前言
上文ShardingSphere-JDBC入门实战中对ShardingSphere-JDBC如何使用做了简单介绍,接下来打算从源码层面对数据分片做更加详细的介绍,整个数据分片会经过一个复杂的流程包括:解析、路由、改写、执行、归并这几个子流程,每个子流程都有对应的引擎来处理,本文重点分析子流程中的解析引擎。
分片流程
在介绍解析引擎之前,我们对各个子流程做一个简单的介绍;我们可以想象一下大概要经过几个流程;首先用户操作的都是逻辑表,最终是要被替换成物理表的,所以需要对SQL进行解析,其实就是理解SQL;然后就是根据分片路由算法,应该路由到哪个表哪个库;接下来需要生成真实的SQL,这样SQL才能被执行;生成的SQL可能有多条,每条都要执行;最后把多条执行的结果进行归并,返回结果集;整个流程大致如下(来自官网):
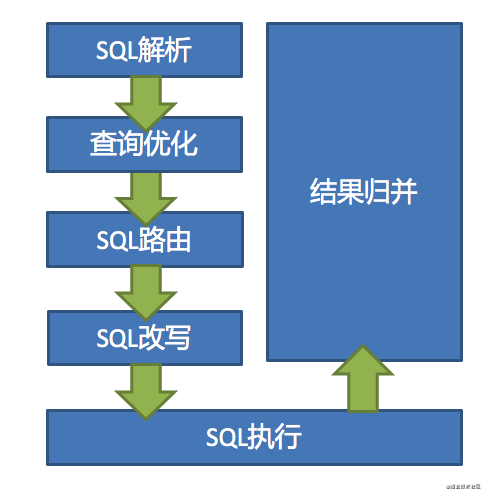
由 SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并的流程组成;每个子流程都有专门的引擎:
- SQL解析:分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记;
- 执行器优化:合并和优化分片条件,如 OR 等;
- SQL路由:根据解析上下文匹配用户配置的分片策略,并生成路由路径;目前支持分片路由和广播路由;
- SQL改写:将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写;
- SQL执行:通过多线程执行器异步执行;
- 结果归并:将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
本文重点分析SQL解析部分,但是在分析之前我们需要大致了解其中的ANTLR核心组件;
关于ANTLR
ANTLR (Another Tool for Language Recognition) 是一个强大的解析器的生成器,可以用来读取、处理、执行或翻译结构化文本或二进制文件。他被广泛用来构建语言,工具和框架。ANTLR可以从语法上来生成一个可以构建和遍历解析树的解析器。
ANTLR官方地址:https://www.antlr.org
ANTLR由两部分组成:
- 将用户自定义语法翻译成Java中的解析器/词法分析器的工具,对应antlr-complete.jar;
- 解析器运行时需要的环境库文件,对应antlr-runtime.jar;
ANTLR语法
ANTLR默认是一个已.g4结尾的文件,一个语法定义文件一般来说有一个通用的结构如下:
/** Optional javadoc style comment */
grammar Name; ①
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleN
-
grammar:语法名称,必须和文件名一致;可以包含前缀lexer和parser,如下所示:
lexer grammar MySqlLexer; parser grammar MySqlParser; -
options:可以在语法和规则元素级别指定许多选项,grammar可以包含:superClass、language、tokenVocab、TokenLabelType、contextSuperClass等,比如
options { tokenVocab=MySqlLexer; } -
import:将一个语法分割成多个逻辑上的、可复用的块,有点类似超类;
-
tokens:为那些没有关联词法规则的
grammar来定义tokens的类型;// explicitly define keyword token types to avoid implicit definition warnings tokens { BEGIN, END, IF, THEN, WHILE } @lexer::members { // keywords map used in lexer to assign token types Map<String,Integer> keywords = new HashMap<String,Integer>() { { put("begin", KeywordsParser.BEGIN); put("end", KeywordsParser.END); ... }}; } -
channels:只有lexer(词法分析)的
grammar才能包含自定义的channels,比如:channels { WHITESPACE_CHANNEL, COMMENTS_CHANNEL }以上
channels可以在lexer(词法分析)规则中像枚举一样使用:WS : [ \r\t\n]+ -> channel(WHITESPACE_CHANNEL) ; -
actionName:目前只有两个定义的命名操作(针对Java目标)在语法规则之外使用:
header和members;前者在识别器类定义之前将代码注入到生成的识别器类文件中,后者将代码作为字段和方法注入到识别器类定义中。 -
rule:规则可以分为:Lexer Rules和Parser Rules;规则格式如下所示:
``` ruleName : alternative1 | ... | alternativeN ; ```Lexer Rules:名称以大写字母开头;
Parser Rules:名称以小写字母开头;
更多参考官方文档:https://github.com/antlr/antlr4/blob/master/doc/index.md
ANTLR使用
配置环境
首先需要去官网下载antlr-complete.jar文件,我这里使用的版本是:4.7.2;然后需要配置CLASSPATH:
.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar;E:\antlr\antlr-4.7.2-complete.jar
检测一下是否成功:
E:\antlr>java org.antlr.v4.Tool
ANTLR Parser Generator Version 4.7.2
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
......
