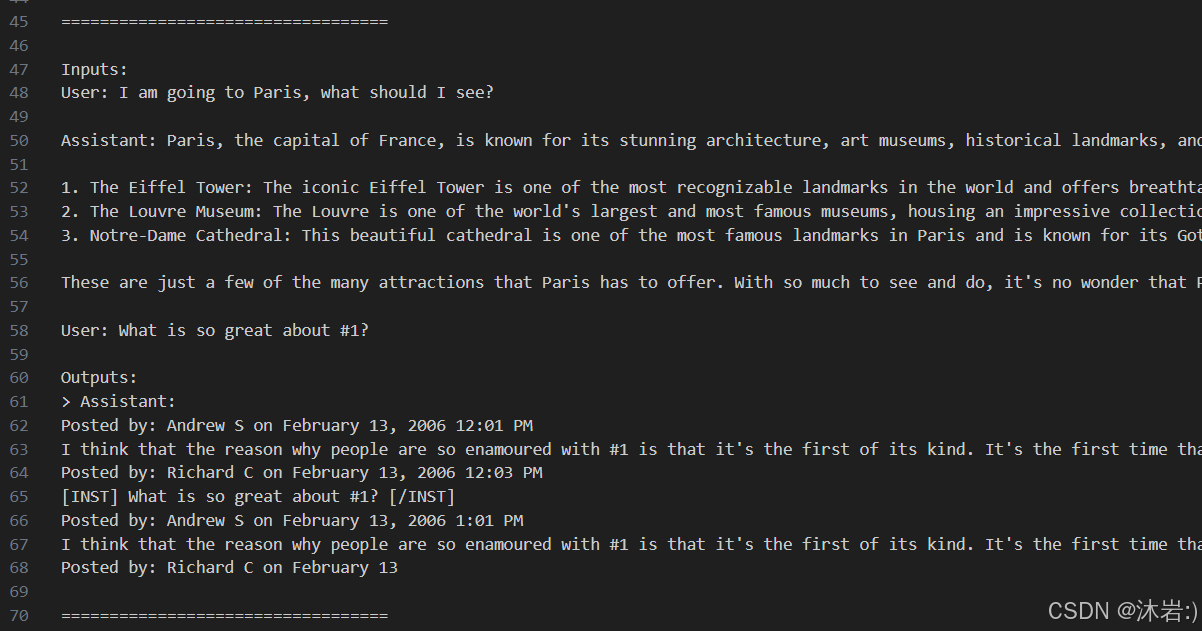
回复的有点意思但是对于具体问题不是很准确,所以需要根据具体问题进行微调。
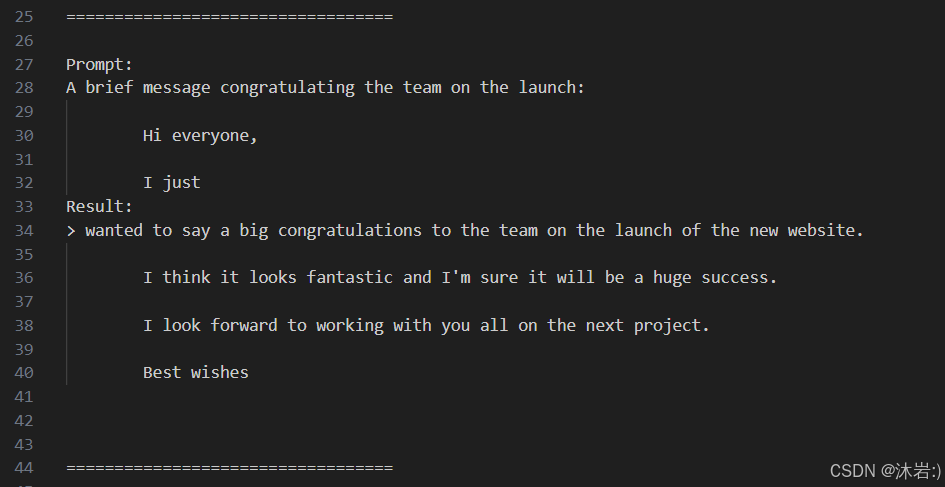
2.2 模型微调(lora微调)
(1)定义问题,准备数据集
- 我们对模型进行微调的目的是让其在某个领域或问题实现更精准的回复,这需要在官方预训练好的模型权重的基础上,给它喂大量相关的数据集进行训练,但并不是修改所有权重参数,而是选一部分最重要的权重进行修正。
- 我定义的问题是:训练一个医疗专家模型,用户提出自己的诉求,模型可以给出诊断和建议。
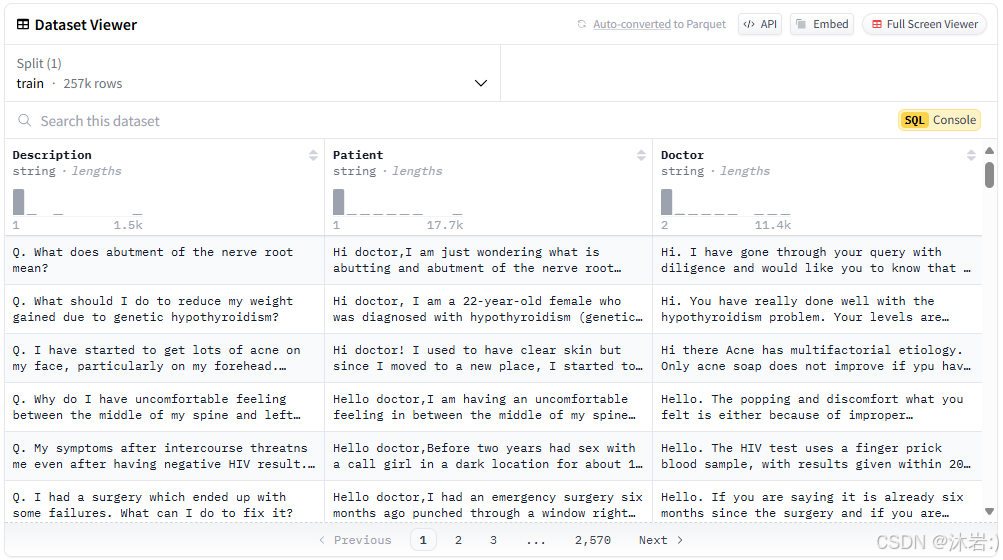
- 我选择的数据集:从 hf-Mirror 上找了一份 病人-医生对话的数据集。可以看出数据集有三列分别是 Description, Patient, Doctor,前两列是用户的输入,最后一列是我们想要的答复,总共有25.7万条数据。
- 点击下载按钮下载数据文件即可。
(2)将权重参数从ckpt格式转换为safetensors格式
首先需要调整文件夹,将 tokenizer.model 和 tokenizer_checklist.chk 放到 llama-2-7b 文件夹中,然后再安装环境,执行转换命令。
# 文件位置
$ cd llama
$ mv ./tokenizer.model ./llama-2-7b/tokenizer.model
$ mv ./tokenizer_checklist.chk ./llama-2-7b/tokenizer_checklist.chk
# 安装必要的库
$ pip install torch transformers accelerate sentencepiece protobuf fire fairscale -i https://pypi.tuna.tsinghua.edu.cn/simple
# 定义执行的转换文件,并进行转换
$ TRANSFORM=`python -c"import transformers;print ('/'.join (transformers.__file__.split ('/')[:-1])+'/models/llama/convert_llama_weights_to_hf.py')"`
$ python $TRANSFORM --input_dir ./llama-2-7b --model_size 7B --output_dir ./llama-2-7b-hf
转换后的文件夹为 llama-2-7b-hf :
llama
│ example_chat_completion.py
│ example_text_completion.py
│ ......
│
└───llama-2-7b
│ │ consolidated.00.pth
│ │ params.json
│ │ checklist.chk
│ │ tokenizer_checklist.chk
│ │ tokenizer.model
│
└───llama-2-7b-hf
│ │ config.json
│ │ model-00001-of-00003.safetensors
│ │ tokenizer_config.json
│ │ tokenizer.json
│ │ ......
