基于极光PLO优化算法的机器人三维路径规划
完整代码私信回复基于极光PLO优化算法的机器人三维路径规划Matlab代码
一、引言
1.1、研究背景与意义
机器人路径规划是机器人技术中的一个核心问题,它涉及到在复杂环境中寻找一条从起点到终点的最优或次优路径。这一问题在自动化制造、服务机器人、自动驾驶等领域具有重要的应用价值。随着工业4.0和智能制造的发展,机器人路径规划的效率和优化程度直接影响到生产效率和成本控制。此外,在服务机器人和自动驾驶领域,路径规划的合理性和安全性直接关系到用户体验和服务质量。因此,研究高效的路径规划算法对于提升机器人的智能化水平和实际应用效果具有重要意义。
极光优化算法(PLO)是一种受极光现象启发的新型元启发式优化算法。它通过模拟极光的运动和行为,进行全局搜索和局部开发,具有较强的寻优能力和较快的收敛速度。PLO算法在解决复杂优化问题时表现出色,尤其是在高维度和多模态问题中,其性能优于许多传统优化算法。因此,将PLO算法应用于机器人三维路径规划中,有望提高路径规划的效率和优化效果,为机器人技术的研究和应用提供新的思路和方法。
1.2、研究现状
目前,机器人路径规划的方法多种多样,包括但不限于A算法、Dijkstra算法、遗传算法、粒子群优化算法等。这些方法在特定环境下表现出良好的性能,但也存在一些问题。例如,A算法和Dijkstra算法在处理大规模复杂环境时,计算量巨大,实时性较差;而遗传算法和粒子群优化算法虽然在全局搜索能力上表现突出,但在局部优化和收敛速度方面仍有待提高。此外,这些方法在处理三维路径规划问题时,往往面临计算复杂度高、优化效果不理想等问题。
近年来,随着元启发式优化算法的发展,一些新型优化算法如极光优化算法(PLO)、灰狼优化算法(GWO)、鲸鱼优化算法(WOA)等在路径规划中的应用逐渐增多。这些算法通过模拟自然现象或生物行为,具有较强的全局搜索能力和较快的收敛速度,为解决复杂环境下的路径规划问题提供了新的思路和方法。然而,将这些新型算法应用于三维路径规划问题仍面临许多挑战,如算法参数的设置、适应度函数的设计、路径平滑处理等。
1.3、研究目的与内容
本研究旨在探索极光优化算法在机器人三维路径规划中的应用可能性,通过设计合适的适应度函数和优化策略,解决传统方法在三维路径规划中遇到的难题。研究内容主要包括:分析极光优化算法的基本原理和特点;建立机器人三维路径规划的数学模型;设计基于PLO算法的路径优化流程;通过仿真实验验证算法的有效性和优越性。具体而言,本研究将探讨如何利用PLO算法的全局搜索能力和局部开发能力,在复杂三维环境中找到最优或次优路径,并对比传统算法,评估PLO算法在路径长度、计算时间和路径平滑度等方面的性能。
二、极光优化算法(PLO)概述
2.1、PLO算法的基本原理
极光优化算法(PLO)是一种模拟极光现象的元启发式优化算法。极光是由于太阳带电粒子进入地球磁场,在高层大气中激发气体分子或原子而产生的发光现象。PLO算法通过模拟极光的运动和行为,进行全局搜索和局部开发,具体包括以下几个步骤:
- 初始化种群:随机生成一组初始解,代表搜索空间中的潜在最优路径。
- 极光运动模拟:模拟极光的运动,包括极光的扩散、传播和相互作用。这一步骤通过更新解的位置,探索搜索空间,寻找更优的解。
- 适应度评估:计算每个解的适应度值,根据适应度值评估解的优劣。适应度函数的设计根据具体问题而定,通常考虑路径长度、平滑度、避开障碍物等因素。
