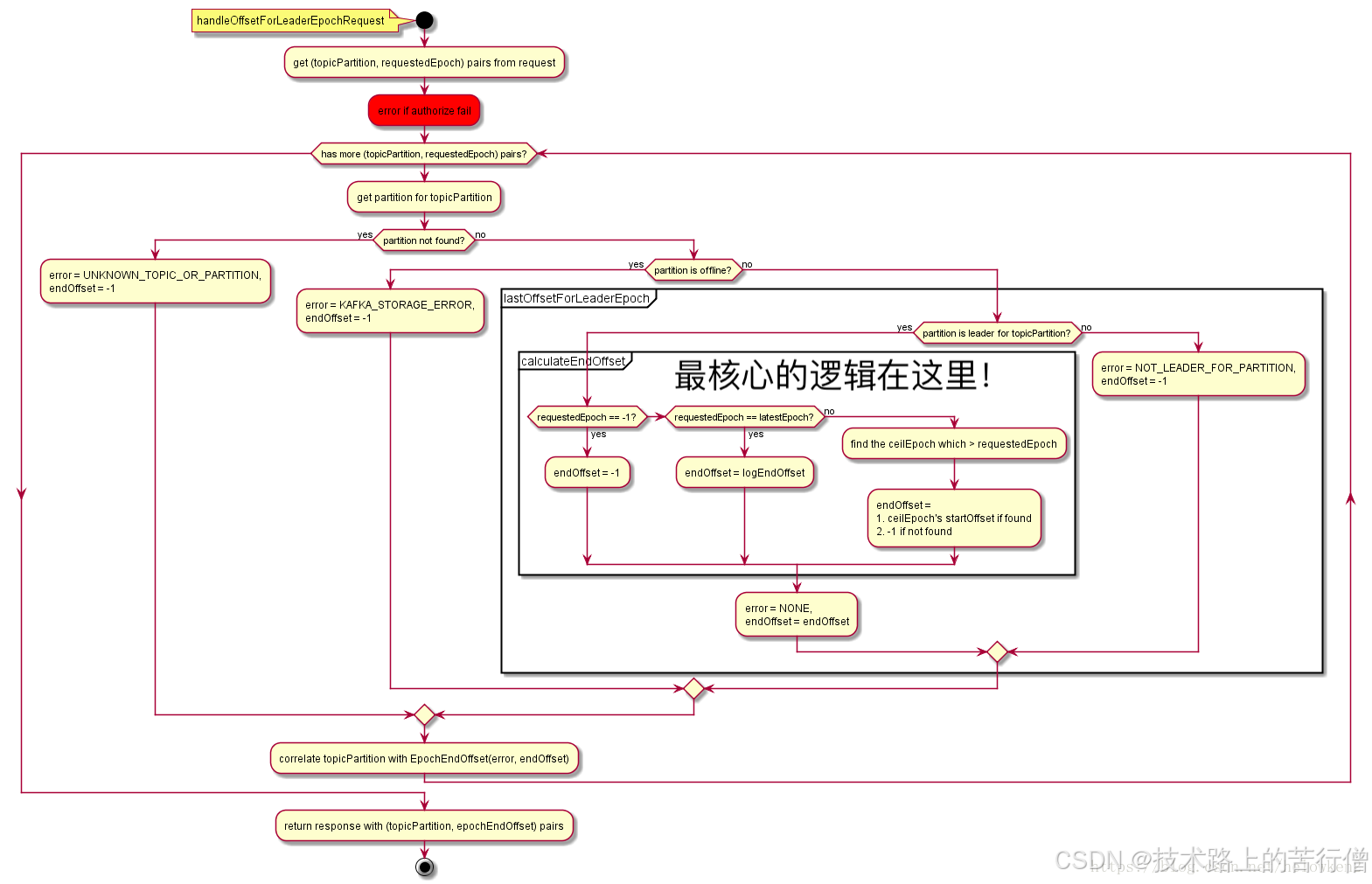
一、Kafka底层架构
1.1 存储架构
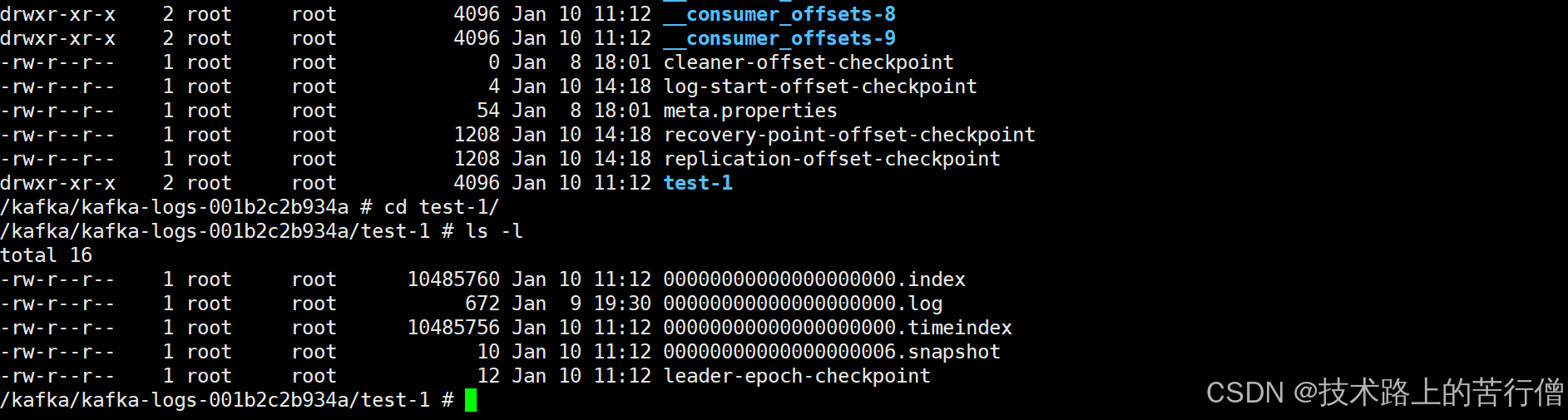
在前面讲过kafka每个主题可以有多个分区,每个分区在它所在的broker上创建一个文件夹每个分区又分为多个段,每个段两个文件,log文件存储顺序消息,index文件里存消息的索引,然后每一个段的命名直接以当前段的第一条消息的offset为名。
需要注意的是偏移量,不是序号,然后偏移量是从下标0开始,第几条消息 = 偏移量 +1,类似于数组长度和下标。
例如:
0.log -> 该文件存储8条数据,offset为0-7;
8.log -> 有两条,offset为 8-9;
10.log -> 有xxx条,offset从10-xx
1.1.2 日志索引
每个log文件配备一个索引文件*.index,文件格式为:(offset,内存偏移量)
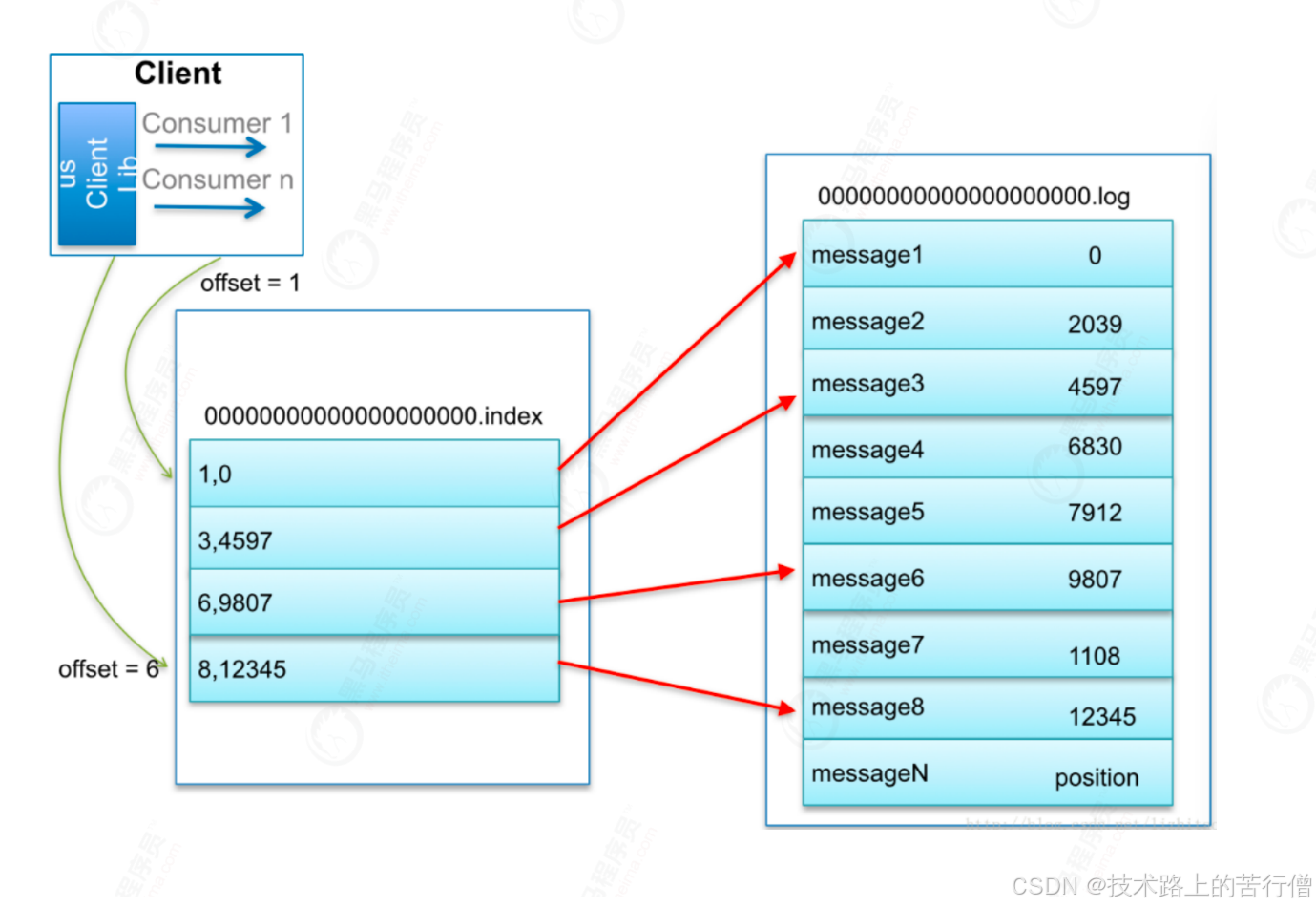
kafka中查找消息的整体流程如下:
- consumer发起请求要求从offset=6的消息开始消费;
- kafka首先会根据offset,查找offset=6的消息存在在那个*.log文件中,定位到这个.log文件;
- 定位到这个log文件之后,会再去对应x.log文件对应的x.index文件中去查找该消息的具体定位,如上图发现到6,9807,注意9807就是消息在x.log文件具体的内存偏移量;
- 那么就会从x.log文件9807位置开始读取,具体读取的长度就是到下一条消息的偏移量即可;
需要注意的是,*.index并不是存储每一条消息的内存偏移量,而是一个散列索引,所以可能还是存在一小段的内存检索;
1.1.2 日志删除
Kafka作为消息中间件,数据需要按照一定的规则删除,否则数据量太大会把集群存储空间占满。
