SSA-CNN-LSTM-MATT多头注意力机制多特征分类预测
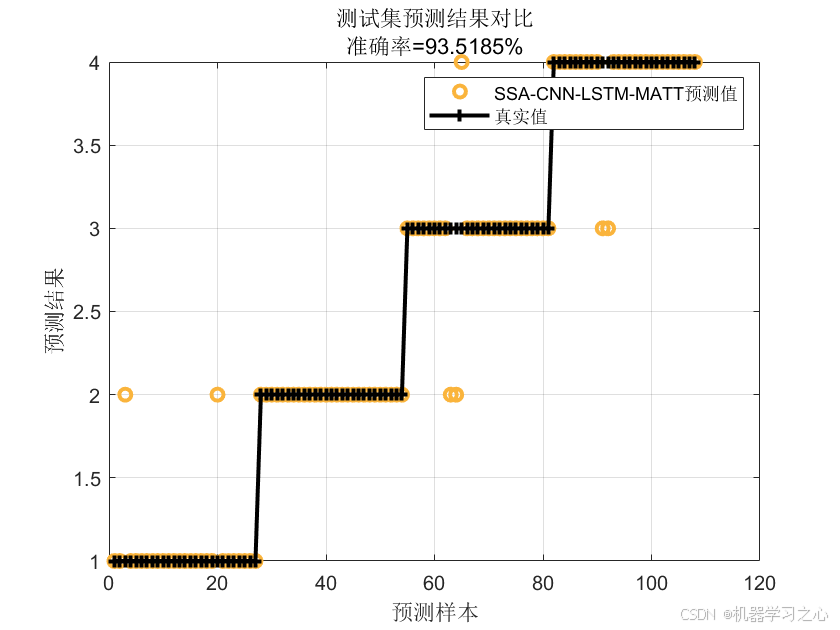
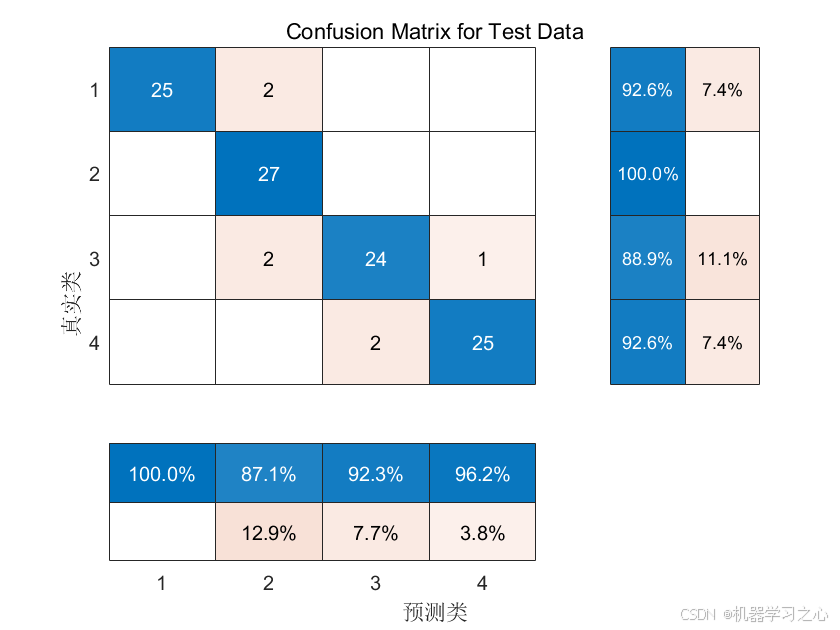
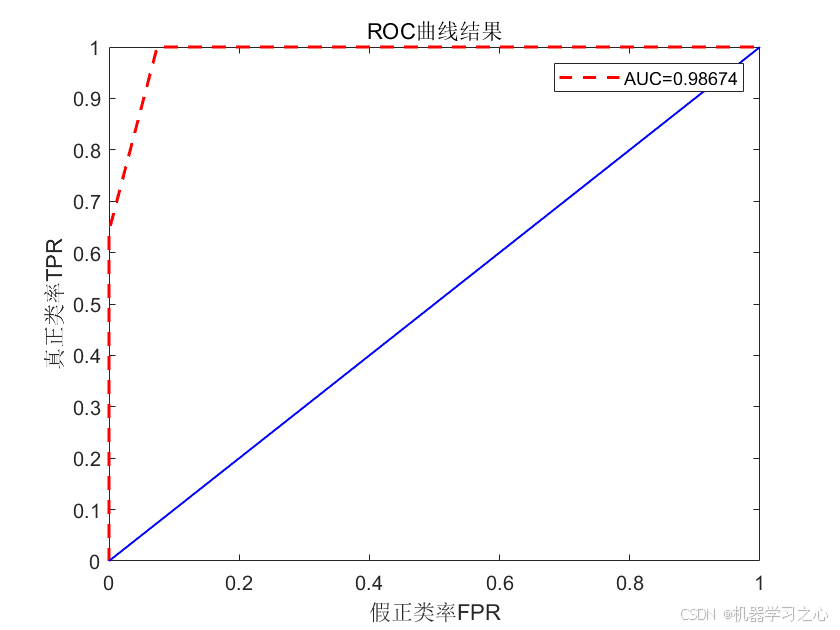
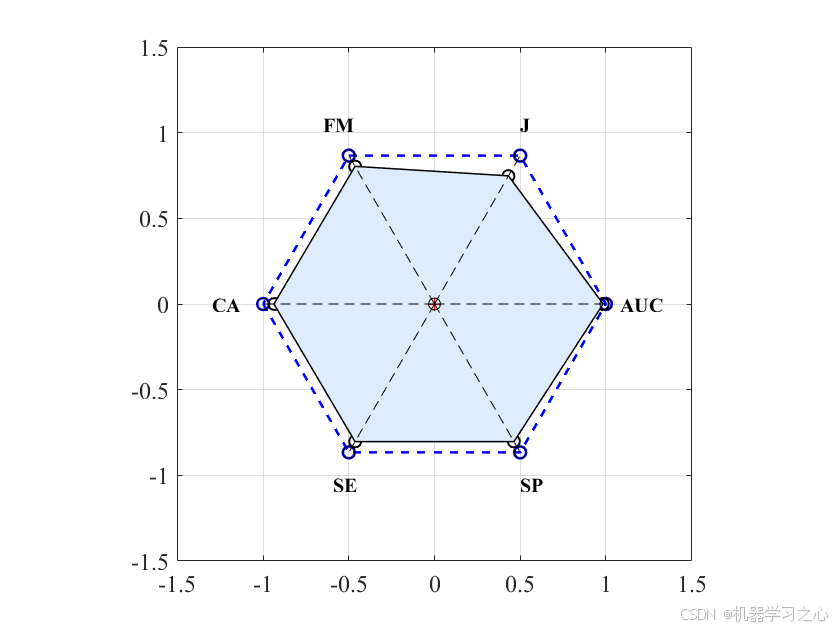
分类效果
基本介绍
1.Matlab实现SSA-CNN-LSTM-MATT麻雀算法优化卷积神经网络-长短期记忆神经网络融合多头注意力机制多特征分类预测,SSA-CNN-LSTM-Multihead-Attention;
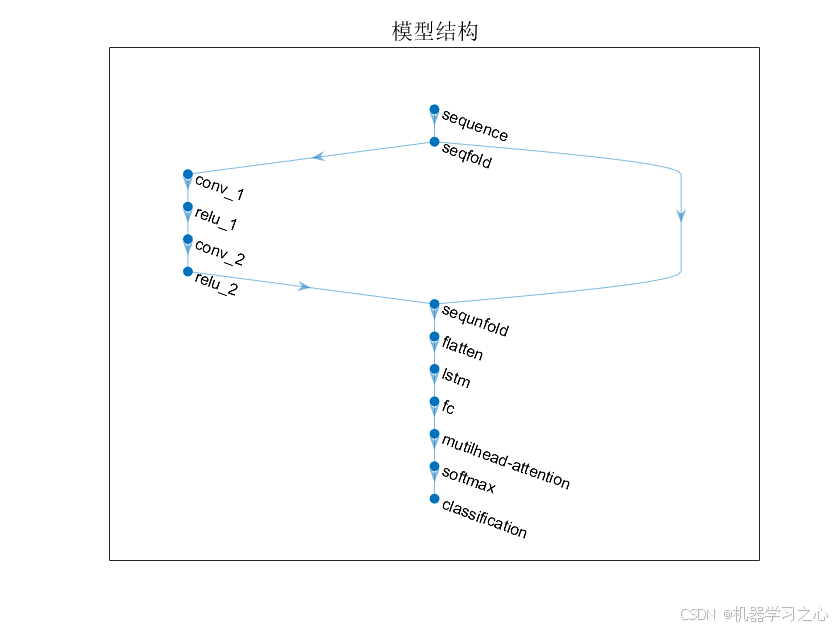
多头自注意力层 (Multihead-Self-Attention):Multihead-Self-Attention多头注意力机制是一种用于模型关注输入序列中不同位置相关性的机制。它通过计算每个位置与其他位置之间的注意力权重,进而对输入序列进行加权求和。注意力能够帮助模型在处理序列数据时,对不同位置的信息进行适当的加权,从而更好地捕捉序列中的关键信息。
2.数据输入12个特征,输出4个类别,main.m是主程序,其余为函数文件,无需运行;
3.优化参数为:学习率,隐含层节点,正则化参数;
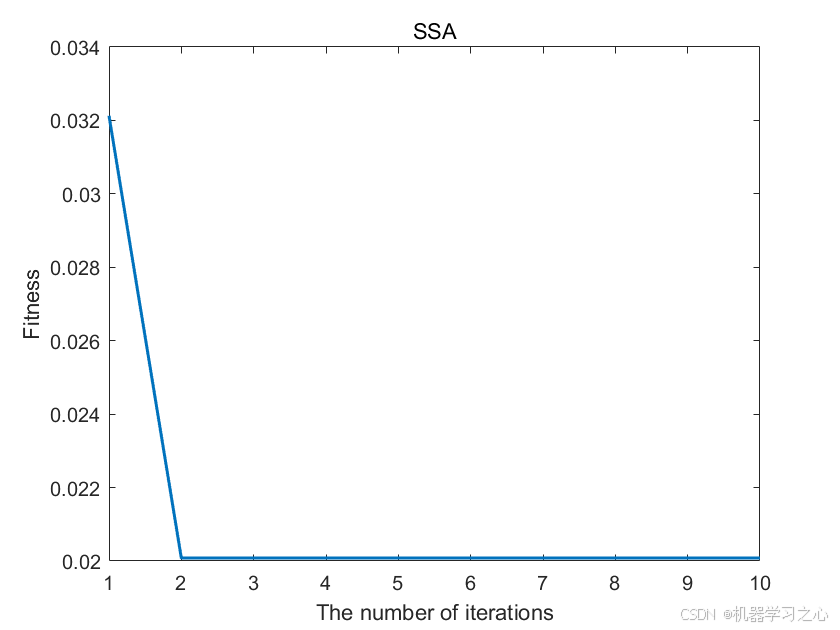