- 终止条件判断:判断是否满足终止条件,如达到预设的迭代次数或适应度值达到预设阈值。如果满足终止条件,输出最优解;否则,继续迭代优化过程。
2.2、PLO算法的特点
PLO算法具有以下几个特点:
- 全局搜索能力强:通过模拟极光的扩散和传播,PLO算法能够在整个搜索空间中广泛探索,避免陷入局部最优解。
- 收敛速度快:PLO算法通过极光的相互作用,进行局部开发,加速收敛过程,提高搜索效率。
- 参数设置简单:相比其他元启发式优化算法,PLO算法的参数设置较为简单,易于实现和调整。
- 适用于高维复杂问题:PLO算法在处理高维度和多模态问题时表现出色,适用于解决复杂环境下的路径规划问题。
三、机器人三维路径规划问题建模
3.1、路径规划问题的数学描述
在机器人三维路径规划问题中,目标是为机器人找到一个从起点到终点的最优路径,同时避开环境中的障碍物。这一问题可以形式化为一个数学优化问题,具体包括以下几个要素:
- 搜索空间:三维环境中的所有可能路径构成搜索空间。搜索空间通常被离散化为一系列三维坐标点,机器人路径由这些坐标点的序列组成。
- 目标函数:目标函数用于评价路径的优劣,通常考虑路径长度、平滑度、能量消耗等因素。目标函数的设计根据具体问题而定,旨在找到满足多个优化标准的最佳路径。
- 约束条件:约束条件包括机器人的运动学约束和避障约束。运动学约束保证机器人在运动过程中满足其物理限制,如最大速度、加速度和转向角度等;避障约束保证机器人在路径规划过程中避开环境中的障碍物。
3.2、适应度函数的设计
适应度函数是评价路径优劣的关键指标,通常包括以下几个部分:
- 路径长度:路径长度是评价路径优劣的重要指标,通常定义为路径上所有线段长度之和。较短的路径能够减少机器人的运动时间和能量消耗。
- 路径平滑度:路径平滑度是评价路径质量的另一个重要指标,通常定义为路径曲率的积分。平滑的路径能够减少机器人的运动颠簸,提高运动稳定性和舒适性。
- 避障能力:避障能力是评价路径安全性的关键指标,通常定义为路径与障碍物之间最小距离的函数。较大的最小距离能够保证机器人在运动过程中安全避开障碍物。
综合以上三个部分,适应度函数可以设计为以下形式:
f ( x ) = w 1 ⋅ L ( x ) + w 2 ⋅ S ( x ) + w 3 ⋅ O ( x ) f(x) = w_1 \cdot L(x) + w_2 \cdot S(x) + w_3 \cdot O(x) f(x)=w1⋅L(x)+w2⋅S(x)+w3⋅O(x)
其中, L ( x ) L(x) L(x)为路径长度, S ( x ) S(x) S(x)为路径平滑度, O ( x ) O(x) O(x)为避障能力, w 1 w_1 w1、 w 2 w_2 w2和 w 3 w_3 w3为权重系数,用于平衡不同部分的贡献。适应度函数的设计需要根据具体问题进行调整,以确保找到满足多个优化标准的最佳路径。
四、基于PLO的机器人三维路径规划方法
4.1、初始化路径种群
在基于PLO的机器人三维路径规划方法中,首先需要随机生成一组初始路径,构成初始种群。每个路径由一系列三维坐标点组成,代表机器人从起点到终点的一条潜在最优路径。初始种群的生成可以采用均匀分布或正态分布等方法,以确保搜索空间的多样性。
4.2、PLO算法的迭代过程
PLO算法的迭代过程主要包括以下几个步骤:
- 极光运动模拟:模拟极光的扩散、传播和相互作用,更新每个路径的位置。具体而言,通过计算极光的偏振方向和强度,更新路径上每个坐标点的位置,探索搜索空间,寻找更优的路径。
- 适应度评估:计算每个路径的适应度值,根据适应度值评估路径的优劣。适应度值较低的路径代表更优的解。
- 选择操作:根据适应度值,选择一部分较优的路径进入下一代种群。选择操作可以采用轮盘赌选择、锦标赛选择等方法,以确保较优的路径有更高的概率被选中。
- 交叉操作:对选中的路径进行交叉操作,生成新的路径。交叉操作可以通过随机选择交叉点,交换两个路径之间的部分坐标点来实现。
- 变异操作:对新生成的路径进行变异操作,增加搜索空间的多样性。变异操作可以通过随机改变路径上某些坐标点的位置来实现。
- 终止条件判断:判断是否满足终止条件,如达到预设的迭代次数或适应度值达到预设阈值。如果满足终止条件,输出最优路径;否则,继续迭代优化过程。
4.3、路径优化操作
在路径优化过程中,为了进一步提高路径的质量,可以采用一些额外的优化操作,如路径平滑处理和局部搜索等。
- 路径平滑处理:通过插值或拟合等方法,减少路径的曲率,提高路径的平滑度。常用的路径平滑方法包括Bezier曲线、B样条曲线等。
- 局部搜索:在当前最优路径的附近进行局部搜索,寻找更优的路径。局部搜索可以采用梯度下降法、模拟退火等方法,以提高搜索效率和优化效果。
4.4、终止条件与结果输出
终止条件通常包括达到预设的迭代次数或适应度值达到预设阈值。当满足终止条件时,算法停止迭代,输出最优路径作为最终结果。结果输出可以包括路径的三维坐标点序列、路径长度、平滑度、避障能力等指标,以评估路径规划的效率和优化效果。
五、仿真实验与结果分析
5.1、实验设置
为了验证基于PLO算法的机器人三维路径规划方法的有效性,进行了一系列仿真实验。实验环境设置了一个包含多种障碍物的三维空间,机器人的起点和终点随机设定。实验参数包括种群大小、迭代次数、权重系数等,根据具体问题进行设置。
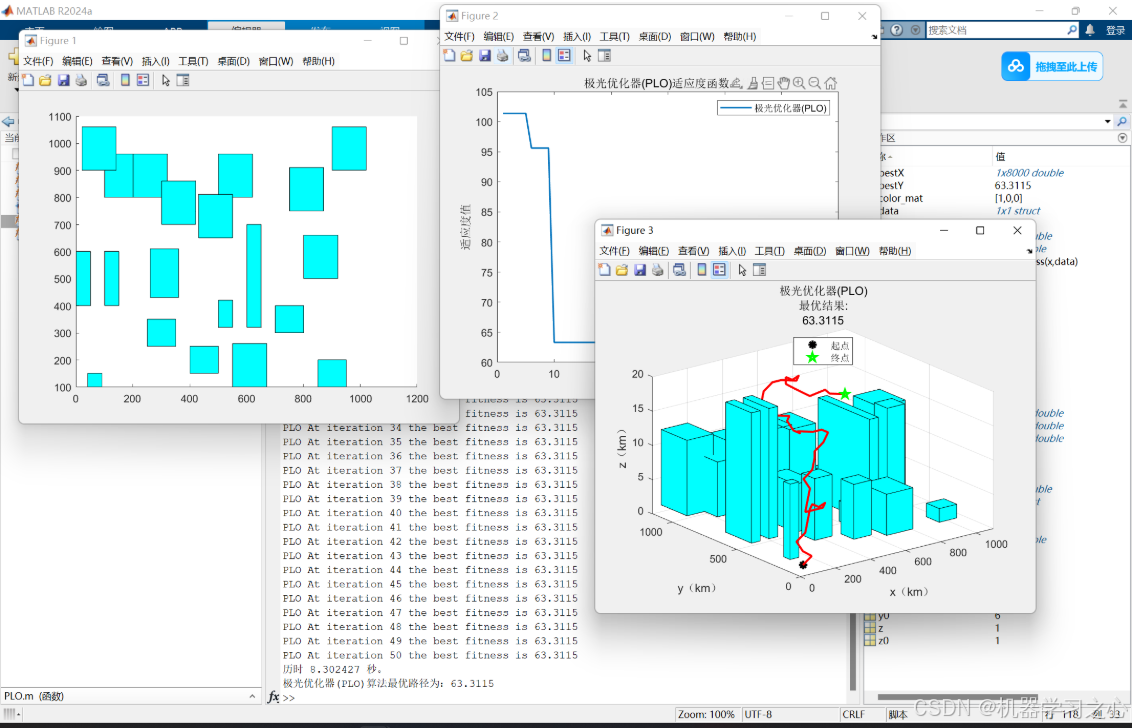
5.2、结果展示
仿真实验结果表明,基于PLO算法的路径规划方法能够有效找到从起点到终点的最优路径,避开所有障碍物。图1展示了某一实验场景下的路径规划结果,图中绿色线表示规划的路径,红色块表示障碍物。
5.3、结果分析
通过对比传统算法如A*算法和遗传算法,基于PLO的路径规划方法在路径长度、计算时间和路径平滑度等方面表现出优势。具体而言,PLO算法在处理复杂三维环境时,能够快速找到较优的路径,且路径平滑度较高,适合实际机器人的运动控制。此外,PLO算法的参数设置相对简单,易于调整和优化,提高了算法的实用性和适应性。
六、结论与展望
6.1、研究总结
本研究成功地将极光优化算法应用于机器人三维路径规划中,通过设计合适的适应度函数和优化策略,有效解决了传统方法在三维路径规划中遇到的难题。仿真实验结果表明,基于PLO算法的路径规划方法在路径长度、计算时间和路径平滑度等方面表现出优势,验证了算法的有效性和优越性。
6.2、未来研究方向
未来的研究可以进一步探索PLO算法在其他类型机器人路径规划中的应用,如水下机器人、无人机等。此外,可以研究PLO算法与其他优化算法的结合,以提高路径规划的效率和优化效果。具体而言,可以将PLO算法与遗传算法、粒子群优化算法等相结合,利用各自的优势,进一步提高路径规划的性能。最后,可以探索PLO算法在实际机器人系统中的应用,评估其在真实环境中的表现和可靠性。