数据删除的方式:
- 按照时间,超过一段时间后删除过期消息;
- 按照消息大小,消息数量超过一定大小后删除最旧的数据;
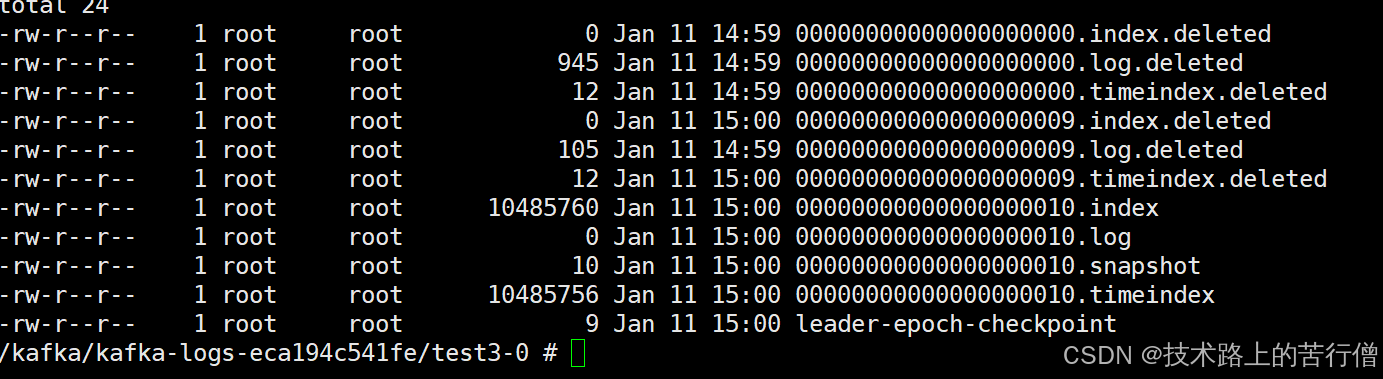
Kafka删除数据的最小单位:segment,也就是直接删除对应文件*.log,一删就是删除一个log和对应的index文件。
kafka通过配置retention.bytes:超出后旧日志被删除跟retention.ms超出时间后旧日志被删除。接下来我们新建一个topic来验证kafka的日志删除策略;
kafka-topics.sh --zookeeper zookeeper:2181 --create --topic test3 --partitions 2 --replication-factor 1 --config retention.bytes=1000 --config retention.ms=60000 --config segment.bytes=1000
retention.ms=60000:即超出一分钟后的旧日志会被删除;
retention.bytes=1000:超出1000byte的旧日志会被删除
segment.bytes=1000 :配置log的每个segment的大小,当log文件大小超出这个值的时候就会被新建新的log文件

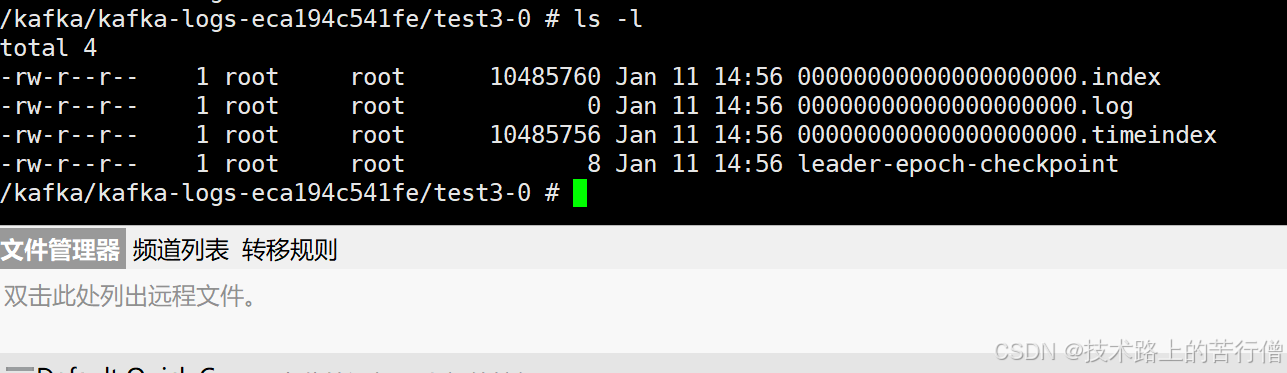
然后我们进入到容器中查看对应的日志存储文件:
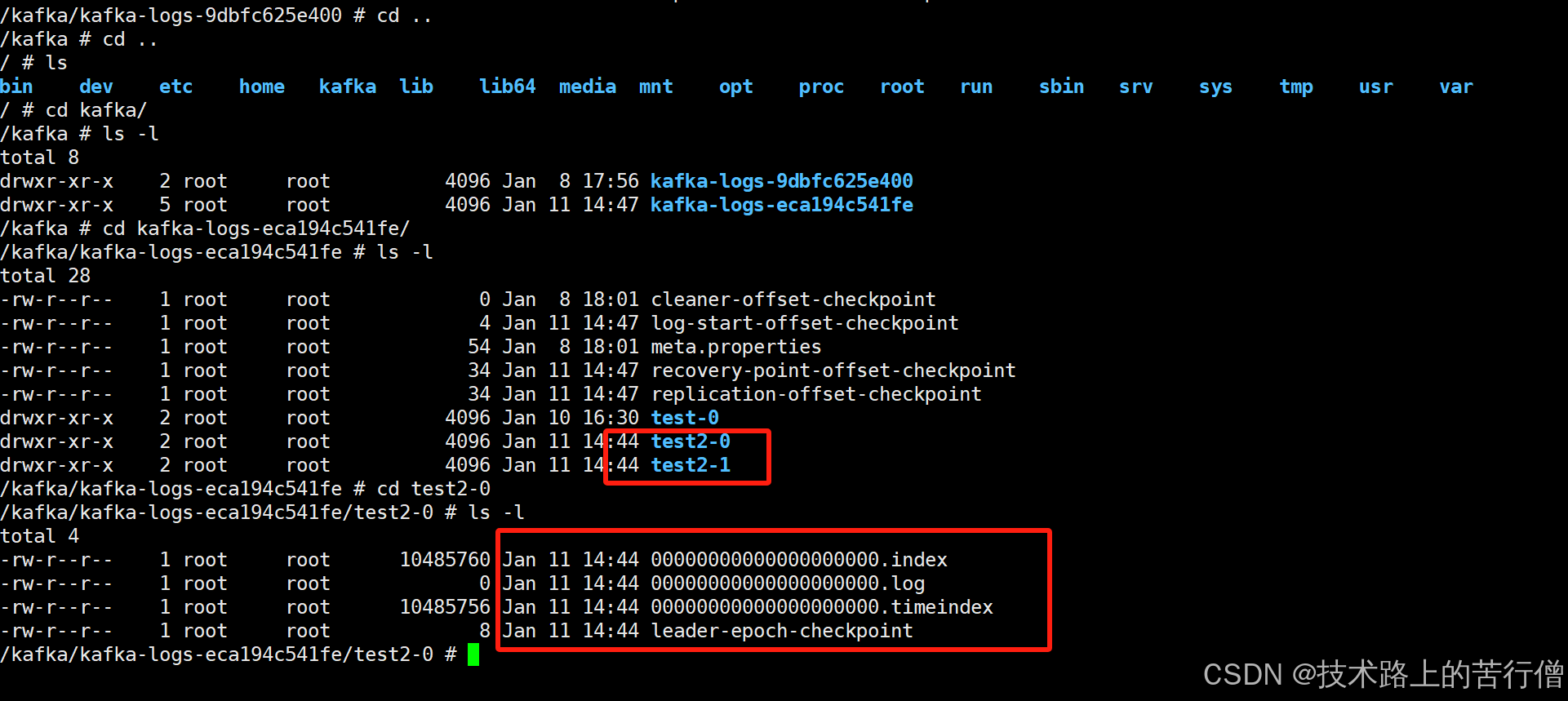
然后我们指定生产者往partition0中发消息然后来验证我们的日志删除策略:
@RestController
public class PartitionProducer {
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