语法文件
我们需要根据ANTLR提供的语法定义自己的语法文件,比如Hello.g4如下所示:
// Define a grammar called Hello
grammar Hello;
r : 'hello' ID ; // match keyword hello followed by an identifier
ID : [a-z]+ ; // match lower-case identifiers
WS : [ \t\r\n]+ -> skip ; // skip spaces, tabs, newlines
处理语法文件
使用ANTLR执行如下命令:
E:\antlr>java -jar antlr-4.7.2-complete.jar Hello.g4
会在当前目录下生成如下一堆文件:
HelloParser.java
HelloLexer.java
HelloListener.java
HelloBaseListener.java
HelloLexer.tokens
Hello.tokens
HelloLexer.interp
Hello.interp
测试
首先需要编译上面生成的java类:
E:\antlr>javac Hello*.java
通过如下命令,展示树形图形:
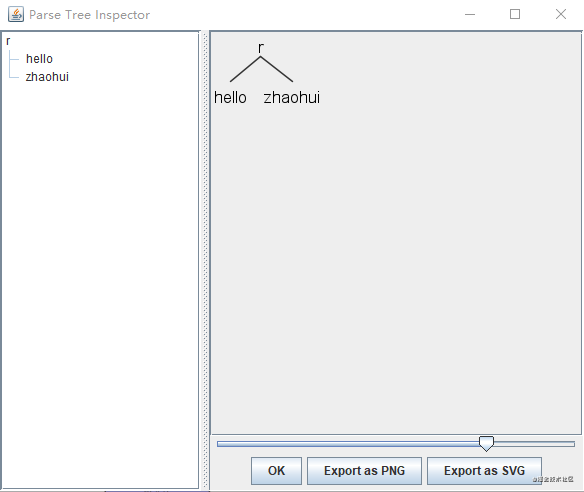
E:\antlr>java org.antlr.v4.gui.TestRig Hello r -gui
hello zhaohui
^Z
注:最后的结尾unix使用ctrl+D,windows使用ctrl+Z;
插件方式
除了以上方式还可以直接在IDE中使用插件,各种IDE的插件地址可以直接在官网查看:
插件地址:https://www.antlr.org/tools.html
处理语法文件
在Hello.g4文件上右击“Configure Antlr…”,如下所示:
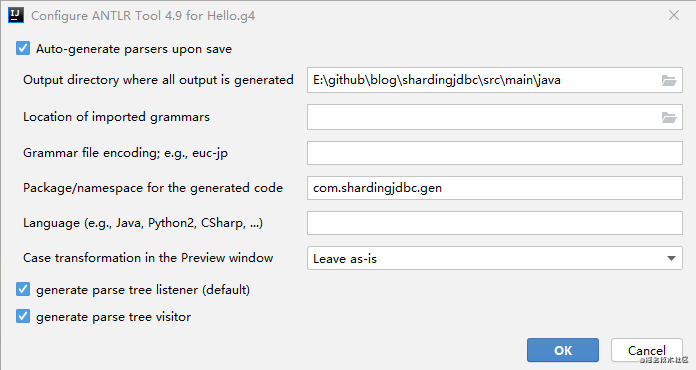
其中几个比较重要的配置包括:生成文件输出的位置、生成类指定的包名、语法树遍历的模式;
语法树遍历的模式其中可以配置两种模式:listener模式和visitor模式
测试
同样使用Hello.g4语法文件,在IDEA中,打开Hello.g4右击"Test Rule",ANTLR视图显示如下:

代码实现
有了以上的测试就可以使用代码来获取Parse tree,进行遍历;看下面一个简单的实例:
public class HelloDemo {
public static void main