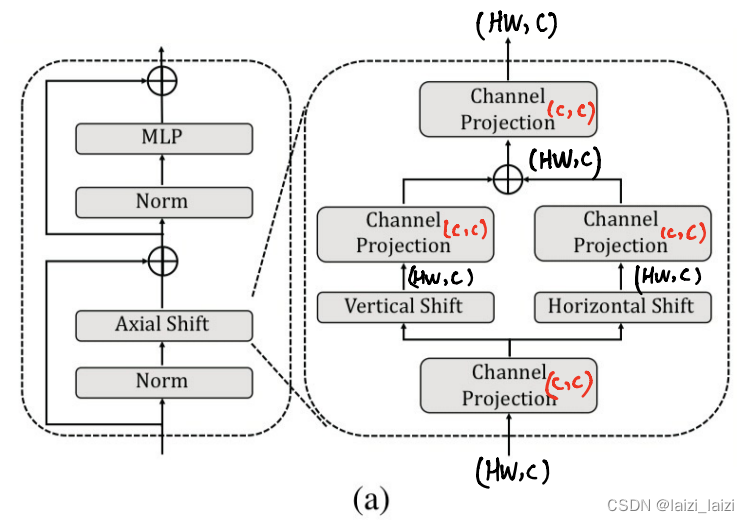
在AS-MLP里面有这几个公式:
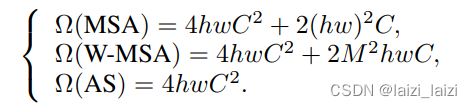
-
首先,这三个名词首先知道是从哪里来的:
- MSA: Multi-head self-attention
- W-MSA: Window multi-head self-attention
- AS-MLP:axial shifted MLP
-
然后我们这里说的是计算复杂度,而不是直接的计算量,所以会忽略比如softmax和scale的计算部分。
-
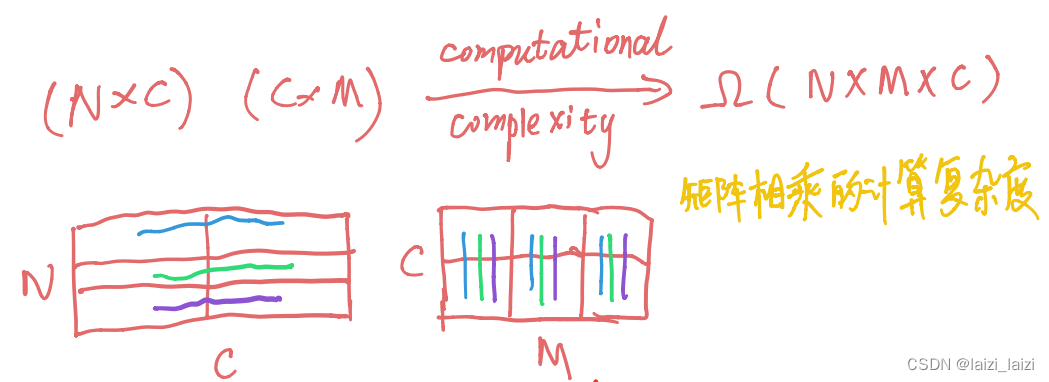
首先明确最简单的矩阵相乘的计算复杂度,可以看下面这张图:
NxC的矩阵与CxM的矩阵相乘,计算复杂度为 O ( N M C ) O(NMC) O(NMC)
好,明白以上的就可以往下看了。
一、先来看self-attention的计算就能明白了:
多头自注意力模块运算公式,简单说就是(具体流程可以看上面和下面的图):
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V
Attention(Q,K,V)=softmax(dkQKT)V
下面这幅图中黑色是tensor的shape,蓝色表示运算流,黄色是计算复杂度,nd是多头注意力里面的头数num_heads
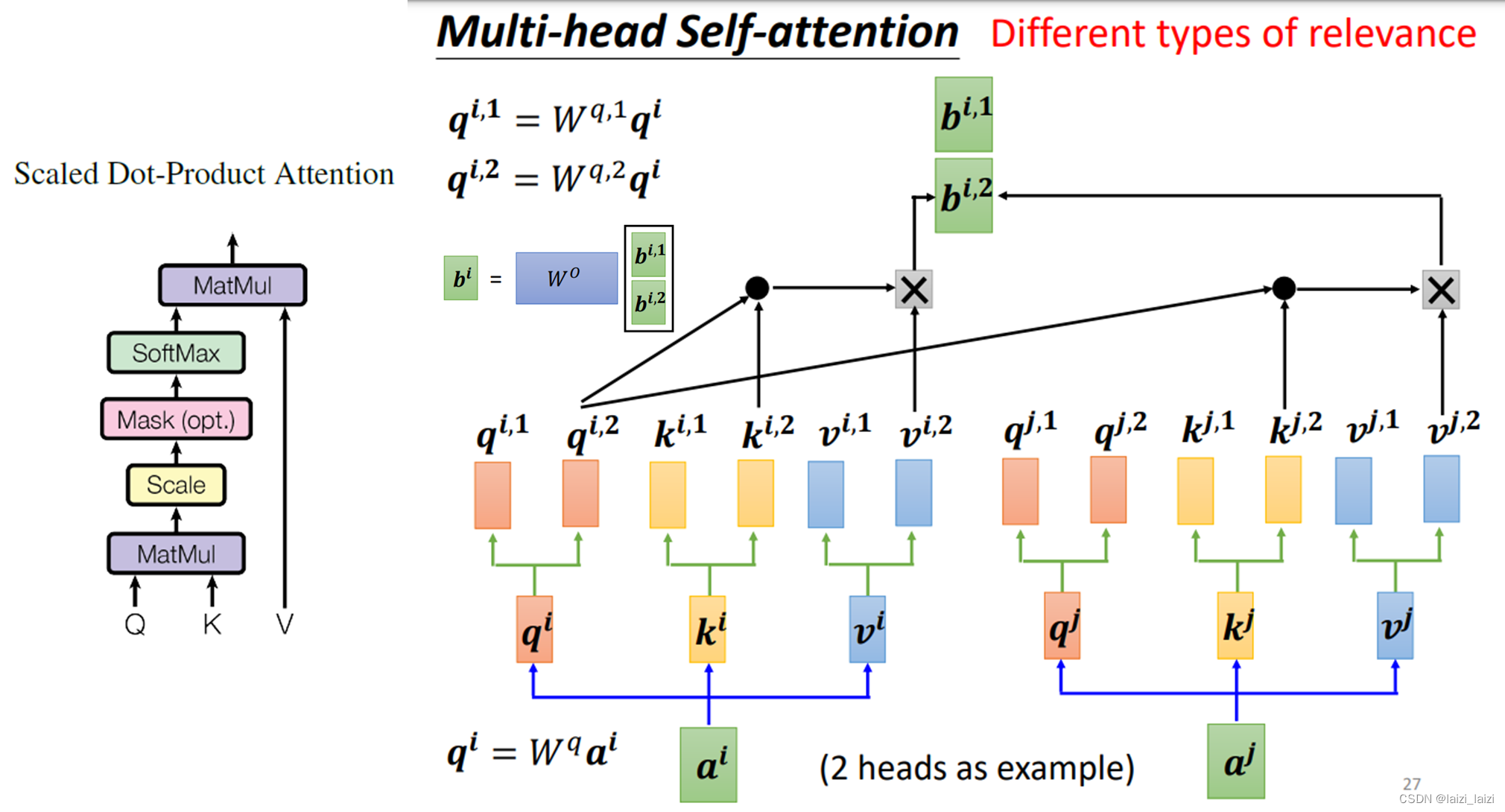
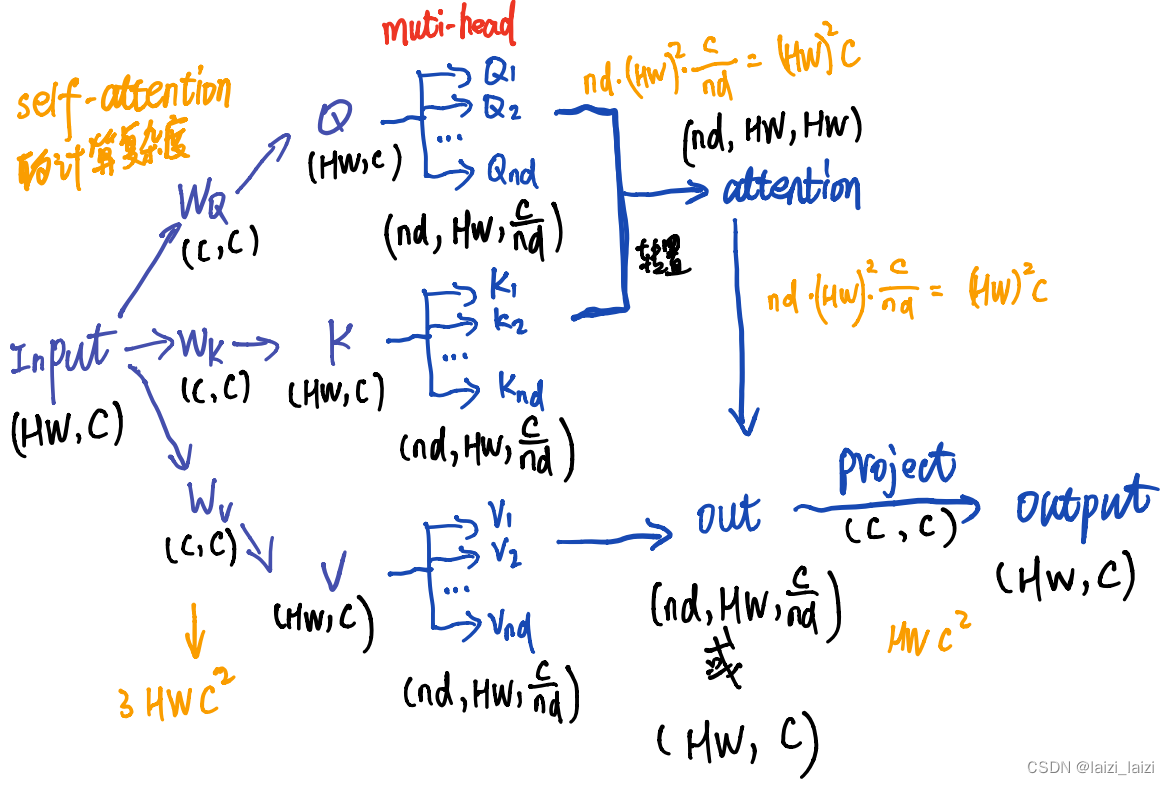
- 输入
