1.问答机器人的组成
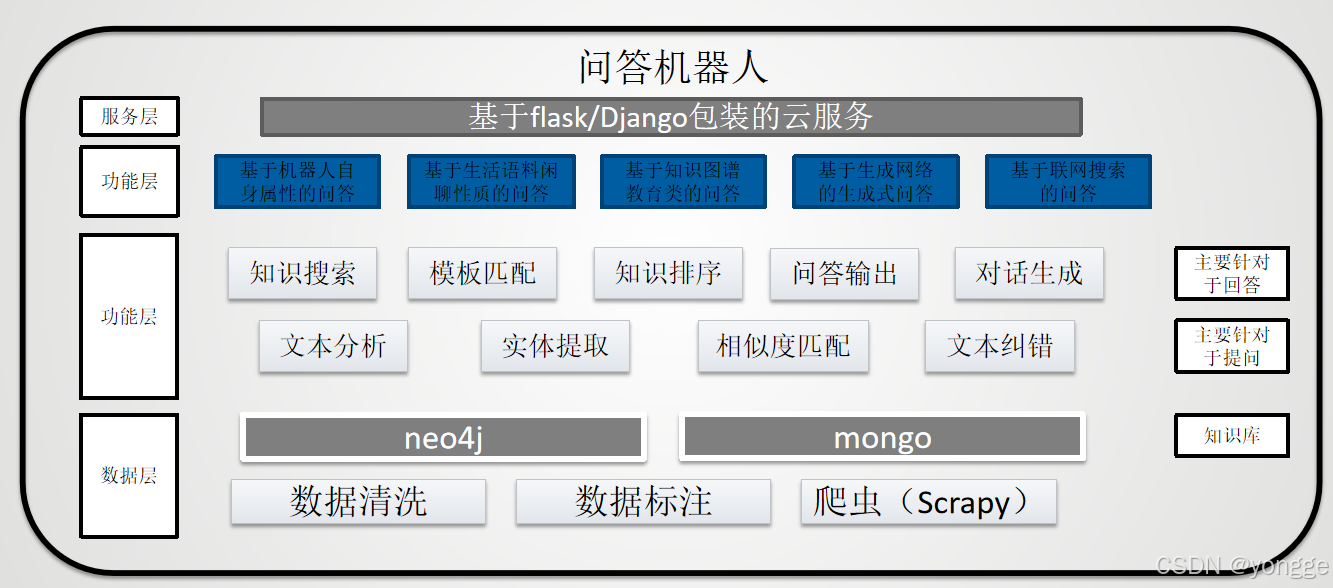
1.1 问答机器人的组成结构图
2. 问答机器人的组成-机器人的个人属性
所谓的机器人一般具备有个人的属性,这些属性固定,形成了机器人的个人偏好
在实现过程中,此处使用一个xml配置文件,配置了机器人的个人年龄、性别、职业等内容,同时包含常见有关于机器人属性的问答
服务初始化时,预加载这些属性作为准备;
线上推理时,一般会判断是否是有关于机器人属性的提问,从而进行回答 此处使用模板匹配,进行问题搜索,匹配成功则返回相关的答案
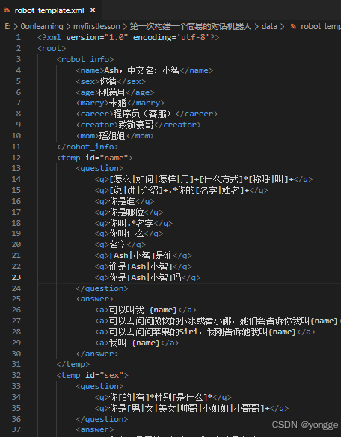
2.1 问答机器人代码实现
import xml.etree.ElementTree as et#python可读取xml工具
template = et.parse('data/robot_template.xml')#加载xml
class template():
def __init__(self):
self.template = et.parse(TEMPLATE_PATH)
self.robot_info = self.load_robot_info()#加载个人属性
self.temp = self.template.findall('temp')#加载问答样式
def load_robot_info(self):
rebot_info = self.template.find('robot_info')
rebot_info_dict = {}
for info in rebot_info:
rebot_info_dict[info.tag] = info.text
return rebot_info_dict
def search_answer(self, question):
match_temp = None
flag = None
for temp in self.temps:
qs = temp.find('question').findall('q')
for q in qs:
res = re.search(q.text,question)
if res:
match_temp = temp
flag = True
break
if flag:
break
if flag:
a_s = choice([i.text for i in match_temp.find('answer').findall('a')])