// 指定分区发送
// 不管你key是什么,到同一个分区
@GetMapping("/kafka/partitionSend/{key}")
public void setPartition(@PathVariable("key") String key) {
kafkaTemplate.send("test2", 0,key,"key="+key+",msg=指定0号分区");
}
// 指定key发送,不指定分区
// 根据key做hash,相同的key到同一个分区
@GetMapping("/kafka/keysend/{key}")
public void setKey(@PathVariable("key") String key) {
kafkaTemplate.send("test2", key,"key="+key+",msg=不指定分区");
}
// 什么也不指定
@GetMapping("/kafka/test/{msg}")
public void sendMessage(@PathVariable("msg") String msg) {
Message message = new Message();
message.setMessage(msg);
kafkaTemplate.send("test2", JSON.toJSONString(message));
}
} 此时就会发现我们超出了大小就会分裂出来新的文件。
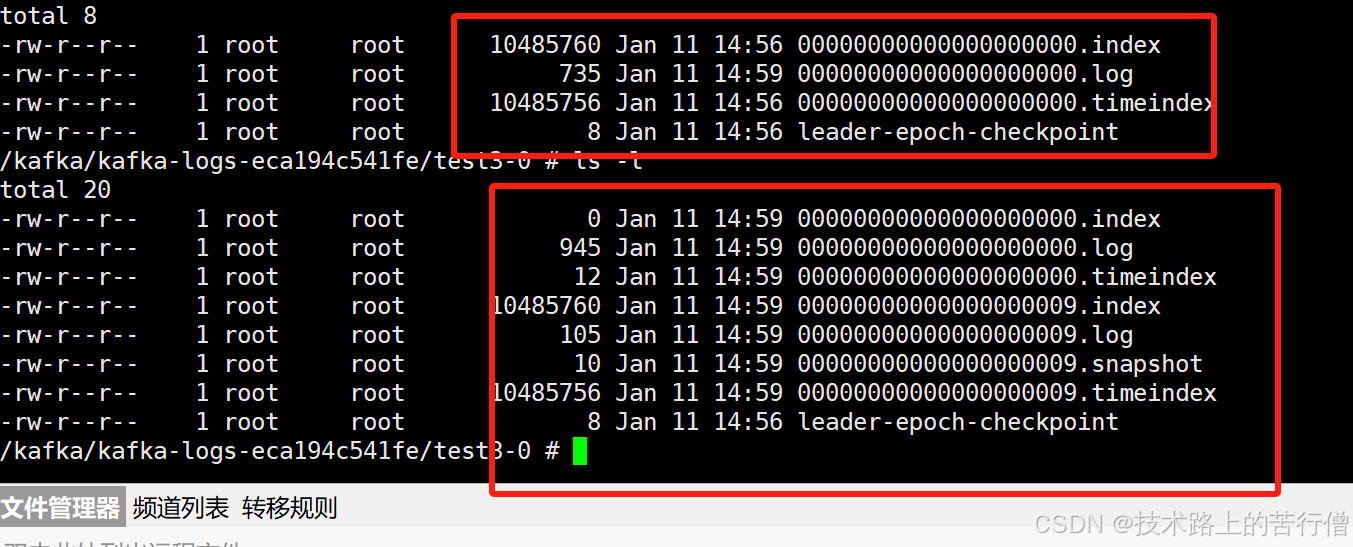
然后我们观察60s之后再去刷新看下对应的日志文件。
1.2 零拷贝
零拷贝(英语: Zero-copy) 技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
1.2.1 传统数据传输机制
比如:读取文件,再用socket发送出去,实际经过四次copy。伪码实现如下:
buffer = File.read()
Socket.send(buffer) 第一次:将磁盘文件,读取到操作系统内核缓冲区;
第二次:将内核缓冲区的数据,copy到应用程序的buffer;
第三步:将application应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区);
第四次:将socket buffer的数据,copy到网卡,由网卡进行网络传输。
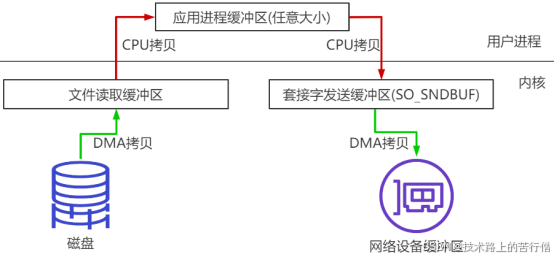
分析上述的过程,虽然引入DMA来接管CPU的中断请求,但四次copy是存在“不必要的拷贝”的。实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区之外什么都不做。相反,数据可以直接从读缓冲区传输到套接字缓冲区。
1.2.2 DMA
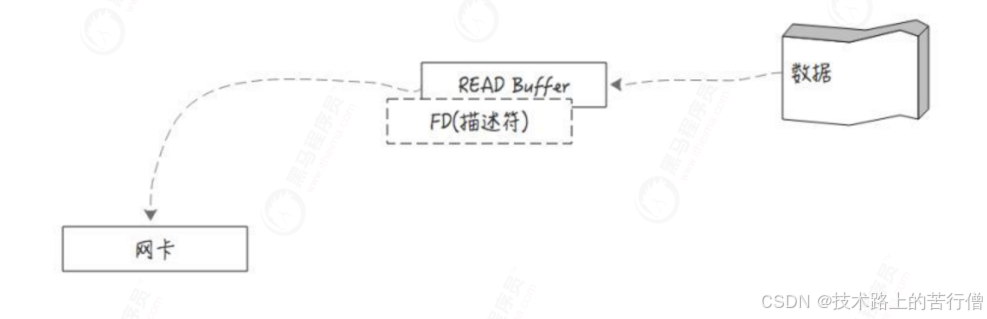
DMA其实是由DMA芯片来控制的,通过DMA控制芯片,可以让网卡等外部设备直接去读取内存,而不是由cpu来回拷贝传输,这就是零拷贝。目前计算机主流硬件基本都支持DMA,就包括我们的硬盘和网卡。
kafka就是调取操作系统的sendfile,借助DMA来实现零拷贝数据传输的。
1.3 分区一致性
1.3.1 水位值
先来回顾两个值:
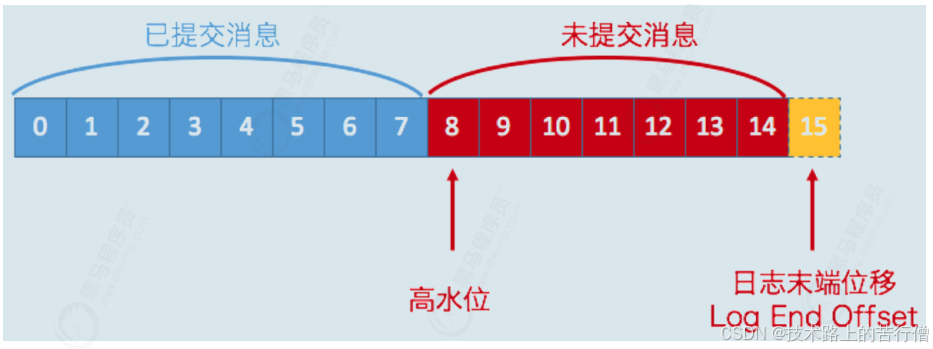
LEO:指向了当前已经写入的最大偏移量;
HW:指向了目前可以被消费的最大偏移量;
其中LEO >= HW,需要注意的是分区是有leader和follower的,最新写的消息会进入到leader,follower从leader不停地同步,无论是leader还是follower,都有自己的HW和LEO,存储在各自分区的磁盘上,但是leader会多存储一个Remote LEO,它表示针对各个follower的LEO,leader又额外存储了一份各个follower的LEO;