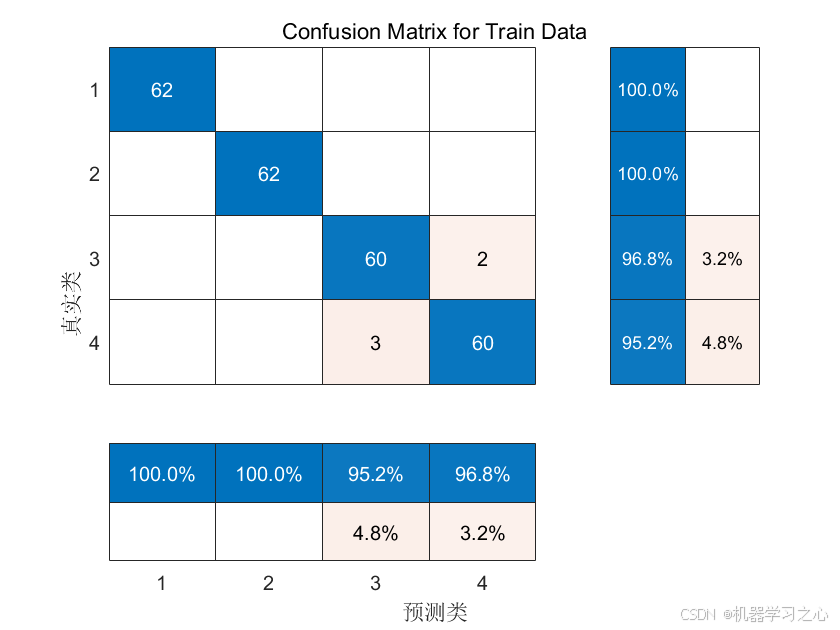
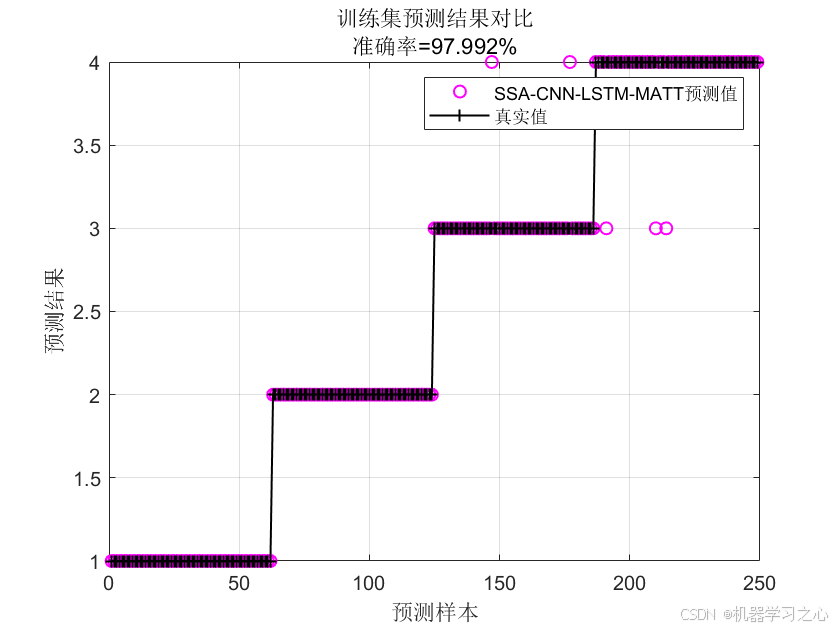
4.可视化展示分类准确率;
5.运行环境matlab2023b及以上。

程序设计
- 完整程序和数据获取方式私信博主回复SSA-CNN-LSTM-MATT多头注意力机制多特征分类预测。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 读取数据
res = xlsread('data.xlsx');
%% 分析数据
num_class = length(unique(res(:, end))); % 类别数(Excel最后一列放类别)
num_dim = size(res, 2) - 1; % 特征维度
num_res = size(res, 1); % 样本数(每一行,是一个样本)
num_size = 0.7; % 训练集占数据集的比例
res = res(randperm(num_res), :); % 打乱数据集(不打乱数据时,注释该行)
flag_conusion = 1; % 标志位为1,打开混淆矩阵(要求2018版本及以上)
%% 设置变量存储数据
P_train = []; P_test = [];
T_train = []; T_test = [];
