书接上回,在前些章节提到过公司最近购置了一台 A6000 算力服务器。 现在老板发话了,要用那台服务器做“人工智能+”应用。
我这边主要负责开源大模型(以下简称“llm”)问答和提供实时推理 API 接口。此外,数据资产管理工作也是归我这边。需要对开业以来的交易数据、业务数据、视频、音频等数据进行清洗入库,并结合 llm 打造一套 RAG(检索增强生成)应用。
稍微吐槽一下- 14 年 Java 老兵从此转型为 Python 新兵。不过还好我也拥抱变化,技多不压身嘛;
- 只有一张 A6000 是没办法做大数据模型训练了(接受现实吧),能够让老板最快看出效果的估计也只有 RAG 吧(顺便自己也能够积累一下经验);
- 其实有很多第三方工具能够实现私有化 RAG 的,但考虑到后期要申请软件著作权、API 接口扩展、数据切割的颗粒度等问题...最终还是选择自己写一个(老板对于最终目标还未明确,直接用第三方工具最后只会玩死自己);
- 不断迭代去做数据的清洗、脱敏、增强、对齐、校验、审查等工序真的很枯燥且漫长。虽然能够通过 Python + Ollama 实现一部分无监督数据处理工作,但是校验和审查涉及跨部门协作的,简直是不可控沟通起来费时费力。如果数据是公开的,我真建议选择阿里云或者腾讯云等云平台的线上数据清洗功能,不用像现在这么麻烦;
1. 现状
其实一开始我是没有一点头绪的(毕竟之前没有接触过)。但过往经验告诉我要找出性能问题,首先要知道性能瓶颈在哪里。而找“瓶颈”最直接的办法就是进行“性能压测”。
可是上网找了一圈,对于 llm 自身的测试、评估有很多文章能够参考,但对于 llm “并发性能”却很少有人说,大家普遍认为“算力不够就硬件来凑”。这跟 15、16 年前“水平集群”的概念相似:一个应用处理不了的并发通过反向代理做水平集群分摊到其他应用就可以了😂
也许这才是业界的解决方案吧。但我穷啊,没有更多资源给我只能从代码下手,看看这个 RAG 应用有哪些地方能优化的尽可能优化掉咯…实在没有办法,找不到现成的就自己写一个吧。
2. 分析
由于 llm 的数据流是通过 SSE(ServerSent Event)从服务端单向推送给客户端的,因此它与过往 HTTP 交互方式稍微有点区别。
题外话:llm 的打字机效果是有意为之的特效吗?
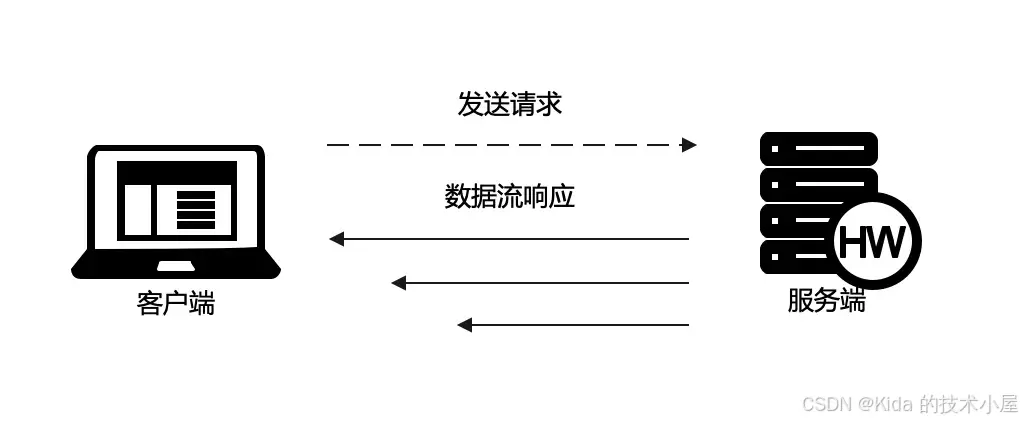
No,其实 llm 每次推理只能生成有限的 token。为了改善用户体验,这些 token 会采用 SSE 发送给前端(如上图所示 SSE 不是一次性的数据包,而是一个多次发送的数据流),最后前端监听到响应数据就进行逐字输出,这个效果就像打字机一样。而且在这个过程中 SSE 不要中断,一旦中断服务器就会关闭连接。
因此,压测程序必须适配 SSE 特性才行。但原生 SSE 只支持 GET 请求,这 GET 请求的限制想必各位都清楚。那么问题来了,SSE 要如何支持自定义参数和长上下文发送呢?