leader会拿这些remote值里最小的来更新自己的hw,具体过程如下。
1.3.2 同步原理
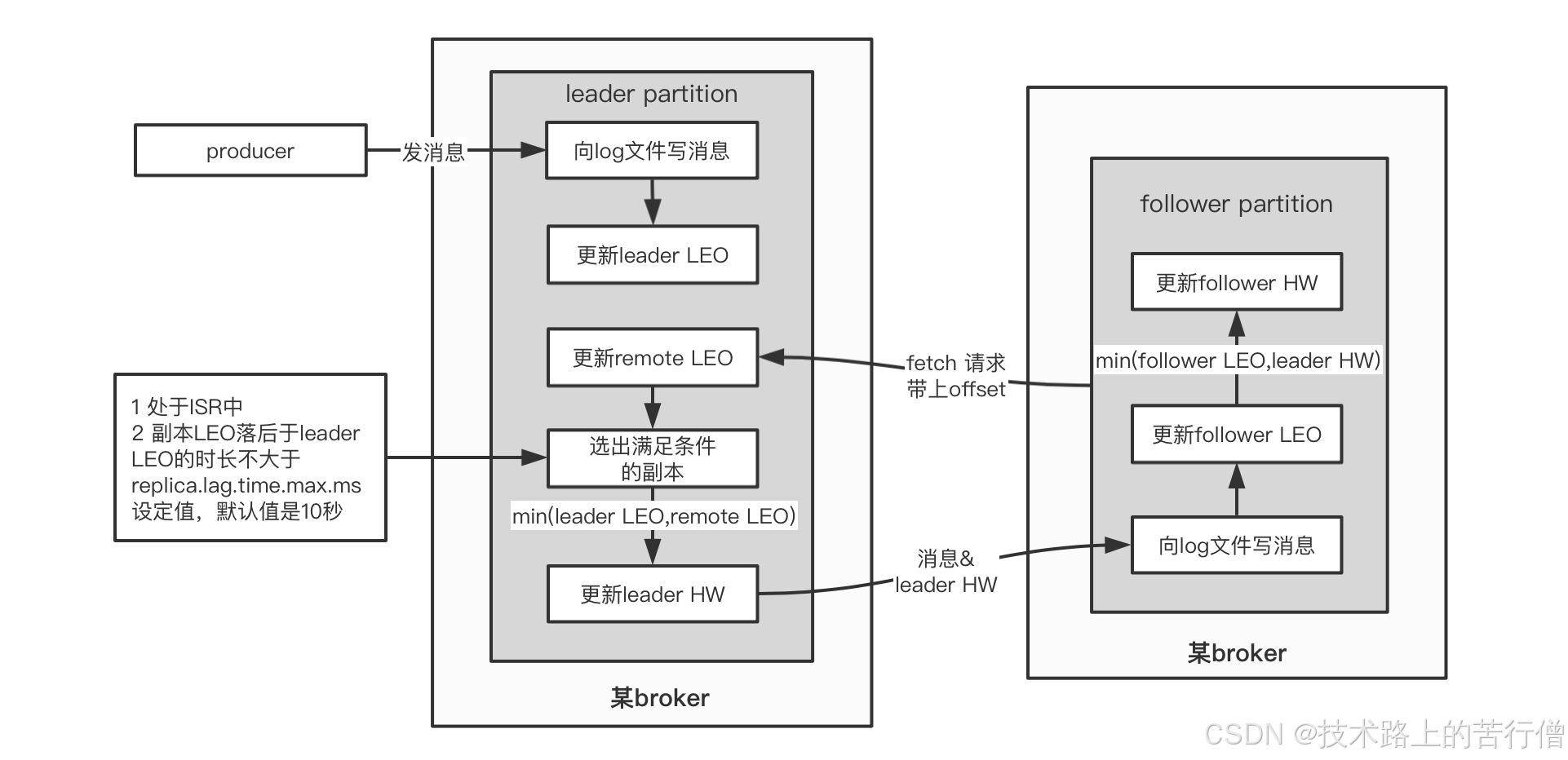
我们用伪代码来表示上面这个流程:
/**
* @author maoqichaun
* @date 2025年01月11日 15:24
*/
public class Follower {
private List<Message> messages;
private HW hw;
private LEO leo;
@Scheduled("不停地向leader发起同步请求")
void execute(){
// 向leader发起fetch请求,将自己的leo传过去
// leader返回leo之后最新的消息,以及leader的hw
LeaderReturn lr = leader.fetch(leo);
// 存消息
this.messages = lr.getMessages();
// 增加follower的leo的值
this.leo = this.leo + lr.newMsg.length;
// 比较自己的leo和leader的hw,取两者最小的作为follower的hw
this.hw = Math.min(this.hw, lr.hw);
}
}
// leader节点返回的报文
class LeaderReturn {
List<Message> newMsg;
// leader的hw
HW leaderHw;
}
public class Leader {
private List<Message> messages;
private HW hw;
private LEO leo;
// 如果此时有多个follower的话,这里就会有多个RemoteLEO对象
