Alphago家族又添新成员
来源:环球科学ScientificAmerican公众号
策划 | 吴非 绘制 | 铁蛋公主



专家评Alphago Zero 成绩令人欣喜但AI还在路上

Alphago进步速度示意图
作者:葛熔金
在金庸的小说《射雕英雄传》里,周伯通“左手画圆,右手画方”,左手攻击右手,右手及时反搏,自娱自乐,终无敌于天下。
现实世界中,亦有这么一个“幼童”,他没见过一个棋谱,也没有得到一个人指点,从零开始,自娱自乐,自己参悟,用了仅仅40天,便称霸围棋武林。
这个“幼童”,叫阿尔法元(AlphaGo Zero),就是今年5月在乌镇围棋峰会上打败了人类第一高手柯洁的阿尔法狗强化版AlphaGo Master的同门“师弟”。不过,这个遍读人类几乎所有棋谱、以3比0打败人类第一高手的师兄,在“师弟”阿尔法元从零自学第21天后,便被其击败。
10月19日,一手创造了AlphaGo神话的谷歌DeepMind团队在Nature杂志上发表重磅论文Mastering the game of Go without human knowledge,介绍了团队最新研究成果——阿尔法元的出世,引起业内轰动。
虽师出同门,但是师兄弟的看家本领却有本质的差别。
“过去所有版本的AlphaGo都从利用人类数据进行培训开始,它们被告知人类高手在这个地方怎么下,在另一个地方又怎么下。” DeepMind阿尔法狗项目负责人David Silver博士在一段采访中介绍,“而阿尔法元不使用任何人类数据,完全是自我学习,从自我对弈中实践。”
David Silver博士介绍,在他们所设计的算法中,阿尔法元的对手,或者叫陪练,总是被调成与其水平一致。“所以它是从最基础的水平起步,从零开始,从随机招式开始,但在学习过程中的每一步,它的对手都会正好被校准为匹配器当前水平,一开始,这些对手都非常弱,但是之后渐渐变得越来越强大。”
这种学习方式正是当今人工智能最热门的研究领域之一——强化学习(Reinforcement learning)。
昆山杜克大学和美国杜克大学电子与计算机工程学教授李昕博士向澎湃新闻(www.thepaper.cn)介绍,DeepMind团队此次所利用的一种新的强化学习方式,是从一个对围棋没有任何知识的神经网络开始,然后与一种强大的搜索算法相结合,“简单地解释就是,它开始不知道该怎么做,就去尝试,尝试之后,看到了结果,若是正面结果,就知道做对了,反之,就知道做错了,这就是它自我学习的方法。”
这一过程中,阿尔法元成为自己的“老师”,神经网络不断被调整更新,以评估预测下一个落子位置以及输赢,更新后的神经网络又与搜索算法重新组合,进而创建一个新的、更强大的版本,然而再次重复这个过程,系统性能经过每一次迭代得到提高,使得神经网络预测越来越准确,阿尔法元也越来越强大。
其中值得一提的是,以前版本的阿尔法狗通常使用预测下一步的“策略网络(policy network)”和评估棋局输赢的“价值网络(value network)”两个神经网络。而更为强大的阿尔法元只使用了一个神经网络,也就是两个网络的整合版本。
这个意义上而言,“AlphaGo Zero”译成“阿尔法元”,而不是字面上的“阿尔法零”,“内涵更加丰富,代表了人类认知的起点——神经元。”李昕教授说。
上述研究更新了人们对于机器学习的认知。“人们一般认为,机器学习就是关于大数据和海量计算,但是通过阿尔法元,我们发现,其实算法比所谓计算或数据可用性更重要。”DavidSilver博士说。
李昕教授长期专注于制造业大数据研究,他认为,这个研究最有意义的一点在于,证明了人工智能在某些领域,也许可以摆脱对人类经验和辅助的依赖。“人工智能的一大难点就是,需要大量人力对数据样本进行标注,而阿尔法元则证明,人工智能可以通过‘无监督数据(unsupervised data)’,也就是人类未标注的数据,来解决问题。”
有人畅想,类似的深度强化学习算法,或许能更容易地被广泛应用到其他人类缺乏了解或是缺乏大量标注数据的领域。
不过,究竟有多大实际意义,能应用到哪些现实领域,李昕教授表示“还前途未卜”,“下围棋本身是一个比较局限的应用,人类觉得下围棋很复杂,但是对于机器来说并不难。而且,下围棋只是一种娱乐方式,不算作人们在生活中遇到的实际问题。”
那么,谷歌的AI为什么会选择围棋?
据《第一财经》报道,历史上,电脑最早掌握的第一款经典游戏是井字游戏,这是1952年一位博士在读生的研究项目;随后是1994年电脑程序Chinook成功挑战西洋跳棋游戏;3年后,IBM深蓝超级计算机在国际象棋比赛中战胜世界冠军加里•卡斯帕罗夫。
除了棋盘游戏外,IBM的Watson系统在2011年成功挑战老牌智力竞赛节目Jeopardy游戏一战成名;2014年,Google自己编写的算法,学会了仅需输入初始像素信息就能玩几十种Atari游戏。
但有一项游戏仍然是人类代表着顶尖水平,那就是围棋。
谷歌DeepMind创始人兼CEO Demis Hassabis博士曾在2016年AlphaGo对阵李世石时就做过说明,有着3000多年历史的围棋是人类有史以来发明出来的最复杂的游戏,对于人工智能来说,这是一次最尖端的大挑战,需要直觉和计算,要想熟练玩围棋需要将模式识别和运筹帷幄结合。
“围棋的搜索空间是漫无边际的——比围棋棋盘要大1个古戈尔(数量级单位,10的100次方,甚至比宇宙中的原子数量还要多)。”因此,传统的人工智能方法也就是“为所有可能的步数建立搜索树”,在围棋游戏中几乎无法实现。
而打败了人类的AlphaGo系统的关键则是,将围棋巨大无比的搜索空间压缩到可控的范围之内。David Silver博士此前曾介绍,策略网络的作用是预测下一步,并用来将搜索范围缩小至最有可能的那些步骤。另一个神经网络“价值网络(valuenetwork)”则是用来减少搜索树的深度,每走一步估算一次游戏的赢家,而不是搜索所有结束棋局的途径。
李昕教授对阿尔法元带来的突破表示欣喜,但同时他也提到,“阿尔法元证明的只是在下围棋这个游戏中,无监督学习(unsupervised learning)比有监督学习(supervised learning)‘更优’,但并未证明这就是‘最优’方法,也许两者结合的semi-supervised learning,也就是在不同时间和阶段,结合有监督或无监督学习各自的优点,可以得到更优的结果。”
李昕教授说,人工智能的技术还远没有达到人们所想象的程度,“比如,互联网登录时用的reCAPTCHA验证码(图像或者文字),就无法通过机器学习算法自动识别”,他说,在某些方面,机器人确实比人做得更好,但目前并不能完全替换人。“只有当科研证明,一项人工智能技术能够解决一些实际问题和人工痛点时,才真正算作是一个重大突破。”
昆山杜克大学常务副校长、中美科技政策和关系专家丹尼斯·西蒙(Denis Simon)博士在接受澎湃新闻采访时表示,阿尔法元在围棋领域的成功说明它确实有极大的潜力。阿尔法元通过与自身对弈实现了自身能力的提升,每一次它都变得更聪明,每一次棋局也更有挑战性。这种重复性的、充分参与的学习增强了阿尔法元处理更高层次的、战略复杂问题的能力。但缺点是这是一个封闭的系统。“阿尔法元如何能够超过自身的局限获得进一步的成长?换句话说,它能跳出框框思考吗?”