%% 划分数据集
for i = 1 : num_class
mid_res = res((res(:, end) == i), :); % 循环取出不同类别的样本
mid_size = size(mid_res, 1); % 得到不同类别样本个数
mid_tiran = round(num_size * mid_size); % 得到该类别的训练样本个数
P_train = [P_train; mid_res(1: mid_tiran, 1: end - 1)]; % 训练集输入
T_train = [T_train; mid_res(1: mid_tiran, end)]; % 训练集输出
P_test = [P_test; mid_res(mid_tiran + 1: end, 1: end - 1)]; % 测试集输入
T_test = [T_test; mid_res(mid_tiran + 1: end, end)]; % 测试集输出
end
%% 数据转置
P_train = P_train'; P_test = P_test';
T_train = T_train'; T_test = T_test';
%% 得到训练集和测试样本个数
M = size(P_train, 2);
N = size(P_test , 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
t_train = categorical(T_train)';
t_test = categorical(T_test )';
%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
P_train = double(reshape(P_train, num_dim, 1, 1, M));
P_test = double(reshape(P_test , num_dim, 1, 1, N));
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 优化算法参数设置
SearchAgents_no = 8; % 数量
Max_iteration = 10; % 最大迭代次数
dim = 3; % 优化参数个数
lb = [1e-3,10 1e-4]; % 参数取值下界(学习率,隐藏层节点,正则化系数)
ub = [1e-2, 30,1e-1]; % 参数取值上界(学习率,隐藏层节点,正则化系数)
参考资料
[1] https://blog.csdn.net/kjm13182345320/category_11799242.html?spm=1001.2014.3001.5482
[2] https://blog.csdn.net/kjm13182345320/article/details/124571691