
🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年11月25日20点02分
神秘男子影,
秘而不宣藏。
泣意深不见,
男子自持重,
子夜独自沉。
论文链接
 https://www.aspiringcode.com/content?id=17269250482026&uid=f36d077cf4d24a1397dde09f09780350
https://www.aspiringcode.com/content?id=17269250482026&uid=f36d077cf4d24a1397dde09f09780350主要内容
这篇文章的主要内容是关于如何通过预测反馈来改善大型语言模型(LLMs)在情感分析中的上下文内学习(In-Context Learning, ICL)能力。文章提出了一个框架,该框架通过以下三个步骤来增强ICL:
- 获取LLMs的先前预测:使用传统的ICL方法为每个候选示例产生先前预测。
- 设计基于正确性的预测反馈:根据预测的正确性将示例分类,并提供反馈以阐明先前预测与人类标注之间的差异。
- 利用反馈驱动的提示来提炼情感理解:在推理过程中,从每个子池中选择相关示例,并使用特定的反馈驱动提示来包装输入、预测、标签和反馈。
文章通过在九个情感分析数据集上的实验结果表明,该框架相较于传统的ICL方法在平均F1分数上提高了5.95%。此外,文章还探讨了该框架的有效性和鲁棒性,并指出了其在其他任务上的潜在应用。
模型图
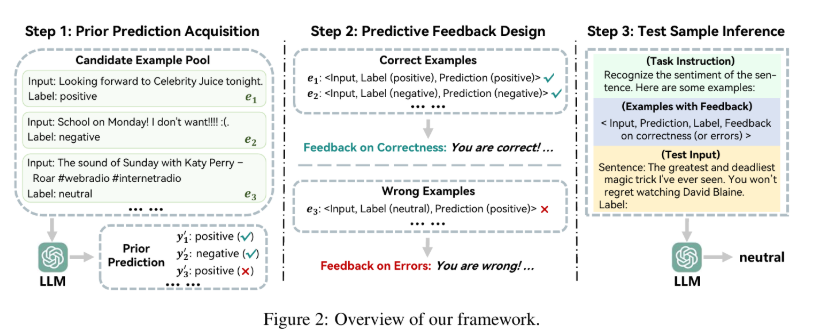
文章的反馈提示框架主要分为三步。
第一步正常预测,第二步将预测结果和真实结果进行比较得到反馈,第三步构建获得反馈的示例构建最终的提示词优化模型的任务表现。
技术细节
第一步:先验预测获取
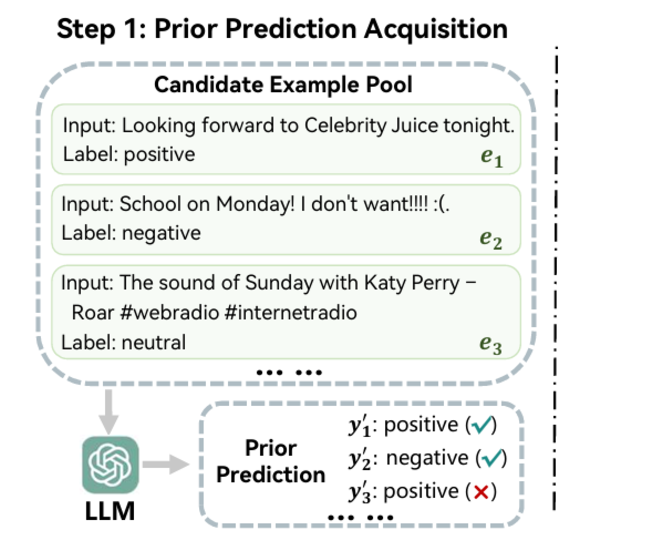
这一步的重点是获取对每条数据的预测值,以便后续的反馈提供。
为此,遵循传统的ICL,文章先从候选池中随机选择四条数据作为示例,它们与任务指令结合起来提示LLM进行预测。
这些预测称为先验预测,因为它们反映了大模型的先验情感理解。
第二步:预测反馈设计

先验预测的正确性直接标志着llm能否准确把握相应样例的情感。
为了让大模型在理解和推理方面的自我调整,文章首先将示例分为两部分,Pc和Pw,其中前者为先验正确分类的数据,后者为先验错误分类的数据。
然后,以自然语言的形式分别提供反馈:

第三步:测试样本推断
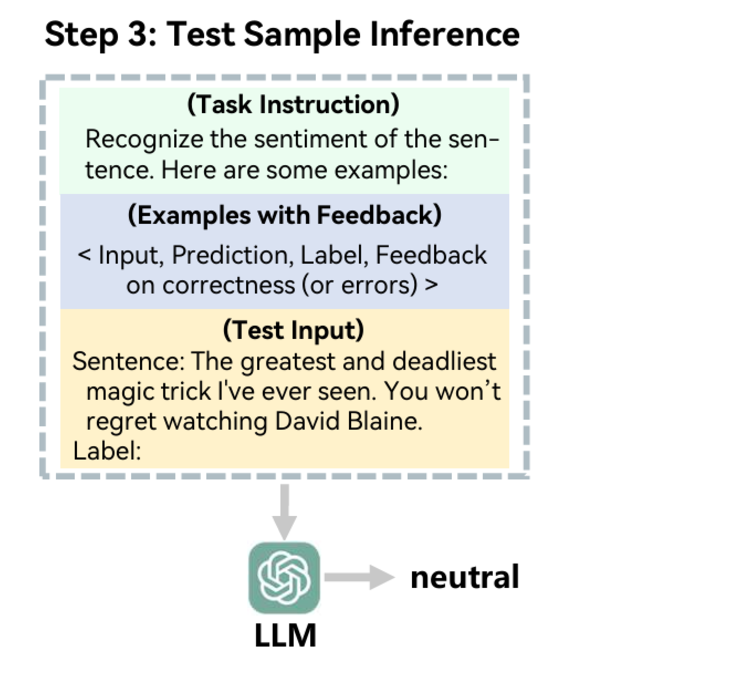
为了完成给定测试输入的推理,首先从每组数据(先验正确和先验错误得到反馈的数据)中检索k/2(文章中k默认取2)个示例。
由于文章的框架与检索模式无关,因此这里可以使用任何示例检索技术。
此外,文章还开发了一个反馈驱动的提示模板,将每个选定示例的输入、预测、标签和反馈包装成一个四件套,也就是现在的一个示例是包含数据、先验预测值、真实标签和反馈值。
其实简单来说,文章的改进点就是示例进行了改进,在示例中加入反馈了。

这就是文章提出的框架运用的实例了。
前四个都是示例
最后一个就是要进行预测的。
实验结果
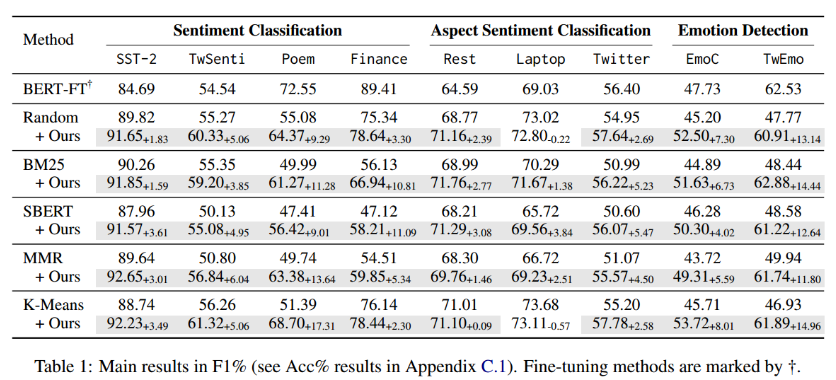
表1展示了在不同的情感分析数据集上,使用不同方法进行情感分类、方面情感分类和情绪检测任务时的性能对比。表中的性能通过F1分数(一种综合考虑查准率和查全率的性能指标)来衡量。
其中Random表示随机选取样例,BM25、SBERT、MMR、KMeans都是选取样例的各种方法,目的是选择更有代表性或者语义相似度更高的示例,以帮助大模型提示学习。
文章默认使用的大模型是Llama2-13B-Chat
我们可以看到实验结果,文章提出的方法都有提升,特别是在情绪分析任务上提升最大。
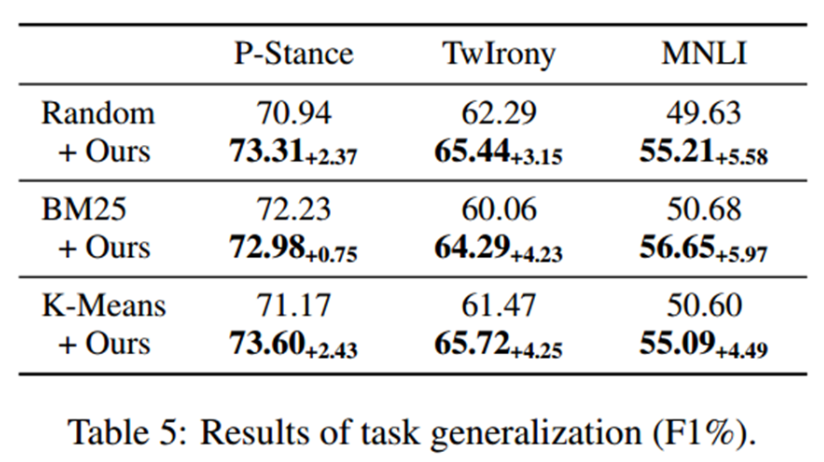
在一些立场检测,自然语言理解的任务上,文章提出的框架仍然有用。


消融实验表明每个部分都是有用的,去除都会影响性能。
运行
基础配置

安装包
python3.11
pip install -r req.txt --default-timeout=120 -i https://pypi.tuna.tsinghua.edu.cn/simple运行代码
run.bat小结
文章的思路比较简单,但是效果确实有提升,提示学习还是有点东西的。
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
"每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。"
神秘泣男子
