文章中会用到的文件,如果官网下不了可以在这下
链接: https://pan.baidu.com/s/1SeRdqLo0E0CmaVJdoZs_nQ?pwd=xr76
提取码: xr76
一、 ES 环境搭建
注:环境搭建过程中的命令窗口不能关闭,关闭了服务就会关闭(除了修改设置后重启的)
● 安装 ES
ES 下载地址: https://www.elastic.co/cn/downloads/elasticsearch 默认打开是最新版本
7.6.1 版下载:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.1-windows-x86_64.zip
新建一个文件夹,重名为 ES ,将 elasticsearch-7.6.1-windows-x86_64.zip 解压
在 bin 目录中 双击启动 elasticsearch.bat

访问 http://127.0.0.1:9200
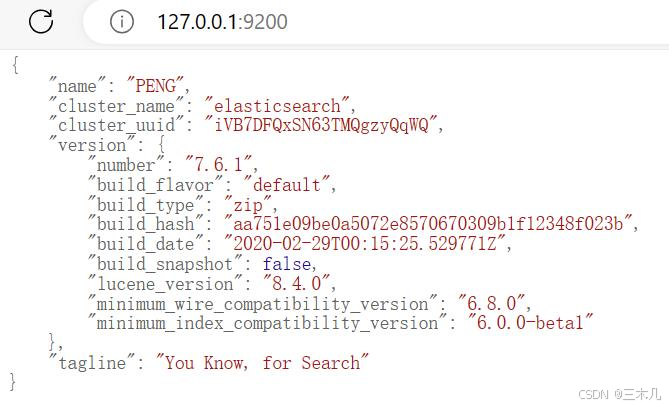
成功
● 安装数据可视化界面 elasticsearch head
前提需要安装 nodejs
github 下载 elasticsearch head : https://github.com/mobz/elasticsearch-head/
解压 elasticsearch-head-master.zip
从界面访问 9200 服务会出现跨域问题
在 es/elasticsearch-7.6.1/config 目录中的 elasticsearch.yml 文件最底下配置
# 开启跨域
http.cors.enabled: true
# 所有人访问
http.cors.allow-origin: "*"
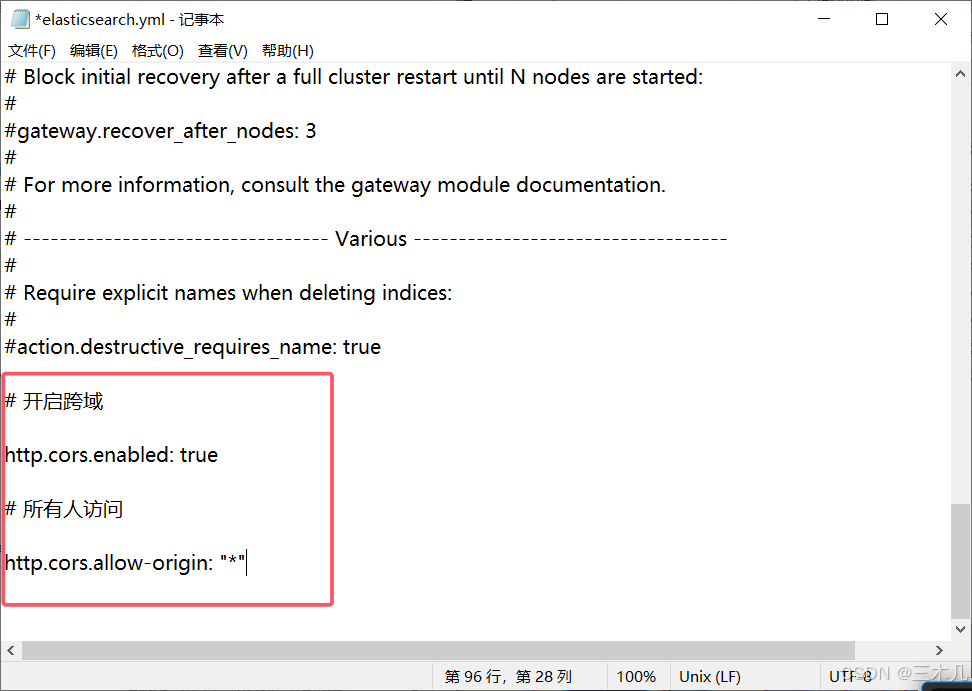
重启 elasticsearch (重新运行elasticsearch.bat)
命令行进入目录(在 \es\elasticsearch-head-master 中)
分别输入:
npm install
*回车
npm run start
*回车
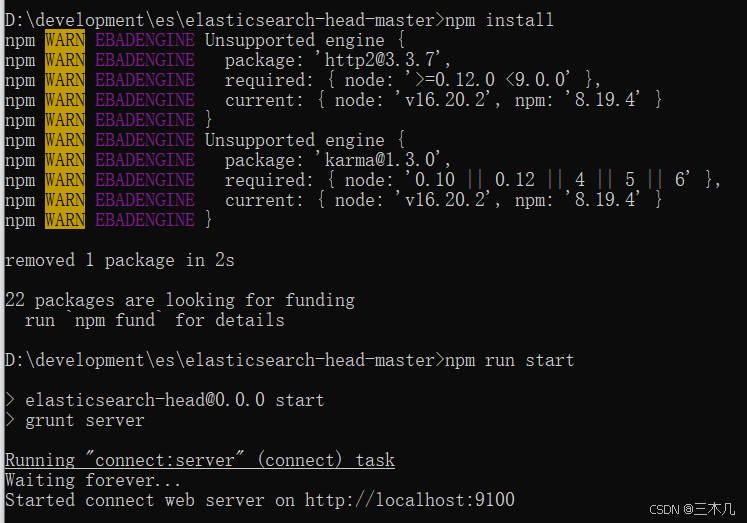
然后访问 http://localhost:9100 或 http://127.0.0.1:9100
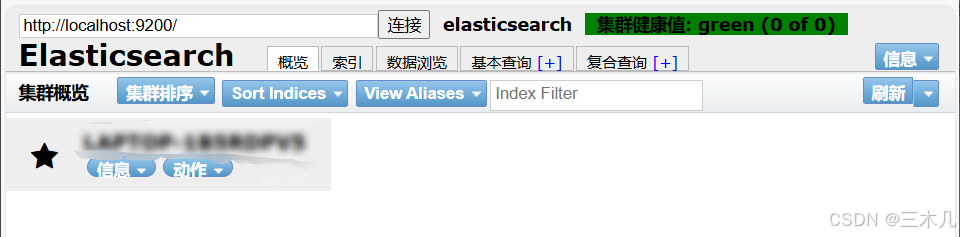
成功
● 安装可视化 kibana 组件
下载版本要和 ES 版本一致
下载地址https://www.elastic.co/cn/downloads/kibana: 默认打开是最新版本
7.6.1 下载版 :https://artifacts.elastic.co/downloads/kibana/kibana-7.6.1-windows-x86_64.zip
解压 kibana-7.6.1-windows-x86_64.zip,汉化 kibana
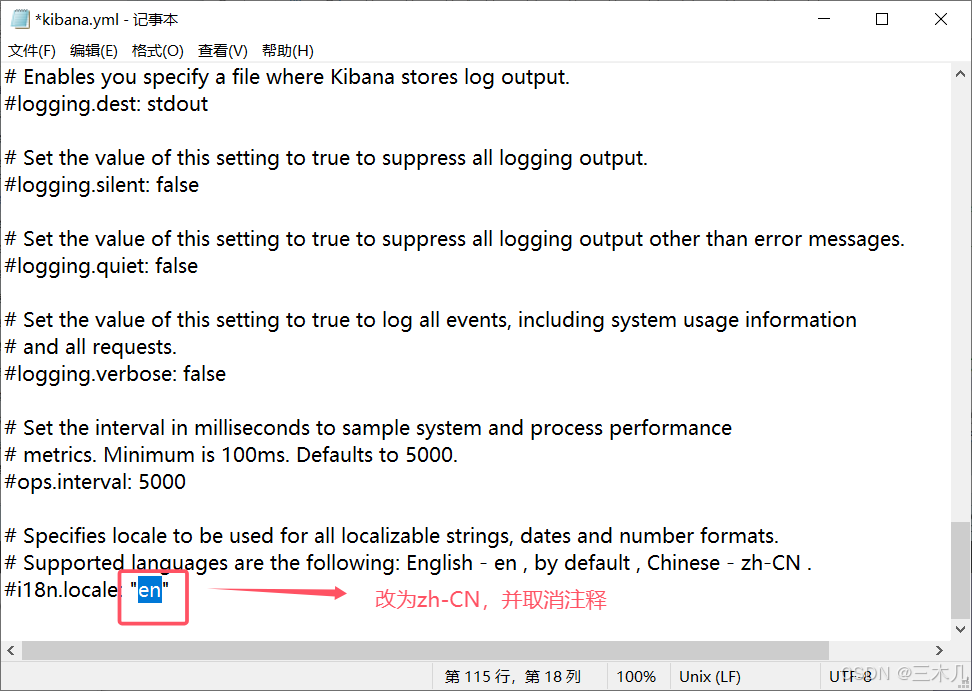
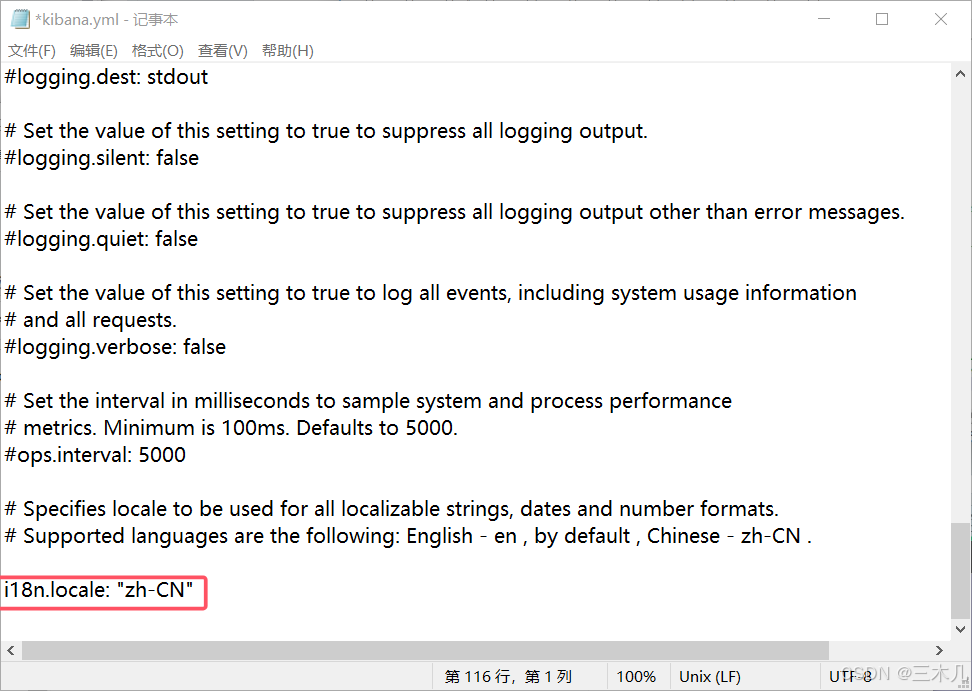
修改 \es\kibana-7.6.1-windows-x86_64\config 目录下的 kibana.yml 文件
i18n.locale: "zh-CN
双击 bin 目录下的 kibana.bat 启动
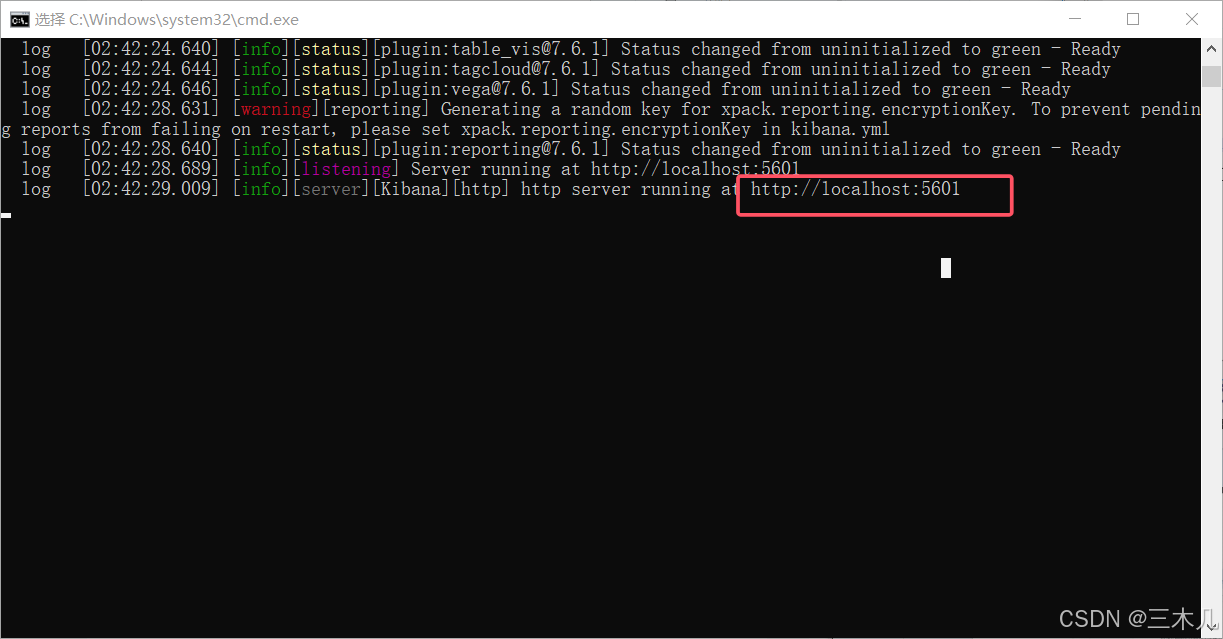
访问 http://localhost:5601 或 http://127.0.0.1:5601

● 安装 ik 分词器插件
解压 elasticsearch-analysis-ik-7.6.1.zip,在 \es\elasticsearch-7.6.1\plugins 目录下创建名称为ik的文件夹,将解压后的文件复制到 ik 目录。
自定义 ik 分词器(非必要,可以根据实际情况选择配置)
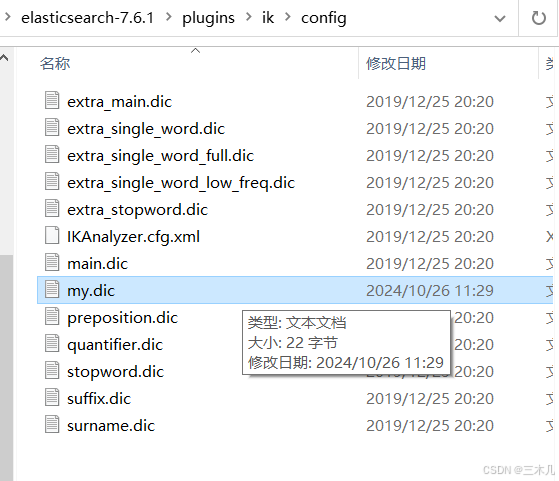
在 elasticsearch-7.6.1\plugins\ik\config
添加 xxx.dic 文件 定义词组
.dic 文件必须是 utf-8 编码格式,否则启动报错
在 IKAnalyzer.cfg.xml 文件添加自定义分词器文件

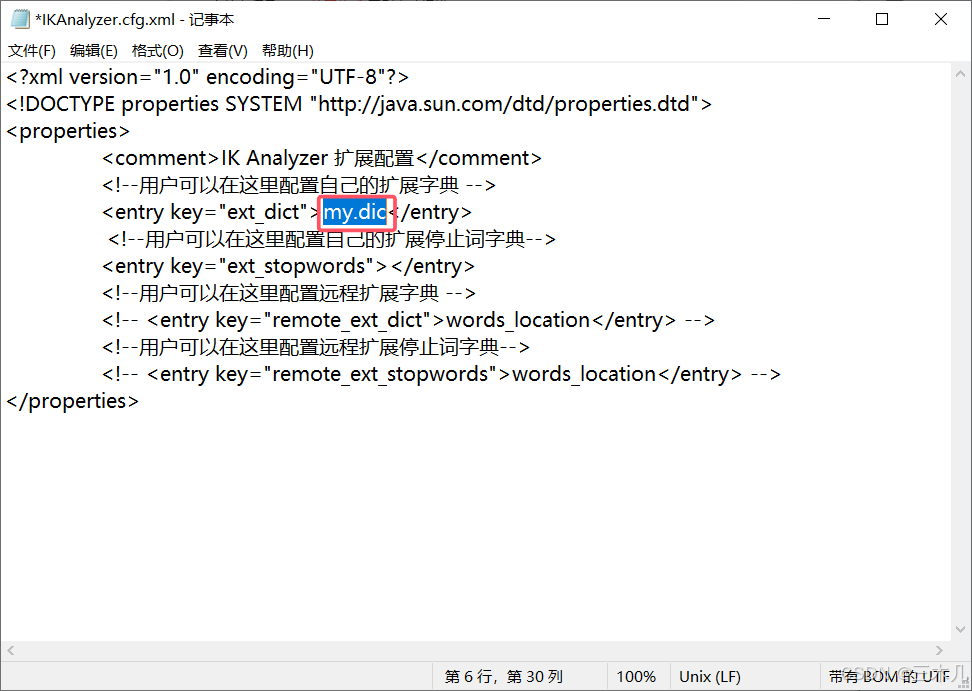
* 记得重启 elasticsearch
在 Kibana 中打开控制台
在没有安装 ik 分词器时
GET _analyze
{
"analyzer": "standard",
"text": "我是中国人"
}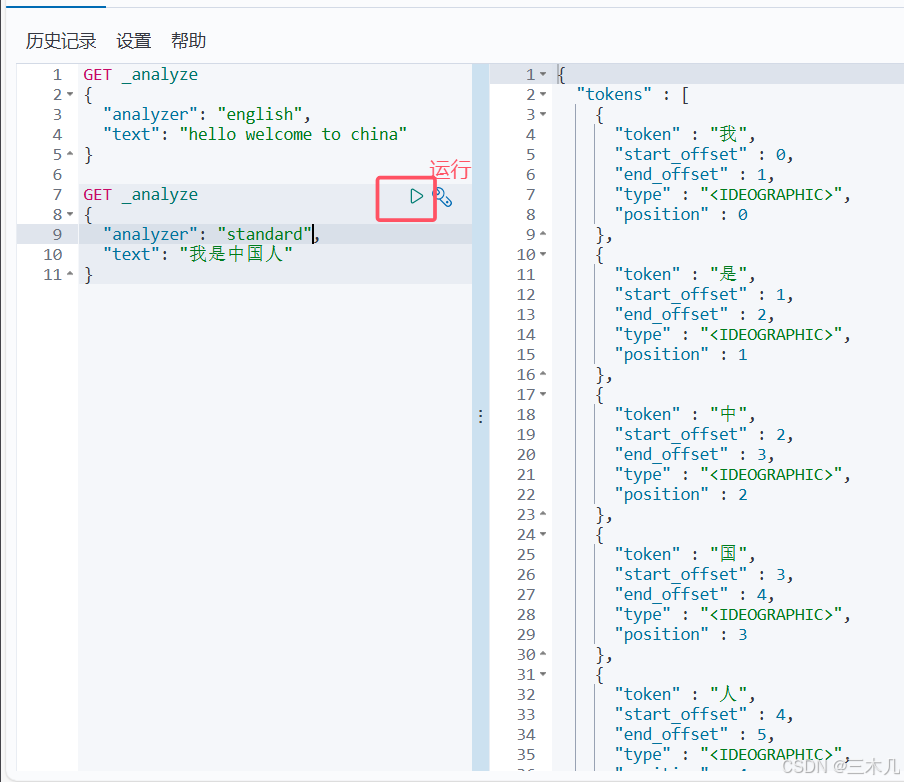
可以看到在没有启用 ik分词器时,分的关键词是单字为组的,不符合正常使用。
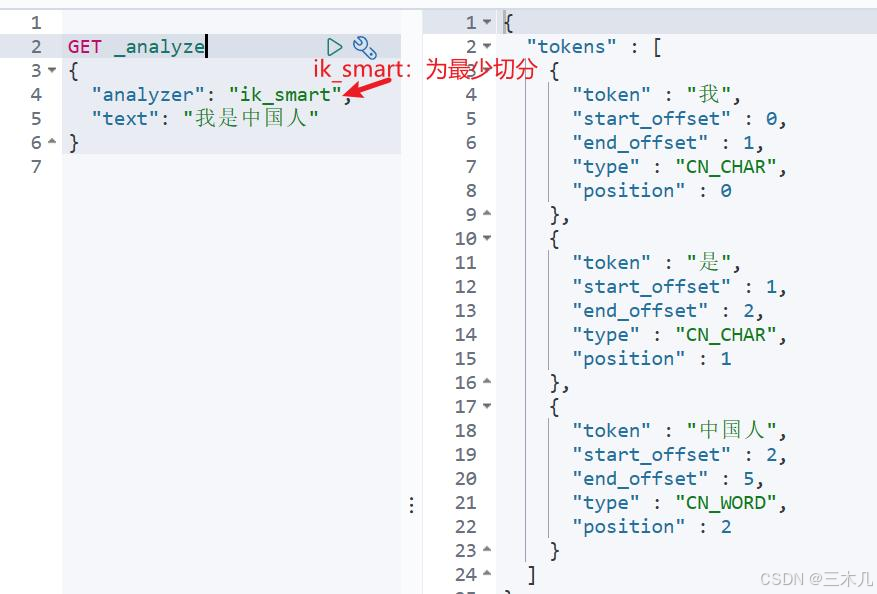
这是使用 ik分词器后的:
最少切分:
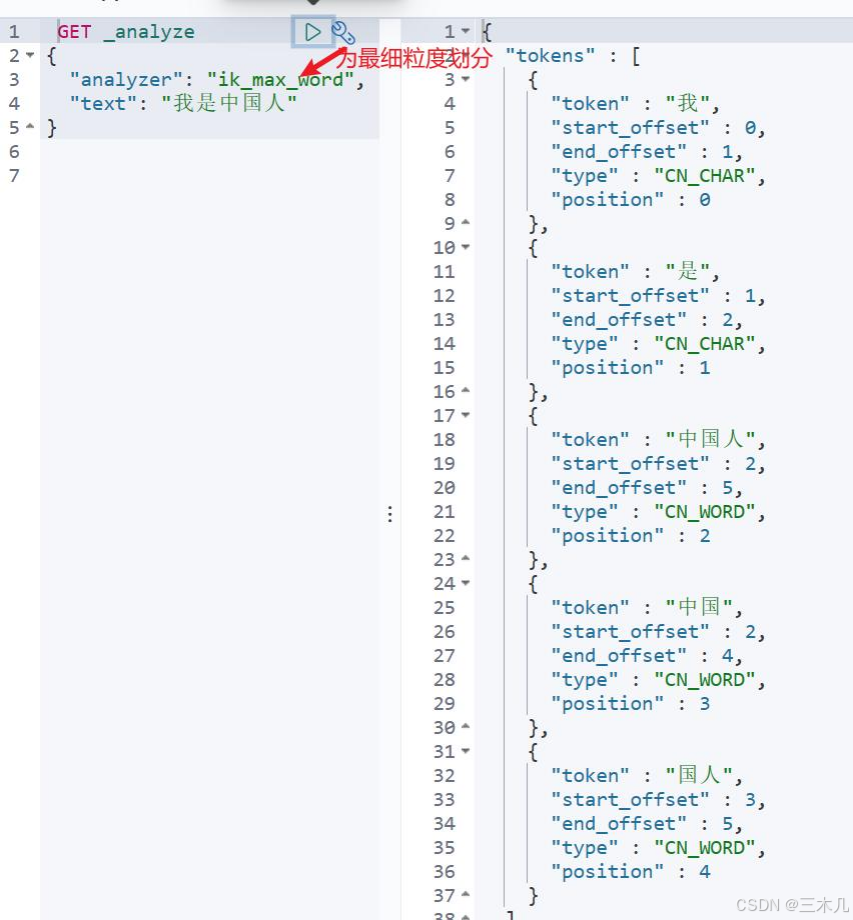
最细粒度划分:
二、 ES 基本概念
elasticsearch 是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为 json 格式后存储在 elasticsearch 中。
索引:同类型文档的集合
文档:一条数据就是一个文档,es 中是 Json 格式
字段:Json 文档中的字段
映射:索引中文档的约束,比如字段名称、类型

● 关系行数据库 MySQL 和 elasticsearch 对比

| MySQL | Elasticsearch | 说明 |
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| ROW | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| CoLumn | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
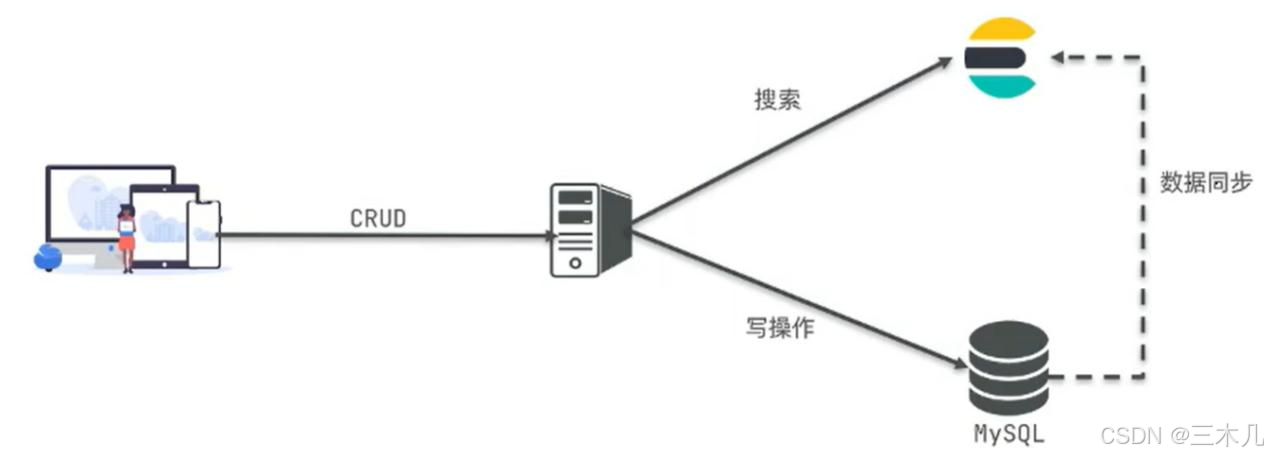
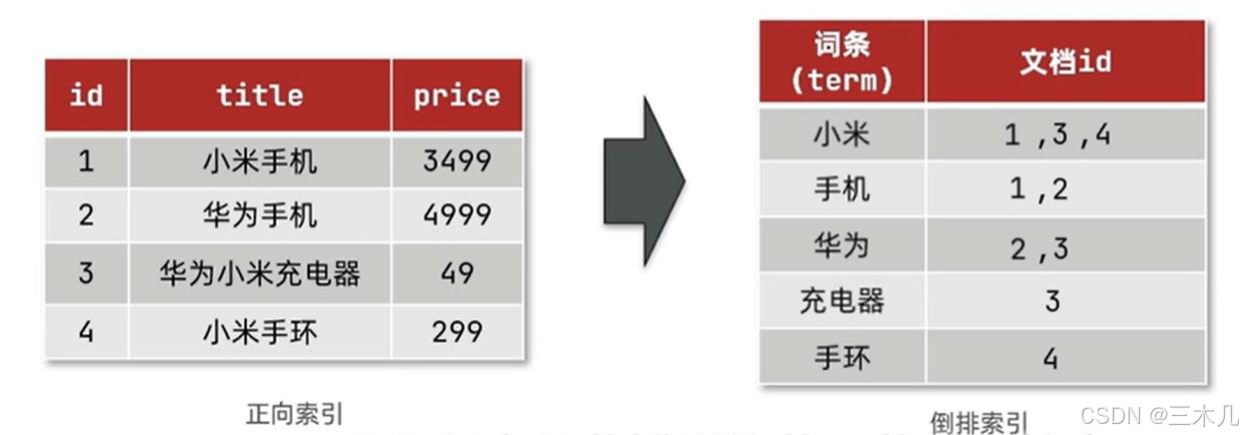
● 正向索引和倒排索引
Mysql 采用正向索引:基于文档 id 创建索引。查询词条时必须先找到文档,而判断是否包含搜索的内容. elasticsearch 采用倒排索引:
文档(document):每条数据就是一个文档
词条(term):文档按照语义分成的词语
三、 ES 索引库基本操作
● 创建索引库
mapping 属性 : mapping 是对索引库中文档的约束,常见的 mapping 属性包括:
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本),keyword(精确值,例如:品牌,国家,邮箱)
数值:long、integer、short、byte、double、float、
布尔:boolean
日期:date
对象:object
index:是否创建索引参与搜索,默认为 true,如果不需要参与搜索设置为 false
analyzer:使用哪种分词器
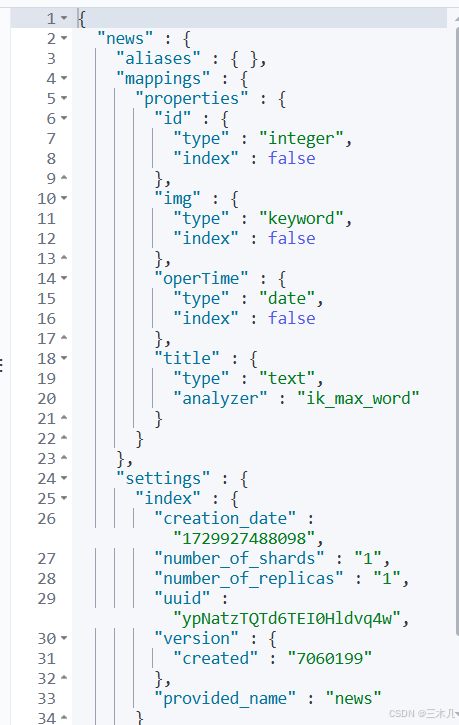
实例,创建一个新闻索引库:
PUT /news
{
"mappings": {
"properties": {
"id":{
"type": "integer",
"index": false
},
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"img":{
"type": "keyword",
"index": false
},
"operTime":{
"type": "date",
"index": false
}
}
}
}
● 查询索引库
语法: GET /索引库名
实例: GET /news
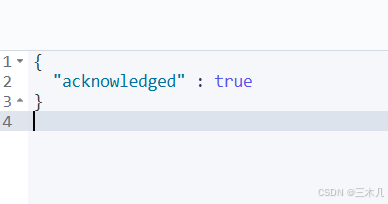
● 删除索引库
语法: DELETE /索引库名
实例: DELETE /news
● 修改索引库
索引库和 mapping 一旦创建无法修改(不能删除索引),但是可以添加新的字段,语法如下:
PUT /news/_mapping
{
"properties":{
"count":{
"type":"long"
}
}
}

四、 ES 文档操作
● 新增文档
语法:
POST /索引库名/_doc/文档 id
{
“字段名 1”:”值 1”
“字段名 2”:”值 2”
.....
}
POST /news/_doc/1
{
"id":1,
"title":"小米公司发布最新小米手机",
"img":"1111111111.jpg",
"dzcount":30
}POST /news/_doc/2
{
"id":2,
"title":"华为公司最新科技",
"img":"2222222222.jpg",
"dzcount":22
}● 查询文档
语法:
GET /索引库名/_doc/文档 id
GET /news/_doc/1● 删除文档
语法:
DELETE /索引库名/_doc/文档 id
DELETE /news/_doc/3● 修改文档
POST /索引库名/_update/文档 id
{
"doc":{
"要修改的字段":"新值"
}
}
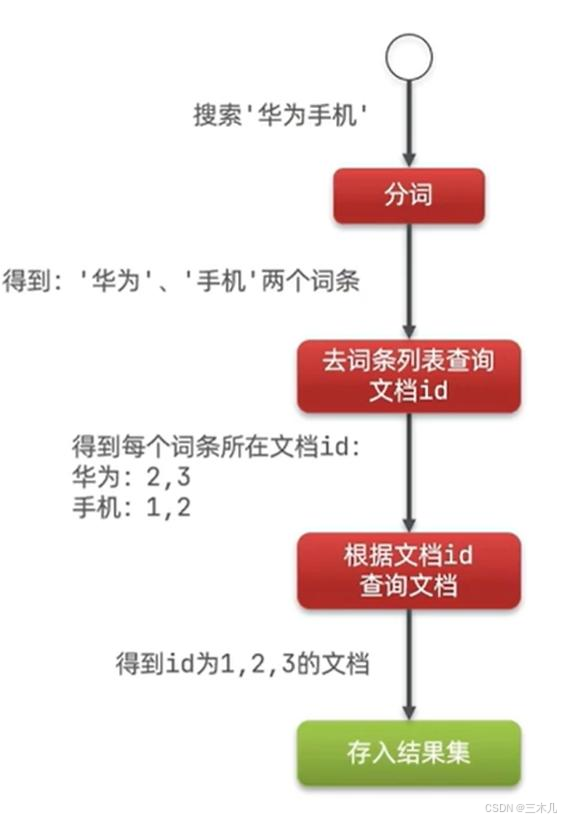
● 搜索文档(分词查询)
GET /news/_search
{
"query":{
"match":{
"title":"手机"
}
}
}
GET /news/_search
{
"query":{
"match":{
"title":"小米公司"
}
}
}
五、 SpringBoot 集成 ES
● 搭建
官网地址: https://www.elastic.co/guide/en/elasticsearch/client/index.html
指定版本,版本必须与安装的 ES 版本一致(在 pom.xml 中)
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
添加依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
添加初始化 RestHighLevelClient 的配置类
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
● 索引库操作
• 创建索引库
CreateIndexRequest request = new CreateIndexRequest("users");
CreateIndexResponsecreateIndexResponse = restHighLevelClient.indices().create(request,RequestOptions.DEFAULT);• 判断索引库是否存在
GetIndexRequest request = new GetIndexRequest("users");
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);• 删除索引库
DeleteIndexRequest indexRequest = new DeleteIndexRequest("users");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(indexRequest, RequestOptions.DEFAULT);
delete.isAcknowledged();//返回 true 删除成功,返回 false 删除失败新建一个 EStest.java 类
● 文档操作
• 添加文档
//将新闻添加到 mysql 的同时,将数据同步更新到 ES,为搜索提供数据
News news = new News();
news.setId(3);
news.setTitle("美国今年要总统选择,拜登着急了");
news.setImg("aaaaasssss.jpg");
IndexRequest indexRequest = new IndexRequest("news").id(news.getId().toString());
//将对象转为 json 存进 ES
indexRequest.source(new ObjectMapper().writeValueAsString(news),XContentType.JSON);
restHighLevelClient.index(indexRequest,RequestOptions.DEFAULT);• 修改文档
News news = new News();
news.setId(3);
news.setTitle("中国航母开往美国,准备开战,拜登着急了");
news.setImg("dddddddddddd.jpg");
UpdateRequest updateRequest = new UpdateRequest("news",news.getId().toString());
updateRequest.doc(new ObjectMapper().writeValueAsString(news), XContentType.JSON);
restHighLevelClient.update(updateRequest,RequestOptions.DEFAULT);• 查询文档
GetRequest getRequest = new GetRequest("news","1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//获取查询的内容,返回 json 格式
String json = getResponse.getSourceAsString();
//使用 jackson 组件将 json 字符串解析为对象
News news = new ObjectMapper().readValue(json, News.class);• 删除文档
DeleteRequest deleteRequest = new DeleteRequest("news","1");
DeleteResponse delete = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);• 搜索文档
SearchRequest searchRequest = new SearchRequest("news");
SearchRequest searchRequest = new SearchRequest("news");
//精确条件查询
searchRequest.source().query(QueryBuilders.termQuery("title","美国"));
//发送查询请求
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//接收查询结果
SearchHits hits = search.getHits();
//组装查询结果
ArrayList<News> list = new ArrayList<>();
//取出结果集
for (SearchHit searchHit : hits.getHits()){
String json = searchHit.getSourceAsString();
News news = new ObjectMapper().readValue(json,News.class);
list.add(news);
}