AI科学家详解AlphaGo Zero的伟大与局限

AlphaGo Zero
(文章来源:量子位 报道 | 公众号 QbitAI 作者:夏乙 李根 发自 凹非寺 )
“人类太多余了。”
面对无师自通碾压一切前辈的AlphaGo Zero,柯洁说出了这样一句话。

如果你无法理解柯洁的绝望,请先跟着量子位回顾上一集:
今年5月,20岁生日还未到的世界围棋第一人柯洁,在乌镇0:3败给了DeepMind的人工智能程序AlphaGo,当时的版本叫做Master,就是今年年初在网上60:0挑落中日韩高手的那个神秘AI。
AlphaGo Zero骤然出现,可以说是在柯洁快要被人类对手和迷妹们治愈的伤口上,撒了一大把胡椒粉。
被震动的不止柯洁,在DeepMind的Nature论文公布之后,悲观、甚至恐慌的情绪,在大众之间蔓延着,甚至有媒体一本正经地探讨“未来是终结者还是黑客帝国”。
于是,不少认真读了论文的人工智能“圈内人”纷纷站出来,为这次技术进展“去魅”。
无师自通?
首当其冲的问题就是:在AlphaGo Zero下棋的过程中,人类知识和经验真的一点用都没有吗?
在这一版本的AlphaGo中,虽说人类的知识和经验没多大作用,但也不至于“多余”。
在Zero下棋的过程中,并没有从人类的对局经验和数据中进行学习,但这个算法依然需要人类向它灌输围棋的规则:哪些地方可以落子、怎样才算获胜等等。
剩下的,就由AI自己来搞定了。
对于这个话题,鲜有人比旷视科技首席科学家孙剑更有发言权了,因为AlphaGo Zero里面最核心使用的技术ResNet,正是孙剑在微软亚洲研究院时期的发明。

孙剑
孙剑也在接受量子位等媒体采访的过程中,对AlphaGo Zero的“无师自通”作出了评价,他认为这个说法“对,也不对”,并且表示“伟大与局限并存”。
究竟对不对,还是取决于怎样定义无师自通,从哪个角度来看。
和之前三版AlphaGo相比,这一版去掉了人类教授棋谱的过程,在训练过程最开始的时候,AI落子完全是随机的,AlphaGo团队的负责人David Silver透露,它一开始甚至会把开局第一手下在1-1。在和自己对弈的过程中,算法才逐渐掌握了胜利的秘诀。
从这个角度来看,Zero的确可以说是第一次做到了无师自通,也正是出于这个原因,DeepMind这篇Nature论文才能引起这么多圈内人关注。
但要说它是“无监督学习”,就有点“不对”。孙剑说:“如果仔细看这个系统,它还是有监督的。”它的监督不是来自棋谱,而是围棋规则所决定的最后谁输谁赢这个信号。
“从这个意义上说,它不是百分之百绝对的无师自通,而是通过这个规则所带来的监督信号,它是一种非常弱监督的增强学习,它不是完全的无师自通。”
孙剑还进一步强调:“但是同时这种无师自通在很多AI落地上也存在一些局限,因为严格意义上讲,围棋规则和判定棋局输赢也是一种监督信号,所以有人说人类无用、或者说机器可以自己产生认知,都是对AlphaGo Zero错误理解。”
离全面碾压人类有多远?

Zero发布之后,媒体关切地询问“这个算法以后会用在哪些其他领域”,网友认真地担心“这个AI会不会在各个领域全面碾压人类”。
对于Zero算法的未来发展,DeepMind联合创始人哈萨比斯介绍说,AlphaGo团队的成员都已经转移到其他团队中,正在尝试将这项技术用到其他领域,“最终,我们想用这样的算法突破,来解决真实世界中各种各样紧迫的问题。”
DeepMind期待Zero解决的,是“其他结构性问题”,他们在博客中特别列举出几项:蛋白质折叠、降低能耗、寻找革命性的新材料。
哈萨比斯说AlphaGo可以看做一个在复杂数据中进行搜索的机器,除了博客中提到几项,新药发现、量子化学、粒子物理学也是AlphaGo可能大展拳脚的领域。
不过,究竟哪些领域可以扩展、哪些领域不行呢?