private RemoteLEO remoteLEO;
LeaderReturn fetch(LEO followerLEO){
// 根据follower传过来的leo来更新leader的remote
this.remoteLEO = followerLEO;
// 然后取ISR(所有可用副本)得最小leo作为leader的hw
this.hw = Math.min(this.remoteLEO.getIsr(),this.leo);
// 从leader的消息列表里,查找大于follower的leo的所有消息
List<Message> newMsg = this.messages.stream().filter(msg -> msg.getSendTime() > this.hw).collect(Collectors.toList());‘
// 将最新消息(大于follower leo的那些消息)以及leader的hw返回给follower
return new LeaderReturn(newMsg,this.hw);
}
}
1.3.3 Leader Epoch机制
发生的背景:0.11版本之前的kafka,完全借助hw作为消息的基准,不管leo,发生故障之后的规则:
- follower故障再次恢复后,从磁盘读取hw的值并开始剔除后面的消息,并同步leader消息;
- leader故障后,新当选的leader的hw作为新的分区的hw,其余节点按照此hw进行剔除数据,并重新同步;
上诉根据hw进行数据恢复出现数据丢失和数据不一致的情况,下面分开来看:
假设:我们存在两个副本:leader(A)、follower(B)
1)丢数据
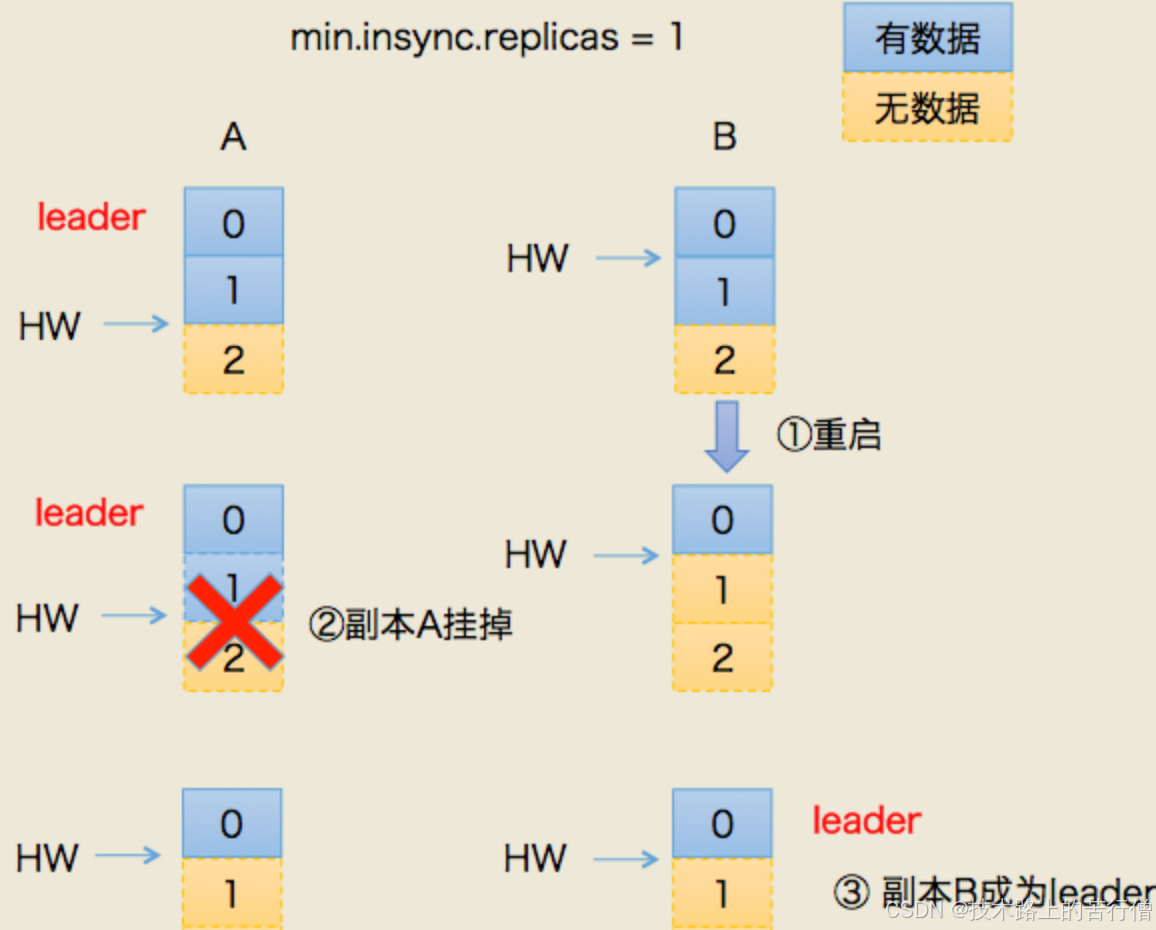
- 某个时间点节点B挂了,当它恢复后,以挂之前的hw为准,设置leo=hw;
