一、异常
1.1、C++的异常的使用
其实在C语言阶段我们就接触过异常了,例如C语言中的assert断言判断程序错误以及errorno异常编号。
而C++中把异常设计成了一个类,如果要使用C++中的异常,就要引入exception这个头文件:

这个头文件中就是C++标准库提供的异常类的实现。
C++异常的使用方法:
C++异常的语法主要是以下这种形式:
try {
// 被判断是否出异常的代码……
throw "发生异常"; // 构造出异常对象并抛出
}
catch ("异常类型变量") { // 捕捉异常对象
// 显示异常对象(输出或打日志)
}当然,在实际应用中,一般都不是在try的代码块中直接抛出异常,可能是在try的代码块中调用了某些函数,而这些函数内部出现了异常,则直接在函数内部抛异常也是可以的。
接下来使用一个最简单的除零错误,来演试一下异常的基本使用:
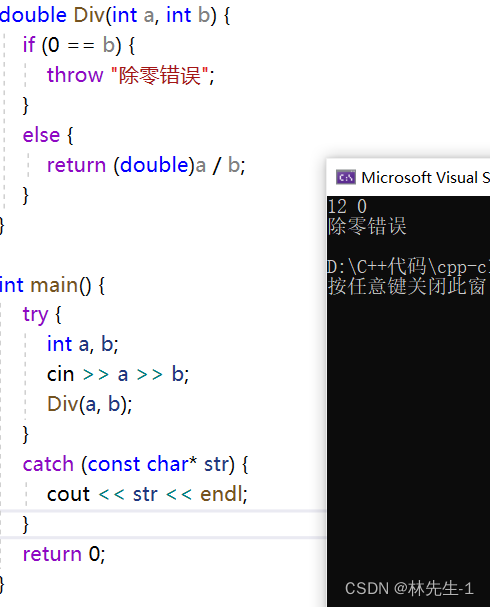
事实上,抛出异常的地方可以是任意地方,在抛出异常后,程序的执行流会直接跳到catch的地方,例如我们再封装一层:
double Div(int a, int b) {
return (double)a / b;
}
void func() {
int a, b;
cin >> a >> b;
if (b == 0) {
throw "除零错误";
}
else {
Div(a, b);
}
cout << "你看不见我,嘿嘿" << endl;
}
int main() {
try {
func();
}
catch (const char* str) {
cout << str << endl;
}
return 0;
}执行结果:
如上,异常直接在func函数里面抛也是可以的,而且抛出异常后func后面的代码也没有再执行了。
当然,我们知道函数的调用都是会创建栈帧的,而异常的抛出只是让执行流调到了catch的地方,抛出后后续的代码就不会执行,但是之前创建过得栈帧都是要被销毁的。
下面这个例子可以很好的证明这一点:
class A {
public :
A() {
cout << "A()" << endl;
}
~A() {
cout << "~A()" << endl;
}
};
double Div(int a, int b) {
return (double)a / b;
}
void func() {
int a, b;
cin >> a >> b;
A aa; // 创建一个A对象
if (b == 0) {
throw "除零错误";
}
else {
Div(a, b);
}
cout << "你看不见我,嘿嘿" << endl;
}
int main() {
try {
func();
}
catch (const char* str) {
cout << str << endl;
}
return 0;
}运行结果:
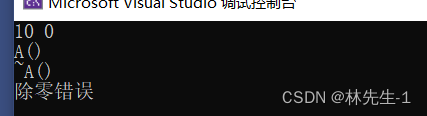
栈帧销毁的时候,对象会自动调用析构函数,所以证明了抛出异常后也是要销毁栈帧的。
catch其实还可以有多个,当有多个catch的时候异常机制会跳到匹配的那一个,例如下面这个例子:
double Div(int a, int b) {
if (b == 0) {
throw "除零错误";
}
else {
return (double)a / b;
}
}
void func() {
int a, b;
cin >> a >> b;
try {
Div(a, b);
}
catch (const int e) {
cout << e << endl;
}
}
int main() {
try {
func();
}
catch (const char* str) {
cout << str << endl;
}
return 0;
}运行结果:

而如果有多个匹配的catch,则就会去匹配里throw最近的那个catch,例如下面这个例子:
double Div(int a, int b) {
if (b == 0) {
throw "除零错误";
}
else {
return (double)a / b;
}
}
void func() {
int a, b;
cin >> a >> b;
try {
Div(a, b);
}
catch (const char * str) {
cout << "Zero division error occurred" << endl;
}
}
int main() {
try {
func();
}
catch (const char* str) {
cout << str << endl;
}
return 0;
}运行结果:
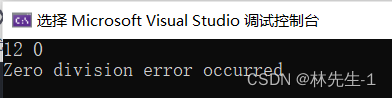
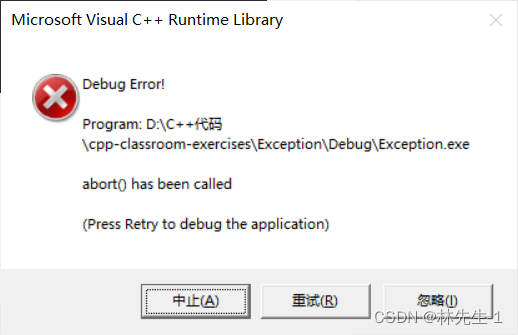
而若是一个都没匹配上,那么程序就会崩溃:
double Div(int a, int b) {
if (b == 0) {
throw "除零错误";
}
else {
return (double)a / b;
}
}
void func() {
int a, b;
cin >> a >> b;
try {
Div(a, b);
}
catch (const int str) {
cout << "Zero division error occurred" << endl;
}
}
int main() {
try {
func();
}
catch (const int str) {
cout << str << endl;
}
return 0;
}
在实际应用中,可能会有很多的异常,当然也有可能有一些未知的异常,如果想要捕获这些未知异常,可以在catch里面写三个点“...”:
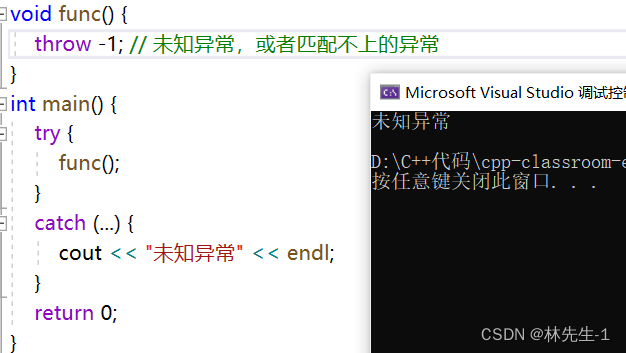
1.2、异常所导致的问题
正是因为异常有导致执行流跳跃的后果,所以在使用的时就可能会导致一些问题,最典型的就是会导致指针没有释放。
例如下面这个例子就是典型的异常导致执行流跳跃所导致的指针没有被释放的场景:
double Div(int a, int b) {
int* nums = new int[10];
double ret = 0.0;
if (b == 0) {
throw "除零错误";
}
else {
ret = (double)a / b;
}
cout << "delete[] nums" << endl;
delete[] nums;
return ret;
}
int main() {
int a, b;
try {
while (cin >> a >> b) {
cout << "answer = " << Div(a, b) << endl;
}
}
catch (const char* str) {
cout << str << endl;
}
return 0;
}运行结果:

从结果我们就可以看出,前两次没有抛异常的情况nums都是正常被销毁的,但是抛了异常之后就没有再销毁了,这正是因为异常导致执行流跳跃而使得后面的代码没有执行导致的,这样就内存泄漏了。
想要解决这个问题,有一个简单的方法,叫做“异常的重新抛出”,我们可以把指针的释放放到catch里面,然后捕捉到异常,就释放指针,然后再将捕获到的异常重新抛出:
double Div(int a, int b) {
int* nums = new int[10];
double ret = 0.0;
try {
if (b == 0) {
throw "除零错误";
}
else {
ret = (double)a / b;
}
}
catch (const char* str) {
cout << "delete[] nums" << endl;
delete[] nums;
throw str;
}
cout << "delete[] nums" << endl;
delete[] nums;
return ret;
}
int main() {
int a, b;
try {
while (cin >> a >> b) {
cout << "answer = " << Div(a, b) << endl;
}
}
catch (const char* str) {
cout << str << endl;
}
return 0;
}运行结果:

这样不管是正常运行还是抛异常都能保证指针被释放了。
但是这种方法并不是一个很好的方法,如果我们今天有很多个指针,那么在上面的情景中我们要对每一个指针都在catch里面释放,而且没出异常的时候还需要在catch外边释放:
double Div(int a, int b) {
int* nums1 = new int[10];