孙剑说要解释AlphaGo算法能扩展到哪些领域,需要先了解它现在所解决的问题——围棋——具有哪些特性。
首先,它没有噪声,是能够完美重现的算法;
其次,围棋中的信息是完全可观测的,不像在麻将、扑克里,对手的信息观测不到;
最后也是最重要的一点,是围棋对局可以用计算机迅速模拟,很快地输出输赢信号。
基于对围棋这个领域特性的理解,提到用AlphaGo算法来发现新药,孙剑是持怀疑态度的。
他说,发现新药和下围棋之间有一个非常显著的区别,就是“输赢信号”能不能很快输出:“新药品很多内部的结构需要通过搜索,搜索完以后制成药,再到真正怎么去检验这个药有效,这个闭环非常代价昂贵,非常慢,你很难像下围棋这么简单做出来。”
不过,如果找到快速验证新药是否有效的方法,这项技术就能很好地用在新药开发上了。
而用AlphaGo算法用来帮数据中心节能,孙剑就认为非常说得通,因为它和围棋的特性很一致,能快速输出结果反馈,也就是AlphaGo算法依赖的弱监督信号。
当然,从AlphaGo算法的这些限制,我们也不难推想,它在某些小领域内可以做得非常好,但其实并没有“全面碾压人类”的潜力。
去魅归去魅,对于AlphaGo Zero的算法,科研人员纷纷赞不绝口。
大道至简的算法
在评价Zero的算法时,创新工场AI工程院副院长王咏刚用了“大道至简”四个字。
简单,是不少人工智能“圈内人”读完论文后对Zero的评价。刚刚宣布将要跳槽伯克利的前微软亚洲研究院首席研究员马毅教授就发微博评论说,这篇论文“没有提出任何新的方法和模型”,但是彻底地实现了一个简单有效的想法。

为什么“简单”这件事如此被学术圈津津乐道?孙剑的解释是“我们做研究追求极简,去除复杂”,而Zero的算法基本就是在前代基础上从各方面去简化。
他说,这种简化,一方面体现在把原来的策略网络和价值网络合并成一个网络,简化了搜索过程;另一方面体现在用深度残差网络(ResNet)来对输入进行简化,以前需要人工设计棋盘的输入,体现“这个子下过几次、周围有几个黑子几个白子”这样的信息,而现在是“把黑白子二值的图直接送进来,相当于可以理解成对着棋盘拍照片,把照片送给神经网络,让神经网络看着棋盘照片做决策”。
孙剑认为,拟合搜索和ResNet,正是Zero算法中的两个核心技术。
其中拟合搜索所解决的问题,主要是定制化,它可以对棋盘上的每一次落子都进行量化,比如会对最终获胜几率做多大贡献,但是这其实并不是近期才产生的一种理论,而是在很早之前就存在的一种基础算法理论。
而另一核心技术是最深可达80层的ResNet。总的来说,神经网络越深,函数映射能力就越强、越有效率,越有可能有效预测一个复杂的映射。
下围棋时要用到的,就是一个非常复杂的映射,神经网络需要输出每个可能位置落子时赢的概率,也就是最高要输出一个361维的向量。这是一个非常复杂的输出,需要很深的网络来解决。
人类棋手下棋,落子很多时候靠直觉,而这背后实际上有一个非常复杂的函数,Zero就用深层ResNet,拟合出了这样的函数。
ResNet特点就是利用残差学习,让非常深的网络可以很好地学习,2015年,孙剑带领的团队就用ResNet把深度神经网络的层数从十几二十层,推到了152层。
也正是凭借这样的创新,孙剑团队拿下了ImageNet和MSCOCO图像识别大赛各项目的冠军。到2016年,他们又推出了第一个上千层的网络,获得了CVPR最佳论文奖。
而令孙剑更加意料之外的是,ResNet还被AlphaGo团队看中,成为AlphaGo Zero算法中的核心组件之一。
这位Face++首席科学家表示很开心为推动整个AI进步“做了一点微小的贡献”,同时也很钦佩DeepMind团队追求极致的精神。
任剑还说,在旷视研究院的工作中,还会不断分享、开放研究成果,更注重技术在产业中的实用性,进一步推动整个AI产业的进步。
另外,还有不少AI大咖和知名科研、棋手对AlphaGo Zero发表了评价,量子位汇集如下:
大咖评说AlphaGo Zero
李开复:AI进化超人类想象,但与“奇点”无关
昨天AlphaGo Zero横空出世,碾压围棋界。AlphaGo Zero完全不用人类过去的棋谱和知识,就再次打破人类认知。很多媒体问我对AlphaGo Zero的看法,我的观点是:一是AI前进的速度比想象中更快,即便是行业内的人士都被AlphaGo Zero跌破眼镜;二是要正视中国在人工智能学术方面和英美的差距。
一方面,AlphaGo Zero的自主学习带来的技术革新并非适用于所有人工智能领域。围棋是一种对弈游戏,是信息透明,有明确结构,而且可用规则穷举的。对弈之外,AlphaGo Zero的技术可能在其他领域应用,比如新材料开发,新药的化学结构探索等,但这也需要时间验证。而且语音识别、图像识别、自然语音理解、无人驾驶等领域,数据是无法穷举,也很难完全无中生有。AlphaGo Zero的技术可以降低数据需求(比如说WayMo的数据模拟),但是依然需要大量的数据。
另一方面,AlphaGo Zero里面并没有新的巨大的理论突破。它使用的Tabula Rosa learning(白板学习,不用人类知识),是以前的围棋系统Crazy Stone最先使用的。AlphaGo Zero里面最核心使用的技术ResNet,是微软亚洲研究院的孙剑发明的。孙剑现任旷视科技Face++首席科学家。
虽然如此,这篇论文的影响力也是巨大的。AlphaGo Zero 能够完美集成这些技术,本身就具有里程碑意义。DeepMind的这一成果具有指向标意义,证明这个方向的可行性。在科研工程领域,探索前所未知的方向是困难重重的,一旦有了可行性证明,跟随者的风险就会巨幅下降。我相信从昨天开始,所有做围棋对弈的研究人员都在开始学习或复制AlphaGo Zero。材料、医疗领域的很多研究员也开始探索。
AlphaGo Zero的工程和算法确实非常厉害。但千万不要对此产生误解,认为人工智能是万能的,所有人工智能都可以无需人类经验从零学习,得出人工智能威胁论。AlphaGo Zero证明了AI 在快速发展,也验证了英美的科研能力,让我们看到在有些领域可以不用人类知识、人类数据、人类引导就做出顶级的突破。但是,AlphaGo Zero只能在单一简单领域应用,更不具有自主思考、设定目标、创意、自我意识。即便聪明如AlphaGo Zero,也是在人类给下目标,做好数字优化而已。这项结果并没有推进所谓“奇点”理论。
南大周志华:与“无监督学习”无关
花半小时看了下文章,说点个人浅见,未必正确仅供批评:
别幻想什么无监督学习,监督信息来自精准规则,非常强的监督信息。