- 这就造成了一个问题:现实中,leo很可能是大于hw的,这种暴力赋值就导致了leo被回退了;
- 如果这个时候,恰恰A也挂掉了,kafka会重选leader,B被选中。
- 过段时间,A恢复后变成follower,从B开始同步数据。
- 问题就来了,上面说了,B得数据是被回退过的,以他为基准会有问题;
- 最终结果就是:两者的数据都会发生丢失,没有地方可以找回;
2):场景二:数据不一致;
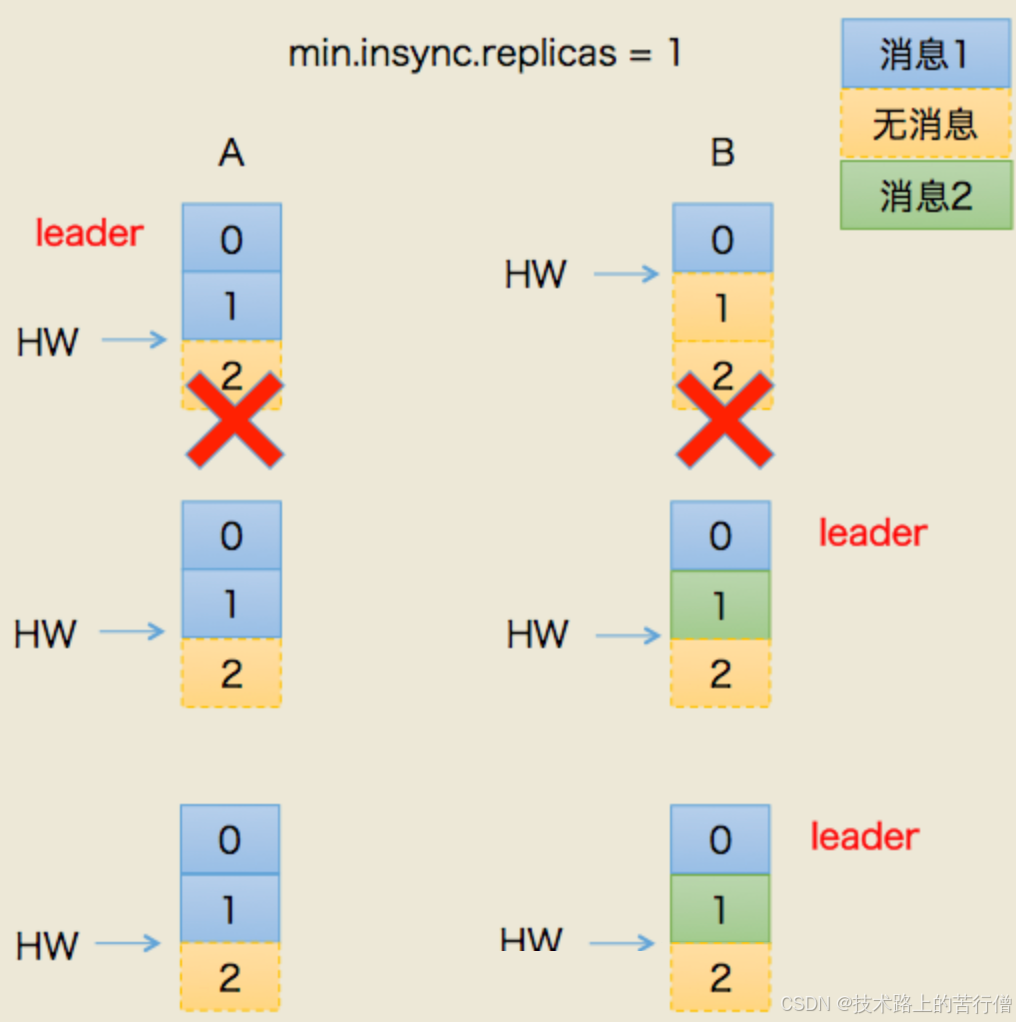
- 假设A/B节点都挂掉了;
- B先恢复,但是它的hw有可能挂之前没从A同步过来(A是挂之前的leader);
- 我们假设,A.hw = 2,B.hw=1;
- B恢复之后,集群里面只有B自己,所以被选中为leader,B开始接受新消息;
- B.hw上涨,变为2;
- 然后此时A恢复了,原来A.hw=2,恢复后B得hw,也就是以2为基准开始同步。
- 问题就来了,B当leader后新接到的2号消息不回同步给A的,A一直保留着他当leader时的旧数据。
- 那么此时节点A,B的数据就存在不一致了;
改进思路:0.11之后,kafka改进改进了hw做主的规则,这个就是 leader epoch,leader epoch给leader节点带了一个版本号,类似于乐观锁的设计,它的思想是,一旦机器发生故障,重启之后,不再机械的将leo退回hw,而是借助epoch的版本信息,去请求当前的leader,让它去算一算leo应该是什么。
实现原理:
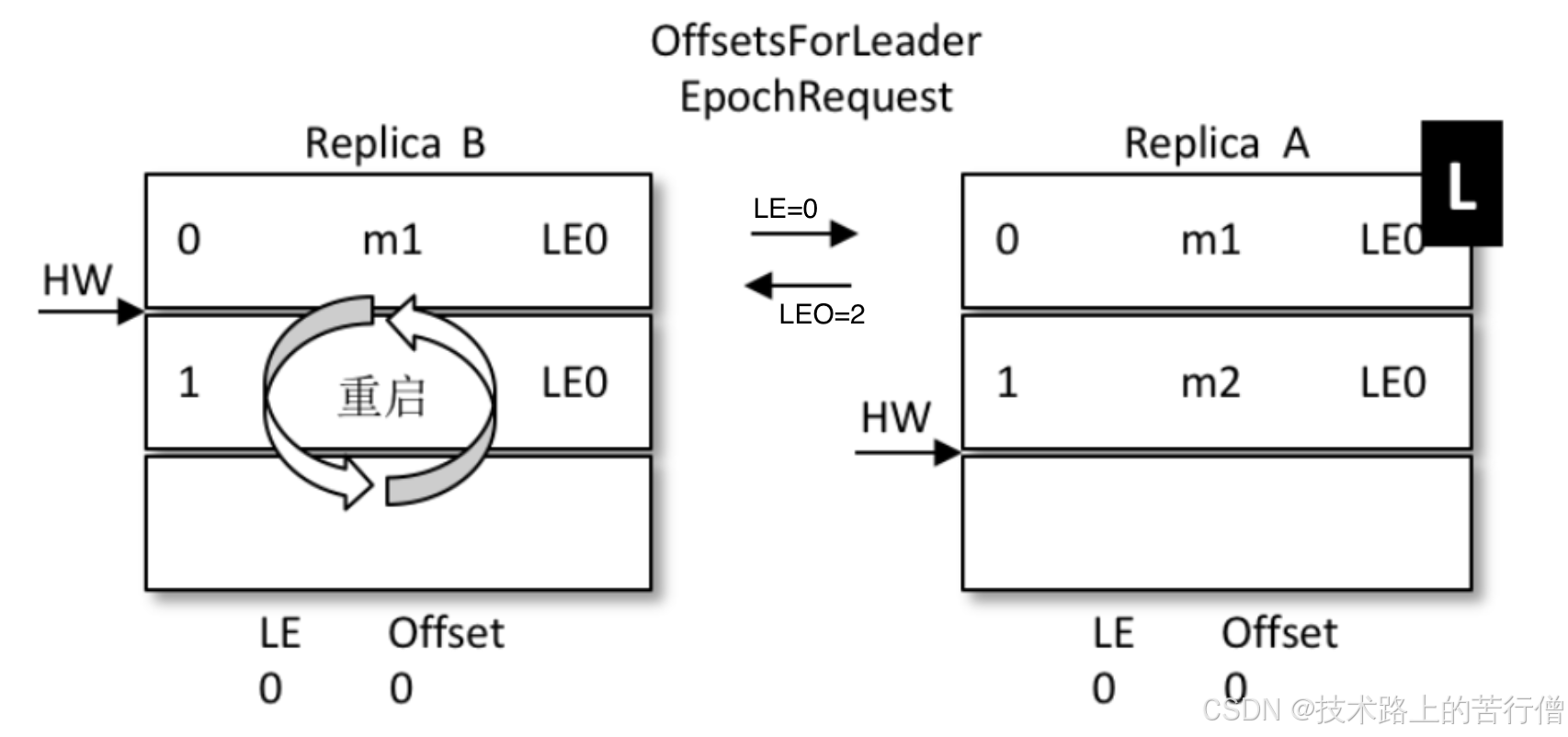
- A为(leo =2,hw=2),B为(leo =2,hw=1);
- B重启,但是B不着急将leo打回hw,而是发起一个Epoch请求给当前的leader,也就是A;
- A收到LE=0,发现和自己的LE一样,说明B在改掉前后,leader没变,但是A自己;