答案是对 SSE 进行一点点改造即可。最终是通过 POST 发送请求,服务端通过 content_type=‘text/event-stream’ 类型将数据推送到前端。伪代码如下图:
@app.route('/text-generation', methods=['POST'])
def text_stream():
...
def generate():
...
for chunk in pytorch_stream(prompt):
yield f"data: {json.dumps({'text': chunk['text']})}\n\n"
...
yield f"data: [DONE]\n\n"
return Response(generate(), content_type='text/event-stream')
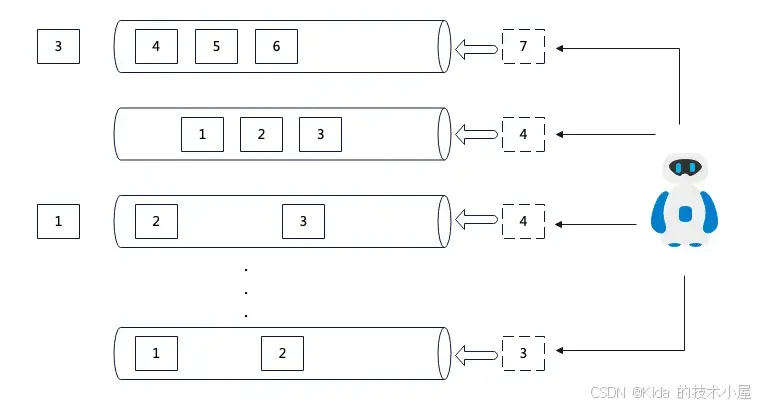
因此,压测程序设计构思如下图所示:
首先,生成 N 个“队列”,这些队列可以理解为“人数”,N 个队列就是 N 人并发。队列之间互不干扰,采用多线程进行控制。其次,队列中会存在一个或多个任务,任务之间采用串联方式执行(这是为了模拟人与 llm 对话场景且 SSE 推送不能中断),最后 Python 机器人会不断增派任务到队列中。
3. 实现
好了,问题来了。这个任务数是如何决定的呢?
其实任务数最终是通过“循环次数”和“持续时间”决定(这里参考了 JMeter)。当使用循环次数时,任务数 = 队列数 * 循环次数。而当使用持续时间时,任务数将无限制,队列将不断被增派任务直到持续时间结束。
最后编写出来的压测程序如下:
import threading
import queue
import time
import random
import json
import requests
...
def load_data_for_test():
"""
将测试数据从指定的JSON文件加载到全局变量中。
此函数从配置文件中检索测试数据的文件路径,
然后读取JSON内容并将其解析为一个名为“question_array”的全局列表。
全局变量:
question_array(list):一个用于存储从JSON文件加载的测试数据的列表。
"""
global question_array
pressure_file_path = os.path.join(pressure_config, yu.get_value_from_yaml(test_config, 'pressure.data-filename'))
with open(pressure_file_path, 'r', encoding='utf-8') as f:
# 遍历获取数组内容
question_array = json.load(f)
def sse_ask(url,data):
"""
使用给定的数据向指定的URL发送POST请求,期望得到服务器发送事件(SSE)响应。
此函数在数据到达时从服务器流式传输数据,生成每个完整的事件。
它逐行处理响应,收集数据,直到遇到空白行,
这表示事件的结束。事件由以“data:”开头的行标识。
当函数遇到“[DONE]”或响应不成功时,它将停止处理。
参数:
url(str):POST请求发送到的url。
data(dict):请求体中要发送的数据,编码为JSON。
"""
headers = {
'Accept': 'text/event-stream',
'Content-Type': 'application/json'
}
json_data = json.dumps(data)
response = requests.post(url, data=json_data, headers=headers, stream=True)
if response.status_code == 200:
buffer = ''
# 注意这里不要使用 decode_unicode=True 的自动解码
# 由于数据不是 GBK 会出现乱码,需要自己使用 decode 来解码
for line in response.iter_lines(decode_unicode=False):
line = line.decode('utf-8')
if line.startswith('data:'):
data = line[5:].strip()
if data == '[DONE]':
break
buffer += data
elif line.strip() == '':
if buffer:
yield buffer
buffer = ''
else:
raise Exception(f"请求失败,状态码:{response.status_code}")
def sse_totally(queue_id,task,user_id):
"""
向指定 URL 发送服务器发送事件 (SSE) 请求,并处理响应。
此函数构造一个包含用户ID和随机选择的问题的请求体
从预加载的列表中选择。它将请求发送到配置文件中指定的URL
并对接收的事件数据进行迭代,将每个事件打印到控制台。一旦所有
当事件被处理时,它会打印一条完成消息。
参数:
user_id (str): 发出请求的用户的 ID。
"""
url = yu.get_value_from_yaml(test_config, 'pressure.target-url')
# 自定义发送提问json,其中问题可以随机抽取(背靠公司业务数据库大胆提取)
request_body = {
"recommend": 0,
"user_id": user_id,
"us_id": '',
"messages": [{ "role": 'user', "content": random.choice(question_array) }]
}
# 监听返回数据进行输出
for event_data in sse_ask(url, request_body):
logger.info(f"Queue{queue_id}的{task}接收到事件数据:{event_data}")
logger.info(f"Queue{queue_id}的{task}数据传输已完成")
class TaskHandler(threading.Thread):
def __init__(self, q, stop_event, queue_id, completion_counter):
"""
初始化一个TaskHandler实例。
参数:
q (queue.Queue): 从其中获取任务的队列。
stop_event (threading.Event): 一个用于指示何时停止处理任务的事件。
queue_id (int):队列的标识符。
completion_counter (dict): 跟踪已完成任务数量的计数器。
属性:
running (bool): 任务处理程序当前是否正在运行的标志。
"""
super().__init__()
self.queue = q
self.stop_event = stop_event
self.queue_id = queue_id
self.completion_counter = completion_counter
self.running = True
def run(self):
"""
任务处理程序主循环。
在这个循环中,我们会不断地从队列中获取任务,并将其交由 process_task() 方法来处理。如果停止信号被设置,我们会清空队列并退出循环。
在处理每个任务时,我们会在完成任务后将其从队列中删除,并在 completion_counter 中增加完成任务的数量。
"""
while True:
# 在 duration 模式下,如果停止信号被设置,立即退出
if self.stop_event.is_set():
# 清空队列
while not self.queue.empty():
try:
self.queue.get_nowait()
self.queue.task_done()
except queue.Empty:
break
break
try:
# 缩短超时时间,使线程能更快响应停止信号
task = self.queue.get(timeout=0.1)
self.process_task(task)
self.queue.task_done()
with self.completion_counter.get_lock():
self.completion_counter.value += 1
except queue.Empty:
continue
def process_task(self, task):
logger.info(f"Queue {self.queue_id} processing {task}, start time: {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())}")
# 在处理任务时也要检查是否需要停止
if not self.stop_event.is_set():
user_id = int(yu.get_value_from_yaml(test_config, 'pressure.num-users'))
ran_user_id = random.randint(1, user_id)
sse_totally(self.queue_id,task,ran_user_id)
logger.info(f"Queue {self.queue_id} completed, end time: {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())}")
class TaskGenerator(threading.Thread):
def __init__(self, queues, stop_event, mode, limit, completion_counters, interval=1):
"""
任务生成器的构造函数。
该函数将创建一个任务生成器,用于在多个队列中生成任务。可以选择在 count 模式下生成指定数量的任务,或者在 duration 模式下生成任务直到达到指定的时间限制。
参数:
queues (list[queue.Queue]): 任务队列的列表。
stop_event (threading.Event): 一个用于指示何时停止生成任务的事件。
mode (str): 任务生成的模式,可能的值为 'count' 或 'duration'。
limit (int or float): 任务生成的限制,可能是一个数量限制(int)或一个时间限制(float,单位为秒)。
completion_counters (dict[threading.Value]): 一个字典,用于跟踪每个队列中完成的任务数量。
interval (int, optional): 任务生成的间隔时间(单位为秒),默认值为 1。
属性:
running (bool): 任务生成器当前是否正在运行的标志。
"""
super().__init__()
self.queues = queues
self.stop_event = stop_event
self.mode = mode
self.limit = limit
self.interval = interval
self.running = True
self.start_time = time.time()
self.task_counters = {i: 0 for i in range(len(queues))}
self.completion_counters = completion_counters
def run(self):
"""
任务生成器主循环。
在这个循环中,我们会不断地在队列中生成任务,直到达到制定的限制为止。
如果是 'count' 模式,我们会生成指定数量的任务,并在所有任务完成后停止。
如果是 'duration' 模式,我们会生成任务直到达到指定的时间限制为止。
在生成每个任务时,我们会在完成任务后将其从队列中删除,并在 completion_counter 中增加完成任务的数量。
"""
while not self.stop_event.is_set():
# 当模式选择了循环次数模式
if self.mode == 'count':
all_tasks_generated = True
# 遍历添加任务
for i, q in enumerate(self.queues):
if self.task_counters[i] < self.limit:
q.put(f"Task_{i}_{self.task_counters[i]}")
self.task_counters[i] += 1
all_tasks_generated = False
if all_tasks_generated:
all_completed = True
# 循环检测是否已经达成次数
for counter in self.completion_counters:
if counter.value < self.limit:
all_completed = False
break
# 确认完成这更改停止状态
if all_completed:
self.stop_event.set()
break
# 当模式选择了持续时间模式
elif self.mode == 'duration':
# 检查是否超过时间限制
if time.time() - self.start_time >= self.limit:
logger.info(f"Duration limit of {self.limit} seconds reached. Stopping all tasks...")
self.stop_event.set()
break
# 如果还在时间限制内,继续生成任务
for i, q in enumerate(self.queues):
q.put(f"Task_{i}_{self.task_counters[i]}")
self.task_counters[i] += 1
time.sleep(self.interval)
if __name__ == "__main__":
# 加载压测问题
load_data_for_test()
# 队列个数
num_queues = yu.get_value_from_yaml(test_config, 'pressure.num-queues')
# 创建队列数组
queues = [queue.Queue() for _ in range(num_queues)]
# 创建线程数组
threads = []
# 线程停止信号
stop_event = threading.Event()
import multiprocessing
completion_counters = [multiprocessing.Value('i', 0) for _ in range(num_queues)]
mode = yu.get_value_from_yaml(test_config, 'pressure.mode')
limit = yu.get_value_from_yaml(test_config, 'pressure.limit')
interval = yu.get_value_from_yaml(test_config, 'pressure.interval')
# 创建任务处理线程
for i, q in enumerate(queues):
thread = TaskHandler(q, stop_event, i, completion_counters[i])
threads.append(thread)
thread.start()
# 创建任务生成器线程
generator_thread = TaskGenerator(queues, stop_event, mode, limit, completion_counters, interval)
generator_thread.start()
# 等待任务生成器线程完成
generator_thread.join()
# 等待所有任务处理线程完成
for thread in threads:
thread.join()
# 打印最终统计信息
logger.info("Program completed!")
for i, counter in enumerate(completion_counters):
logger.info(f"Queue {i} completed {counter.value} tasks")
logger.info(f"Total run time: {time.time() - generator_thread.start_time:.2f} seconds")
上面的代码注释也写得相当清晰了(自认为),虽然没有像 JMeter、LoadRunner 那样能够直接提供数据分析,但大家可以配合 zabbix、nvtop 等工具一起使用,同样也能做到性能分析效果。
下一节我将为大家演示一下如何通过压测程序做基于 torch 驱动的 llm 性能优化,敬请期待。
4. 内容补充
为了能够将工具分享给有需要的人,我已经对工具代码进行重构并加入到 brain-mix 项目中,路径为:${project_path}/utils/pressure_util.py,有需要的小伙伴可以自取。
项目地址:https://github.com/yzh0623/brain-mix
(未完待续…)