(hw,C)先与形状都是(C,C)的 W Q , W K , W V W_{Q},W_{K},W_{V} WQ,WK,WV映射成Q,K,V,三者也都是(hw,C),这里的计算复杂度就是 3 h w C 2 3hwC^{2} 3hwC2 - 然后
Q,K,V在特征维度分成num_heads个,因为是多头,进行 Q K T QK^{T} QKT, 多头的话可以用类似torch.matmul这样的函数,得到形状为(nd,hw,hw)的attention。所以这里的计算复杂度就是 n d ∗ ( h w ) 2 ∗ C n d = ( h w ) 2 C nd*(hw)^{2}* \frac{C}{nd}=(hw)^{2}C nd∗(hw)2∗ndC=(hw)2C - 然后attention与V相乘,得到 ( n d , h w , C n d ) (nd,hw, \frac{C}{nd}) (nd,hw,ndC)的out,这一步的计算复杂度也是 n d ∗ ( h w ) 2 ∗ C n d = ( h w ) 2 C nd*(hw)^{2}* \frac{C}{nd}=(hw)^{2}C nd∗(hw)2∗ndC=(hw)2C
- 最后一步如第二张图左上角,b还要乘以个Wo才输出最后的B,类似的,
(
n
d
,
h
w
,
C
n
d
)
(nd,hw, \frac{C}{nd})
(nd,hw,ndC)的out要concat一起变成
(hw,C)再乘以一个(C,C)的矩阵project得到最后的输出(hw,C),这一步的计算复杂度也是 h w C 2 hwC^{2} hwC2