- 那么A就将自己的leo的值返回给B,也就是数字2;
- B收到2后和自己的leo做比较取最小值,发现也是2,那么就不会再将leo回退到2;
- 没有发生回退,那就是信息1的位置没有被覆盖,最大程度的保护数据;
- 如果和上面一样,A挂掉了,B被选为leader;
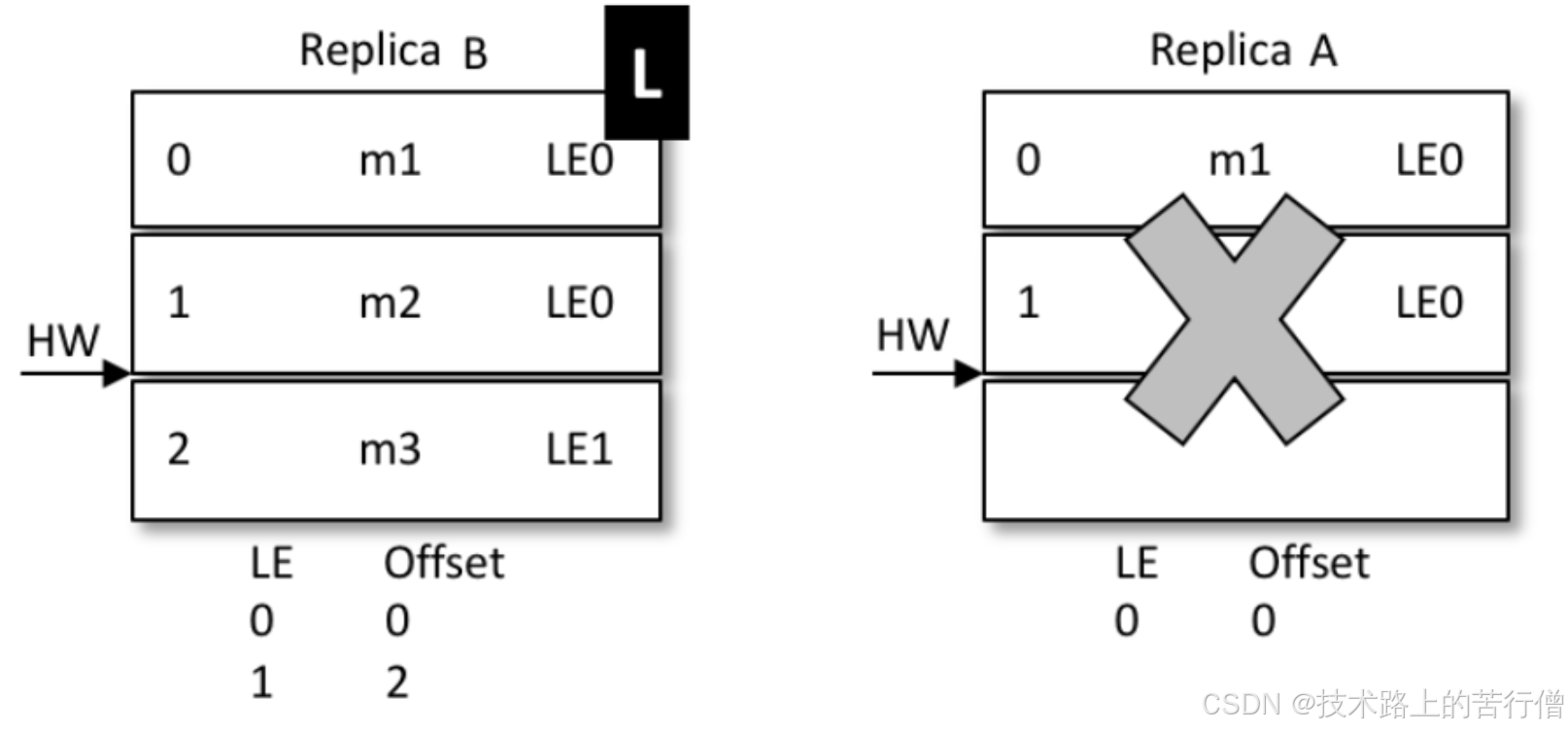
- 那么A再次启动之后,从B开始同步数据;
- 因为B之前没有回退,1号信息得到了保留;
- 同时B的LE(Epoch号码)开始增加,从0变成1,offset记录为B当leader时的位置,也就是2;
- A传过来的epoch为0,B是1,不相等,那么取大于0的所有epoch里最小的(现实环境可能发生了多次重新选主,有多条epoch)
- 其实就是LE=1的那条,现实中可能有多条,并找到它的offset(也就是2)给A返回回去;
- 最终A得到了B同步过来的数据;
再来看看一致性问题的解决:

- 还是上面的场景,AB同时挂掉,但是hw还没有同步,那么A.hw=2,B.hw=1;
- B先启动被选成了leader,新leader选举之后,epoch加了一条记录;(参考下图,LE=1,这时候offset=1);
- 表示B从1开始往后继续写数据,新来了一条小学,内容为m3,写到1号位
- A启动前,集群只有B自己,消息被确认,hw上涨到2,变成了下面的样子:
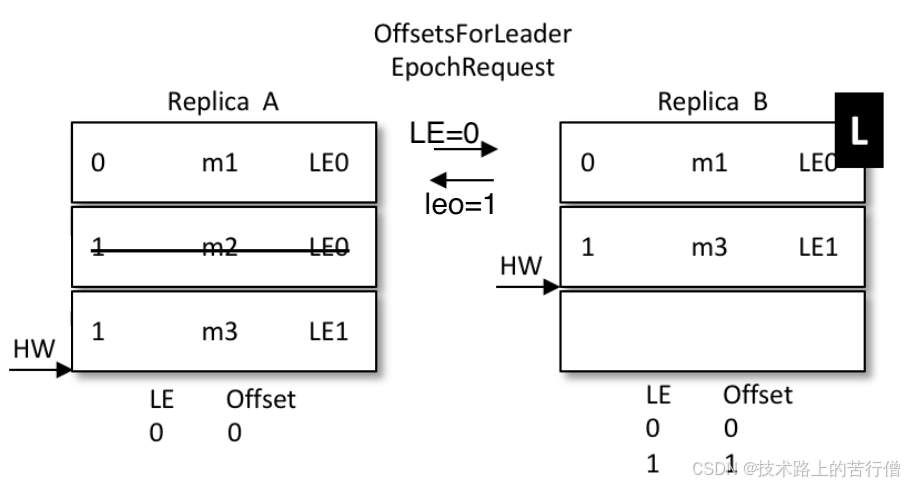
- A开始恢复,启动后向B发送epoch请求,将自己的LE=0告诉leader,也就是B
- B发现自己的LE不同,同样去大于0的LE里最小的那条,也就是1,对应的offset也就是1,返回给A
- A从1开始同步数据,将自己本地的数据截断,覆盖,hw上升到2;
- 那么最新的写入的m3从B同步到了A,并覆盖了A上之前的旧数据M2
- 结果:数据一致;
epoch流程图如下: