**导读:**人们正在以前所未有的速度转向互联网,我们在互联网上所做的很多行为产生了大量的“用户数据”,比如微博、购买记录等。
互联网成了海量信息的载体;互联网目前是分析市场趋势、监视竞争对手或者获取销售线索的最佳场所,数据采集以及分析能力已成为驱动业务决策的关键技能。
**如何有效地提取并利用这些信息成了一个巨大的挑战,而网络爬虫是一种很好的自动采集数据的通用手段。**本文将会对爬虫的类型、爬虫的抓取策略以及深入学习爬虫所需的网络基础等相关知识进行介绍。
作者:赵国生 王健
来源:大数据DT(ID:hzdashuju)

01 爬虫是什么
**网络爬虫(又被称为网页蜘蛛、网络机器人,在FOAF社区中,更经常地称为网页追逐者)是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。**另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫通过爬取互联网上网站服务器的内容来工作。它是用计算机语言编写的程序或脚本,用于自动从Internet上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有能正常打开的页面。
作为搜索引擎的重要组成部分,爬虫首要的功能就是爬取网页数据(如图2-1所示),目前市面流行的采集器软件都是运用网络爬虫的原理或功能。
▲图2-1 网络爬虫象形图
02 爬虫的意义
现如今大数据时代已经到来,网络爬虫技术成为这个时代不可或缺的一部分,企业需要数据来分析用户行为、自己产品的不足之处以及竞争对手的信息等,而这一切的首要条件就是数据的采集。
网络爬虫的价值其实就是数据的价值,在互联网社会中,数据是无价之宝,一切皆为数据,谁拥有了大量有用的数据,谁就拥有了决策的主动权。网络爬虫的应用领域很多,如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商网站的商品销量信息及用户评价来进行分析,如图2-2所示。
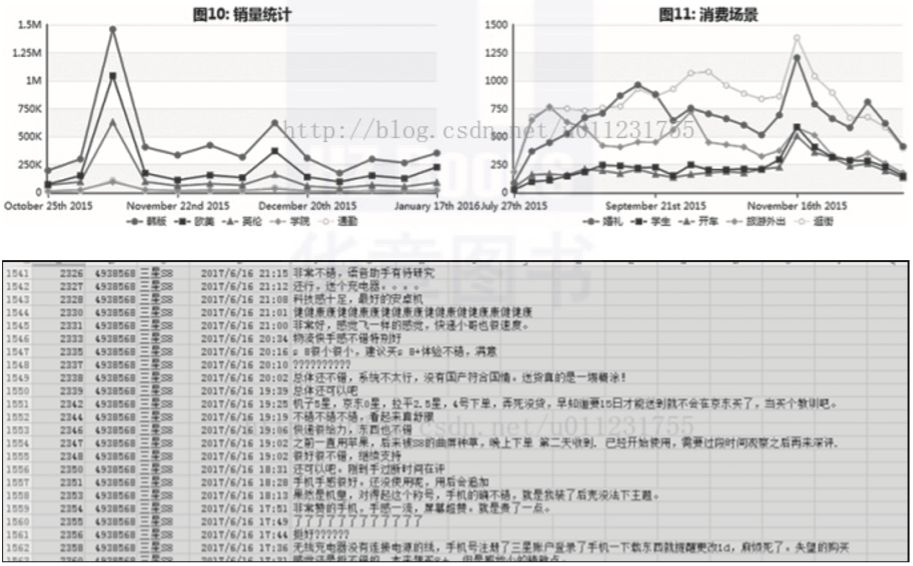
▲图2-2 电商网站的商品销售信息
2)分析大众点评、美团网等餐饮类网站的用户消费、评价和发展趋势,如图2-3所示。

▲图2-3 餐饮类网站的用户消费信息
3)分析各个城市中学区房的比例,以及学区房比普通二手房价格高出多少,如图2-4所示。
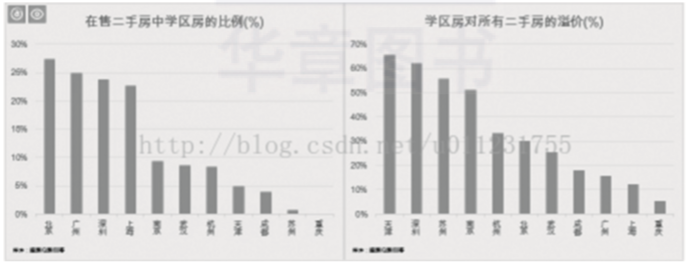
▲图2-4 学区房的比例与价格对比
以上数据是通过前嗅ForeSpider数据采集软件爬下来的,有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常会将网络爬虫的组成模块分为初链接库、网络抓取模块、网页处理模块、网页分析模块、DNS模块、待抓取链接队列、网页库等,网络爬虫的各系模块可形成一个循坏体系,从而不断地进行分析和抓取。
**爬虫的工作原理可以很简单地解释为先找到目标信息网,然后页面抓取模块,接着页面分析模块,最后数据存储模块。**其具体详情如图2-5所示。
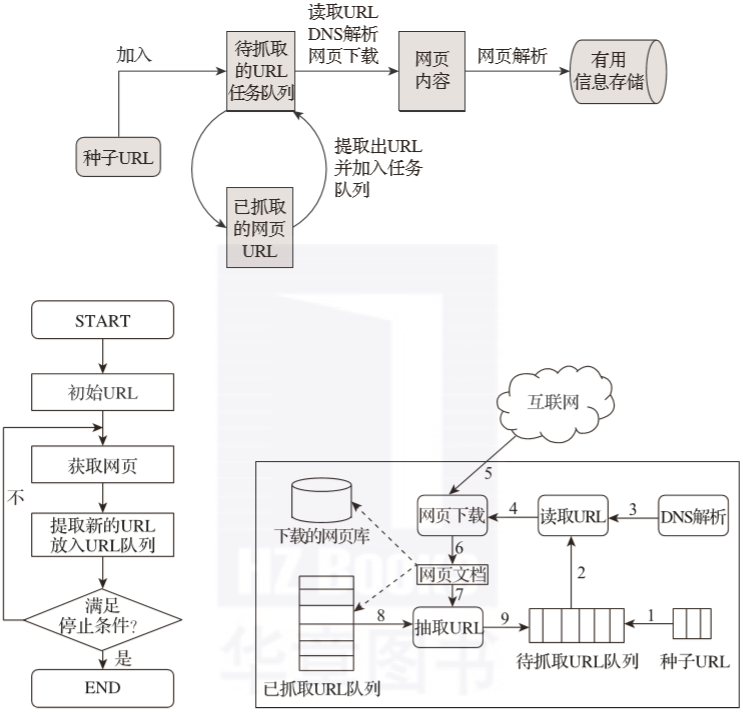
▲图2-5 爬虫原理图
爬虫工作基本流程:
-
首先在互联网中选出一部分网页,以这些网页的链接地址作为种子URL;
-
将这些种子URL放入待抓取的URL队列中,爬虫从待抓取的URL队列依次读取;
-
将URL通过DNS解析;
-
把链接地址转换为网站服务器对应的IP地址;
-
网页下载器通过网站服务器对网页进行下载;
-
下载的网页为网页文档形式;
-
对网页文档中的URL进行抽取;
-
过滤掉已经抓取的URL;
-
对未进行抓取的URL继续循环抓取,直至待抓取URL队列为空。
04 爬虫技术的类型
-
聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
-
增量抓取意即针对某个站点的数据进行抓取,当网站的新增数据或者该站点的数据发生变化后,自动地抓取它新增的或者变化后的数据。
-
Web页面按存在方式可以分为表层网页(surface Web)和深层网页(deep Web,也称invisible Web pages或hidden Web)。
-
表层网页是指传统搜索引擎可以索引的页面,即以超链接可以到达的静态网页为主来构成的Web页面。
-
深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。
关于爬虫技术类型的更详细讲解请戳详解4种类型的爬虫技术。
为了帮助大家更好的学习网络安全,我给大家准备了一份网络安全入门/进阶学习资料,里面的内容都是适合零基础小白的笔记和资料,不懂编程也能听懂、看懂这些资料!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
网络安全学习路线&学习资源

网络安全的知识多而杂,怎么科学合理安排?
下面给大家总结了一套适用于网安零基础的学习路线,应届生和转行人员都适用,学完保底6k!就算你底子差,如果能趁着网安良好的发展势头不断学习,日后跳槽大厂、拿到百万年薪也不是不可能!
初级网工
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
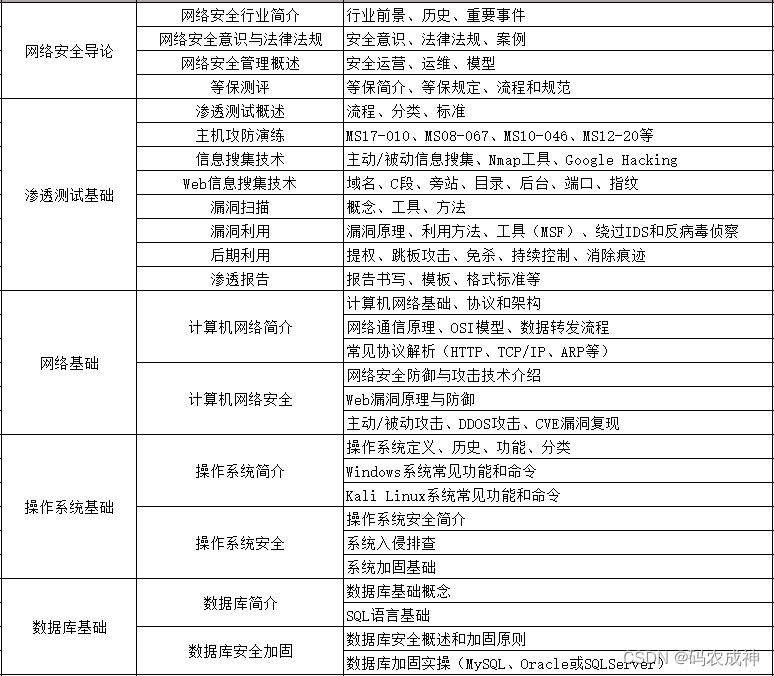
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
零基础入门,建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习; 搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime; ·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完; ·用Python编写漏洞的exp,然后写一个简单的网络爬虫; ·PHP基本语法学习并书写一个简单的博客系统; 熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选); ·了解Bootstrap的布局或者CSS。
8、超级网工
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,贴一个大概的路线。感兴趣的童鞋可以研究一下,不懂得地方可以【点这里】加我耗油,跟我学习交流一下。
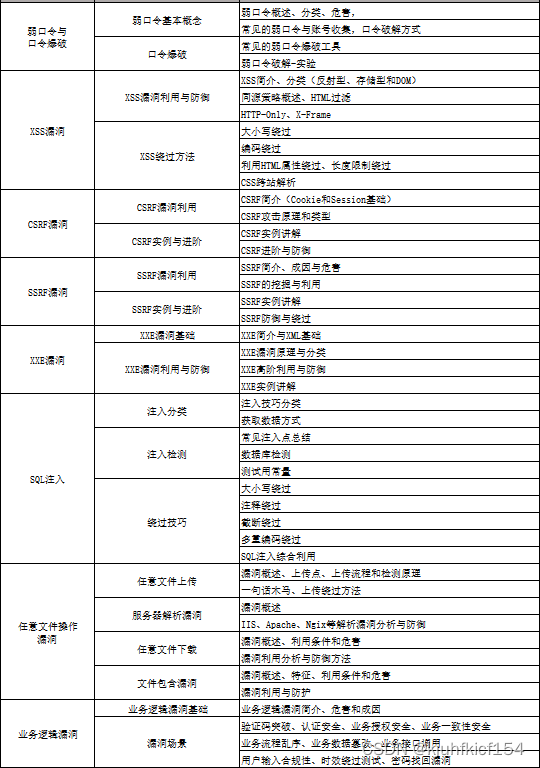
网络安全工程师企业级学习路线
如图片过大被平台压缩导致看不清的话,可以【点这里】加我耗油发给你,大家也可以一起学习交流一下。
一些我自己买的、其他平台白嫖不到的视频教程:
需要的话可以扫描下方卡片加我耗油发给你(都是无偿分享的),大家也可以一起学习交流一下。
结语
网络安全产业就像一个江湖,各色人等聚集。相对于欧美国家基础扎实(懂加密、会防护、能挖洞、擅工程)的众多名门正派,我国的人才更多的属于旁门左道(很多白帽子可能会不服气),因此在未来的人才培养和建设上,需要调整结构,鼓励更多的人去做“正向”的、结合“业务”与“数据”、“自动化”的“体系、建设”,才能解人才之渴,真正的为社会全面互联网化提供安全保障。
特别声明:
此教程为纯技术分享!本书的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本书的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施,从而减少由网络安全而带来的经济损失!!!