不再把围棋当作从数据中学习的问题,回归到启发式搜索这个传统棋类解决思路。这里机器学习实质在解决搜索树启发式评分函数问题。
如果说深度学习能在模式识别应用中取代人工设计特征,那么这里显示出强化学习能在启发式搜索中取代人工设计评分函数。这个意义重大。启发式搜索这个人工智能传统领域可能因此巨变,或许不亚于模式识别计算机视觉领域因深度学习而产生的巨变。机器学习进一步蚕食其他人工智能技术领域。
类似想法以往有,但常见于小规模问题。没想到围棋这种状态空间巨大的问题其假设空间竟有强烈的结构,存在统一适用于任意多子局面的评价函数。巨大的状态空间诱使我们自然放弃此等假设,所以这个尝试相当大胆。
工程实现能力超级强,别人即便跳出盲点,以启发式搜索界的工程能力也多半做不出来。
目前并非普适,只适用于状态空间探索几乎零成本且探索过程不影响假设空间的任务。
Facebook田渊栋:AI穷尽围棋还早
老实说这篇Nature要比上一篇好很多,方法非常干净标准,结果非常好,以后肯定是经典文章了。
Policy network和value network放在一起共享参数不是什么新鲜事了,基本上现在的强化学习算法都这样做了,包括我们这边拿了去年第一名的Doom Bot,还有ELF里面为了训练微缩版星际而使用的网络设计。另外我记得之前他们已经反复提到用Value network对局面进行估值会更加稳定,所以最后用完全不用人工设计的defaultpolicy rollout也在情理之中。
让我非常吃惊的是仅仅用了四百九十万的自我对局,每步仅用1600的MCTS rollout,Zero就超过了去年三月份的水平。并且这些自我对局里有很大一部分是完全瞎走的。这个数字相当有意思。想一想围棋所有合法状态的数量级是10^170(见Counting Legal Positions in Go),五百万局棋所能覆盖的状态数目也就是10^9这个数量级,这两个数之间的比例比宇宙中所有原子的总数还要多得多。仅仅用这些样本就能学得非常好,只能说明卷积神经网络(CNN)的结构非常顺应围棋的走法,说句形象的话,这就相当于看了大英百科全书的第一个字母就能猜出其所有的内容。用ML的语言来说,CNN的inductivebias(模型的适用范围)极其适合围棋漂亮精致的规则,所以稍微给点样本水平就上去了。反观人类棋谱有很多不自然的地方,CNN学得反而不快了。我们经常看见跑KGS或者GoGoD的时候,最后一两个百分点费老大的劲,也许最后那点时间完全是花费在过拟合奇怪的招法上。
如果这个推理是对的话,那么就有几点推断。一是对这个结果不能过分乐观。我们假设换一个问题(比如说protein folding),神经网络不能很好拟合它而只能采用死记硬背的方法,那泛化能力就很弱,Self-play就不会有效果。事实上这也正是以前围棋即使用Self-play都没有太大进展的原因,大家用手调特征加上线性分类器,模型不对路,就学不到太好的东西。一句话,重点不在左右互搏,重点在模型对路。
二是或许卷积神经网络(CNN)系列算法在围棋上的成功,不是因为它达到了围棋之神的水平,而是因为人类棋手也是用CNN的方式去学棋去下棋,于是在同样的道路上,或者说同样的inductive bias下,计算机跑得比人类全体都快得多。假设有某种外星生物用RNN的方式学棋,换一种inductive bias,那它可能找到另一种(可能更强的)下棋方式。Zero用CNN及ResNet的框架在自学习过程中和人类世界中围棋的演化有大量的相似点,在侧面上印证了这个思路。在这点上来说,说穷尽了围棋肯定是还早。
三就是更证明了在理论上理解深度学习算法的重要性。对于人类直觉能触及到的问题,机器通过采用有相同或者相似的inductive bias结构的模型,可以去解决。但是人不知道它是如何做到的,所以除了反复尝试之外,人并不知道如何针对新问题的关键特性去改进它。如果能在理论上定量地理解深度学习在不同的数据分布上如何工作,那么我相信到那时我们回头看来,针对什么问题,什么数据,用什么结构的模型会是很容易的事情。我坚信数据的结构是解开深度学习神奇效果的钥匙。
另外推测一下为什么要用MCTS而不用强化学习的其它方法(我不是DM的人,所以肯定只能推测了)。MCTS其实是在线规划(online planning)的一种,从当前局面出发,以非参数方式估计局部Q函数,然后用局部Q函数估计去决定下一次rollout要怎么走。既然是规划,MCTS的限制就是得要知道环境的全部信息,及有完美的前向模型(forward model),这样才能知道走完一步后是什么状态。围棋因为规则固定,状态清晰,有完美快速的前向模型,所以MCTS是个好的选择。但要是用在Atari上的话,就得要在训练算法中内置一个Atari模拟器,或者去学习一个前向模型(forward model),相比actor-critic或者policy gradient可以用当前状态路径就地取材,要麻烦得多。但如果能放进去那一定是好的,像Atari这样的游戏,要是大家用MCTS我觉得可能不用学policy直接当场planning就会有很好的效果。很多文章都没比,因为比了就不好玩了。
另外,这篇文章看起来实现的难度和所需要的计算资源都比上一篇少很多,我相信过不了多久就会有人重复出来,到时候应该会有更多的insight。大家期待一下吧。
清华大学马少平教授:不能认为AI数据问题解决了
从早上开始,就被AlphaGo Zero的消息刷屏了,DeepMind公司最新的论文显示,最新版本的AlphaGo,完全抛弃了人类棋谱,实现了从零开始学习。
对于棋类问题来说,在蒙特卡洛树搜索的框架下,实现从零开始学习,我一直认为是可行的,也多次与别人讨论这个问题,当今年初Master推出时,就曾预测这个新系统可能实现了从零开始学习,可惜根据DeepMind后来透露的消息,Master并没有完全抛弃人类棋谱,而是在以前系统的基础上,通过强化学习提高系统的水平,虽然人类棋谱的作用越来越弱,但是启动还是学习了人类棋谱,并没有实现“冷”启动。
根据DeepMind透露的消息,AlphaGo Zero不但抛弃了人类棋谱,实现了从零开始学习,连以前使用的人类设计的特征也抛弃了,直接用棋盘上的黑白棋作为输入,可以说是把人类抛弃的彻彻底底,除了围棋规则外,不使用人类的任何数据和知识了。仅通过3天训练,就可以战胜和李世石下棋时的AlphaGo,而经过40天的训练后,则可以打败与柯洁下棋时的AlphaGo了。
真是佩服DeepMind的这种“把革命进行到底”的作风,可以说是把计算机围棋做到了极致。
那么AlphaGo Zero与AlphaGo(用AlphaGo表示以前的版本)都有哪些主要的差别呢?
