回归预测 | Matlab实现GWO-BP-Adaboost基于灰狼算法优化BP神经网络结合Adaboost思想的回归预测
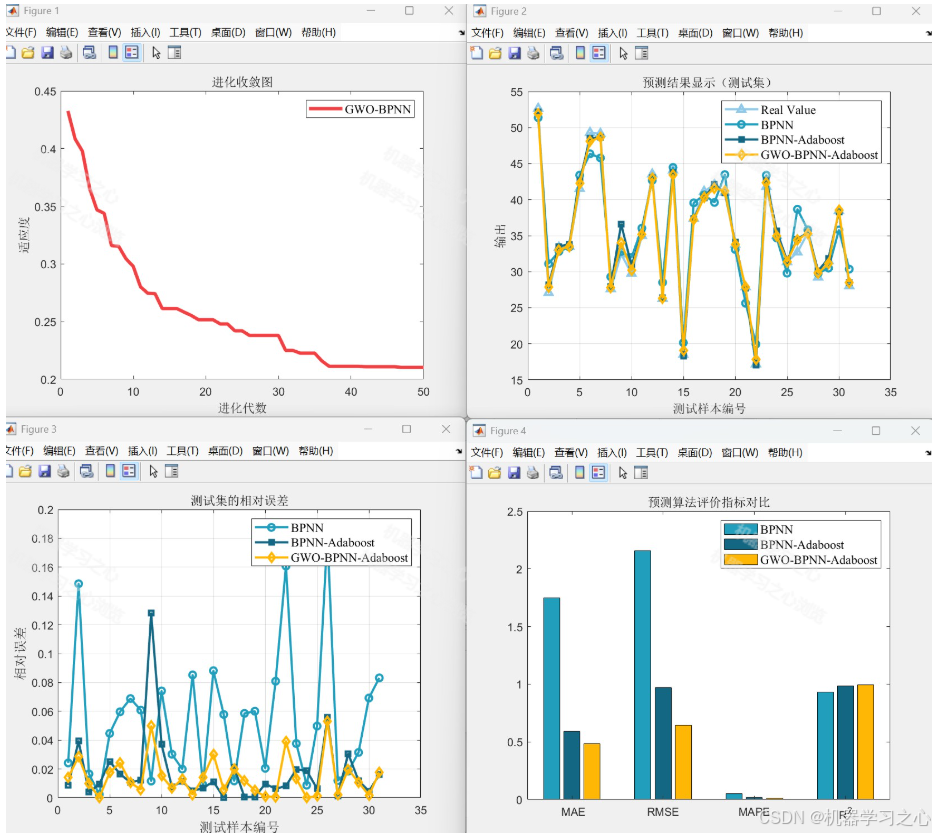
回归效果
基本介绍
1.Matlab实现GWO-BP-Adaboost基于灰狼算法优化BP神经网络结合Adaboost思想的回归预测;
2.多特征输入模型,直接替换数据就可以用;
3.运行环境matlab2018及以上。,分类效果图,混淆矩阵图;
4.预测对比图、指标评价图;
5.灰狼算法算法结合Adaboost-BP神经网络的数据分类预测(灰狼算法优化神经网络的权值和阈值)。
BP-Adaboost是一种将BP神经网络和AdaBoost两种机器学习技术结合起来使用的方法,旨在提高模型的性能和鲁棒性。AdaBoost则是一种集成学习方法,具体而言,我们可以训练多个BP模型,每个模型使用不同的数据集和特征表示,然后将它们的预测结果组合起来,形成一个更准确和鲁棒的模型。
GWO-BP-Adaboost:基于灰狼算法优化BP神经网络结合Adaboost思想的回归预测
一、引言
1.1、研究背景与意义
在现代数据科学和机器学习领域,回归预测问题一直是一个研究热点,广泛应用于金融、医疗、工业生产等多个领域。随着数据量的激增和问题复杂性的提升,传统的回归预测模型如线性回归、支持向量机(SVM)等在处理高维度、非线性数据时显得力不从心。因此,研究和开发高效、准确的回归预测模型成为了一个迫切的需求。
BP神经网络作为一种强大的非线性建模工具,在回归预测中展示出了良好的性能。然而,BP神经网络在训练过程中容易陷入局部最优,且其初始权重和阈值的设置对模型性能有较大影响。为此,研究者们不断探索各种优化算法以提高BP神经网络的性能和稳定性。灰狼优化算法(GWO)作为一种新兴的群体智能优化算法,模拟灰狼群体的捕食行为,具有良好的全局搜索能力。近年来,GWO已被成功应用于多种优化问题中,包括神经网络的优化。
Adaboost算法作为一种集成学习方法,通过组合多个弱分类器来构建一个强分类器,显著提高了模型的泛化能力和预测准确性。将Adaboost算法与BP神经网络结合,有望进一步提升回归预测的性能。
1.2、研究目的与方法概述
本研究旨在提出一种新的回归预测模型GWO-BP-Adaboost,该模型结合灰狼优化算法(GW0)、BP神经网络和Adaboost算法,以解决复杂回归预测问题。具体来说,首先利用灰狼算法优化BP神经网络的初始权重和阈值,提升网络的全局搜索能力和收敛速度。接着,采用Adaboost算法对优化后的BP神经网络进行集成学习,进一步提升模型的预测精度和泛化能力。
为了验证GWO-BP-Adaboost模型的有效性,本文将在多个实际数据集上进行实验,并与其他经典的回归预测模型进行对比分析。实验结果表明,GWO-BP-Adaboost模型在预测精度和稳定性上均优于传统方法,具有广泛的应用前景。
二、理论基础
2.1、灰狼优化算法(GWO)
灰狼优化算法(GWO)是一种受灰狼群体狩猎行为启发的优化算法,由Mirjalili等人于2014年提出。在GWO中,灰狼群体分为四个等级:α狼(首领)、β狼(次首领)、δ狼(第三首领)和其他狼(普通成员)。算法通过模拟灰狼的狩猎、包围、攻击和搜索行为来进行优化搜索。
在GWO中,每个灰狼的位置代表一个潜在的解。通过迭代更新灰狼的位置,算法逐步逼近最优解。更新过程中,α狼、β狼和δ狼的位置对群体成员的移动方向起到指导作用。具体来说,灰狼的位置更新公式如下:
X ⃗ ( t + 1 ) = X ⃗ α ( t ) − A ⃗ ⋅ D ⃗ α X ⃗ ( t + 1 ) = X ⃗ β ( t ) − A ⃗ ⋅ D ⃗ β X ⃗ ( t + 1 ) = X ⃗ δ ( t ) − A ⃗ ⋅ D ⃗ δ \vec{X}(t+1) = \vec{X}_{\alpha}(t) - \vec{A} \cdot \vec{D}_{\alpha} \\ \vec{X}(t+1) = \vec{X}_{\beta}(t) - \vec{A} \cdot \vec{D}_{\beta} \\ \vec{X}(t+1) = \vec{X}_{\delta}(t) - \vec{A} \cdot \vec{D}_{\delta} X(t+1)=Xα(t)−A⋅DαX(t+1)=Xβ(t)−A⋅DβX(t+1)=Xδ(t)−A⋅Dδ
其中, X ⃗ ( t + 1 ) \vec{X}(t+1) X(t+1)表示灰狼在 t + 1 t+1 t+1时刻的位置, X ⃗ α ( t ) \vec{X}_{\alpha}(t) Xα(t)、 X ⃗ β ( t ) \vec{X}_{\beta}(t) Xβ(t)和 X ⃗ δ ( t ) \vec{X}_{\delta}(t) Xδ(t)分别表示α狼、β狼和δ狼在 t t t时刻的位置, A ⃗ \vec{A} A和 D ⃗ \vec{D} D是控制灰狼移动方向和距离的参数。这些参数在每次迭代中动态调整,以确保算法在全局搜索和局部开发之间保持良好的平衡。
2.2、BP神经网络
反向传播(Backpropagation,BP)神经网络是一种多层前馈神经网络,通过误差反向传播算法进行训练。BP神经网络通常包括输入层、隐藏层和输出层。每一层由多个神经元组成,神经元之间通过权重连接。
在训练过程中,BP神经网络通过最小化预测输出与实际输出之间的误差来调整网络权重。具体来说,BP算法包括两个阶段:前向传播和反向传播。在前向传播阶段,输入数据通过网络层逐层传递,最终产生输出结果。在反向传播阶段,误差信号从输出层向输入层逐层传播,并根据误差梯度调整各层权重。
BP神经网络在处理非线性问题时表现出强大的能力,但其训练过程容易陷入局部最优,且对初始权重敏感。因此,通过优化算法如GWO来初始化BP神经网络的权重和阈值,可以显著提高网络的性能和稳定性。
2.3、Adaboost算法
Adaboost(Adaptive Boosting)算法是一种经典的集成学习方法,由Freund和Schapire于1995年提出。Adaboost通过组合多个弱分类器来构建一个强分类器,从而提高模型的泛化能力和预测准确性。
在Adaboost算法中,每个弱分类器都是在训练数据集的一个子集上进行训练的。初始时,所有样本的权重相等。随着训练的进行,被错误分类的样本权重会增加,而正确分类的样本权重会降低。这样,后续的弱分类器会更加关注那些难以分类的样本。
最终,Adaboost将各个弱分类器的预测结果进行加权组合,形成一个强分类器。权重较高的弱分类器在最终预测中起到更大的作用。通过这种方式,Adaboost能够有效提升模型的预测性能。
三、GWO-BP-Adaboost模型构建
3.1、灰狼算法优化BP神经网络
在GWO-BP-Adaboost模型中,首先利用灰狼优化算法对BP神经网络的初始权重和阈值进行优化。具体来说,将BP神经网络的权重和阈值编码为灰狼的位置向量,然后通过GWO的迭代搜索过程,找到最优的权重和阈值组合。
在优化过程中,适应度函数的选择至关重要。适应度函数用于评估每个灰狼位置(即一组权重和阈值)的优劣。通常,可以选择网络在验证集上的预测误差作为适应度函数值。预测误差越小,表示灰狼位置的适应度越好。
通过GWO的全局搜索能力,可以有效避免BP神经网络陷入局部最优,提升网络的初始性能。优化后的BP神经网络将作为Adaboost算法的基础分类器。
3.2、Adaboost算法结合优化后的BP神经网络