answer = a_s.format(**self.robot_info)
return answer
else:
return None3. 问答机器人的组成-基于语料的回答
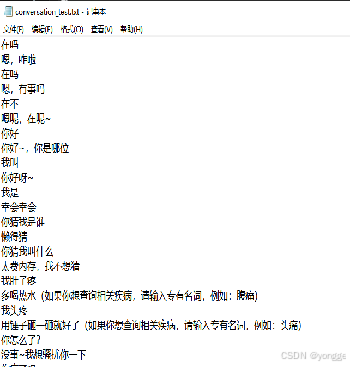
机器人的对话学习过程中,一般有一些现成的语料,这些语料来源于日常生活的对话
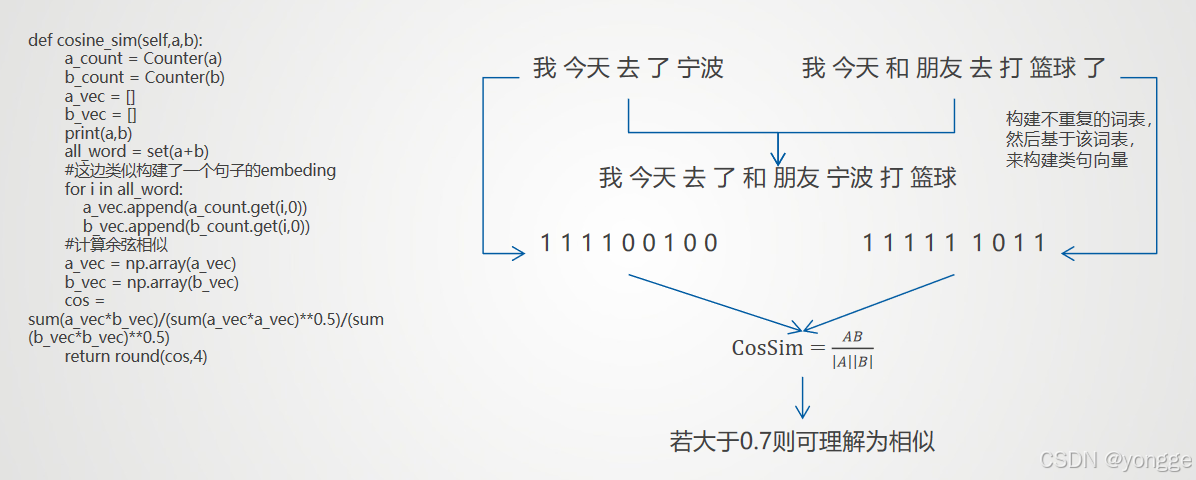
在此处,基于余弦相似度,对用户的提问和已有语料的提问进行匹配,若匹配成功,则表明用户提问与现有语料中有高度相似的提问,从而返回该提问对应的回答
通过这种余弦相似度的匹配,可以构建一个简易的对话系统,但并不准确,且当语料很庞大时,这样的计算是很可怕的,而且准确率很差
在后续的学习过程中会使用更多的语料,通过深度学习模型来生成或者快速检索合适的答案进行回答
3.1 问答机器人的组成-基于语料的回答(预处理)
s1:文本清洗+切词+生成q,a列表
def load_seq_qa():
q_list,a_list = [],[]
with open(CORPUS_PATH,'r',encoding = 'utf-8') as f:
for ind, i in enumerate(f):
i = jieba.lcut(i.strip())
if ind % 2 == 0:
q_list.append(i)
else:
a_list.append(i)
return q_list,a_list
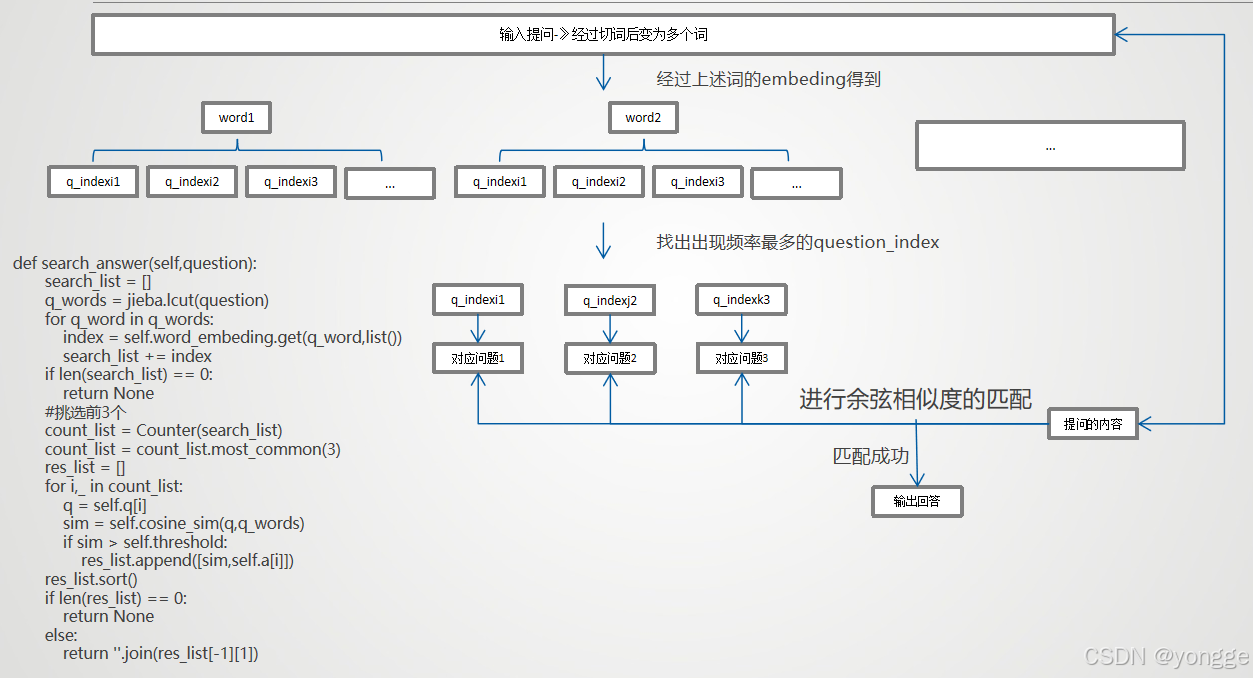
s2:将所得词index化(为后续生成式问答服务)
def build_vocab():
q,_ = load_seq_qa()
word_dict = set([j for i in q for j in i])
word_dict = dict(zip(word_dict,range(len(word_dict))))
return word_dict
s3:将所得词embeding化
def build_word_embeding():
q,_ = load_seq_qa()
word_dict = build_vocab()
word_embeding = {}
for w in word_dict.keys():
word_embeding[w] = []
for ind,qs in enumerate(q):
for w in qs:
word_embeding[w].append(ind)
return word_embeding