所以最后总的复杂度就是: Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C \Omega(MSA)=4hwC^{2}+2(hw)^{2}C Ω(MSA)=4hwC2+2(hw)2C
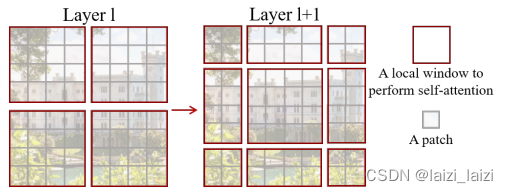
二、MSA明白,W-MSA就很容易了
因为现在self-attention操作只在大小为
M
M
M的patch里面做,所以
Ω
(
M
S
A
)
=
4
h
w
C
2
+
2
(
h
w
)
2
C
\Omega(MSA)=4hwC^{2}+2(hw)^{2}C
Ω(MSA)=4hwC2+2(hw)2C中的
4
h
w
C
2
4hwC^{2}
4hwC2是不变的,这些还是有的,就是
2
(
h
w
)
2
C
2(hw)^{2}C
2(hw)2C这部分变成了,跟上面是吻合的:
Ω
(
W
−
M
S
A
)
=
4
h
w
C
2
+
2
h
M
w
M
(
M
2
)
2
C
=
4
h
w
C
2
+
2
M
2
h
w
C
\Omega(W-MSA)=4hwC^{2}+2\frac{h}{M}\frac{w}{M}(M^{2})^{2}C=4hwC^{2}+2M^{2}hwC
Ω(W−MSA)=4hwC2+2MhMw(M2)2C=4hwC2+2M2hwC
三、AS-MLP也很简单
这里面只有四个channel projection也就是全连接层的操作,具体实现的时候就是1x1卷积,所以
Ω
(
A
S
−
M
L
P
)
=
4
h
w
C
2
\Omega(AS-MLP)=4hwC^{2}
Ω(AS−MLP)=4hwC2