1 Separate Compilation
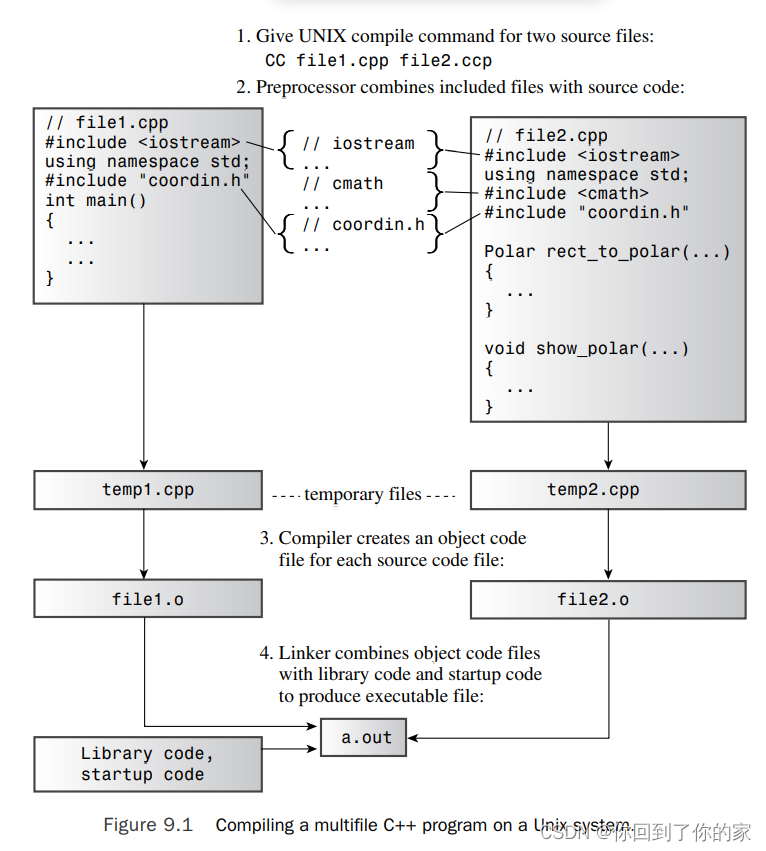
C++, like C, allows and even encourages you to locate the component functions of a program in separate files.You can compile the files separately and then link them into the final executable program. If you modify just one file, you can recompile just that one file and then link it to the previously compiled versions of the other files.This facility makes it easier to manage large programs. Furthermore, most C++ environments provide additional facilities to help with the management.Unix and Linux systems,for example,have make programs,which keep track of which files a program depends on and when they were last modified. If you run make, and it detects that you’ve changed one or more source files since the last compilation, make remembers the proper steps needed to reconstitute the program. Most integrated development environments (IDEs), like Microsoft Visual C++,provide similar facilities with their Project menus.
Let’s look at a simple example. Instead of looking at compilation details, which depend on the implementation, let’s concentrate on more general aspects, such as design.
Suppose, for example, that you decide to break up the program in Listing 7.12 by placing the two supporting functions in a separate file. Listing 7.12 将直角坐标转化为极坐标并显示结果.You can’t simply cut the original file on a dotted line after the end of main().The problem is that main() and the other two functions use the same structure declarations, so you need to put the declarations in both files. Simply typing them in is an invitation to error. Even if you copy the structure declarations correctly, you have to remember to modify both sets of declarations if you make changes later. In short, spreading a program over multiple files creates new problems.
//Listing 7.12 strctfun.cpp
// strctfun.cpp -- functions with a structure argument
#include <iostream>
#include <cmath>
// structure declarations
struct polar{
double distance; // distance from origin
double angle; // direction from origin
};
struct rect{
double x; // horizontal distance from origin
double y; // vertical distance from origin
};
// prototypes
polar rect_to_polar(rect xypos);
void show_polar(polar dapos);
int main(){
using namespace std;
rect rplace;
polar pplace;
cout << "Enter the x and y values: ";
while (cin >> rplace.x >> rplace.y){
pplace = rect_to_polar(rplace);
show_polar(pplace);
cout << "Next two numbers (q to quit): ";
}
cout << "Done.\n";
return 0;
}
// convert rectangular to polar coordinates
polar rect_to_polar(rect xypos){
using namespace std;
polar answer;
answer.distance = sqrt( xypos.x * xypos.x + xypos.y * xypos.y);
answer.angle = atan2(xypos.y, xypos.x);
return answer; // returns a polar structure
}
// show polar coordinates, converting angle to degrees
void show_polar (polar dapos){
using namespace std;
const double Rad_to_deg = 57.29577951;
cout << "distance = " << dapos.distance;
cout << ", angle = " << dapos.angle * Rad_to_deg;
cout << " degrees\n";
}
The developers of C and C++ provided the #include facility to deal with this situation.Instead of placing the structure declarations in each file, you can place them in a header file and then include that header file in each source code file.That way, if you modify the structure declaration, you can do so just once, in the header file.Also you can place the function prototypes in the header file. Thus,you can divide the original program into three parts:
- A header file that contains the structure declarations and prototypes for functions that use those structures
- A source code file that contains the code for the structure-related functions
- A source code file that contains the code that calls the structure-related functions
这是一种非常有用的组织程序的策略。例如,如果编写另一个程序时也需要使用这些函数,则只需包含头文件,并将函数文件添加到项目列表或make列表中即可。
程序9.1 coordin.h



// coordin.h -- structure templates and function prototypes
// structure templates
#ifndef COORDIN_H_
#define COORDIN_H_
struct polar{
double distance; // distance from origin
double angle; // direction from origin
};
struct rect{
double x; // horizontal distance from origin
double y; // vertical distance from origin
};
// prototypes
polar rect_to_polar(rect xypos);
void show_polar(polar dapos);
#endif
头文件管理
在同一个文件中只能将同一个头文件包含一次。记住这个规则很容易,但很可能在不知情的情况下将头文件包含多次。例如,可能使用包含了另外一个头文件的头文件。有一种标准的C/C++技术可以避免多次包含同一个头文件。它是基于预处理器编译指令#ifndef的。下面的代码片段意味着仅当以前没有使用预处理器编译指令#ifdefine定义名称COORDIN_H_时,才处理#ifndef和#endif之间的语句:
#ifndef COORDIN_H_
...
#endif
通常,使用#define来创建符号常量,如下所示:
#define MAXIMUM 4096
但只要将#define用于名称,就足以完成该名称的定义,如下所示:
#define COORDIN_H_
程序9.1使用这种技术是为了将文件内容包含在#ifndef中:
#ifndef COORDIN_H_
#define COORDIN_H_
//place include file contents here
#endif
编译器首次遇到该文件时,名称COORDIN_H_没有定义。在这种情况下,编译器将查看#ifndef和#endif之间的内容,并读取定义COORDIN_H_的一行。如果在同一个文件中遇到其他包含coordin.h的代码,编译器将知道COORDIN_H_已经被定义了,从而跳到#endif后面的一行上。注意,这种方式并不能防止编译器将文件包含两次,而只是让它忽略除第一次包含之外的所有内容。大多数标准C和C++头文件都使用这种防护方案。否则,可能在一个文件中定义同一个结构两次,这将导致编译错误。
程序9.2 file1.cpp
// file1.cpp 一个三程序例子
#include <iostream>
#include "coordin.h" // structure templates, function prototypes
using namespace std;
int main(){
rect rplace;
polar pplace;
cout << "Enter the x and y values: ";
while (cin >> rplace.x >> rplace.y){
pplace = rect_to_polar(rplace);
show_polar(pplace);
cout << "Next two numbers (q to quit): ";
}
cout << "Bye!\n";
return 0;
}
程序9.3 file2.cpp
// file2.cpp -- contains functions called in file1.cpp
#include <iostream>
#include <cmath>
#include "coordin.h" // structure templates, function prototypes
// convert rectangular to polar coordinates
polar rect_to_polar(rect xypos){
using namespace std;
polar answer;
answer.distance =
sqrt( xypos.x * xypos.x + xypos.y * xypos.y);
answer.angle = atan2(xypos.y, xypos.x);
return answer; // returns a polar structure
}
// show polar coordinates, converting angle to degrees
void show_polar (polar dapos){
using namespace std;
const double Rad_to_deg = 57.29577951;
cout << "distance = " << dapos.distance;
cout << ", angle = " << dapos.angle * Rad_to_deg;
cout << " degrees\n";
}
将这两个源代码和新的头文件一起进行编译和链接,将生成一个可执行程序。下面是该程序的运行情况:
Enter the x and y values: 120 80
distance = 144.222, angle = 33.6901 degrees
Next two numbers (q to quit): 120 50
distance = 130, angle = 22.6199 degrees
Next two numbers (q to quit): q

2 Storage Duration, Scope, and Linkage
C++ uses three separate schemes (four under C++11) for storing data, and the schemes differ in how long they preserve data in memory:
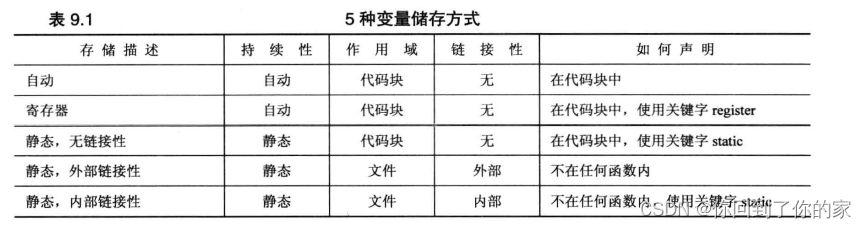
- 自动存储持续性:在函数定义中声明的变量(包括函数参数)的存储持续性为自动的。它们在程序开始执行其所属的函数或代码块时被创建,在执行完函数或代码块时,它们使用的内存被释放。C++有两种存储持续性为自动的变量。
- 静态存储持续性:在函数定义外定义的变量和使用关键字static 定义的变量的存储持续性都为静态。它们在程序整个运行过程中都存在。C++有3种存储持续性为静态的变量。
- 线程存储持续性(C++11): 当前,多核处理器很常见,这些CPU可同时处理多个执行任务。这让程序能够将计算放在可并行处理的不同线程中。如果变量是使用关键字thread_ local 声明的,则其生命周期与所属的线程一样长。本书不探讨并行编程。
- 动态存储持续性:用new运算符分配的内存将一直存在, 直到使用delete运算符将其释放或程序结束为止。这种内存的存储持续性为动态,有时被称为自由存储(free store)或堆(heap)。
2.1 作用域和链接
Scope describes how widely visible a name is in a file (translation unit). For example, a variable defined in a function can be used in that function but not in another, whereas a variable defined in a file above the function definitions can be used in all the functions. Linkage
describes how a name can be shared in different units. A name with external linkage can be shared across files, and a name with internal linkage can be shared by functions within a single file. Names of automatic variables have no linkage because they are not shared.
(在C++中,automatic variables(自动变量)是指那些在函数体内声明,且没有静态存储期的局部变量。其生命周期从声明点开始,到它们所在的代码块结束时终止。这意味着它们在函数被调用时自动创建(分配内存),并在函数执行结束后自动销毁(释放内存)。因此,它们也被称作局部自动变量。
void exampleFunction() {
int localVar = 10; // localVar 是一个自动变量
// ...
} // 当函数结束时,localVar 被自动销毁
)
A C++ variable can have one of several scopes. A variable that has local scope (also termed block scope) is known only within the block in which it is defined. Recall that a
block is a series of statements enclosed in braces. A function body, for example, is a block, but you can have other blocks nested within the function body. A variable that has global scope (also termed file scope) is known throughout the file after the point where it is defined. Automatic variables have local scope, and a static variable can have either scope, depending on how it is defined. Names used in a function prototype scope are known just
within the parentheses enclosing the argument list. (That’s why it doesn’t really matter what they are or if they are even present.) Members declared in a class have class scope (see Chapter 10,“Objects and Classes”).Variables declared in a namespace have namespace scope.
(Now that namespaces have been added to the C++ language, the global scope has
become a special case of namespace scope.)
C++ functions can have class scope or namespace scope, including global scope, but they can’t have local scope. (Because a function can’t be defined inside a block, if a function were to have local scope, it could only be known to itself and hence couldn’t be called by another function. Such a function couldn’t function.)
The various C++ storage choices are characterized by their storage duration, their scope, and their linkage. Let’s look at C++’s storage classes in terms of these properties. We
begin by examining the situation before namespaces were added to the mix and then see how namespaces modify the picture.
2.2
2.3 静态持续变量
和C语言一样,C++也为静态存储持续性变量提供了三种链接性:外部链接性(可在其他文件中访问)、内部链接性(只能在当前文件中访问)和无链接性(只能在当前函数或代码块中访问)。这三种链接性都在整个程序执行期间存在,与自动变量相比,它们的寿命更长。由于静态变量的数目在程序运行期间是不变的,因此程序不需要使用特殊的装置(例如栈)来管理它们。编译器将分配固定的内存块来存储所有的静态变量,这些变量在整个程序执行期间一直存在。另外,如果没有显式地初始化静态变量,编译器将把它设置为0。在默认情况下,静态数组和结构将每个元素或成员的所有位都设置为0。
下面介绍如何创建这三种静态持续变量,然后介绍它们的特点。
- 要想创建链接性为外部的静态持续变量,必须在代码块的外面声明它
- 要想创建链接性为内部的静态持续变量,必须在代码块的外部声明它,并使用static限定符
- 要创建没有链接性的静态持续变量,必须在代码块内声明它,并使用static限定符。
下面用代码说明这三种变量:
...
int global=1000; //外部链接
static int one_file=50; //内部链接
int main(){
...
}
void funct1(int n){
static int count=0; //无链接
int llama=0;
...
}
void funct2(int q){
...
}
待补充 326


静态变量的初始化
除默认的零初始化外,还可对静态变量进行常量表达式初始化和动态初始化。零初始化意味着将变量设置为零,对于标量类型,零将被强制转换为合适的类型。例如,在C++代码中,空指针用0表示,但内部可能采用非零表示,因此指针变量将被初始化相应的内部表示。结构成员被零初始化,且填充位都被设置为零。
零初始化和常量表达式初始化被统称为静态初始化,这意味着在编译器处理文件(翻译单元)时初始化变量。动态初始化意味着变量将在编译后初始化。
那么初始化形式由什么因素决定呢?首先,所有静态变量都被零初始化,而不管程序员是否显式地初始化了它。接下来,如果使用常量表达式初始化了变量,且编译器仅根据文件内容(包括被包含的头文件)就可计算表达式,编译器将执行常量表达式初始化。必要时,编译器将执行简单计算。如果没有足够的信息,变量将被动态初始化。观看如下代码:
#include<cmath>
int x; //零初始化
int y=15; //常量表达式初始化
long z=13*13; //常量表达式初始化
const double pi = 4.0*atan(1.0); //动态初始化

3 Namespaces
Names in C++ can refer to variables, functions, structures, enumerations, classes, and class and structure members. When programming projects grow large, the potential for name conflicts increases. When you use class libraries from more than one source, you can get name conflicts. For example, two libraries might both define classes named List, Tree, and Node, but in incompatible ways. You might want the List class from one library and the Tree from the other, and each might expect its own version of Node. Such conflicts are termed namespace problems.
The C++ Standard provides namespace facilities to provide greater control over the scope of names. It took a while for compilers to incorporate namespaces, but, by now, support has become common.
3.1 Traditional C++ Namespaces(完成)
Before looking at the new namespace facilities in C++, let’s review the namespace properties that already exist in C++ and introduce some terminology.
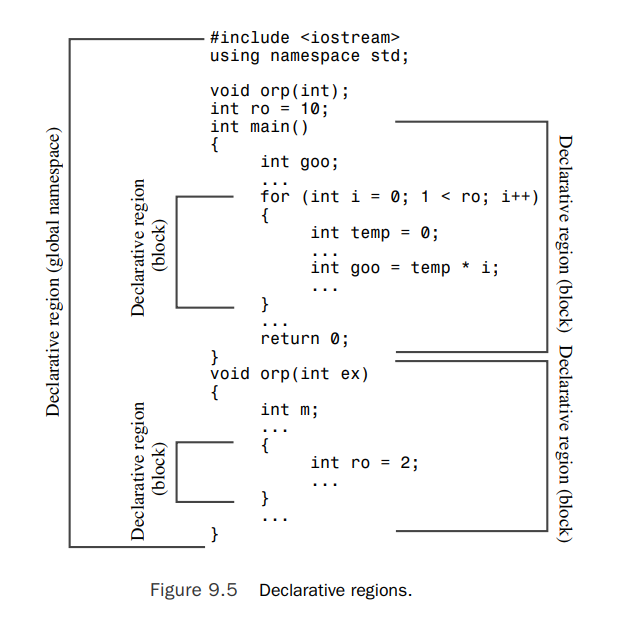
- declarative region: A declarative region is a region in which declarations can be made. For example, you can declare a global variable outside any function. The declarative region for that variable is the file in which it is declared. If you declare a variable inside a function, its declarative region is the innermost block in which it is declared.
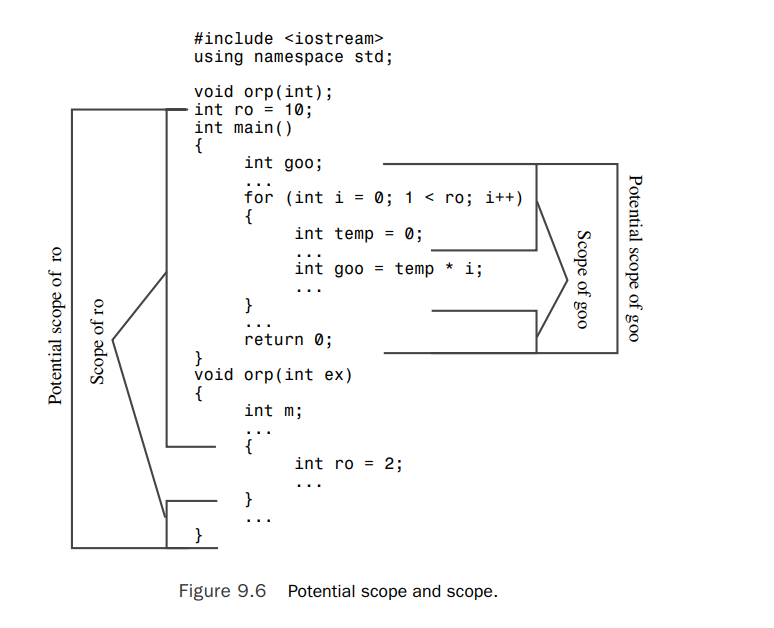
- potential scope: The potential scope for a variable begins at its point of declaration and extends to the end of its declarative region. So the potential scope is more limited than the declarative region because you can’t use a variable above the point where it is first defined.
- scope: However, a variable might not be visible everywhere in its potential scope(例如我们在最外层声明了一个变量name,那么在内层再次声明的变量name就会覆盖掉上层的name变量).The portion of the program that can actually see the variable is termed the scope. Figures 9.5 and 9.6 illustrate the terms declarative region, potential scope, and scope.
C++’s rules about global and local variables define a kind of namespace hierarchy. Each declarative region can declare names that are independent of names declared in other declarative regions. A local variable declared in one function doesn’t conflict with a local variable declared in a second function.
3.2 New Namespace Features(完成)
C++ now adds the ability to create named namespaces by defining a new kind of declarative region, one whose main purpose is to provide an area in which to declare names. The names in one namespace don’t conflict with the same names declared in other namespaces, and there are mechanisms for letting other parts of a program use items declared in a namespace. The following code, for example, uses the new keyword namespace to create two namespaces, Jack and Jill:
namespace Jack {
double pail; // variable declaration
void fetch(); // function prototype
int pal; // variable declaration
struct Well { ... }; // structure declaration
}
namespace Jill {
double bucket(double n) { ... } // function definition
double fetch; // variable declaration
int pal; // variable declaration
struct Hill { ... }; // structure declaration
}
Namespaces can be located at the global level or inside other namespaces, 但不能位于代码块中. Thus, a name declared in a namespace has external linkage by default (unless it refers to a constant).
In addition to user-defined namespaces, there is one more namespace, the global namespace. This corresponds to the file-level declarative region, so what used to be termed global variables are now described as being part of the global namespace.
The names in any one namespace don’t conflict with names in another namespace. Thus, the fetch in Jack can coexist with the fetch in Jill, and the Hill in Jill can coexist with an external Hill. The rules governing declarations and definitions in a namespace are the same as the rules for global declarations and definitions.