int* nums2 = new int[10];
int* nums3 = new int[10];
double ret = 0.0;
try {
if (b == 0) {
throw "除零错误";
}
else {
ret = (double)a / b;
}
}
catch (const char* str) {
cout << "delete[] nums1" << endl;
delete[] nums1;
cout << "delete[] nums2" << endl;
delete[] nums2;
cout << "delete[] nums3" << endl;
delete[] nums3;
throw str;
}
cout << "delete[] nums1" << endl;
delete[] nums1;
cout << "delete[] nums2" << endl;
delete[] nums2;
cout << "delete[] nums3" << endl;
delete[] nums3;
return ret;
}
int main() {
int a, b;
try {
while (cin >> a >> b) {
cout << "answer = " << Div(a, b) << endl;
}
}
catch (const char* str) {
cout << str << endl;
}
return 0;
}这样的代码就会显得很冗余,而且不美观。
而且new也是会抛异常的,所以我们也需要对nwe抛出的异常进行捕捉,在上面的代码中,如果是最后一个nums3创建失败了那我们就要在catch里面释放nums1和nums2,但是我们并没有办法知道是哪一个new失败了,如果释放了还没申请的空间,就又会发生异常,很头疼!
所以这个方法也就只能解决一些问题而已。
如果想要很好的解决这里的问题,就要用到我们后面要讲到的“智能指针”。
1.3、异常书写的规范
如果我们大致知道有个函数可能会抛那些异常,我们可以在这个函数的后面加一个throw(A, B, C, D),表示这个函数可能会抛ABCD四种类型的异常。
double Div(int a, int b) throw (const char*, const int, const double) {
if (b == 0) {
throw "除零错误";
}
else {
return (double)a / b;
}
}
int main() {
try {
int a, b;
cin >> a >> b;
Div(a, b);
}
catch (const char* str) {
cout << str << endl;
}
return 0;
}但这只是个规范,规范就是可写可不写,相当于一个提醒,也并不是写在里面的所有异常都要抛出,写一个根本不会抛出的异常也行。
而如果能确定一个函数不会抛异常,就可以在它后面加一个noexcept:
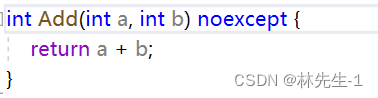
同样这只做个提醒作用,如果看到一个函数后面有noexcept,那在调用这个函数的时候就不用考虑异常情况了。
二、智能指针
前面之所以要先讲异常,是因为讲了异常之后,我们才能更清楚的理解智能指针的应用场景——处理内存泄漏问题。
2.1、智能指针的设计方法
智能指针的这个智能其实是体现在“自动”上,像之前我们异常所导致的内存泄漏问题就是因为没有释放指针所导致的,那么我们如果能让这些指针出了作用自动会释放不就解决问题了。
那么智能指针怎么实现这个“自动”呢?我们想想,我们以前是不是学过一些可以自动调用的函数?
这个函数就析构函数,析构函数可以做到创建好的对象出了作用域自动释放。
所以智能指针的设计方法就是把指针交给一个类,然后让这个类的析构函数释放这个指针!这就是智能指针最根本的设计方法。
设计一个最简单的智能指针来演示:
class SmartPtr {
public :
// 构造
SmartPtr(int* ptr)
:_ptr(ptr)
{
}
// 析构
~SmartPtr() {
delete[] _ptr;
cout << "delete[]" << _ptr << endl;
}
private :
int* _ptr;
};然后我们就可以直接将之前new出来的指针交给我们写的这个智能指针,就不用担心内存泄漏问题了:
class SmartPtr {
public :
// 构造
SmartPtr(int* ptr)
:_ptr(ptr)
{
}
// 析构
~SmartPtr() {
delete[] _ptr;
cout << "delete[]" << _ptr << endl;
}
private :
int* _ptr;
};
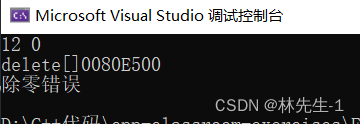
double Div(int a, int b) throw (const char*, const int, const double) {
int* nums = new int[10];
SmartPtr ptr(nums);
if (b == 0) {
throw "除零错误";
}
else {
return (double)a / b;
}
}运行结果:
当然了,智能指针并不是只有这么简单的,它还需要做很多的事情,目的是让它能像指针一样使用。
2.2、智能指针的完善
智能指针如果想要完善就一定要让它能像普通指针一样使用,那我们势必要在智能指针里面再添加一点东西,比如星号解引用运算符重载,箭头进引用运算符重载、方括号运算符重载……
首先我们可以先把智能指针修改成一个类模板:
template <class T>
class SmartPtr {
public :
// 构造
SmartPtr(T* ptr)
:_ptr(ptr)
{
}
// 析构
~SmartPtr() {
delete[] _ptr;
cout << "delete[]" << _ptr << endl;
}
private :
T* _ptr;
};然后先重载一下星号和箭头:
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}这样我们就可以像使用普通指针一样使用智能指针了:
template <class T>
class SmartPtr {
public:
// 构造
SmartPtr(T* ptr)
:_ptr(ptr)
{
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
// 析构
~SmartPtr() {
delete[] _ptr;
cout << "delete[]" << _ptr << endl;
}
private:
T* _ptr;
};
int main() {
SmartPtr<int> p(new int[10]);
for (int i = 0; i < 10; i++) {
*p = i;
cout << *p << " ";
}
cout << endl;
return 0;
}运行结果:
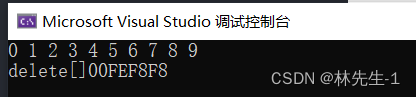
而且还不用自己手动释放。
当然自定义类型也是一样的:
template <class T>
class SmartPtr {
public:
// 构造
SmartPtr(T* ptr)
:_ptr(ptr)
{
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
// 析构
~SmartPtr() {
delete[] _ptr;
cout << "delete[]" << _ptr << endl;
}
private:
T* _ptr;
};
class Date {
public :
Date()
:_year(1)
,_month(1)
,_day(1)
{}
public :
int _year;
int _month;
int _day;
};
int main() {
SmartPtr<Date> d1(new Date());
d1->_year = 2024;
d1->_month = 3;
d1->_day = 28;
printf("今天是%d-%d-%d\n", d1->_year, d1->_month, d1->_day);
return 0;
}运行结果:

同样的,重载一个operator[]也是非常简单的:
T& operator[](int index) {
return _ptr[index];
}
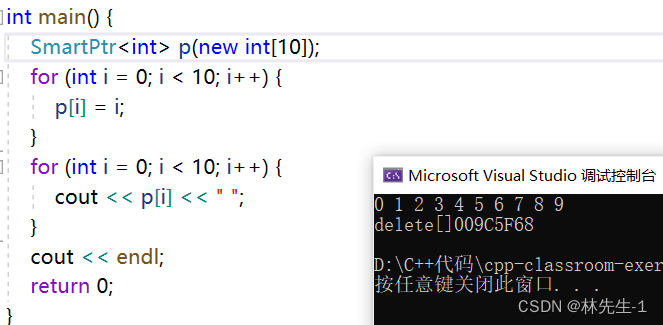
2.3、智能指针的拷贝问题
普通的指针都可以拷贝,而且是单纯的浅拷贝,那智能指针是否也能直接拷贝(浅拷贝)呢?