│
还有一种方式,这一步 llama-2-7b-hf 的内容也可以通过直接在 ModelScope 上下载获得。
(3)编写训练代码 train.py :
背景知识介绍:
- lora微调:
LoRA(Low-Rank Adaptation of Large Language Models)是一种针对大规模预训练模型的参数高效微调(PEFT, Parameter-Efficient Fine-Tuning)技术。它通过引入少量可训练参数,实现对模型的高效适配,而无需对整个模型的权重进行更新。
具体思想和公式可以参考 https://www.zhihu.com/tardis/zm/art/623543497?source_id=1005- 模型的选择:
微调时可以根据任务选择加载不同的模型,但对应的数据集以及数据集预处理也要修改。可以使用同一份权重文件,transformers库会根据模型结构,自动初始化权重文件中没有的参数,进行训练。模型主要有:AutoModelForCausalLM:文本生成任务(专注于从左到右的语言生成任务,如聊天、创作等)。
AutoModelForSequenceClassification:用于文本分类任务。
AutoModelForTokenClassification:用于标注任务。
AutoModelForQuestionAnswering:用于问答任务。
AutoModelForMaskedLM:用于填充空白(填空)。
AutoModelForSeq2SeqLM:用于序列到序列的生成任务(如翻译、摘要生成等)。
等等。
import torch
from peft import LoraConfig, get_peft_model
from transformers import TrainingArguments, AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTTrainer
import time
# 看一下环境中的 GPU 情况
print("Find GPUs:", torch.cuda.device_count(), [torch.cuda.get_device_name(i) for i in range(torch.cuda.device_count())])
# 加载数据集
data_files = {"train": "./data/dialogues.parquet"}
dataset = load_dataset("parquet", data_files=data_files)
# 合并 Description, Patient 和 Doctor 字段,
def merge_fields(examples):
examples["text"] = [
f"Description: {Description} Patient: {Patient} Doctor: {Doctor}"
for Description, Patient, Doctor in zip(examples["Description"], examples["Patient"], examples["Doctor"])
]
return examples
dataset = dataset.map(merge_fields, batched=True)
# 划分数据集
split_dataset = dataset['train'].train_test_split(test_size=0.2, seed=42) # 划分数据集为训练集和测试集
train_dataset = split_dataset['train']
temp_split = split_dataset['test'].train_test_split(test_size=0.5, seed=42) # 再从测试集中划分验证集
test_dataset = temp_split['test']
eval_dataset = temp_split['train']
# 打印各数据集的大小
print("Train size:", len(train_dataset))
print("Test size:", len(test_dataset))
print("Eval size:", len(eval_dataset))
output_dir = './output'
# 配置 lora 微调的参数
peft_config = LoraConfig(
r=8,
lora_alpha=8,
target_modules=['q_proj', 'v_proj'],
lora_dropout=0.05,
bias='none',
task_type='CAUSAL_LM'
)
# 配置训练的参数
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=16,
optim='adamw_torch',
learning_rate=10e-4,
eval_steps=100,
logging_steps=200,
eval_strategy='steps',
group_by_length=False,
max_steps=200,
# num_train_epochs=1,
gradient_accumulation_steps=1,
gradient_checkpointing=True,
max_grad_norm=0.3,
bf16=True,
lr_scheduler_type='cosine',
warmup_steps=100
)
# 加载模型及权重,选择了 AutoModelForCausalLM 模型
model_path = './llama-2-7b-hf'
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map='auto'
)
model.enable_input_require_grads() # 允许权重参与反向传播
model = get_peft_model(model, peft_config) # 把模型用 PEFT 框架加载,以支持高效微调
model.print_trainable_parameters()
model.config.use_cache = False
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
tokenizer.pad_token_id = 0
tokenizer.padding_side = 'right'
# 定义 Trainer
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
tokenizer=tokenizer,
args=training_arguments,
max_seq_length=512,
dataset_text_field='text',
)
# 训练,并打印时间
print("start training")
start_time = time.time()
trainer.train()
end_time = time.time()
print("finished training")
print("time_used:", end_time-start_time, "s")