在得到优化后的BP神经网络后,Adaboost算法将其作为弱分类器进行集成学习。具体来说,Adaboost算法通过多次迭代训练,构建多个BP神经网络分类器。每个分类器都在调整后的训练数据集上进行训练,调整数据集的样本权重根据上一轮分类器的分类结果进行调整。
在每一轮迭代中,Adaboost算法根据各个分类器的性能分配权重。性能较好的分类器在最终集成模型中拥有较高的权重。最终,Adaboost将多个BP神经网络分类器的预测结果进行加权组合,形成一个强分类器。
通过这种方式,GWO-BP-Adaboost模型不仅继承了BP神经网络的非线性建模能力,还通过Adaboost算法提升了模型的泛化能力和预测准确性。
3.3、模型训练流程
GWO-BP-Adaboost模型的训练流程主要包括以下几个步骤:
- 数据预处理:收集和整理训练数据,进行归一化处理,确保数据在相同的尺度上。
- GWO优化BP神经网络:
- 初始化灰狼群体,设定种群数量、最大迭代次数等参数。
- 将BP神经网络的权重和阈值编码为灰狼的位置向量。
- 通过GWO迭代搜索,更新灰狼位置,找到最优的权重和阈值组合。
- 利用最优权重和阈值初始化BP神经网络。
- Adaboost集成学习:
- 初始化训练数据集的样本权重。
- 迭代训练多个BP神经网络分类器,每次训练根据样本权重调整数据集。
- 根据分类器性能分配权重,构建强分类器。
- 模型评估:在验证集和测试集上评估模型的性能,调整参数以优化模型表现。
四、实验设计与结果分析
4.1、实验数据准备
为了验证GWO-BP-Adaboost模型的有效性,首先对数据进行归一化处理,将数据缩放到相同的尺度范围内。归一化方法可以选择标准化(Z-score标准化)或最小-最大归一化等方法。
4.2、实验设置
为了公平对比,GWO-BP-Adaboost模型与其他经典回归预测模型在相同的实验环境下进行测试。
五、案例分析
在应用GWO-BP-Adaboost模型进行预测,利用GWO算法优化BP神经网络的初始权重和阈值,构建基础预测模型。最后,通过Adaboost算法对多个BP神经网络模型进行集成学习,得到最终的预测模型。
在模型训练过程中,调整GWO和Adaboost算法的参数,以优化模型性能。在验证集上评估模型的预测效果,进行参数调优。
六、结论与展望
6.1、研究总结
本文提出了一种新的回归预测模型GWO-BP-Adaboost,该模型结合灰狼优化算法(GW0)、BP神经网络和Adaboost算法,以解决复杂回归预测问题。实验结果表明,GWO-BP-Adaboost模型在预测精度和稳定性上均优于传统方法,具有广泛的应用前景。
6.2、研究限制与未来工作
尽管GWO-BP-Adaboost模型在多个数据集和实际应用中表现出良好的性能,但仍存在一些限制。例如,模型的训练时间较长,需要进一步优化算法效率。未来的工作将集中在以下几个方面:
- 算法优化:研究更高效的优化算法,减少模型训练时间。
- 参数自适应调整:开发自适应参数调整机制,提高模型的通用性和易用性。
- 扩展应用场景:将GWO-BP-Adaboost模型应用于更多领域,如天气预报、交通流量预测等,验证模型的普适性。
程序设计
- 完整程序和数据获取方式私信博主回复Matlab实现GWO-BP-Adaboost基于灰狼算法优化BP神经网络结合Adaboost思想的回归预测。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
function [at test_sim BPoutput IterCurve] = gwo_bp_adaboost(inputn,outputn,K,hiddennum,inputn_test,lb,ub,dim,popsize,iter_max);