1。在训练中不再依靠人类棋谱。AlphaGo在训练中,先用人类棋谱进行训练,然后再通过自我互博的方法自我提高。而AlphaGo Zero直接就采用自我互博的方式进行学习,在蒙特卡洛树搜索的框架下,一点点提高自己的水平。
2。不再使用人工设计的特征作为输入。在AlphaGo中,输入的是经过人工设计的特征,每个落子位置,根据该点及其周围的棋的类型(黑棋、白棋、空白等)组成不同的输入模式。而AlphaGo Zero则直接把棋盘上的黑白棋作为输入。这一点得益于后边介绍的神经网络结构的变化,使得神经网络层数更深,提取特征的能力更强。
3。将策略网络和价值网络合二为一。在AlphaGo中,使用的策略网络和价值网络是分开训练的,但是两个网络的大部分结构是一样的,只是输出不同。在AlphaGo Zero中将这两个网络合并为一个,从输入到中间几层是共用的,只是后边几层到输出层是分开的。并在损失函数中同时考虑了策略和价值两个部分。这样训练起来应该 会更快吧?
4。网络结构采用残差网络,网络深度更深。AlphaGo Zero在特征提取层采用了多个残差模块,每个模块包含2个卷积层,比之前用了12个卷积层的AlphaGo深度明显增加,从而可以实现更好的特征提取。
5。不再使用随机模拟。在AlphaGo中,在蒙特卡洛树搜索的过程中,要采用随机模拟的方法计算棋局的胜率,而在AlphaGo Zero中不再使用随机模拟的方法,完全依靠神经网络的结果代替随机模拟。这应该完全得益于价值网络估值的准确性,也有效加快了搜索速度。
6。只用了4块TPU训练72小时就可以战胜与李世石交手的AlphaGo。训练40天后可以战胜与柯洁交手的AlphaGo。
对于计算机围棋来说,以上改进无疑是个重要的突破,但也要正确认识这些突破。比如,之所以可以实现从零开始学习,是因为棋类问题的特点所决定的,是个水到渠成的结果。因为棋类问题一个重要的特性就是可以让机器自动判别最终结果的胜负,这样才可以不用人类数据,自己实现产生数据,自我训练,自我提高下棋水平。但是这种方式很难推广到其他领域,不能认为人工智能的数据问题就解决了。
对于计算机围棋来说,以上改进无疑是个重要的突破,但也要正确认识这些突破。比如,之所以可以实现从零开始学习,是因为棋类问题的特点所决定的,是个水到渠成的结果。因为棋类问题一个重要的特性就是可以让机器自动判别最终结果的胜负,这样才可以不用人类数据,自己实现产生数据,自我训练,自我提高下棋水平。但是这种方式很难推广到其他领域,不能认为人工智能的数据问题就解决了。
Rokid祝铭明:数据学习到评分方法学习的切换
Alpha Zero的文章有多少人认真看过,就在传无监督学习,这次有意思的是方法其实有点回归传统规则指导的思考模式。如果这个算是无监督学习,那几十年前就有了。只是这次是超大空间下的基于规则的决策树裁决评分,文章最有价值的是把之前数据学习变成了评分方法学习,这个其实有点意思,对于规则清晰问题可以大大减少数据依赖。
简单说这个就是如何通过学习,避免对超大规模搜索树的遍历,同时保证决策打分的合理性。其实有点白盒子的味道。这方法的确在很多规则简单清晰,但空间规模大的问题上有启发意义,而且从理论上来说肯定比之前的基于数据学习的要优秀很多,因为过去的方法仍然对经验数据依赖。不过和大家说的无监督学习是两码事。这么说大家都能理解了吧。
即将加入加州伯克利的马毅教授
熬夜读完AlphaGo zero的Nature论文,深有感触:我们一生与多少简单而又有效的想法失之交臂,是因为我们或者过早认为这些想法不值得去做或者没有能力或毅力正确而彻底地实现它们?这篇论文可以说没有提出任何新的方法和模型——方法可以说比以前的更简单“粗暴”。但是认真正确彻底的验证了这个看似简单的想法到底work不work。在做研究上,这往往才是拉开人与人之间差距的关键。
柯洁九段
一个纯净、纯粹自我学习的AlphaGo是最强的…对于AlphaGo的自我进步来讲…人类太多余了。
还有一些零散讨论:
微软全球资深副总裁、美国计算机协会(ACM)院士Peter Lee认为这是一个激动人心的成果,如果应用到其他领域会有很多前景。其中的理论与康奈尔大学计算机系教授、1986年图灵奖获得者John Hopcroft之前下国际象棋的工作相似,而且Deepmind之前做的德州扑克比围棋搜索空间更大、更难。不过受限规则下的围棋跟现实世界的应用场景有天壤之别,现在的自动驾驶、商业决策比游戏复杂很多。
John Hopcroft提到了他常说的监督学习和非监督学习,因为给大量数据标标签是一件非常难的事情。他还说,现在AI还在工程阶段,我们先是把飞机飞向天,此后才理解了空气动力学。AI现在能告诉你是谁,未来能告诉你在想什么,再之后会有理论解释为什么这能工作。
美国人工智能学会(AAAI)院士Lise Getoor认为,在监督学习和非监督学习之上还有结构化学习,如何让机器发现可能是递归的ontological commitment。我们现在的深度学习模型可能存在structure bias。
杨强教授没有说话,不过AlphaGo Zero论文刚一发布,他担任理事会主席的国际人工智能大会(IJCAI)就为这支团队颁发了第一枚马文·明斯基奖章,可谓最高赞许。
AlphaGo从零开始自学围棋为什么能成功
不要片面强调说人类知识没用,还不如零知识。Master与AlphaGo Zero从算法层面看,差距很小。
陈经
2017年10月19日
(本文原发于观察者网:AlphaGo从零开始自学围棋为什么能成功)
一。AlphaGo从零开始自学习新版本算法框架与等级分表现