答案是不能,如果直接拷贝的话就会出错:
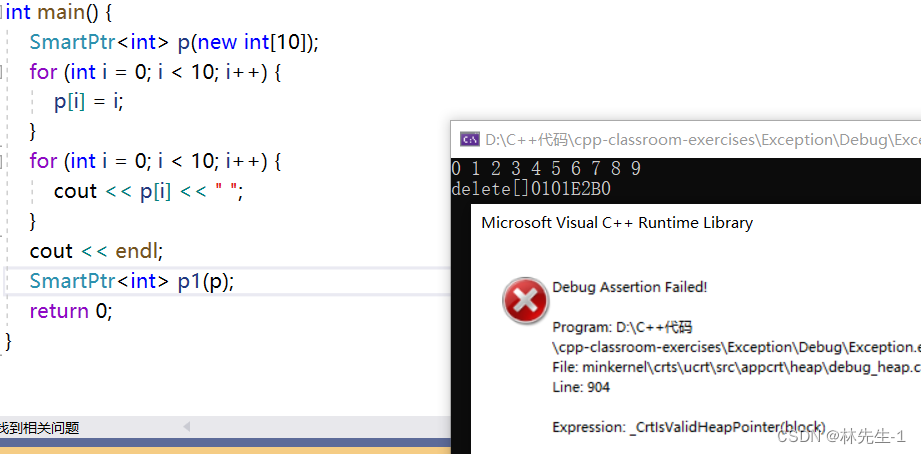
究其原因是因为我们析构了两次,因为默认的拷贝构造对内置类型做的是浅拷贝,所以这两个智能指针多指向了同一个空间,自然析构的时候就会出错。
但是我们这里并不能实现深拷贝,因为如果实现的是深拷贝的话,两个指针指向的就不是同一个空间了,而我们想要让智能指针像普通指针一样使用,就一定不能实现这样的功能,因为如果两个指针指向的是不同的空间,那么这根在创建一个变量或数组让两个智能指针指向有什么区别?
为了解决这样的问题,C++标准库提供了三种解决方法。
第一种——auto_ptr
auto_ptr的实现思路其实是一个“管理权转移”,它实现的拷贝构造是先将拷贝对象的指针赋值给构造对象的指针,然后再将拷贝对象的指针置空:
Auto_ptr(const Auto_ptr& ap)
:_ptr(ap._ptr)
{
ap._ptr = nullptr;
}这样析构两次的情况就不会出现了:
template <class T>
class Auto_ptr {
public:
// 构造
Auto_ptr(T* ptr)
:_ptr(ptr)
{
}
T& operator*() {
return *_ptr;
}
T& operator[](int index) {
return _ptr[index];
}
T* operator->() {
return _ptr;
}
// 模拟auto_ptr的拷贝构造
Auto_ptr(Auto_ptr& ap)
:_ptr(ap._ptr)
{
ap._ptr = nullptr;
}
// 析构
~Auto_ptr() {
delete[] _ptr;
cout << "delete[]" << _ptr << endl;
}
private:
T* _ptr;
};
int main() {
Auto_ptr<int> p(new int[10]);
for (int i = 0; i < 10; i++) {
p[i] = i;
}
for (int i = 0; i < 10; i++) {
cout << p[i] << " ";
}
cout << endl;
Auto_ptr<int> p1(p);
return 0;
}运行结果:
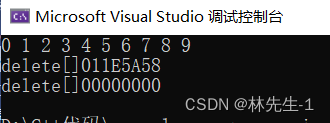
虽然也是调用两次析构函数,但是析构的并不是同一块空间。
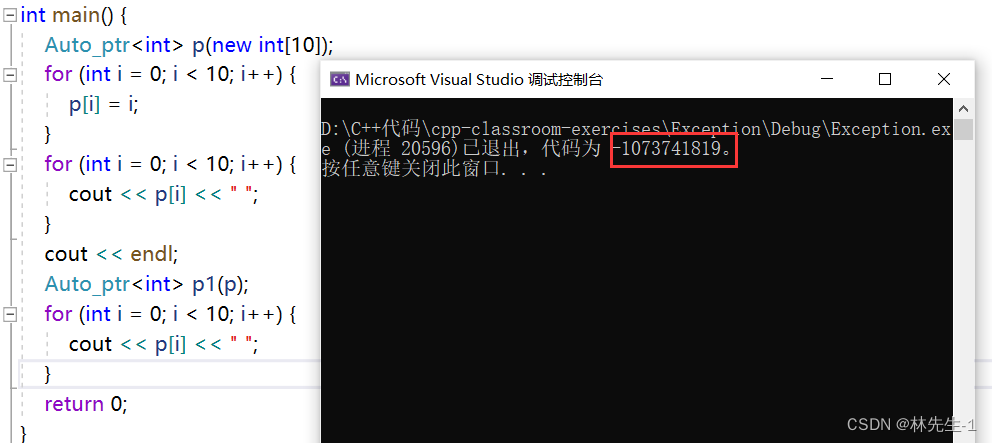
但是这个auto_ptr会有一个很坑的地方,如果我不熟悉auto_ptr的实现机制,有可能我会再次使用被转移控制权的指针,那么这就是对空指针进行解引用了:
同样的,我们使用库中的auto_ptr也是会这样:
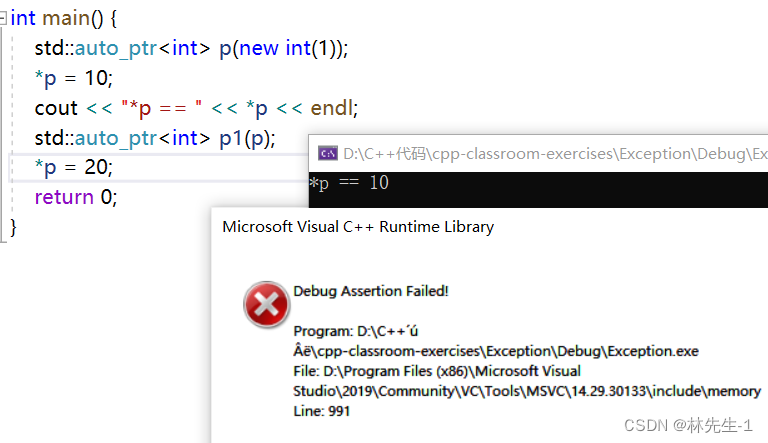
所以,很明显这个auto_ptr就是一个坑货,甚至很多公司都明确规定不要使用这个auto_ptr。
第二种——unique_ptr:
第二种这个unique_ptr从名字就可以看出,应该是一个“唯一的指针”,那它的实现方式就是把这个指针设计成唯一的。怎么设计成唯一的呢?
方法就是防止拷贝。
如果想要防止一个类不能被拷贝,则需要做到两点,第一将拷贝构造声明出来但不实现,因为拷贝构造是默认构造函数,如果不这样做编译器就会自动生成一个默认拷贝构造,而且是浅拷贝的。第二是将它设置为私有成员函数,因为如果不设置成私有,有可能会被别人在外部实现,而且设置成私有,比人也就不能在外部调用了。
template <class T>
class Unique_ptr {
public:
// 构造
Unique_ptr(T* ptr)
:_ptr(ptr)
{
}
T& operator*() {
return *_ptr;
}
T& operator[](int index) {
return _ptr[index];
}
T* operator->() {
return _ptr;
}
// 析构
~Unique_ptr() {
delete[] _ptr;
cout << "delete[]" << _ptr << endl;
}
private :
Unique_ptr(Unique_ptr& ap); // 只声明不实现
private:
T* _ptr;
};
同样,使用标准库中的unique_ptr也是一样的:
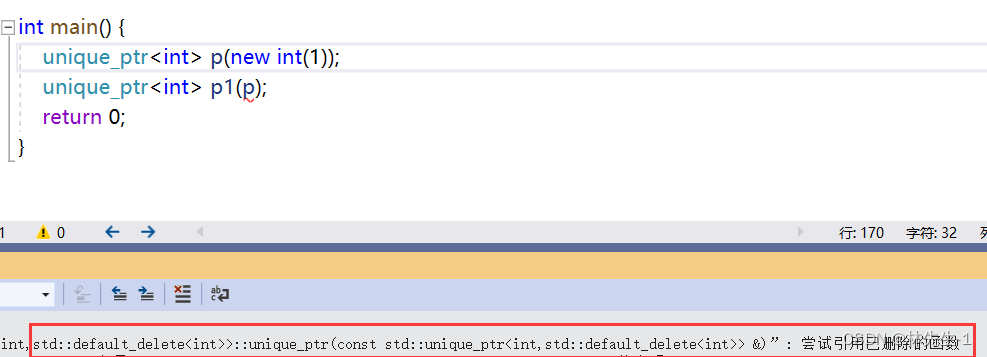
对此C++还提供了一个新的方法,防止拷贝的发生,就是在只声明不实现构造函数,然后再其后面加上一个 = delete:
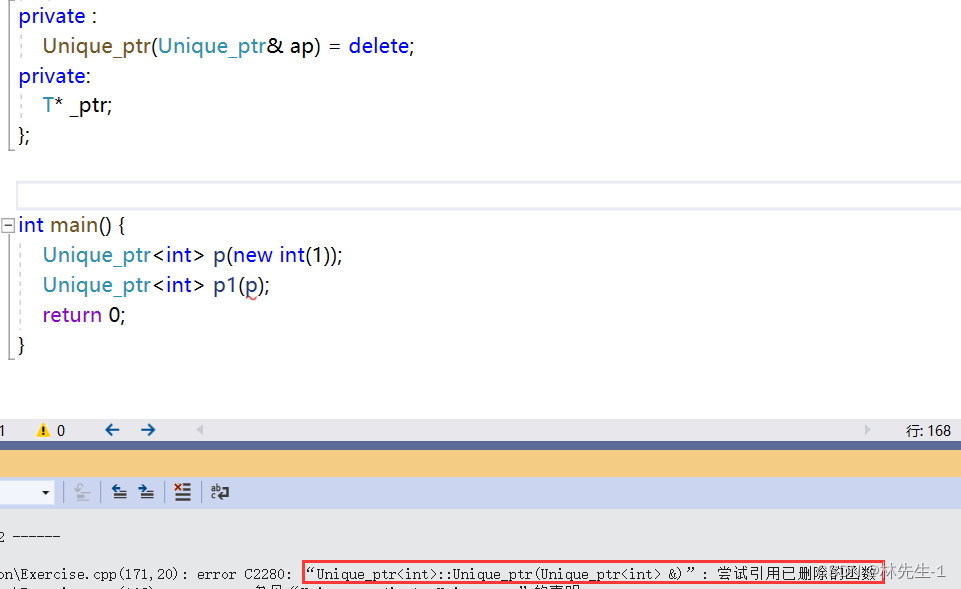
这也正是标准库中的unique_ptr使用的方法,加上了这个delete之后,则表示该函数已被删除。
但是完全的禁止拷贝也不是个好事,万一有一天我就想要拷贝呢?万一我就想实现多个智能指针指向同一块空间的场景呢?
第三种——shared_ptr:
第三种指针shared_ptr就是解决拷贝问题的最佳方案了,它是用引用计数来实现的,也就是有多少智能指针指向同一块空间,引用计数就为几,析构的时候只需要将引用计数做自减1不释放空间,只有当引用计数减到0时才会真正释放空间。
这个shared_ptr的实现就有点复杂了,我们不能简单的就把引用计数定义成类内的成员变量,因为每个类的成员变量都是互相独立的,那么一个对象在析构的时候就只会减少自己的引用计数,而其他对象的引用计数就不会改变,所以这种方法是不可行的。
而且也不能将引用计数在内类定义成静态的,因为静态成员或函数都是所类共享的,如果是一个对象拷贝另一个对象,是可以达到引用计数为2并且两个对象指向同一块空间的场景。但是如果你再创建出一个对象去指向了另一个空间,那么新对象就会将引用计数初始化成1,而静态成员变量是所有类共享的,所以所有对象的引用计数就都变成1了,这就出大事了!