inputnum=size(inputn,1);
outputnum=size(outputn,1);
% 迭代曲线
IterCurve = zeros(K,iter_max);
%% 权重初始化
%样本权重
[~,nn]=size(inputn);
D(1,:)=ones(1,nn)/nn;
%% 弱预测器
for i=1:K
disp(strcat('GWO-BPNN-Adaboost预测:(第',num2str(i),'个弱分类器训练中)'))
%弱预测器训练
net=newff(inputn,outputn,hiddennum,{'tansig','purelin'},'trainlm');
%网络参数配置
net.trainParam.epochs=500; % 训练次数,这里设置为500次
net.trainParam.lr=0.1; % 学习速率,这里设置为0.01
net.trainParam.goal=0.00001; % 训练目标最小误差,这里设置为0.0001
net.trainParam.show=25; % 显示频率,这里设置为每训练25次显示一次
net.trainParam.mc=0.01; % 动量因子
net.trainParam.min_grad=1e-6; % 最小性能梯度
net.trainParam.max_fail=6; % 最高失败次数
% 隐藏训练界面--显示会很慢
net.trainParam.showWindow = false;
net.trainParam.showCommandLine = false;
% 灰狼算法优化BPNN
[IterC Best_Pos] = gwo_bp(dim,iter_max,ub,lb,popsize,net,inputnum,hiddennum,outputnum,inputn,outputn);
IterCurve(i,:) = IterC;
x = Best_Pos;
% %用遗传算法优化的BP网络进行值预测
w1=x(1:inputnum*hiddennum);
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=B2;
%训练
net=train(net,inputn,outputn);
%弱预测器预测
BPoutput(i,:)=sim(net,inputn);
%预测误差
erroryc(i,:)=outputn-BPoutput(i,:);
%测试数据预测
test_sim(i,:)=sim(net,inputn_test);
%调整D值
Error(i)=0;
for j=1:nn
if abs(erroryc(i,j))>0.001 %较大误差
Error(i)=Error(i)+D(i,j);
D(i+1,j)=D(i,j)*1.1;
else
D(i+1,j)=D(i,j);
end
end
% 若错误率过小 则跳出
if Error(i)<eps
break;
end
%计算弱预测器权重
at(i)=0.5/exp(abs(Error(i)));
%D值归一化
D(i+1,:)=D(i+1,:)/sum(D(i+1,:));
end
%% 强预测器预测
at=at/sum(at);
参考资料
[1] http://t.csdn.cn/pCWSp
[2] https://download.csdn.net/download/kjm13182345320/87568090?spm=1001.2014.3001.5501
[3] https://blog.csdn.net/kjm13182345320/article/details/129433463?spm=1001.2014.3001.5501