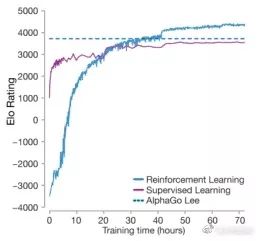
2017年10月18日,业界非常期待的AlphagGo新论文终于在《自然》上发表了。Deepmind开发了一个名为AlphaGo Zero的新版本,它只用一个策略与价值合体的神经网络下棋,从随机走子开始自我对弈学习,完全不需要人类棋谱。新的强化学习策略极为高效,只用3天,AlphaGo Zero就以100:0完全击败了2016年3月轰动世界的AlphaGo Lee。经过21天的学习,它达到了Master的实力(而Master在2017年5月3:0胜人类第一柯洁)。
40天后,它能以90%的胜率战胜Master,成为目前最强的围棋程序。而且AlphaGo Zero的计算过程中直接由神经网络给出叶子节点胜率,不需要快速走子至终局,计算资源大大节省,只需要4个TPU就行(AlphaGo Lee要48个)。

从Goratings棋力等级分上看,AlphaGo Zero其实和Master还能比较,只多个300多分。这相当于论文发表当天,人类第一柯洁九段的3667分与第38名的人气主播孟泰龄六段3425分的分差,两人肯定实力有差距,但也还有得下。论文公布了AlphaGo Zero的83局棋谱,其中与Master下的有20局,Master在第11局还胜了一局。
AlphaGo新版本从零开始训练成功,这个结果大大出乎了我的预料,相信也让业界不少人感到震惊。我本来是预期看到Master的算法解密,为什么它能碾压人类高手。AlphaGo退役让人以为Deepmind不研究围棋了,剩下任务是把Master版本的算法细节在《自然》公布出来,腾讯的绝艺等AI就可以找到开发方向突破目前的实力瓶颈了。
本来5月的乌镇围棋大会上说,6月新论文就能出来了,开发者们可以参考了。至于从零知识开始学习,是个有趣的想法,2016年3月人机大战胜李世石后就有这样的风声,人们期待这个“山洞中左右互搏”的版本出来,与人类的下法是不是很不相同,如开局是不是会占天元?但是后来一直好像没进展,乌镇也没有提。
好几个月了,新论文一直没出来。绝艺明显进入发展瓶颈,总是偶而会输给人,还输给了DeepZenGo与CGI。各个借鉴AlphaGo的AI都迫切需要Deepmind介绍新的思路与细节。到8月跑出来一篇AlphaGo打星际争霸的论文,从零知识开始学,学人类录像打,两种办法都不太行。
这时我认为让AlphaGo从零知识开始学可能不太成功,会陷入局部陷阱,人类棋谱能提供一个“高起点”,高水平AI还是需要人类的“第一推动”。
实际是Deepmind团队认为,仅仅写Master对于《自然》级别的文章不够震憾。新的论文标题是 “Mastering the Game of Go without Human Knowledge”,这个主题升华就足够了。而Master用人类棋谱训练了初始的策略网络,人类知识还是有影响,虽然后来自学习提升后人类影响很小了。对于不懂围棋或者对算法细节不关心的人,Master相比AlphaGo Lee无非是棋力更强一些,战胜的柯洁与李世石都是顶级高手没本质区别,Master的创新性也需要懂围棋才能明白。
AlphaGo Zero是真正的从零开始训练,整个学习过程与人类完全没有关系,全是自己学,这个哲学意义还是很大的。过程中与人或者其它版本下,只是验证棋力不是学招。
二。真正的算法突破是Master版本实现的
可以认为,在技术上从AlphaGo Lee进步到Master是比较难的,需要真正的变革,神经网络架构需要大变,强化学习过程也要取得突破。绝艺、DeepZenGo等AI开发就一直卡在这个阶段,突破不了AlphaGo Lee的水平,总是出bug偶尔输给人,离Master差距很大。
但如果Master的开发成功了,再去试AlphaGo Zero就是顺理成章的事。如果它能训练成功,应该是比较快的事,实际不到半年顶级论文就出来了,回头看是个自然的进展。Deepmind团队在五月后应该是看到了成功的希望,于是继续开发出了AlphaGo Zero,新论文虽然推迟了,但再次震惊了业界。
也可以看出,2016年Deepmind《自然》论文描述的强化学习过程,整个训练流水线比较复杂,要训练好几种神经网络的系数,进化出一个新版本需要几个星期。用这个训练流水线,从零开始强化学习,应该是意义不大,所以一直没有进展。
但是Master的自学习过程取得了重大突破,之前从人类棋谱开始训练2个月的水平,改进后只要一星期就行了,学习效率,以及能够达到的实力上限都有了很大进展。以此为基础,再把从零开始引进来,就能取得重大突破。所以Deepmind真正的技术突破,应该是开发Master时取得的。AlphaGo Zero是Master技术成果的延续,但看上去哲学与社会意义更重大。
Master与AlphaGo Zero的成功,是机器强化学习算法取得巨大发展的成果与证明。训练需要的局数少了,490万局就实现了AlphaGo Lee的水平。而绝艺到2017年3月就已经自我对弈了30亿局,实力一直卡着没有重大进步,主要应该是强化学习技术上有差距。
我在2017年1月9日写的《AlphaGo升级成Master后的算法框架分析》文中进行了猜测:
从实战表现反推,Master的价值网络质量肯定已经突破了临界点,带来了极大的好处,思考时间大幅减少,搜索深度广度增加,战斗力上升。AlphaGo团队新的prototype,架构上可能更简单了,需要的CPU数目也减少了,更接近国际象棋的搜索框架,而不是以MCTS为基础的复杂框架。比起国际象棋AI复杂的人工精心编写的局面评估函数,AlphaGo的价值网络完全由机器学习生成,编码任务更为简单。
理论上来说,如果价值网络的估值足够精确,可以将叶子节点价值网络的权重上升为1.0,就等于在搜索框架中完全去除了MCTS模块,和传统搜索算法完全一样了。这时的围棋AI将从理论上完全战胜人,因为人能做的机器都能做,而且还做得更好更快。而围棋AI的发展过程可以简略为两个阶段。第一阶段局面估值函数能力极弱,被逼引入MCTS以及它的天生弱点。第二阶段价值网络取得突破,再次将MCTS从搜索框架逐渐去除返朴归真,回归传统搜索算法。
从新论文的介绍来看, 这个猜测完全得到了证实。Master和AlphaGo Zero的架构确实更简单了,只需要4个TPU。AlphaGo Zero到叶子节点就完全不用rollout下完数子了,直接用价值网络(已经与策略网络合并)给出胜率,就等于是“价值网络的权重上升为1.0”。Master有没有rollout没有明确说,从实战表现看应该是取消了。
当然新论文中还是将搜索框架称为“MCTS”,因为有随机试各分支,但这不是新东西,和传统搜索差异不算大。对围棋来说,2006年引入MCTS算法真正的独特之处是从叶子节点走完数子,代替难以实现的评估函数。
这种疯狂的海量终局模拟更像是绝望之下的权宜之计,也把机器弄得很疲惫。但是Master与AlphaGo Zero都成功训练出了极为犀利的价值网络,从而又再次将rollout取消。价值网络的高效剪枝,让Master与AlphaGo Zero的判断极为精确,从而算得更为深远战斗力极为强大。这个价值网络怎么训练出来,就是现在Deepmind的独门绝技。可以说,新论文最有价值的就是这个部分。
从Master开始,AlphaGo的网络结构应该就有大变了。到AlphaGo Zero,将价值与策略网络合为一个,这并不奇怪。因为第一篇论文中,就明确说价值与策略网络的架构是完全一样的,只是系数不同。那么二者共用一个网络也不奇怪,前面盘面特征表述应该是一样的,等需要不同的输出时再分出不同的系数。Master网络结构大变之后,也许Deepmind发现,许多盘面特征都可以训练出来,所以就简单将盘面输入简化成黑白。
AlphaGo Zero的强化学习过程,应该与Master差不多,都是成功地跳出了陷阱,不断提升到超乎人类想象的程度。Master从研发上来说,像一个探路先锋,证明了这条路是可以跑通的,能把等级分增加1000分。而AlphaGo Zero,像是一个更为精减的过程,本质是与Master类似的。
新论文中的AlphaGo Zero确实显得架构优美。只需要一个网络,既告诉机器可以下哪,也能给出局面的胜率。盘面输入就是黑白,也不需要任何人类知识。强化学习就是两招,搜索的结果好于神经网络直觉想下的点,可以用于策略选点的训练,一盘下完的结果回头用于修正胜率,都很自然。但是为了实现这个优美结果,需要勇敢的探索。一开始的AlphaGo并没有这么优美,路跑通了,才想到原来可以做得更简单。
本文再提出一个猜测:现在的绝艺、DeepZenGo等AI实力接近AlphaGo Lee了,但都经常出现死活bug,会怎么出和人类对手的实力关系不大,并不是对手等级分高的它就容易出bug,基本是自己莫明其妙送死。这个bug的原因是rollout模块带来的,因为rollout策略是人类棋谱训练出来的,也可能有人工加代码打补丁。
它的目的是快速下完终局,但如果牵涉到死活,这种快速下完就不太可靠了,活的下死,死的杀活。但是,怎么实现不出错的rollout,这非常困难,应该是不可能完成的任务。Master和AlphaGo Zero的办法,是取消这个不可靠的rollout,直接让神经网络给出结果。如果神经网络给出的胜率结果有问题,那就靠训练来解决。这样纠错,强过程序员去排查rollout代码里出了什么错。
三。机器与人类对围棋的适应能力差异很大
Master和AlphaGo Zero的突破说明,在极高的水平上,需要考虑出现瓶颈的原因。人类棋谱能够提供一个“高起点”,但是机器从零开始训练一两天也就追上了,带来的“先发优势”没多少。而人类棋谱中显然有一些“有害成分”,这可能将AI的学习过程带歪。如果AI不能找到消除这些“人类病毒”的办法,那训练就会陷入瓶颈。如下图,零知识强化学习的版本实力迅速追上有人类棋谱帮忙的。
从围棋本身看,它的规则几乎是所有游戏中最优美最简单的。规则就是两句话可以了,气尽提子,禁全同(打劫的由来)。甚至贴目这样的胜负规则都是人类强加的,围棋游戏不需要胜负规则就可以成为一个定义明确的游戏。打砖块这样的Atari游戏就是这样,目标就是打到更高的分。围棋游戏的目标可以是占更多的地,结果可能是黑183、184、185子这样,不需要明确说出黑胜黑负。黑白博弈,会有一个上帝知道的“均衡”结果,猜测可能是黑184子白177子,或者黑184.5白176.5(有眼双活)。
这是一个优美的博弈问题,是掌握了强化学习方法的AI最喜欢的游戏,规则这么简单,太容易了。最终强大的围棋AI,应该是自然的,开发只依靠原始规则,不需要其它的信息了。AlphaGo Zero应该已经接近了这个目标,除了中国规则强加的7.5目的贴目。也许以后可以让AlphaGo不考虑贴目了,黑白都直接优化占地的多少,不再以胜率为目标,说不定能训练出一个更优秀的AI。如优势时不会退让了,劣势时也不自杀。这次Master与AlphaGo Zero一些局终局输定时就表现得很搞笑,有时摇头劫死棋打个没完。