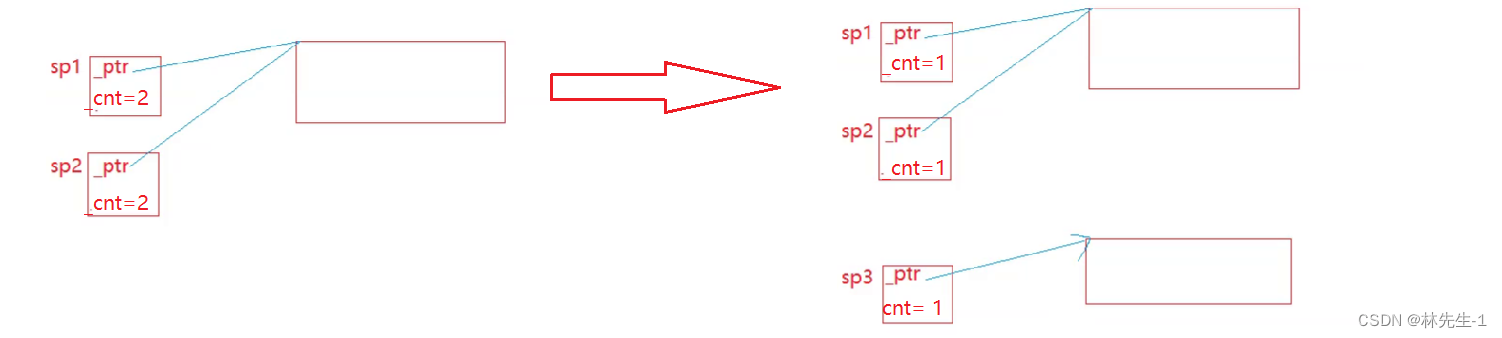
那么最好的方法就是将引用计数在堆上开辟,这样引用计数就能随着资源走了,我们没创建一个对象就在构造函数中开辟一个堆上的引用计数,在拷贝构造的时候就将引用计数传下去。
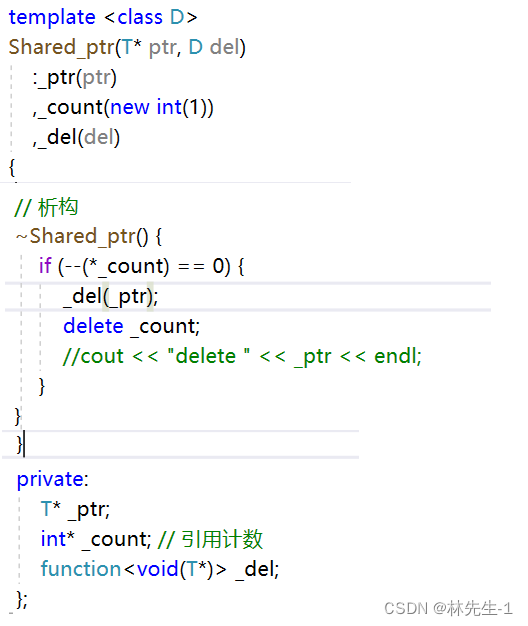
然后析构的时候就只需要先减减引用计数,后面再判断引用计数是否为0,如果为0就释放资源:
template <class T>
class Shared_ptr {
public:
// 构造
Shared_ptr(T* ptr)
:_ptr(ptr)
,_count(new int(1))
{
}
T& operator*() {
return *_ptr;
}
T& operator[](int index) {
return _ptr[index];
}
T* operator->() {
return _ptr;
}
// 拷贝构造
Shared_ptr(const Shared_ptr& sp)
:_ptr(sp._ptr)
,_count(sp._count)
{
(*_count)++;
}
// 析构
~Shared_ptr() {
if (--(*_count) == 0) {
delete[] _ptr;
delete _count;
cout << "delete[]" << _ptr << endl;
}
}
private:
T* _ptr;
int* _count; // 引用计数
};这样我们就能完美的实现多个智能指针指向同一个空间的场景了:
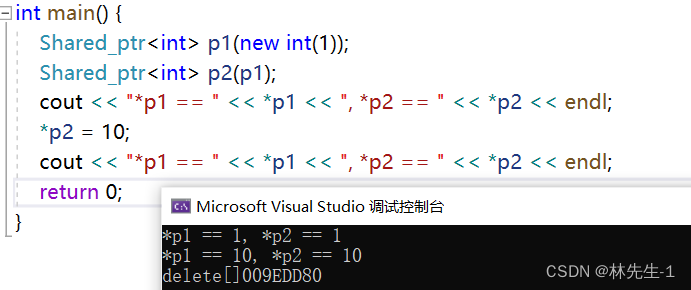
而且析构也只是析构了一个空间。
同理,使用标准库中的shared_ptr也是一样的:
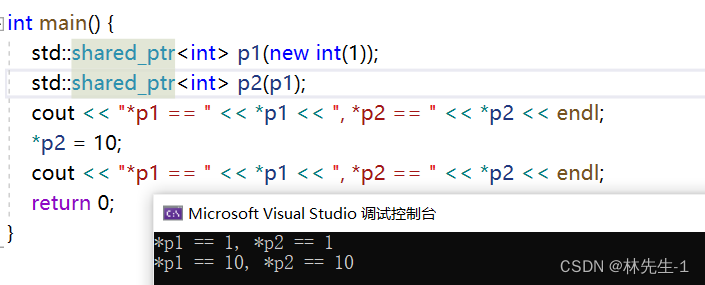
shared_ptr的赋值:
既然shared_ptr能支持拷贝,那么它也就能支持赋值,
// 赋值运算符重载
Shared_ptr<T>& operator=(const Shared_ptr<int>& sp) {
if (_count != sp._count) { // 不能自己给自己赋值
if (--(*_count) == 0) {
delete[] _ptr;
cout << "delete[]" << _ptr << endl;
delete _count;
}
_ptr = sp._ptr;
_count = sp._count;
(*_count)++;
}
return *this;
}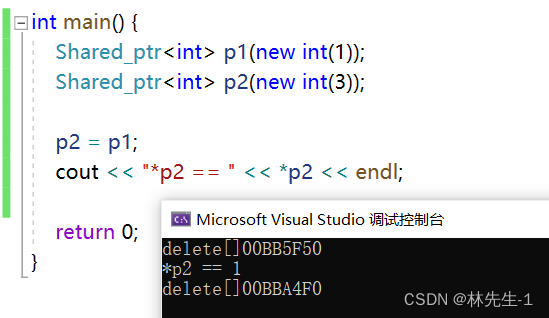
赋值最重要的是要判断是不是给自己赋值,因为如果是给自己赋值的话,假如一个对象的引用计数为1,那么自己给自己赋值就会导致自己的引用计数和所管理的指针都被释放了,因为我们上面的代码中是先减减_count在判断引用计数是否为0,如果对象的引用计数为1,那它的资源就被释放了。而后面又_count和_ptr,这就会导致后面再使用这个对象的时候会发生野指针异常。
而这里判断是不是给自己赋值的时候也不能像往常一样,使用this比较,因为智能指针本身就是用来管理指针资源的,所以就算是两个不同的对象,但是它们指向的空间也就是管理的资源相同,那它们其实也是属于同一个智能指针,所以两个管理相同资源的智能指针之间的赋值也是属于自己给自己赋值。
所以我们在判断是否是自己给自己赋值的时候,要用两个对象的_count判断或者_ptr判断。
share_ptr的循环引用问题:
尽管shared_ptr在各方面已经很完美了,但是它还是有一个严重的大缺陷——循环引用。
在一些场景可能会有两个对象互相指向的需求,最典型的就是双向链表。那这时候如果指针使用的是share_ptr,那就有可能产生循环引用的问题。
具体如下例:
如果我们担心在链表的操作过程中抛出异常导致内存泄漏,就可以将链表节点交给智能指针来管理。
但是这样做又会导致一个错误:

因为链表节点中的_next和_prev都是原生指针,而外部的n1和n2是智能指针,所以类型不兼容。
那么我们就要将链表内部的_next和_prev也都用智能指针管理起来:
struct ListNode {
ListNode(int val = 0)
:_val(val)
,_next(nullptr)
,_prev(nullptr)
{}
int _val;
Shared_ptr<ListNode> _next;
Shared_ptr<ListNode> _prev;
};正是因为这样,循环引用的问题就出现了!