Namespaces are open, meaning that you can add names to existing namespaces. For example, the following statement adds the name goose to the existing list of names in Jill:
namespace Jill {
char * goose(const char *);
}
Similarly, the original Jack namespace provides a prototype for a fetch() function. You can provide the code for the function later in the file (or in another file) by using the Jack namespace again:
namespace Jack {
void fetch(){
...
}
}
Of course, you need a way to access names in a given namespace. The simplest way is to use ::, the scope-resolution operator, to qualify a name with its namespace:
Jack::pail = 12.34; // use a variable
Jill::Hill mole; // create a type Hill structure
Jack::fetch(); // use a function
一个不带修饰的名字,例如 pail,被称为unqualified name;而一个带有namespace的名字,如 Jack::pail,则被称为qualified name。
3.3 using Declarations and using Directives(完成)
Having to qualify names every time they are used is not good, so C++ provides two mechanisms—the using declaration and the using directive—to simplify using namespace names. The using declaration lets you make particular identifiers available, and the using directive makes the entire namespace accessible.
The using declaration involves preceding a qualified name with the keyword using:
using Jill::fetch; // a using declaration
A using declaration adds a particular name to the declarative region in which it occurs. For example, the using declaration of Jill::fetch in main() adds fetch to the declarative region defined by main(). After making this declaration, you can use the name fetch instead of Jill::fetch.The following code fragment illustrates these points:
namespace Jill {
double bucket(double n) { ... }
double fetch;
struct Hill { ... };
}
char fetch;
int main(){
using Jill::fetch; // put fetch into local namespace
double fetch; // Error! Already have a local fetch
cin >> fetch; // read a value into Jill::fetch
cin >> ::fetch; // read a value into global fetch
...
}
Because a using declaration adds the name to the local declarative region, this example precludes creating another local variable by the name of fetch. Also like any other local variable, fetch would override a global variable by the same name. Placing a using declaration at the external level adds the name to the global namespace:
void other();
namespace Jill {
double bucket(double n) { ... }
double fetch;
struct Hill { ... };
}
using Jill::fetch; // put fetch into global namespace
int main(){
cin >> fetch; // read a value into Jill::fetch
other()
...
}
void other(){
cout << fetch; // display Jill::fetch
...
}
A using declaration, then, makes a single name available. In contrast, the using directive makes all the names available. A using directive involves preceding a namespace name with the keywords using namespace, and it makes all the names in the namespace available without the use of the scope-resolution operator:
using namespace Jack; // make all the names in Jack available
Placing a using directive at the global level makes the namespace names available globally:
#include <iostream> // places names in namespace std
using namespace std; // make names available globally
Placing a using directive in a particular function makes the names available just in that function:
int main(){
using namespace jack; // make names available in main()
...
}
One thing to keep in mind about using directives and using declarations is that they increase the possibility of name conflicts. That is, if you have both namespace jack and namespace jill available,and you use the scope-resolution operator, there is no ambiguity:
jack::pal = 3;
jill::pal =10;
The variables jack::pal and jill::pal are distinct identifiers for distinct memory locations. However, if you employ using declarations, the situation changes:
using jack::pal;
using jill::pal;
pal = 4; // which one? now have a conflict
In fact, the compiler won’t let you use both of these using declarations because of the ambiguity that would be created.
3.4 using Directives Versus using Declarations
Using a using directive to import all the names from a namespace wholesale is not the same as using multiple using declarations. It’s more like the mass application of a scope-resolution operator. When you use a using declaration, it is as if the name is declared at the location of the using declaration. If a particular name is already declared in a function, you can’t import the same name with a using declaration. When you use a using directive, however, name resolution takes place as if you declared the names in the smallest declarative region containing both the using declaration and the namespace itself. For the following example, that would be the global namespace. If you use a using directive to import a name that is already declared in a function, the local name will hide the namespace name, just as it would hide a global variable of the same name. However, you can still use the scope-resolution operator,as in the following example:
namespace Jill {
double bucket(double n) { ... }
double fetch;
struct Hill { ... };
}
char fetch; // global namespace
int main(){
using namespace Jill; // import all namespace names
Hill Thrill; // create a type Jill::Hill structure
double water = bucket(2); // use Jill::bucket();
double fetch; // not an error; hides Jill::fetch
cin >> fetch; // read a value into the local fetch
cin >> ::fetch; // read a value into global fetch
cin >> Jill::fetch; // read a value into Jill::fetch
...
