**
训练代码
链接: link.
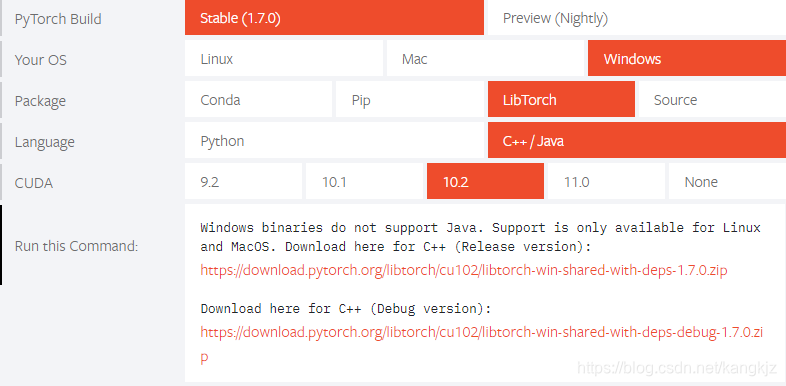
安装libtorch
首先从官网下载libtorch
模型转换
由于python训练保存的是pth文件,是不能在c++中直接调用的,因此需要先转换模型,即转换成c++版本的libtorch可以调用的pt模型,这一步是在python中的pytorch里实现的。
模型的序列化是利用Torch Script来完成的。TorchScript是一种从PyTorch代码创建可序列化和可优化模型的方法。用TorchScript编写的任何代码都可以从Python进程中保存并加载到没有Python依赖关系的进程中。对于一个已经训练好的pytorch模型,官方提供两种方法进行Torch Script的转换:tracing和annotation。
tracing适用于大多数网络,如果你的网络的forward方法中对input有逻辑判断,比如input的size为一个值时走向一个分支,而为另一值时走向另一个分支,那么只能用annotation进行转换。
这里我用的是第一种方法tracing,即需要传一个输入给torch.jit.trace函数,让它输出一次,然后save。模型是采用market1501数据集训练的。示例代码:
from torchvision import models
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from model import PCBModel
from torchvision import datasets, transforms
from PIL import Image
from torch.jit import ScriptModule, script_method, trace
import time
import cv2 as cv
def load_img(img_name):
loader = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img = cv.imread(img_name)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
img = cv.resize(img, (128