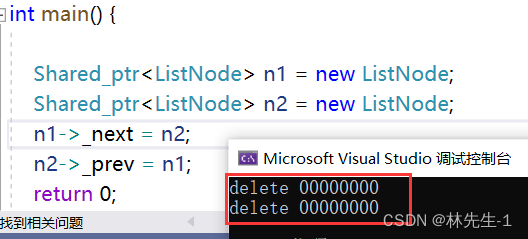
这里为什么会释放两个空指针呢?而且们再进一步观察,会发现链表的节点也没有被释放:
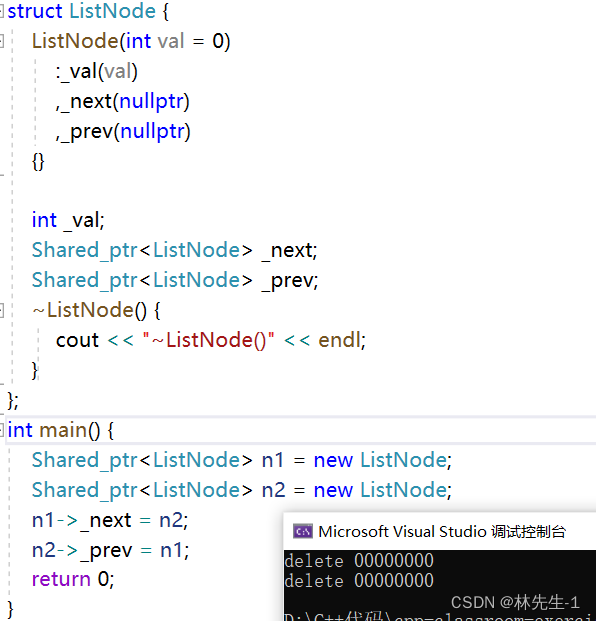
但如果我们去掉两个指向中的任意一个,发现程序又恢复正常了:
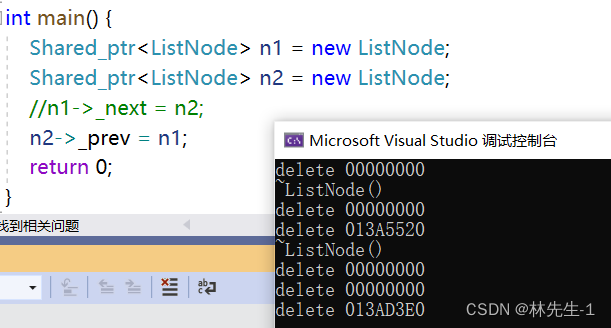
但为什么会这样呢?这需要画图慢慢分析,首先画出程序能正常结束的图,例如我们只让n1的_next指向n2:
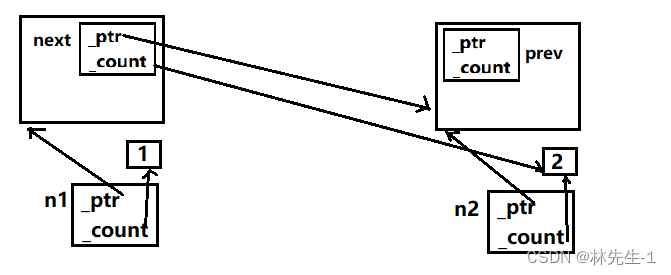
首先要点就是,在每个ListNode结构体中还有两个智能指针_next和_prev,但是这里只画出了有连接的那个,也就是n1的_next和n1的_prev。
那么结构体中的智能指针的析构十几一定是要这个结构体析构的时候才会析构。也就是n1中的_next要n1析构了它才会析构,n2中的_prev要n2析构了它才会析构。
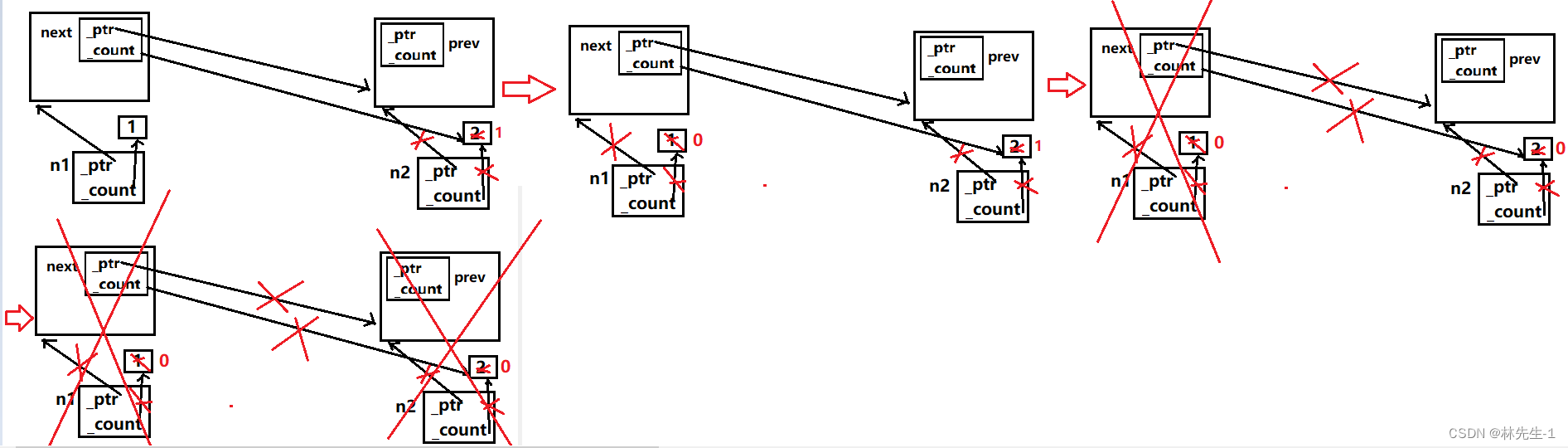
所以上图的析构顺序就是:n2析构,n2的引用计数减减到1(还没释放资源)、接着n1析构,n1的引用计数减减到0(释放资源)、然后n1的_next析构,导致n2的引用计数减减到0,那么n2也就会释放资源、最后就是n2的prev析构。
按步骤画图分析大致如下:
这种情况还是正常的,但是如果我们再让n2的prev指向n1,那就回出问题了。
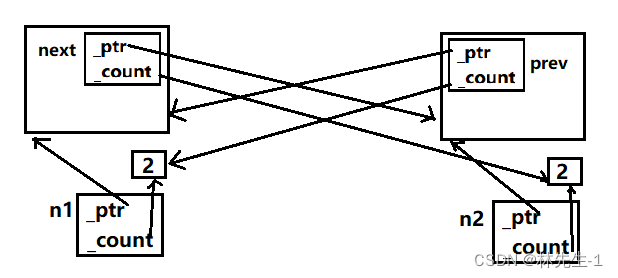
我们只需要按照流程在走一遍上述过程就能发现问题出在哪里了:
首先是n2先析构,n2的引用计数减到1,接着是n1析构,n1的引用计数减到1,然后就没有然后了,因为两个引用计数没有一个为0,也就不会再去释放结构体资源了,就卡死了!