}
int foom(){
Hill top; // ERROR
Jill::Hill crest; // valid
}
Here, in main(), the name Jill::fetch is placed in the local namespace. It doesn’t have local scope, so it doesn’t override the global fetch. But the locally declared fetch
hides both Jill::fetch and the global fetch. However, both of the last two fetch variables are available if you use the scope-resolution operator. You might want to compare
this example to the preceding one, which uses a using declaration.
One other point of note is that although a using directive in a function treats the namespace names as being declared outside the function, it doesn’t make those names available to other functions in the file. Hence in the preceding example, the foom() function can’t use the unqualified Hill identifier.
Note
Suppose a namespace and a declarative region both define the same name. If you attempt to use ausingdeclaration to bring the namespace name into the declarative region, the two names conflict, and you get an error. If you use ausingdirective to bring the namespace name into the declarative region, the local version of the name hides the namespace version.
Generally speaking, the using declaration is safer to use than a using directive because it shows exactly what names you are making available. And if the name conflicts with a local name, the compiler lets you know. The using directive adds all names, even ones you might not need. If a local name conflicts, it overrides the namespace version, and you aren’t warned. Also the open nature of namespaces means that the complete list of names
in a namespace might be spread over several locations, making it difficult to know exactly which names you are adding.
This is the approach used for most of this book’s examples:
#include <iostream>
int main(){
using namespace std;
First, the iostream header file puts everything in the std namespace. Then, the using directive makes the names available within main(). Some examples do this instead:
#include <iostream>
using namespace std;
int main(){
This exports everything from the std namespace into the global namespace.The
main rationale for this approach is expediency. It’s easy to do,and if your system doesn’t
have namespaces, you can replace the first two of the preceding code lines with the original form:
#include <iostream.h>
However, namespace proponents hope that you will be more selective and use either
the scope-resolution operator or the using declaration.That is, you shouldn’t use the
following:
using namespace std; // avoid as too indiscriminate
Instead, you should use this:
int x;
std::cin >> x;
std::cout << x << std::endl;
Or you could use this:
using std::cin;
using std::cout;
using std::endl;
int x;
cin >> x;
cout << x << endl;
You can use nested namespaces, as described in the following section, to create a namespace that holds the using declarations you commonly use.
3.5 More Namespace Features
You can nest namespace declarations, like this:
namespace elements{
namespace fire{
int flame;
...
}
float water;
}
In this case, you refer to the flame variable as elements::fire::flame. Similarly, you can make the inner names available with this using directive:
using namespace elements::fire;
Also you can use using directives and using declarations inside namespaces, like this:
namespace myth{
using Jill::fetch;
using namespace elements;
using std::cout;
using std::cin;
}
Suppose you want to access Jill::fetch. Because Jill::fetch is now part of the myth namespace, where it can be called fetch, you can access it this way:
std::cin >> myth::fetch;
Of course, because it is also part of the Jill namespace, you still can call it Jill::fetch:
std::cout << Jill::fetch; // display value read into myth::fetch
Or you can do this, provided that no local variables conflict:
using namespace myth;
cin >> fetch; // really std::cin and Jill::fetch
Now consider applying a using directive to the myth namespace.The using directive is transitive.We say that an operation op is transitive if A op B and B op C implies A op C. For example, the > operator is transitive. (That is,A bigger than B and B bigger than C implies A bigger than C.) In this context, the upshot is that the following statement places
both the myth and the elements namespaces in scope:
using namespace myth;
This single directive has the same effect as the following two directives:
using namespace myth;
using namespace elements;
You can create an alias for a namespace. For example, suppose you have a namespace defined as follows:
namespace my_very_favorite_things { ... };
You can make mvft an alias for my_very_favorite_things by using the following statement:
namespace mvft = my_very_favorite_things;
You can use this technique to simplify using nested namespaces:
namespace MEF = myth::elements::fire;
using MEF::flame;
3.6 Unnamed Namespaces
待补充 506