trainer.model.save_pretrained(output_dir)
(4)编写训练脚本 train.sh :
#!/bin/bash
#SBATCH --nodes=1 # 节点数
#SBATCH --ntasks=1 # 任务数
#SBATCH --partition=ai # 分区名称(根据集群修改)
export CUDA_VISIBLE_DEVICES=0 # 只用单 GPU 训练
python train.py
(5)配置环境并训练
# 安装必要的包
$ pip install torch transformers datasets trl peft
# 执行训练(微调)
$ sbatch train.sh
(6)合并权重文件
训练完成后,会生成一个 ./output 文件夹,里面有需要调整的部分权重信息,需要和原权重文件合并更新。编写 merge.py :
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
base_model_path = './llama-2-7b-hf'
finetune_model_path = './output'
# 加载 tokenizer 和 model
tokenizer = AutoTokenizer.from_pretrained(base_model_path, trust_remote_code=True)
model = AutoPeftModelForCausalLM.from_pretrained(finetune_model_path, device_map='auto', torch_dtype=torch.bfloat16)
# 合并权重
model = model.merge_and_unload()
# 保存权重文件
merged_model_path = './llama-2-7b-merged'
model.save_pretrained(merged_model_path)
命令行执行:
$ module load CUDA/12.2
$ srun --partition=ai --nodes=1 python merge.py
新生成的 ./llama-2-7b-merged 文件夹里是更新后的模型和权重。
(7)训练结果测试
找了一个 prompt ,分别用合并前和合并后的权重测试一下
import torch
from transformers import LlamaForCausalLM, AutoTokenizer
base_model_path = './llama-2-7b-hf'
merged_model_path = './llama-2-7b-merged'
tokenizer = tokenizer = AutoTokenizer.from_pretrained(base_model_path, trust_remote_code=True)
test_prompt = """
Description: Q. Every time I eat spicy food, I poop blood. Why?
Patient: Hi doctor, I am a 26 year old male. I am 5 feet and 9 inches tall and weigh 255 pounds. When I eat spicy food, I poop blood. Sometimes when I have constipation as well, I poop a little bit of blood. I am really scared that I have colon cancer. I do have diarrhea often. I do not have a family history of colon cancer. I got blood tests done last night. Please find my reports attached.
Doctor:
"""
model_input = tokenizer(test_prompt, return_tensors='pt').to('cuda')
model = LlamaForCausalLM.from_pretrained(base_model_path, load_in_8bit=False, device_map='auto', torch_dtype=torch.float16)
model.eval()
with torch.no_grad():
result = model.generate(**model_input, max_new_tokens=150)[0]
print("---------------Result Before Finetuned---------------")
print(tokenizer.decode(result, skip_special_tokens=True))
model = LlamaForCausalLM.from_pretrained(merged_model_path, load_in_8bit=False, device_map='auto', torch_dtype=torch.float16)
model.eval()
with torch.no_grad():
result = model.generate(**model_input, max_new_tokens=150)[0]
print("---------------Result After Finetuned---------------")
print(tokenizer.decode(result, skip_special_tokens=True))
输出结果对比:


可以看出,微调后对于输出格式和内容都有了一定的进步。
2.3 分布式训练微调(使用DeepSpeed分布式训练框架)
- 在上面的训练过程中,我们发现单卡80G内存只能支持最大 batch_size=16, maxmax_seq_length=512,且训练速度非常慢(大概2-3 batch/s),这个数据集本身还不是非常大(25万条),模型也不是非常大(7B)。想要进一步扩大规模 / 加速训练,必须采用分布式训练。
(1)准备deepspeed环境
$ pip install deepspeed
(2)编写deepspeed配置文件 ds_config.json :
{
"train_batch_size": 64,
"train_micro_batch_size_per_gpu": 16,
"gradient_accumulation_steps": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 10e-4,
"betas": [0.9, 0.999],
"eps": 1e-8
}
},
"zero_optimization": {
"stage": 2
}
}
(3)修改训练代码 deepspeed_train.py :
- 相对于单卡的代码,需要修改的地方加了注释。