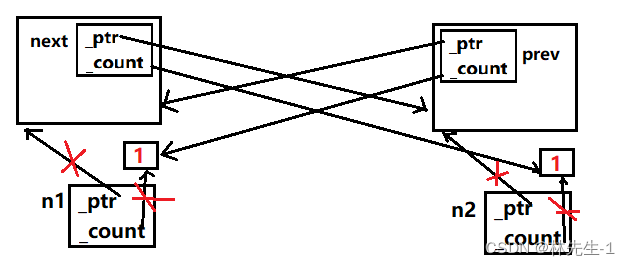
所以如果两个指针都连接的话,程序是没有任何析构的,既没有析构结构体也没析构智能指针:
template <class T>
class Shared_ptr {
public:
// 默认构造
Shared_ptr()
:_ptr(nullptr)
,_count(nullptr)
{}
Shared_ptr(T* ptr)
:_ptr(ptr)
,_count(new int(1))
{
}
T& operator*() {
return *_ptr;
}
T& operator[](int index) {
return _ptr[index];
}
T* operator->() {
return _ptr;
}
// 拷贝构造
Shared_ptr(const Shared_ptr& sp)
:_ptr(sp._ptr)
,_count(sp._count)
{
(*_count)++;
}
// 赋值运算符重载
Shared_ptr<T>& operator=(const Shared_ptr<T>& sp) {
if (_count != sp._count) { // 不能自己给自己赋值
if (--(*_count) == 0) {
delete _ptr;
//cout << "delete " << _ptr << endl;
delete _count;
}
_ptr = sp._ptr;
_count = sp._count;
(*_count)++;
}
return *this;
}
// 析构
~Shared_ptr() {
if (--(*_count) == 0) {
delete _ptr;
delete _count;
cout << "delete " << _ptr << endl;
}
}
private:
T* _ptr;
int* _count; // 引用计数
};
struct ListNode {
ListNode(int val = 0)
:_val(val)
,_next(nullptr)
,_prev(nullptr)
{}
int _val;
Shared_ptr<ListNode> _next;
Shared_ptr<ListNode> _prev;
~ListNode() {
cout << "~ListNode()" << endl;
}
};
int main() {
Shared_ptr<ListNode> n1 = new ListNode;
Shared_ptr<ListNode> n2 = new ListNode;
n1->_next = n2;
n2->_prev = n1;
return 0;
}
简单的总结一句话就是:n1的_next要等n1释放了它才会释放,而n1又要等n2的prev释放了它才会释放,n2的prev要等n2释放了它才会释放,而n2又要等n1的next释放后他才会释放。
间接的描述就是n1的next要等n2的prev释放后,它才会释放,n2的prev要等n1的next释放后它才会释放。
所也就形成了一个类似你不让我我也不让你的“死锁”的场景!
同样的,库中的shared_ptr一样有这样的问题:
虽然库中的智能指针并没有打印出析构的信息,但是我们通过观察ListNode的析构信息也能知道,并没有一个节点被析构。
那么为了解决这样的问题,C++标准库又专门提供另一个weak_ptr,我们只需要将ListNode中的智能指针换成weak_ptr就行了:
为什么只是ListNode里面的指针需要用weak_ptr呢,而外面的n1n2不需要呢?
因为这里的问题主要是因为结构体中嵌套了智能指针,导致里面的智能指针需要等外面的智能指针释放后才能释放引起的。
所以我们对里面的指针就不需要增加引用计数,而weak_ptr在设计的时候其实是不能用原生质之恩来构造的,weak_ptr的构造其实使用shared_ptr来构造的:

也就是说明weak_ptr并不做资源的管理,他只是专门辅助shared_ptr解决循环引用问题的。
那么这个weak_ptr是怎么实现的呢?其实很简单,我们上面的问题就是因为引用计数增加导致引用计数不为零而不能释放资源。所以weak_ptr的核心思想就是资管理资源而不增加引用计数。
我们其实可以打印出这两个智能指针的引用计数来看看:
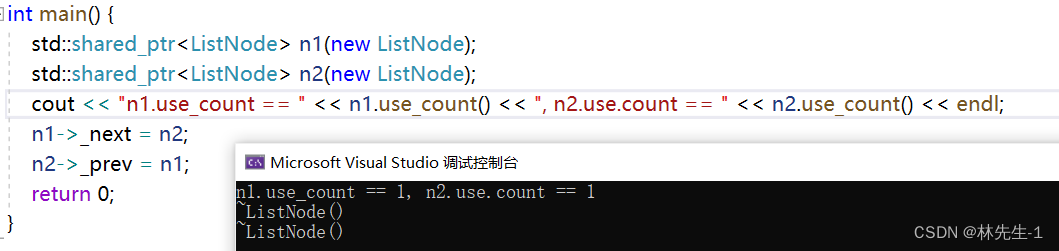
有了原理,那我们实现一个weak_ptr就比较简单了,我们先来实现一个简单的weak_ptr,让它能达到库中weak_ptr的目的:
template <class T>
class Weak_ptr {
public :
Weak_ptr(const Shared_ptr<T>& sp)
:_ptr(sp.get())
{}
T& operator*() {
return *_ptr;
}
T& operator[](int index) {
return _ptr[index];
}
T* operator->() {
return _ptr;
}
Weak_ptr<T>& operator=(const Shared_ptr<T>& sp) {
_ptr = sp.get();
return *this;
}
private :
T* _ptr;
};template <class T>
class Shared_ptr {
public:
// 默认构造