AlphaGo Zero的棋力提升过程非常流畅,说明围棋精致的规则形成的数学空间很优美,神经网络很快就能抓住围棋空间的特征,表现得非常适应。而这种神经网络与围棋空间的适应性,是之前人们没有想到的,因为人自己感觉很困难,没料到神经网络学习起来美滋滋。
AlphaGo Zero能从零开始训练成功,也是因为围棋的绝对客观性。围棋规则如此自洽,不需要人类干预,就能很容易地自我对弈出结果,直接解决了“学习样本”这个大问题。人工智能机器学习碰上的很大问题就是需要海量样本,而实际生活中有时只有少量样本,有时需要人工标注很麻烦。
围棋的对局天然在那了,AlphaGo Zero的任务就是找到合适的学习方法,没有样本的问题。而人类既无法自我产生海量对局,也无法像AI那样目标明确地快速改进自己的脑神经,单位时间学习效率被AI完全碾压。所以围棋是更适合AI去学习的游戏。人类的学习方法也许还是适合人的,但AI学习方法更强。
对于围棋这么自然而且绝对客观的游戏,消除人类的影响应该从哲学上来说是有深度的想法。从围棋规则来看,日韩规则对AI简直是不可理解,甚至无法定义,未来肯定会消亡。而人类的棋谱是客观的,但对棋谱的解读是主观的。主观的东西就可能出错,这要非常小心。
对于人类的知识体系也是如此。客观世界的运行是与人无关的,人对客观世界的解读就是主观的,很可能带入了错误的东西。所以,有时需要返回到客观世界进行本原观察,而不是在错误的知识体系上进入所谓的“推理与搜索”。客观上不成立,什么都完了。经济学道理写得再雄辩,实践中失败了就不行。

另一方面,也不要片面强调说人类知识没用,还不如零知识。实际上Master与AlphaGo Zero的差距从算法层面看,并不太大。二者300分的等级差距,也许不是Master开始学了人类棋谱带来的,也许是更精细的网络架构、训练过程的小细节之类的影响。Master其实找到办法跳出了人类知识的陷阱。
因此,可以说人类知识可能存在问题,但不要说学了人类知识就没法到高境界。意识到旧知识体系的问题,作出突破就可以了。而且人类没法和机器比,不可能真从零知识开始疯狂自己下,没那个体力。现实的选择只有学习前辈的经验。也许AlphaGo的意义是说,要有一个知识体系,这个知识体系可以是自己学出来并检验的,也可以是Master那样借鉴了别人的,但要接受实践检验,也要敢于怀疑突破成见。
四。AlphaGo Zero的实战表现
虽然AlphaGo Zero完全与人类棋谱无关了,但是也许会让棋手们欣慰的是,它下得其实很像人。训练没几个小时就下得非常像人了,也是从角上开始,这方面的判断和人是一致的。
而且它甚至比Master还要像人类棋手,显得比较正义。Master不知道为什么喜欢出怪异的手段,棋谱极为难懂,对人类而言更为痛苦,打又打不过,看也看不懂。AlphaGo Zero对Master的棋谱结果是19:1,感觉上AlphaGo Zero战胜Master的招数不是以怪制怪,而是用正招去应付,然后Master的强招碰上正义的力量就失败了。而人类对Master应错了,就输了。也许是因为,Master训练到后来,为了提高胜率走上了剑走偏锋的路线,出怪招打败之前的版本,而同一版本的黑白是同等实力,以怪对怪正好实力相当,维持了半目胜负。碰上AlphaGo Zero就失去了这种平衡,被正义的招数镇压。

图为AlphaGo Zero执黑对Master。Master气势汹汹54位飞,要吃掉黑三子。在Master与人类棋手的计算中,以及解说的这盘棋的绝艺看来(腾讯围棋经常有绝艺配合人类棋手解说棋局的节目),黑这三子应该是被吃了,要考虑弃子。但是AlphaGo Zero不这么认为。
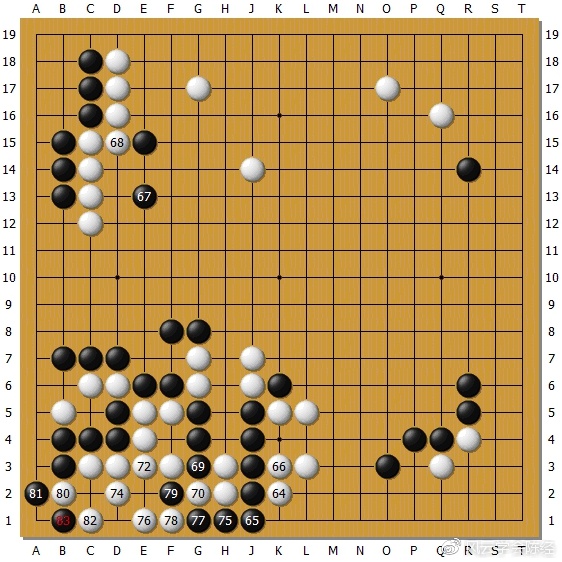
黑棋AlphaGo Zero在左下角将白棋做成了打劫杀。遭此打击,Master就此陷入被动。这说明Master的计算也不一定毫无破绽,只是碰上算得更深的才被抓住。这个计算手数很长,出现错误也可以理解。这也说明Master以及AlphaGo Zero从算法原理看,都可能会被抓住计算错误,仍然有进步空间。一度我被Master的极限对局吓住了,以为围棋的终极奥义可能就是这种看不懂的死掐。
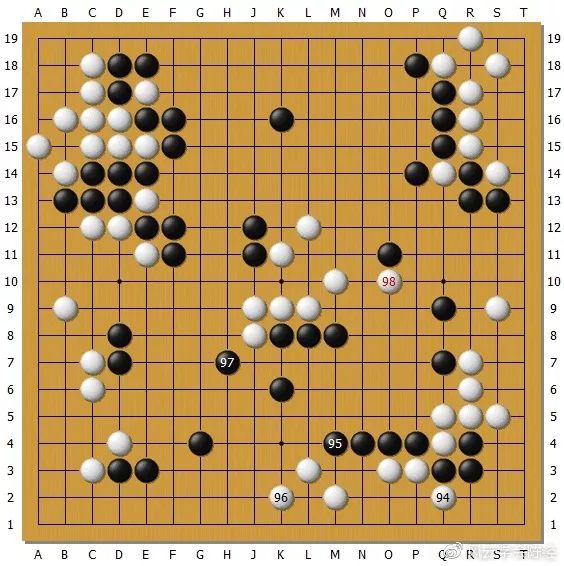
AlphaGo Zero执白对Master。这是双方对局的常见局面,白AlphaGo Zero捞足了实地,Master的中央模样像纸糊的一样被打破,败下阵来。

AlphaGo Zero自战。胜率落后的黑用129的手筋撑住了局势,但最后还是胜率越来越低失败了。
应该说AlphaGo Zero的棋谱还是较为自然的,虽然中盘显然很复杂,但不像Master那样完全看不懂心生恐惧。对于人类棋手来说,AlphaGo Zero会更为亲切,它就像一个最高水平的人类棋手,下得是意图可以说清楚的棋,只是永远正确,不像人类低手这错那错。而Master的自战谱就显得不可理解,蛮不讲理,动不动就搞事,撑得很满步步惊心搞极限对局,人类看得很晕。
围棋AI应该还是在发展过程中,自我对弈容易显得较死劲,实力有差距就会显得一方潇洒自然。围棋的状态空间还很大,应该还能有更厉害的版本一级级发展出来,就像国际象棋AI仍然在不断进步。
当然对Master以及AlphaGo Zero的棋谱,需要人类高手们配合AI的后台数据来解读。AlphaGo Zero这个不需要人类知识的AI棋手,再次给人类提供了不同风格的棋谱,让棋坛越来越精彩。而且Deepmind的这篇论文提供了优美简洁的开发方法,更容易模仿成功,会有越来越多高水平的AI取得突破。
[本文来自微信公众号“棋道经纬”]