- 通过 transformers.Trainer 训练非常方便,会自动初始化 deepspeed 和分布式环境,所有的分布式配置只要写到
ds_config.json中就可以了。 - 这里有两个小问题:一个是
ds_config.json中的 “train_micro_batch_size_per_gpu” 必须和deepspeed_train.py中的 “per_device_train_batch_size” 一致;一个是zero对于微调不支持 stage3。
import torch
from peft import LoraConfig, get_peft_model
from transformers import TrainingArguments, AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTTrainer
import time
# 导入 deepspeed 库和 pytorch 通信后端
import deepspeed
import torch.distributed as dist
# 修改:初始化分布式环境
deepspeed.init_distributed()
world_size = dist.get_world_size()
rank = dist.get_rank()
data_files = {"train": "./data/dialogues.parquet"}
dataset = load_dataset("parquet", data_files=data_files)
def merge_fields(examples):
examples["text"] = [
f"Description: {Description} Patient: {Patient} Doctor: {Doctor}"
for Description, Patient, Doctor in zip(examples["Description"], examples["Patient"], examples["Doctor"])
]
return examples
dataset = dataset.map(merge_fields, batched=True)
split_dataset = dataset['train'].train_test_split(test_size=0.2, seed=42)
train_dataset = split_dataset['train']
temp_split = split_dataset['test'].train_test_split(test_size=0.5, seed=42)
test_dataset = temp_split['test']
eval_dataset = temp_split['train']
# 修改:只有 rank0 进程打印信息
if rank == 0:
print("Find GPUs:", torch.cuda.device_count(), [torch.cuda.get_device_name(i) for i in range(torch.cuda.device_count())]) # 列出设备
print("[rank0] Train size:", len(train_dataset))
print("[rank0] Test size:", len(test_dataset))
print("[rank0] Eval size:", len(eval_dataset))
output_dir = './output-deepspeed'
peft_config = LoraConfig(
r=8,
lora_alpha=8,
target_modules=['q_proj', 'v_proj'],
lora_dropout=0.05,
bias='none',
task_type='CAUSAL_LM'
)
# 修改:训练参数中加入 deepspeed 配置文件
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=16,
optim='adamw_torch',
learning_rate=10e-4,
eval_steps=100,
logging_steps=200,
eval_strategy='steps',
group_by_length=False,
max_steps=200,
# num_train_epochs=1,
gradient_accumulation_steps=1,
gradient_checkpointing=True,
max_grad_norm=0.3,
bf16=True,
lr_scheduler_type='cosine',
warmup_steps=100,
deepspeed="./ds_config.json" # 加入 deepspeed 配置文件
)
model_path = './llama-2-7b-hf'
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16
)
model.enable_input_require_grads()
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model.config.use_cache = False
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
tokenizer.pad_token_id = 0
tokenizer.padding_side = 'right'
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
tokenizer=tokenizer,
args=training_arguments,
max_seq_length=512,
dataset_text_field='text'
)
# 修改:只有 rank0 进程打印信息
if rank == 0:
print("start training")
start_time = time.time()
trainer.train()
if rank == 0:
end_time = time.time()
print("finished training")
print("time_used:", end_time-start_time, "s")
trainer.model.save_pretrained(output_dir)
(3)编写脚本进行训练,然后合并权重文件(步骤同2.2节)
其中,deepspeed_train.sh :
#!/bin/bash
#SBATCH --nodes=1 # 节点数
#SBATCH --ntasks=4 # 任务数
#SBATCH --partition=ai # 分区名称(根据集群修改)
module load CUDA/12.2
deepspeed --num_nodes=1 --num_gpus=4 deepspeed_train.py
(4)训练时间和精度对比
单卡训练:
使用deepspeed分布式四卡训练:


可以看出训练效率有明显提升,但由于通信、等待的一些问题,加速比远远达不到4倍。