Shared_ptr()
:_ptr(nullptr)
,_count(nullptr)
{}
Shared_ptr(T* ptr)
:_ptr(ptr)
,_count(new int(1))
{
}
T& operator*() {
return *_ptr;
}
T& operator[](int index) {
return _ptr[index];
}
T* operator->() {
return _ptr;
}
// 拷贝构造
Shared_ptr(const Shared_ptr& sp)
:_ptr(sp._ptr)
,_count(sp._count)
{
(*_count)++;
}
// 赋值运算符重载
Shared_ptr<T>& operator=(const Shared_ptr<T>& sp) {
if (_count != sp._count) { // 不能自己给自己赋值
if (--(*_count) == 0) {
delete _ptr;
//cout << "delete " << _ptr << endl;
delete _count;
}
_ptr = sp._ptr;
_count = sp._count;
(*_count)++;
}
return *this;
}
T* get() const {
return _ptr;
}
int use_count() {
return *_count;
}
// 析构
~Shared_ptr() {
if (--(*_count) == 0) {
delete _ptr;
delete _count;
cout << "delete " << _ptr << endl;
}
}
private:
T* _ptr;
int* _count; // 引用计数
};
template <class T>
class Weak_ptr {
public :
Weak_ptr(const Shared_ptr<T>& sp)
:_ptr(sp.get())
{}
T& operator*() {
return *_ptr;
}
T& operator[](int index) {
return _ptr[index];
}
T* operator->() {
return _ptr;
}
Weak_ptr<T>& operator=(const Shared_ptr<T>& sp) {
_ptr = sp.get();
return *this;
}
private :
T* _ptr;
};
struct ListNode {
ListNode(int val = 0)
:_val(val)
,_next(nullptr)
,_prev(nullptr)
{}
int _val;
Weak_ptr<ListNode> _next;
Weak_ptr<ListNode> _prev;
~ListNode() {
cout << "~ListNode()" << endl;
}
};
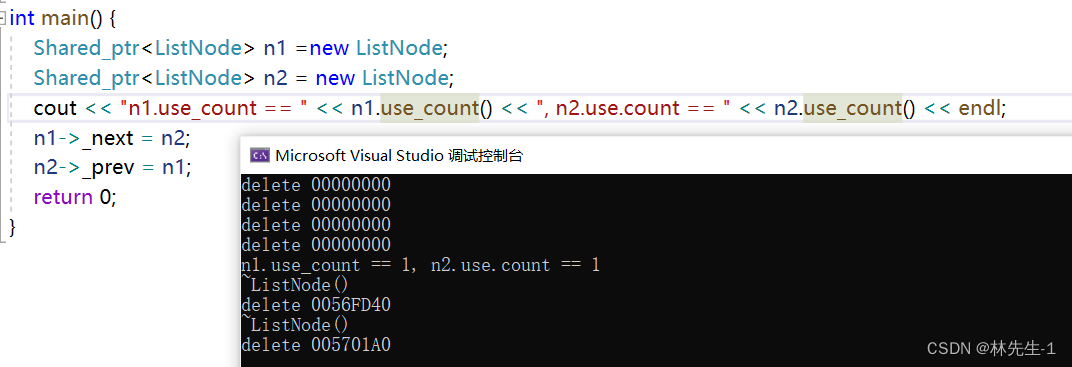
int main() {
Shared_ptr<ListNode> n1 =new ListNode;
Shared_ptr<ListNode> n2 = new ListNode;
cout << "n1.use_count == " << n1.use_count() << ", n2.use.count == " << n2.use_count() << endl;
n1->_next = n2;
n2->_prev = n1;
return 0;
}运行结果:
2.4、定制删除器
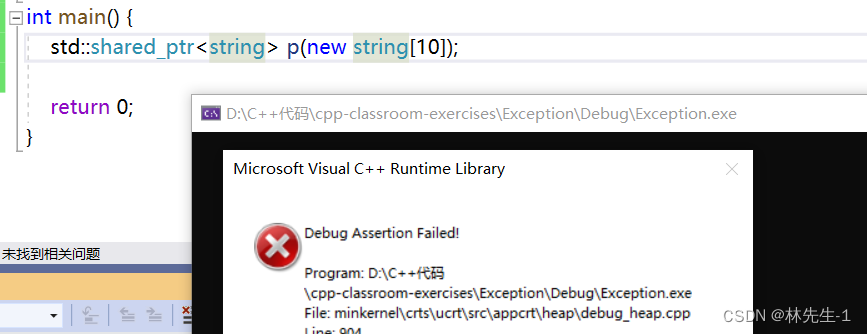
之前我们交给智能指针管理的指针都是一些单独的指针,所以在智能指针里面使用delete直接释放是不会出问题的,但是如果我们想要把new出来的数组交给智能指针,就会出问题了,数组要用delete[]来释放,而我们在智能指针中有没有什么好的方法来判断指针是数组还是单独的变量指针。
库中同样有这样的问题:
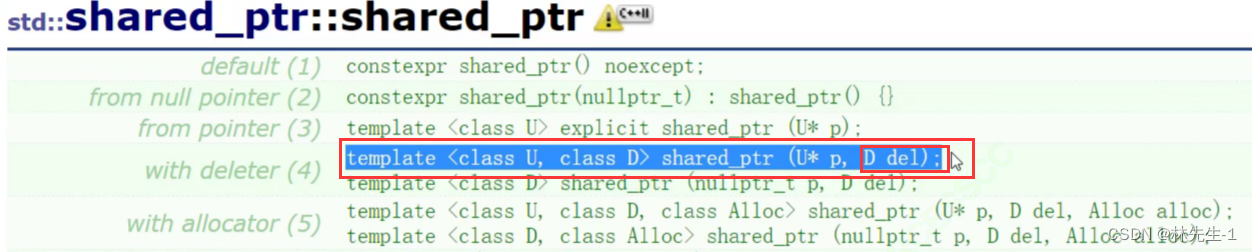
想要解决这样的问题,就要用到一个名字叫做定制删除器的东西。
这个定制删除器其实是个可调用对象,是通过在智能指针的构造函数中传入一个这样的可调用对象,然后在智能指针类中调用这个可调用对象来实现定制删除的。
那我们先来简单的实现一个删除器,把它传给库中的智能指针:
template <class T>
struct DelArray {
void operator()(T* ptr) {
delete[] ptr;
}
};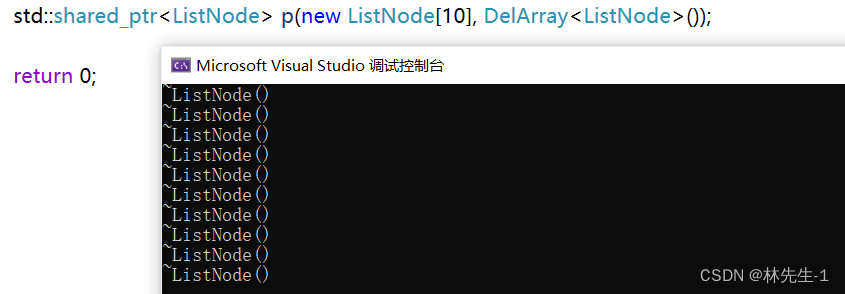
当然,既然是可调用对象,那我们也可以使用更加方便的lambda:
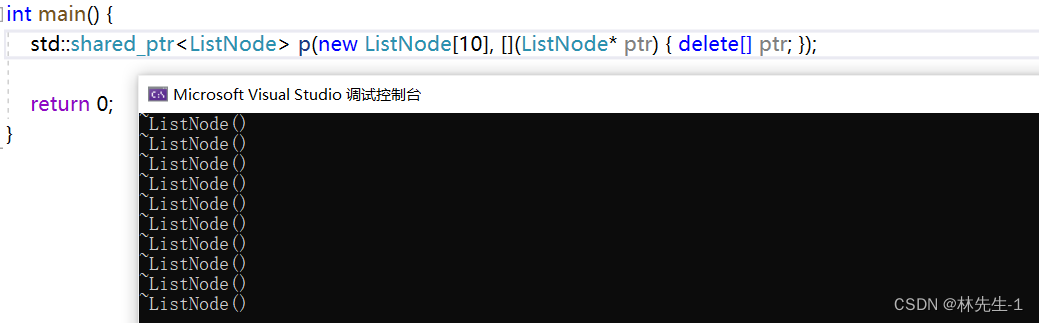
按我们如何在自己写的智能指针里面实现定制删除呢?
其实实现方法也并不难。首先我们得要弄清楚这个定制删除器并不是传给整个类的,而是只单独传给构造函数,不然的话就要在定义类的时候就要传入了。
所以我们得单独把构造函数设计成函数模板:

但是这样又会导致一个问题,就是我们这个del只是传给了构造函数,而我们最终要在析构函数内释放资源,但是析构函数并没有拿到这个删除器啊,而且析构函数是自动调用的,类外并不能手动调用,所以也就用不到。
我们可以使用包装器解决这个问题,